対象
- 各種機械学習手法等を用いて物体検出を行っているが、
作成したモデルをどう評価して良いかわからない人 - 何となくIoU、mAP などで評価すれば良いと知っているが、実装方法が分からない人
はじめに
大学の研究で画像認識を行うことになったのですが、
作成したモデルをどう評価すれば良いかを学ぶ必要があったので、
折角なので記事にまとめさせていただきました。m(__)m
何を評価すべきか
-
物体検出精度
名前の通り、画像中の検出したい物体を、作成したモデルがどの程度正しく検出できるかを評価する指標です。機械学習で基本的な評価指標であるPrecision、Recall等を組み合わせ、複数の画像に対してモデルがどの程度機能しているかを評価します。
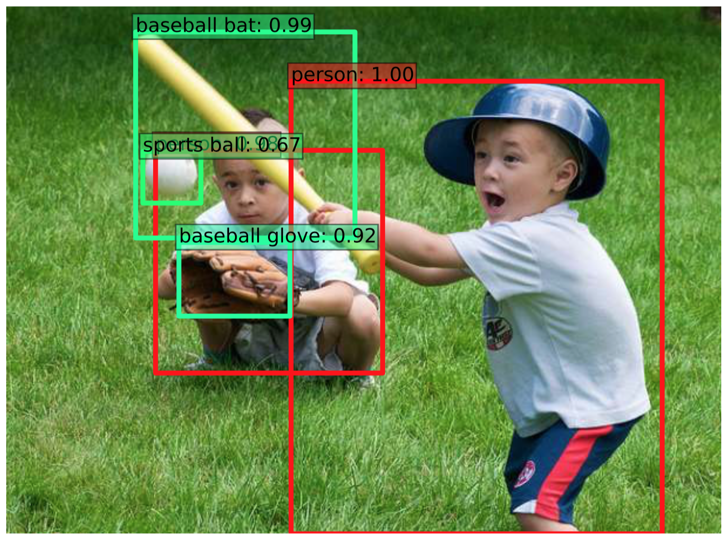
参考:Deep Learningによる一般物体検出アルゴリズムの紹介
今回は、代表的な評価指標であるmAP、IoUというものについて見ていきます。 -
処理速度
比較的データの大きくなりがな画像を、機械学習、特にDeep Learningで扱うとなれば、処理時間が膨大となってしまいます。危険回避のため高い処理速度が求められる自動運転
等では、特にこの処理速度の高速化は重要でしょう。物体検出モデルを評価する指標として、fps(Frames per second)があります。名前の通り、一秒間あたりに何枚の画像を処理できるか、という指標です。高速物体検出手法として良く知られているYOLO(https://pjreddie.com/darknet/yolo/) は、cocoデータセット(coco test-dev)に対して30[fps]の処理速度を誇ります。今回はfpsを測定していきます。
物体検出精度評価指標その1 mAP(mean Average Precision)
まずは、mAP(mean Average Precision)について見ていきます。
これは、ある画像(物体)の情報が与えられた時点までの適合率(Precision)の平均であるAP(Average Precision)の平均です。これだけではなんのことかわからない場合も多いと思いますので(説明下手ですみません)、必要な知識を一つ一つ見ていきましょう。
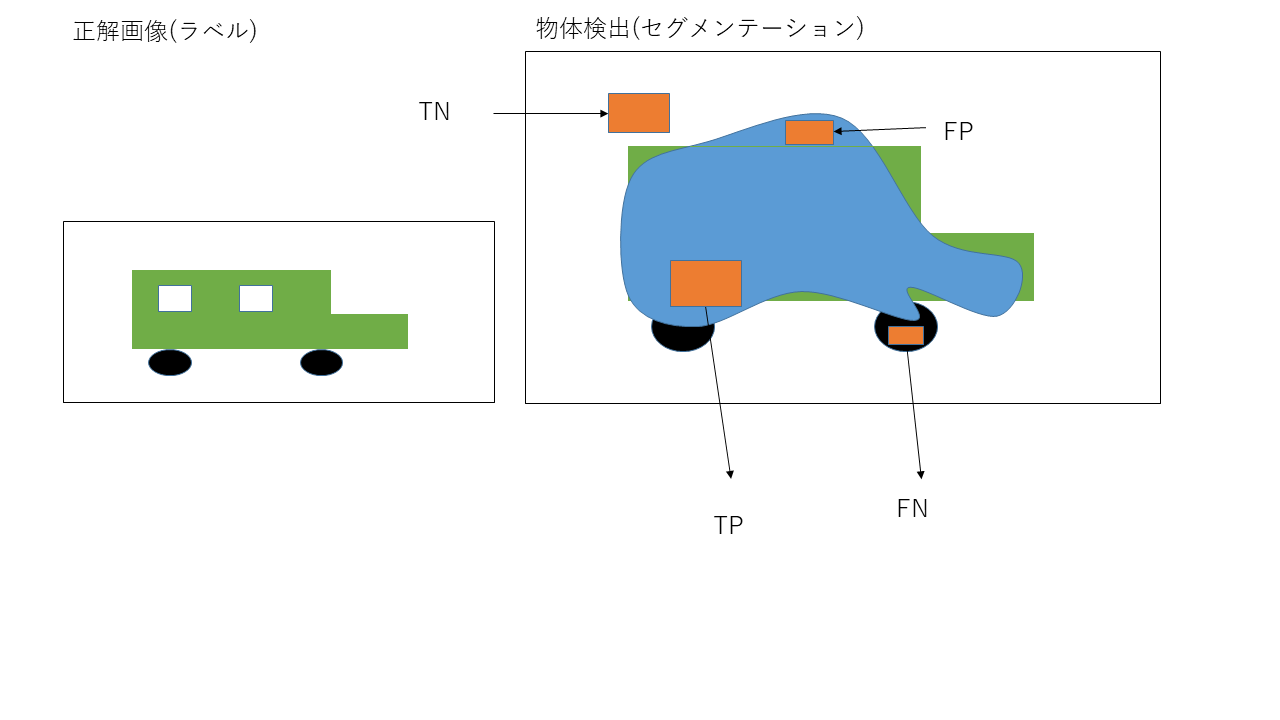
1. TP、TN、FP、FN
それぞれ、TP(True Positive)、TN(True Negative)、FP(False Positive)、FN(False Negative)の略です。画像中の物体検出において、TPは、"画像中に実際に存在する物体を、モデルが見つけることができた"ことを表し、TNは、"画像中に存在しない物体を、モデルは無いとみなすことができた(検出しなかった)"ことを表します。一方でFPは"画像中に存在する物体を、モデルが見つけることはできなかった"表し、FNは、"画像中に存在しない物体を、モデルは存在するものとして認識してしまった"ことを表します。
(上記は誤りです。 FNがは"画像中に存在する物体を、モデルが見つけることはできなかった"表し、FPは、"画像中に存在しない物体を、モデルは存在するものとして認識してしまった"ことを表します。
自動車の参考図も、FPとFNは反対です。m(__)m)
これらを上手く使用し、評価指標を作り上げていきます。物体検出におけるこの4つの指標のイメージとして以下を参照ください。なお、今回は矩形による物体検出ではなく、画素レベルの検出手法であるセグメンテーションを用いています。
2.Precision(適合率)、Recall(再現率)
物体検出に限りませんが、機械学習、パターン認識の分野において、Precision(適合率)、Recall(再現率)という二つの評価指標は良く使われます。Precisionとは、モデルが真である(そこに物体がある)と予想したとき、実際にそれが真である確率で表現されます。上の車の例では、**車が存在すると予想した部分(TP∪FP)**の内、**実際に車が存在した(TP)**ということで、
Precision = \frac{TP}{TP∪FP}
として表します。
一方で、Recallは、実際に正解であるもの(TP∪FN)を、モデルによりどれだけ認識できたかを表します。
よって、
Recall = \frac{TP}{TP∪FN}
となります。
3. AP(Average Precision)
もう少しで、目的のmAPにたどり着きます。これは、m個の正解ラベルが現れた時点で、
モデルがm個のラベルの内、どれだけのラベルを検出できているかを平均的に表現したものになります。平均適合率、ともよばれます。
AP = \frac{1}{N}\sum_{j=1}^I\frac{[num\_of\_Hit]_j}{n_j} \\
= \frac{1}{N}\sum_{j=1}^I Precision \\
N:jの時点でモデルが正しく認識した正解ラベル(物体)の総数 \\
num\_of\_Hit:jの時点で現れた正解ラベル(物体)の内、正しく認識できた数 \\
n_i:jの時点で現れた正解ラベル(物体)の数
4. mAP(mean Average Precision)
これは、全ての時点iにおけるAP(平均適合率)を平均することで、より一般的な平均値を求める為のものです。
mAP = \frac{1}{M}\sum_{i=1}^M AP_i \\
M:画像(画素)の総数 \\
物体検出精度評価指標その2 IoU(Intersection over Union)
次に、もう一つのモデル評価手法の紹介に移ります。もう一つは、IoUと呼ばれる手法です。
これは、
IoU = \frac{TP}{TP∪TN∪FN} \\
で表現されます。これは、上の車のセグメンテーション写真に例えると、実際に車である、
もしくはモデルが車であると予想した領域の内、モデルが正しく車であることを認識できた領域(TP)がどの程度か、を表したものになります。
Python3による実装(mAP、IoU)
物体検出におけるモデル評価を行いますが、
今回は、物体検出のなかでも、矩形(四角形)を使った顔検出を行います。
1. ラベル付け
物体検出に限らず、何らかの方法で設計したモデルを評価する為には、
正解(ラベル)を教えてあげる必要があります。今回は、矩形による顔検出を行うので、
4点を用いて顔である部分を囲み、その内部を何らかの色で塗りつぶすことで、
そこが顔である(正解である)ことを教えます。
今回はこれを行う為に、あるツール(http://arkouji.cocolog-nifty.com/blog/2017/07/yolotensorflow-.html)を用いました。
使い方はリンクを参照くださいませ。
リンクのツールを用いると、csvファイル、あるいはjsonファイルの形式で
顔の中心位置(x,y)、横幅w、高さhが取得できます。
私はcsv形式のものを用いましたが、肝心の部分は見た目がPythonの辞書型っぽい
string型になっていたので、 astモジュールを用いて辞書型へ変換しました。
# csvファイル(正解データ)読込
import ast
import pandas as pd
import cv2
df = pd.read_csv("./label_C.csv")
label = df.values[17] #ある一枚のラベル情報を読込
label = ast.literal_eval(label[5])#arrayに変換
x_label = label["x"]
y_label = label["y"]
w_label = label["width"]
h_label = label["height"]
# オリジナル画像読込
img = cv2.imread('./train/7.jpg')
img_label = img
faces2 = np.array([[x_label,y_label,w_label,h_label]])
# 上で読み込んだcsvファイルを用いて正解(ラベル)画像作成
for (x2,y2,w2,h2) in faces2:
# 検知した顔を矩形で囲む
cv2.rectangle(img_label,(x2,y2),(x2+w2,y2+h2),(255,0,0),-1)
print("img_label:",img_label.shape)
以上のコードより、以下のラベル画像が作成されます。

2. HarrLike 特徴量を用いた顔検出
今回は、Harr-Like特徴量を用いた顔検出を、OpenCVを用いて行います。
このモデルは顔認識用に学習されたものですので、改めて学習する必要はありません。
これは明暗差に関する特徴量ですので、RGB(BGR)などの色情報は使いません。
よって、まずグレースケールに変換します。
# OpenCVで用意されている特徴量を読み込む
img = cv2.imread('./train/7.jpg') #任意の画像ファイルを読込
img_model = img
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face_cascade = cv2.CascadeClassifier("./haarcascade_frontalface_alt.xml")
faces = face_cascade.detectMultiScale(gray) #ここで顔を検出
for (x,y,w,h) in faces:
# 検知した顔を矩形で囲む
cv2.rectangle(img_model,(x,y),(x+w,y+h),(0,0,255),-1) #検出部分は赤色で塗りつぶす。
以上の処理により、読み込んだ画像から、
以下の画像の赤色の矩形部分として顔検出を行いました。

3.IoUの計算
次にIoUの計算を行います。これは、実際に顔である、あるいは顔であると予測した領域(TP+FP+FN)の内、
モデルが正確に顔であると認識した領域(TP)の割合を表します。
これは、先ほど獲得したラベル画像、モデルによる検出結果の画像の2つを用いて、以下の様に
記述することで獲得できます。
TP,FP,FN = 0,0,0
height = img_model.shape[0]
width = img_model.shape[1]
print("height",height)
print("width",width)
for i in range(height):
for j in range(width):
if all(img_model[i][j] == np.array([0,0,255])): #赤色だったら(モデルがfaceだと予想している場合)
if all((img_label[i][j]) == np.array([255,0,0])): #正解画像(ラベル)もfaceだとしていたら(label画像上で青路色)
TP = TP + 1
else:
FP = FP + 1
elif all(img_label[i][j] == np.array([255,0,0])):
if all(img_model[i][j] != np.array([0,0,255])):
FN = FN + 1
IoU = TP/(TP + FP + FN)
print("(TP,FP,FN)=(",TP,",",FP,",",FN,")")
print("IoT:", IoU)
上記のコードでは、モデルが各画素を顔だと認識しているかどうか(BGR=(0,0,255)かどうか)でまず条件分岐させ、その上で、それが正解かどうかでTP、FPである画素数を数えていきます。
そもそもモデルが顔だと予測していない部分については、その上で正解画像の上で顔であれば、
FNの領域とし、同じくその画素数を数えていきます。
最後に上述のIoU計算式で計算すれば完了です。
4. mAPの計算
まず、以下にコードを示します。
import numpy as np
# 認識できたラベル数Nを求める
N = TP #TPはモデルが正解だ(顔であると予測した画素の内、正解だった画素数)
# Precisionの総和を求める(IoUのコードと類似)
height = img_model.shape[0]
width = img_model.shape[1]
# n = np.arange(1,N+1)
n = 0 #モデルが顔だと認識した画素数を入れる
numOfHit = 0 #モデルが顔だと認識した画素の内、正解だった画素数を入れる
AP = [] #各時刻までのAPiを入れていく
Precision = 0
print("N = ",N)
for i in range(height):
for j in range(width):
if all(img_model[i][j] == np.array([0,0,255])): #赤色だったら(モデルがfaceだと予想している場合)
n = n + 1
if all((img_label[i][j]) == np.array([255,0,0])): #正解画像(ラベル)もfaceだとしていたら(label画像上で青路色)
numOfHit = numOfHit + 1
Precision = Precision + (numOfHit / n) #iの時点での適合率
Ni = numOfHit
APi = Precision / Ni
AP.append(APi)
if( (height*width) % 100 == 0):
print("Ni:", Ni)
print("Precision:", Precision)
print("APi:",APi)
print("")
AP = np.array(AP) #下でmean関数を使う為にarray化する
mAP = np.mean(AP)
print("mAP:", mAP)
今回は、各画素(i,j)を順にみていき、各時点までで見てきた部分までの平均適合率APiを計算し、
APというリストに入れ込みます。
最後に、APにはいっている要素をnumpyのmean関数で平均することでmAPを求めています。
for文でAPiをN回(モデルが顔であると予測した画素数=最終的なTP)回さず、リスト化した理由は、
やはりやたら処理速度が遅くなるからです。
最後に
色々と荒くて申し訳ありませんが以上となります。
参考文献
https://qiita.com/GushiSnow/items/8c946208de0d6a4e31e7
2.
http://www.renom.jp/ja/notebooks/renom_img/iou_and_map/notebook.html