TensorFlowのチュートリアルにある「MNIST」を使用して、TensorFlowの処理を理解しようと思います。
はじめに
ざっくりとしたイメージですが、TensorFlowは、あらかじめ処理の流れを登録しておき、後から一気に実行する感じになります。
DirectShowをイメージしてもらうのがいいのかなと思います。
(DirectShowを知らない人、ごめんなさい)
・グラフ→グラフ
・フィルター→ノード(=オペレーション)
といった感じでしょうか。
MNISTデータのダウンロード
まずは、学習/評価に使うデータをダウンロードしてきます。
データの取得元は「http://yann.lecun.com/exdb/mnist/」になります。
※2017/03/21現在、上記サイトは落ちているようです
(読み込もうとするとurllibでエラーになります)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
ダウンロードしてきたファイルは、カレントフォルダ内に「MNIST_data」というフォルダを作成して保存されます。
・train-images-idx3-ubyte.gz:トレーニング用データ(60,000枚)
・train-labels-idx1-ubyte.gz:トレーニング用ラベル
・t10k-images-idx3-ubyte.gz:テスト用データ(10,000枚)
・t10k-labels-idx1-ubyte.gz:テスト用ラベル
なおトレーニング用データのうち、検証用に5,000枚使用する。
※read_data_sets()の引数で「validation_size」を指定することで変更可能
計算式の準備
作成する計算式は
y = Wx + b
になります。
データ数は
画像:784 = 28x28 pixel
ラベル:10 = [0, 1, ... , 8, 9]
といった感じです。
import tensorflow as tf
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
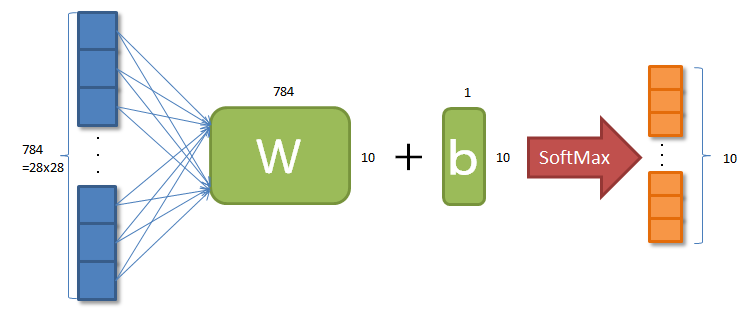
「x」は画像データ、「W」がパラメータ(重み)、「b」がパラメータ(調整値)、「y」がこれらを使った処理って感じでしょうか。
「x」は2次元配列ですが、縦横の2次元ではなく、バッチ数×ピクセル数の2次元になります。
「W」は各ピクセル値をラベルに関連付けする際の重みで、学習しながら調整されていく値になります。
「b」も同様で、学習しながらラベルごとの値を調整するイメージなります。
TensorFlowの型(ノード)には、
・定数(tf.constant)
・変数(tf.Variable)
・プレイスホルダー(tf.placefolder)
などがあります。
この中で「プレイスホルダー」がいまいちピンときませんが、これはとりあえず箱だけ用意して、まだ値は設定していないんですよと理解すればよいかと思います。
今回のケースでは、実際に実行するときに、画像データが入る箱を用意したといった感じになるかと思います。
また「y」に関しては、式を登録するという感覚がいまいちピンとこないのですが、「ノードは処理である」と考えると理解しやすいのかなと思います。
さらに、変数とか配列とか、ノード(=オペレーション)は全部ひっくるめて「テンソル」という概念で考えます。
「テンソル」は、
・次元(Rank)
・形(Shanpe)
・型(Type)
で表現されます。
定数は「次元:0、形:number、型:int8」、2次元配列は「次元:2、形:width,height、型:float64」みたいな感じになります。
式の最後の「softmax」はテンソルの値の合計が1になるようにすることで、各ラベルごとの確率にして出力させます。
最適化
ここでは、パラメータが収束するための仕組みを作成しています。
計算式で求めた値と、ラベルの値とを比較して、差が小さくなるようにしていきます。
最後に誤差逆伝播法でパラメータの調整を行います。
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
「y_」は、各画像ごとのラベルの正解値になります。バッチ数だけため込んで処理しします。
「reduce_mean」のところは交差エントロピーの計算になりますが、ここを深く掘り下げたくないので、そういうもんだと理解します。
「GradientDescentOptimizer()」は誤差逆伝播法の処理を一発で行うしくみで、これもそういうもんだと理解します。
それぞれ、設定するパラメータや式を変えたり、処理自体を変えたりすることで、認識率を上げたりする(チューニング)のですが、ここでは考えません。
※というか、まだそこまで詳しく理解できていません(爆)
学習
いよいよ、学習処理として、今まで設定してきたオペレーションをを実行させます。
セッションを作成し、初期化を行った後、1,000回ループを回します。
各ループでは100個の画像を1かたまり(バッチ)として学習処理を行います。
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
このfor文の書き方に慣れていないのは、私がpython初心者だからでしょうか。TensorFlowのお話とは全く関係ありませんが...
mnistから100枚分のデータを読み込んでいきます。「batch_xs」には100枚の画像データ、「batch_ys」には100枚のラベルが設定されています。
これを最適化処理に渡し、ガリガリ学習を行っていきます。
「sess.run()」がグラフ実行のタイミングです。
評価
最後に、学習した結果、、認識率がどうなったかを表示します。
テスト用のデータを使用し、計算した結果とラベルとを比較し、正解した割合を表示します。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
「equal」のところで正解/不正解を判定する処理を作成します。
さらに「reduce_mean」のところで、正解した割合を計算する処理を作成します。
その後、テスト用データを流し込んで、出てきた結果(正解した割合)を表示します。
学習と評価で「sess.run()」のところを見比べると、似たような記述になっています。引数に処理と入力データ(画像、ラベル)を渡している構造です。
処理は違いますが、ここのタイミングで実行されます。
最後に
「先に処理を作成・登録して、後から実行」は慣れないと違和感があります。
またほとんどの処理や式は関数化されていますので、どれを使えばいいのか、知識が必要になるかもしれません。