はじめに
ここではWebスクレイピングで『Web上の画像を一括で保存する方法』について紹介します。
![]() 注意
注意 ![]()
著作権で保護されている場合や著作権的にはOKだが利用規約でスクレイピングを禁止している場合、損害賠償請求などの可能性があるのでしっかり著作権法や利用規約を理解した上でWebスクレイピングを行いましょう。
目次
1. Webスクレイピングを行う方法
Webスクレイピングを行うためには「Ruby」や「PHP」、「Javascript」など様々な言語で可能ですが、今回はPythonの『Beautiful Soup』を用いた方法を紹介します。
2. 実際に画像を保存してみる
① pipでbeautifulsoup4をインストールする
pip install beautifulsoup4
② Webスクレイピングを行うサイトを決める
※今回は『いらすとや』の画像をダウンロードしていきます。
https://www.irasutoya.com/search/label/%E3%83%93%E3%82%B8%E3%83%8D%E3%82%B9
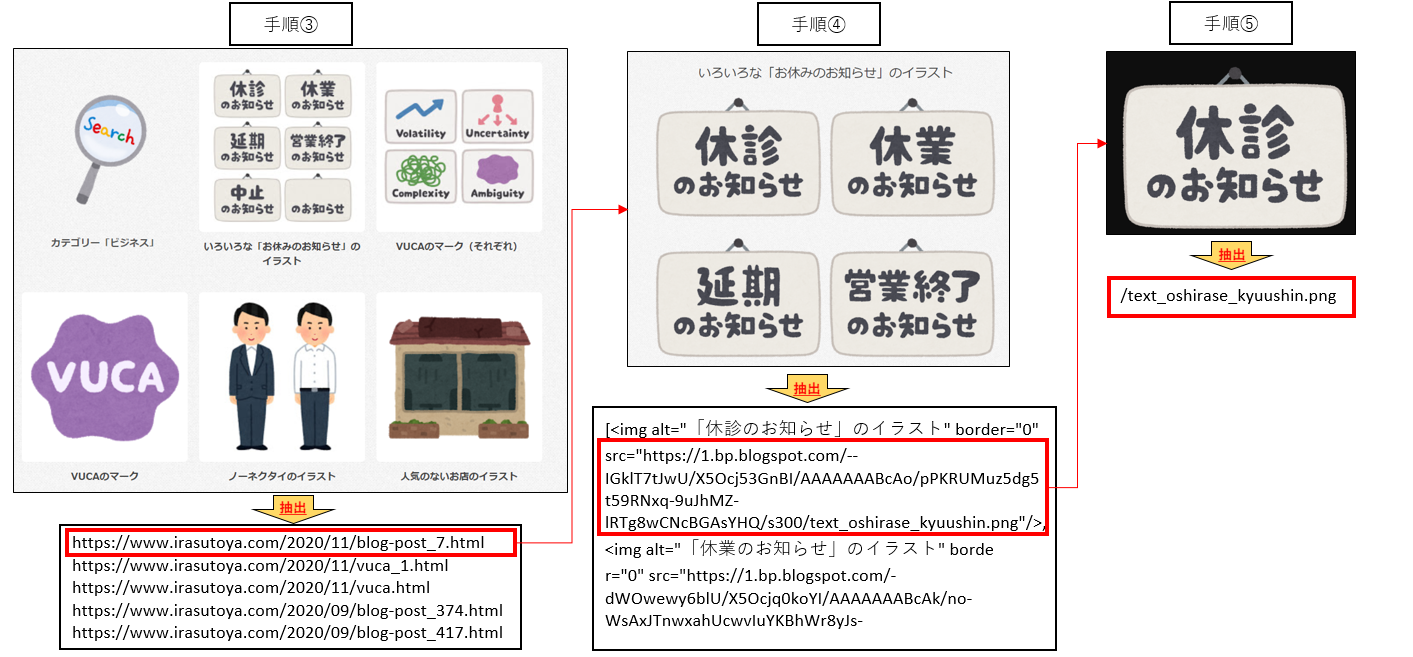
③ 一覧ページから各画像リンクページURLを取得する
url = "https://www.irasutoya.com/search/label/%E3%83%93%E3%82%B8%E3%83%8D%E3%82%B9"
# 画像ページのURLを格納するリストを用意
link_list = []
response = urllib.request.urlopen(url)
soup = BeautifulSoup(response, "html.parser")
# 画像リンクのタグをすべて取得
image_list = soup.select('div.boxmeta.clearfix > h2 > a')
# 画像リンクを1つずつ取り出す
for image_link in image_list:
link_url = image_link.attrs['href']
link_list.append(link_url)
④ 画像ファイルのタグをすべて取得する
for page_url in link_list:
page_html = urllib.request.urlopen(page_url)
page_soup = BeautifulSoup(page_html, "html.parser")
# 画像ファイルのタグをすべて取得
img_list = page_soup.select('div.separator > a > img')
⑤ imgタグを1つずつ取り出し、画像ファイルのURLを取得する
for img in img_list:
# 画像ファイルのURLを取得
img_url = (img.attrs['src'])
file_name = re.search(".*/(.*png|.*jpg)$", img_url)
save_path = output_folder.joinpath(file_name.group(1))
⑥ 画像ファイルのURLからデータをダウンロード
try:
# 画像ファイルのURLからデータを取得
image = requests.get(img_url)
# 保存先のファイルパスにデータを保存
open(save_path, 'wb').write(image.content)
# 保存したファイル名を表示
print(save_path)
except ValueError:
print("ValueError!")
手順としては以上です。
↓ ↓ 実行結果 ↓ ↓

3. 抽出の流れ
手順③~⑤が少しイメージしづらいと思ったので、大まかな抽出の流れを作成してみました。
また、今回のソースはGithubにも掲載してありますので、下記からご参照ください。
https://github.com/miyazakikna/SaveLocalImageWebScraping.git
4. まとめ
ここではPythonのBeatiful Soupを使って画像を一括で保存する方法について解説しました。
今回はいらすとやの画像を取得しましたが、他のサイトでも基本的に同じ要領で画像がダウンロードできるかと思いますので、是非活用してみてください。
5. おまけ
画像ダウンロード後、ファイル名を一括で変更する方法はこちら↓↓
[【仕事効率化】Pythonでファイル名を一括変更する方法]
(https://qiita.com/miyazakikna/items/b9c6d6d83ebcd529afd7)