以前、TensorFlowの処理を理解するために、MNISTのコードを読んでいくことをしてみたが、やっぱり画像なんだからCNNしたいよねということで、畳み込み処理を追加してみました。
参考はもちろん「Deep MNIST for Experts」ですが、こちらも結構参考にさせてもらいました。
畳み込み処理
ズバリ、n×nのフィルターを掛けること。
画像処理をやっている人には、エッジを抽出したり、ぼかしたりしてきたアレですので、非常になじみ深いです。
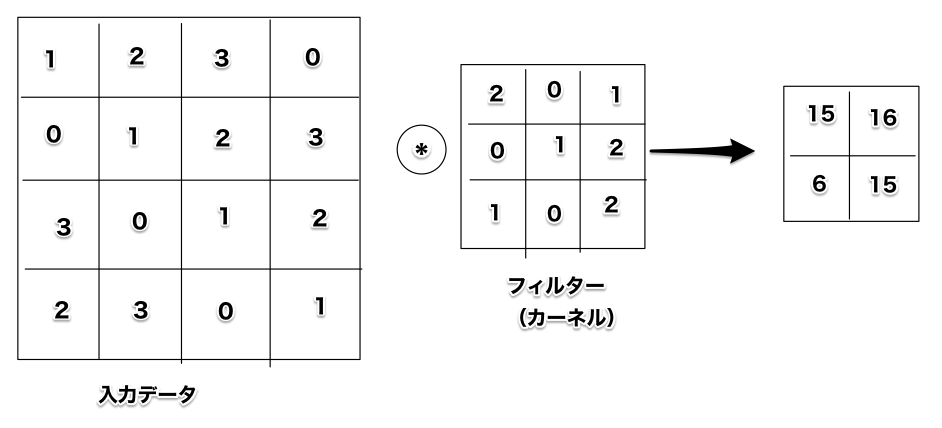
使用する関数は「tensorflow.nn.conv2d()」で、設定する引数は主に4つ。
1つ目は入力データ。
2つ目はフィルター(縦サイズ、横サイズ、入力チャンネル数、出力チャンネル数)。
3つ目は移動ストライド。
4つ目はパディングの設定。
通常はこんな感じで設定します。
x = tensorflow.placeholder(tf.float32, [None, 784])
x_image = tensorflow.reshape(x, [-1, 28, 28, 1])
initial = tensorflow.truncated_normal([5, 5, 1, 32], stddev=0.1)
W_conv1 = tensorflow.Variable(initial)
h_conv1 = tensorflow.nn.conv2d(x_image,
W_conv1,
strides=[1, 1, 1, 1],
padding='SAME')
MNISTのデータは28×28の画像が1次元に伸びた状態なので、まず28×28に戻しています。
次に5×5のフィルターを設定しています。入力は白黒画像なので1チャンネルで、出力は32チャンネルにしています。
なお、畳み込み処理時には、活性化関数としてReLUを使ったりしますので、実際には最後の行は
initial = tensorflow.constant(0.1, [32])
b_conv1 = tensorflow.Variable(initial)
h_conv1 = tensorflow.nn.relu(tensorflow.nn.conv2d(x_image,
W_conv1,
strides=[1, 1, 1, 1],
padding='SAME')
+ b_conv1)
といった感じになります。
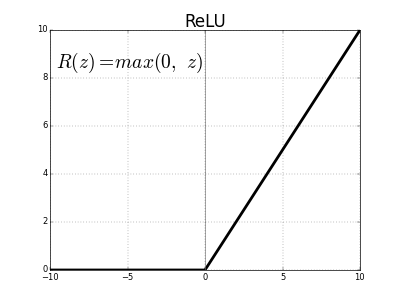
(「W_conv1」や「b_conv1」が、誤差逆伝播で調整される重みパラメータになります)
プーリング処理
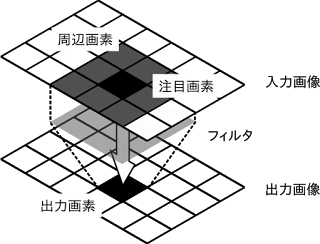
通常、畳み込み処理と対になっているのがプーリング処理です。
こちらは画像サイズの縮小を行うイメージになります。
(n×nの代表値を求める)
平均値だったり中央値だったり、いろいろ方法はありますが、Deep Learningでは、いわゆる「Max Poolong」といわれる最大値を使用することが多いです。
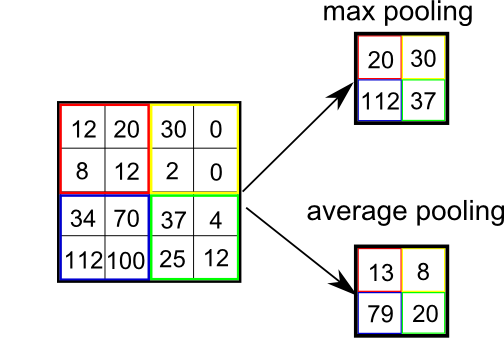
TensorFlowでは、「tensorflow.nn.max_pool()」を使用します。
設定する引数は、主に4つ。
1つ目は入力データ。
2つ目はフィルター。
3つ目が移動ストライド。
4つ目はパディングの設定。
畳み込み処理と似てますよね。
実際のコードはこんな感じになります。
h_pool1 = tensorflow.nn.max_pool(h_conv1,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
入力は畳み込み処理の結果になります。
フィルターのサイズは2×2、ストライドも縦横2ピクセル移動することにしています。これにより、出来上がりの画像サイズは、元の半分になります。
(チャンネル数は変わりません)
全結合処理のために
なお、畳み込み処理やプーリング処理は2次元の画像として処理をしているため、全結合する際に1次元に変換します。
この時、ちゃんと画像サイズとチャンネル数が分かっていないと配列のサイズが設定できないため、注意してください。
関数は、1次元→2次元にした時と同じように、「tensorflow.reshape()」を使用します。
おまけ
まだ説明していない部分もありますが、動く(はず)のソースコードを載せておきます。
※2017/03/21現在、MNISTのデータセットが置かれているサイトにアクセスできなくなっていますのでご注意ください。
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
# オリジナルの関数群
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# メイン関数
def main():
# データセットの取得
# (今は、あらかじめダウンロードしてあるzipのフォルダを指定)
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
# 入出力データの準備
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 畳み込み処理(1)
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# プーリング処理(1)
h_pool1 = max_pool_2x2(h_conv1)
# 畳み込み処理(2)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# プーリング処理(2)
h_pool2 = max_pool_2x2(h_conv2)
# 全結合処理
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# ドロップアウト
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 識別(なぜsoftmaxがないのかは謎)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
# 評価処理(なぜかこっちにはsoftmaxがある)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# セッション作成
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# トレーニング
for i in range(20000):
# バッチサイズは50
batch = mnist.train.next_batch(50)
# 100回ごとに経過表示
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# 結果表示
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
# 処理開始
if __name__ == "__main__":
main()
あとは、ドロップアウトと評価処理のところを書かないとね...
(評価処理、よくわからない ^^;)