Googleの実装コードであるこちらを参考に、オリジナルのデータを学習させてセグメンテーションできるようにします。
なお、筆者はWindows環境でAnaconda Navigatorを使いながら確認しました。
(Jupyter Notebookで動きを確認しつつ、Terminalで実行しました)
パスの設定
今回のモジュールはdeeplabとslim以下のモジュールを使用します。
そのため、パスに「master\research」「master\research\slim」を追加する必要があります。
WindowsのAnaconda環境であれば「PYTHONPATH」にパスを通す必要があります。
SET PYTHONPATH=master\research;master\research\slim
※本当はフルパスで指定
なお、コードに直接、
# From tensorflow/models/research
import sys,os
cur_dir = os.getcwd()
sys.path.append(cur_dir + "/slim")
でもOKです。
エラーメッセージ
うまくパスが通ってないと、以下のようなエラーメッセージが表示されます。
Traceback (most recent call last):
File "deeplab/train.py", line 22, in <module>
from deeplab import common
ModuleNotFoundError: No module named 'deeplab'
環境の準備
まずは学習データを用意するところから。
学習データは、以下の3種類が用意されています。
- PASCAL VOC 2012
- Cityscapes
- ADE20K
今回は「PASCAL VOC 2012」を使用します。
(これをまねして、オリジナルの学習データを用意すればよいということ)
※「tensorflow/models/research/deeplab/datasets」フォルダにある、「download_and_convert_voc2012.sh」を実行すればよいのですが、せっかくなので、その内容を記述していきます
学習データのダウンロード
こちらからファイルをダウンロードします。
「tensorflow/models/research/deeplab/datasets」フォルダの下に「pascal_voc_seg」というフォルダを作成し、そこに保存します。
保存したら、同じところにTARファイルの中身を展開します。
すると、こんな階層のフォルダ構成になっているはずです。
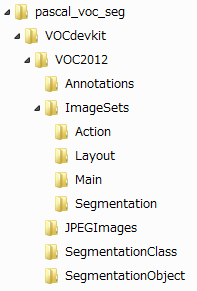
この中の「JPEGImages」が入力データ、「SegmentationClass」がセグメンテーションされているデータになります。また「ImageSets/Segmentation」に使用するファイル名(拡張子なし)のリストが設定されています。
データ変換
この「SegmentationClass」にある画像には、インデックスカラーでセグメンテーションされているので、グレースケール画像(RGBそれぞれに同じインデックス値を設定)に変換(つまり256クラスに分類)して「SegmentationClassRaw」というフォルダに保存しておきます。
※この処理は「remove_gt_colormap.py」のことになります
これと同じことをして、「SegmentationClassRaw」にオリジナルデータのグレースケール画像を設定すればOKということになります。
なお、色とインデックス値とクラスとの関係はこちらを参考にしてください。
次に、学習時に読み込みやすいように、データセットをTFRecords形式に変換します。
保存されているデータは、画像ごとに以下の通りです。
- オリジナルの画像データ
- ファイル名
- 画像フォーマット("jpg"とか)
- 画像高さ
- 画像幅
- チャンネル数(RGBなら3)
- セグメンテーション画像のデータ
- セグメンテーション画像のフォーマット("png"とか)
これらを、例えばトレーニング用、評価用、トレーニング+評価用の3種類用意します。
それぞれ4ファイルに分割されています。(4ファイルに分ける理由は不明)
※この処理は「build_voc2012_data.py」「build_data.py」のことになります
(引数等の説明は省略)
注意事項
読み込む学習データ数が「segmentation_dataset.py」にハードコーディングされています。
_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 1464,
'train_aug': 10582,
'trainval': 2913,
'val': 1449,
},
num_classes=21,
ignore_label=255,
)
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
}
オリジナルのデータを使用する場合は、ここも修正する必要があります。
_ORIGINAL_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 2000,
'eval': 100,
'vis': 10,
},
num_classes=4,
ignore_label=255,
)
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
'original': _ORIGINAL_INFORMATION ,
}
【注意】クラス数を変えた場合、学習時に以前のチェックポイントが残っているとエラーになります。ちゃんとチェックポイントを消してから学習し直してください。
事前学習済みデータのダウンロード
さらに、初期値として事前学習済みのデータを使用しますので、ここからダウンロードしておきます。TAR+ZIPになってますので、解凍・展開しておきます。
学習
準備したデータを使用して学習を行います。
学習は、事前学習済みデータを初期値として、用意した学習データを使用して学習を進めていきます。
※この処理は「train.py」のことになります
python deeplab/train.py \
--logtostderr \
--train_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=513 \
--train_crop_size=513 \
--train_batch_size=64 \
--fine_tune_batch_norm=false \
--tf_initial_checkpoint="./data/init_models/deeplabv3_pascal_train_aug/model.ckpt" \
--initialize_last_layer=false \
--last_layers_contain_logits_only=true \
--train_logdir="./data/log/train" \
--dataset_dir="./data/tfrecord" \
--dataset="pascal_voc_seg"
代表的な引数
| 引数名 | 意味 | 値(例) |
|---|---|---|
| logtostderr | ログ出力の有無 | - |
| training_number_of_steps | 学習回数 | 30000 |
| train_split | 使用データ | train, val, trailval |
| model_variant | 識別モデル種類 | xception_65, mobilenet_v2 |
| atrous_rates | Atrous畳み込みの比率 ※複数回設定可能 |
6 |
| output_stride | 出力ストライド(atrous_rateとの組み合わせ) | 16 |
| decoder_output_stride | 入出力の空間解像度の比率 | 4 |
| train_crop_size | 画像の切り出しサイズ ※XYの2回指定 |
513 |
| train_batch_size | ミニバッチのサイズ | 64 |
| fine_tune_batch_norm | Batch Normalizationの実行 | true, false ※GPUで学習するときはfalse |
| dataset | データセット名 | cityscapes, pascal_voc_seg, ade20k |
| tf_initial_checkpoint | 学習済みモデル名 | deeplab\datasets\pascal_voc_seg\init_models\deeplabv3_pascal_train_aug\model.ckpt |
| initialize_last_layer | 最後のレイヤーの初期化 | true, false クラス数を変えたときはfalse |
| last_layers_contain_logits_only | logitsを最後のレイヤーとしてのみ考慮 | true, false クラス数を変えたときはtrue |
| train_logdir | ログ出力フォルダ名 | deeplab\datasets\pascal_voc_seg\exp\train_on_trainval_set\train |
| dataset_dir | データセットフォルダ名 | deeplab\datasets\pascal_voc_seg\tfrecord |
「train_crop_size」は「output_stride*k+1 (k>=1)」の値を指定してください。
エラーメッセージ
GPUメモリが足らないと、以下のようなエラーメッセージが表示されます。
ResourceExhaustedError (see above for traceback): OOM when allocating tensor wit
h shape[1,64,257,257] and type float on /job:localhost/replica:0/task:0/device:G
PU:0 by allocator GPU_0_bfc
実行結果
学習済みモデル(チェックポイント)がログ出力フォルダに作成されます。
checkpoint
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
評価
学習済みデータを使用して評価を行います。
識別率やloss値を確認します。
なお、評価用の画像データもTFRecords形式にしておく必要があります。
※この処理は「eval.py」のことになります
python deeplab/eval.py \
--logtostderr \
--eval_split="val" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--eval_crop_size=513 \
--eval_crop_size=513 \
--max_resize_value=512 \
--min_resize_value=128 \
--checkpoint_dir="./data/log/train" \
--eval_logdir="./data/log/eval" \
--dataset_dir="./data/tfrecord" \
--max_number_of_evaluations=1 \
--eval_interval_secs=0 \
--dataset="pascal_voc_seg"
代表的な引数
| 引数名 | 意味 | 値(例) |
|---|---|---|
| logtostderr | ログ出力の有無 | - |
| eval_split | 使用データ | train, val, trailval |
| model_variant | 識別モデル種類 | xception_65, mobilenet_v2 |
| atrous_rates | Atrous畳み込みの比率 ※複数回設定可能 |
6 |
| output_stride | 出力ストライド(atrous_rateとの組み合わせ) | 16 |
| decoder_output_stride | 入出力の空間解像度の比率 | 4 |
| eval_crop_size | 画像の切り出しサイズ ※XYの2回指定 |
513 |
| max_resize_value | 画像の最大サイズ | 512 |
| min_resize_value | 画像の最小サイズ | 128 |
| dataset | データセット名 | cityscapes, pascal_voc_seg, ade20k |
| checkpoint_dir | チェックポイントフォルダ名 | deeplab\datasets\pascal_voc_seg\exp\train_on_trainval_set\train |
| eval_logdir | ログ出力フォルダ名 | deeplab\datasets\pascal_voc_seg\exp\train_on_trainval_set\eval |
| dataset_dir | データセットフォルダ名 | deeplab\datasets\pascal_voc_seg\tfrecord |
| max_number_of_evaluations | 繰り返し数 | 1 |
| eval_interval_secs | 繰り返し待ち時間(秒) | 0 |
「model_variant」「atrous_rates」「output_stride」「decoder_output_stride」は学習と同じにする必要があります。
「eval_crop_size」は「output_stride*k+1 (k>=1)」の値を指定してください。
「max_resize_value」は最大「vis_crop_size-1」を指定してください。
※「max_resize_value」を指定したら「min_resize_value」も指定してください
エラーメッセージ
「max_resize_value」を指定せずに「eval_crop_size-1」より大きい値の画像を指定すると、以下のようなエラーになります。
INFO:tensorflow:Error reported to Coordinator: <class 'tensorflow.python.framework.errors_impl.InvalidArgumentError'>, Shape mismatch in tuple component 1. Expected [513,513,3], got [3024,4032,3]
[[Node: batch/padding_fifo_queue_enqueue = QueueEnqueueV2[Tcomponents=[DT_INT64, DT_FLOAT, DT_STRING, DT_INT32, DT_UINT8, DT_INT64], timeout_ms=-1, _device="/job:localhost/replica:0/task:0/device:CPU:0"](batch/padding_fifo_queue, Reshape_3/_1607, add_2/_1609, ParseSingleExample/ParseSingleExample:1, add_3/_1611, batch/packed, Reshape_6/_1613)]]
実行結果
標準出力に、以下のように表示されます。
INFO:tensorflow:Evaluation [1/2]
INFO:tensorflow:Evaluation [2/2]
INFO:tensorflow:Finished evaluation at 2018-09-07-23:40:26
miou_1.0[0.194943964]
mIoU(mean Intersection over Union)とは、正しくセグメンテーションできた割合の評価画像全部の平均の値です。詳しくはこちらを参照してください。
可視化
学習済みデータを使用して、セグメンテーションした画像を取得します。
なお、可視化用の画像データもTFRecords形式にしておく必要があります。
※この処理は「vis.py」のことになります
python deeplab/vis.py \
--logtostderr \
--vis_split="val" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--vis_crop_size=513 \
--vis_crop_size=513 \
--max_resize_value=512 \
--min_resize_value=128 \
--checkpoint_dir="./data/log/train" \
--vis_logdir="./data/log/vis" \
--dataset_dir="./data/tfrecord" \
--max_number_of_iterations=1 \
--eval_interval_secs=0 \
--dataset="pascal_voc_seg"
代表的な引数
| 引数名 | 意味 | 値(例) |
|---|---|---|
| logtostderr | ログ出力の有無 | - |
| vis_split | 使用データ | train, val, trailval |
| model_variant | 識別モデル種類 | xception_65, mobilenet_v2 |
| atrous_rates | Atrous畳み込みの比率 ※複数回設定可能 |
6 |
| output_stride | 出力ストライド(atrous_rateとの組み合わせ) | 16 |
| decoder_output_stride | 入出力の空間解像度の比率 | 4 |
| vis_crop_size | 画像の切り出しサイズ ※XYの2回指定 |
513 |
| max_resize_value | 画像の最大サイズ | 512 |
| min_resize_value | 画像の最小サイズ | 128 |
| dataset | データセット名 | cityscapes, pascal_voc_seg, ade20k |
| checkpoint_dir | チェックポイントフォルダ名 | deeplab\datasets\pascal_voc_seg\exp\train_on_trainval_set\train |
| vis_logdir | ログ出力フォルダ名 | deeplab\datasets\pascal_voc_seg\exp\train_on_trainval_set\vis |
| dataset_dir | データセットフォルダ名 | deeplab\datasets\pascal_voc_seg\tfrecord |
| max_number_of_iterations | 繰り返し数 | 1 |
| eval_interval_secs | 繰り返し待ち時間(秒) | 0 |
「model_variant」「atrous_rates」「output_stride」「decoder_output_stride」は学習と同じにする必要があります。
「vis_crop_size」は「output_stride*k+1 (k>=1)」の値を指定してください。
「max_resize_value」は最大「vis_crop_size-1」を指定してください。
※「max_resize_value」を指定したら「min_resize_value」も指定してください
実行結果
指定したログ出力フォルダの下の「segmentation_results」に、オリジナルの画像とセグメンテーションした画像のペアが保存されます。
ファイル名は順番に番号が振られ、オリジナル画像は「000000_image.png」、セグメンテーション画像は「000000_prediction.png」となります。