背景
私の卒業研究でTesseractを使って手書き文字の認識をさせようとしてます。Tesseractの学習手順が私なりに分かったのでメモ代わりに書き残しておきます。
今回参考にさせていただいた記事は以下となります。
Tesseract 4.1にLSTMを使って手書き文字を再学習させる
この記事の Aki Abekawa さんにはとても感謝しています。Tesseractのwikiを見ても分からなかった私にとってこの記事は本当に貴重なものです。
OS
今回前提としてるOSはUbuntuのUbuntu 18.04.3 LTSです。
Tesseractのwikiを見ると
At time of writing, training only works on Linux. (macOS almost works; it requires minor hacks to the shell scripts to account for the older version of bash it provides and differences in mktemp.) Windows is unknown, but would need msys or Cygwin.
執筆時点では、学習はLinux上のみで動作しますとの事なのでそれに従ってUbuntuにしました。
※裏技的な事として、Windows上にWSLを入れるという方法があります。
・TesseractのLSTM学習をWindows(WSL)上で行う
Tesseractについて
今回使ったTesseractのバージョンは4.1.1-rc2です。(2019年12月20日時点)
ocrd-trainについて
恥ずかしながらTesseractのwikiにある TrainingTesseract 4.00を見ても学習方法がピンと来ませんでした。(原因は私が正確に英語が読めないのと、こういう技術系の記事に慣れていない為です。)
そこでocrd-trainの登場なのです。これを使えば、自分で用意するのはTifとTextファイル形式のデータセットのみとなります。だいぶ作業がシンプルになりますね。
参考:https://github.com/tesseract-ocr/tesstrain/wiki
kmnistについて
kmnistのkはくずし・漢字を意味するみたいですね。くずし文字は2つのデータセットがあって、10種類の文字と49種類の平仮名でデータセットが用意されています。今回は10種類の文字の方を使います。
参考:https://github.com/rois-codh/kmnist#the-dataset
学習手順
さて、学習の事前準備としては以下ステップがあります。
1, Tesseractをインストールする
2, ocrd-trainをインストールする
3, kmnistをインストールする
4, kmnistから一行分のtif画像とテキストファイル(拡張子が.gt.txt)を作成する
5, ocrd-trainに4で作成したデータセットを渡し、jpn_bestを元に再学習させる
また、ocrd-trainで実行する上で都合がよいのでこれらのステップはすべてroot権限で行います。
それでは手順を進めていきます。まず、root権限にならないといけませんね。端末を開いて、
# root権限に移行します
$ sudo su -
パスワードを入力してください。これでroot権限になりました。($マークは入力しないで下さいね^^)
1, Tesseractをインストールする
以下のコマンドを入力して最新版のTesseractをインストールしましょう。
# Ubuntu自体を更新
$ apt update && apt upgrade
# Alexander Pozdnyakov氏のPPA
$ add-apt-repository ppa:alex-p/tesseract-ocr -y && apt update
# Tesseract本体
$ apt install -y tesseract-ocr
# 今回の作業ディレクトリ
$ mkdir ~/tess && cd ~/tess
# tesstrain.shを使用するためTesseractのソースコード
$ git clone --depth 1 https://github.com/tesseract-ocr/tesseract.git
# 全言語の設定ファイル (約232MB)
$ git clone --depth 1 https://github.com/tesseract-ocr/langdata.git
# 環境変数へ既存モデルへのPATHを設定
$ echo "export TESSDATA_PREFIX=/usr/share/tesseract-ocr/4.00/tessdata/" >> ~/.profile && source ~/.profile
# デフォルトで入っているengに加えて、既存モデルjpn_bestをダウンロード
# jpn_vert は縦書用モデルだが jpn, jpn_best 実行時に必要
$ wget https://github.com/tesseract-ocr/tessdata/raw/master/jpn.traineddata -P $TESSDATA_PREFIX
$ wget https://github.com/tesseract-ocr/tessdata_best/raw/master/jpn.traineddata -O $TESSDATA_PREFIX/jpn_best.traineddata
$ wget https://github.com/tesseract-ocr/tessdata_best/raw/master/jpn_vert.traineddata -P $TESSDATA_PREFIX
上記のコマンドで /root/tess ディレクトリが作られて、そこにtesseractの学習に必要なソースコード類がダウンロードされます。また、端末上で $TESSDATA_PREFIX をダウンロードした学習データの保存場所/usr/share/tesseract-ocr/4.00/tessdata/に設定しておきます。
2, ocrd-trainをインストールする
次に、便利なocrd-trainをインストールしていきましょう、現在 /root/tess/ にいるので、そこにocrd-trainをインストールしていきます。
# 必要なライブラリをインストールします
$ apt install -y python python-pip python3-pip imagemagick libsm6 libxext64
# OCR-Dをダウンロードします
$ git clone --depth 1 https://github.com/OCR-D/ocrd-train.git
# jpn_best.traineddataをOCR-D用にコピーします
$ mkdir -p ocrd-train/usr/share/tessdata/
$ cp $TESSDATA_PREFIX/jpn_best.traineddata ocrd-train/usr/share/tessdata/
ついでに学習元データであるjpn_bestも、ocrd-train上に移動させておきました。デフォルトでは学習元データはディレクトリocrd-train/usr/share/tessdata/を参照するようになっているので、自分で作ってそこに置きましょう。
3, kmnistをインストールする
ocrd-trainがインストールできたのであとはデータセットを用意するだけですね。早速崩し文字のデータセットであるkmnistをダウンロードしましょう。(現在位置は/root/tess/です)
# kmnistデータセット用ディレクトリを作成し、そこに移動する
$ mkdir kmnist && cd kmnist
# numpyフォーマットのkmnistをダウンロードする
$ wget http://codh.rois.ac.jp/kmnist/dataset/kmnist/kmnist-train-imgs.npz -O kmnist-train-imgs.npz
$ wget http://codh.rois.ac.jp/kmnist/dataset/kmnist/kmnist-train-labels.npz -O kmnist-train-labels.npz
$ wget http://codh.rois.ac.jp/kmnist/dataset/kmnist/kmnist-test-imgs.npz -O kmnist-test-imgs.npz
$ wget http://codh.rois.ac.jp/kmnist/dataset/kmnist/kmnist-test-labels.npz -O kmnist-test-labels.npz
一応説明しておくと、numpyフォーマットとはpythonのnumpyで扱うことのできる形式の事で、pythonのソースコード上で画像を作成することが来ます。あと、後々必要になるので同じディレクトリ(/root/tess/kuzusi/)上にkmnist_classmap.csvを保存してください。
4, kmnistから一行分のtif画像とテキストファイル(拡張子が.gt.txt)を作成する
さあ、いよいよデータセットの作成ですね。現在、 /root/tess/kmnist/ にいます。ここにTif画像とTextファイルのデータセッ卜を作っていきます。
# データセットの置き場所を作る
$ mkdir data && cd data
# 必要なライブラリをインストールします
$ pip install numpy
$ pip install matplotlib
$ pip install pillow
# numpyフォーマットからデータセットを作成するプログラム
$ touch make_training_dataset.py
$ gedit make_training_dataset.py
これを実行すると、空白のmake_training_dataset.pyが開かれたかと思います。そこに、以下のソースコードをコピーペーストして保存して下さい。
ランダムに文字を選んでデータセットを作るようなプログラムです。
# this code is refered to http://cedro3.com/ai/kmnist-vae/
import numpy as np
import matplotlib.pyplot as plt
import random
import csv
from PIL import Image
# in a training data, the number of line's chars.
line_length = 40
# the number of all of datasets.
all_datasets = 90
# the number of class of char type
class_num = 10
# reading kmnist data
x_train = np.load('../kmnist-train-imgs.npz')['arr_0']
x_test = np.load('../kmnist-test-imgs.npz')['arr_0']
y_train = np.load('../kmnist-train-labels.npz')['arr_0']
y_test = np.load('../kmnist-test-labels.npz')['arr_0']
# make a table of pyplot
# refer to 'https://qiita.com/gaku8/items/90167693f142ebb55a7d#3-subplots%E3%81%A8axxx'
fig,axes = plt.subplots(nrows=1, ncols=line_length, figsize=(12, 12))
plt.subplots_adjust(wspace=0)
# deleting backspace, refer to 'http://kaisk.hatenadiary.com/entry/2014/11/30/163016'
fig.patch.set_alpha(1)
# the indexs of data[*](this 'data' has each class of chars)
# controlling x of data[*][x], adding 1 step by step(form 0)
indexs = [0] * class_num
for r in range(all_datasets):
# to make ***.gt.txt, the contents of text.
texts = []
for c in range(line_length):
# define char_type by extracting value from ramdom.
char_type = random.randint(0, class_num-1)
texts.insert(c, str(char_type))
# y_train is label, and refer to 'https://qiita.com/knqyf263/items/657d5f96cf7540ba59d2#numpy%E3%82%92%E4%BD%BF%E3%81%86%E6%96%B9%E6%B3%95'
# extract elements whose r matchs with y_train(label) from x_train.
data = x_train[y_train==char_type]
# updating 'indexs'
indexs[char_type] = indexs[char_type] + 1
axes[c].axis("off")
axes[c].imshow(255-data[indexs[char_type]], cmap='Greys_r')
# covert 'texts' to Existing char from '../kmnist_classmap.csv'
# preserve 'to_write_texts'
to_write_texts = []
with open('../kmnist_classmap.csv', mode='r') as f:
reader = csv.reader(f)
class_map = [row for row in reader]
for txt in texts:
# serching txt from class_map
for _class in class_map:
if(_class[0] == txt):
to_write_texts.append(_class[2])
# make a ***.git.txt using 'to_write_texts'
with open('kuzusi.' + '{}'.format(str(r)) + '.gt.txt', mode='w') as f:
f.write(''.join(to_write_texts))
# saving ***.tif (at bottom, i cannot avoid to generate unnecessary space)
plt.savefig('kuzusi.' + '{}'.format(str(r)) + '.tif', bbox_inches="tight", pad_inches=0.0)
# by usin PIL method, trimming the unnecessary space in *.tif
# refer to 'https://note.nkmk.me/python-pillow-image-crop-trimming/'
im = Image.open('kuzusi.' + '{}'.format(str(r)) + '.tif')
im_crop = im.crop((28, 1, 963, 30))
im_crop.save('kuzusi.' + '{}'.format(str(r)) + '.tif', quality=100)
データセットを作る上で編集する変数は主に上の方に書いてある2つだと思います。
・line_length:一行あたりの長さ(デフォルトで40文字)
・all_dataset:データセットの総数(デフォルトで90セット)
ここは好きに変えてください。それでは、これを実行してデータセットを作りましょう。
(コメントの英語が稚拙で意味が合ってないかもしれないです。あまり深く考えないようにお願いします)
# データセットを作成する
$ python3 make_training_dataset.py
しばらくすると、dataフォルダ上に0.tifや0.gt.txtなどのファイルがたくさんできていると思います。こいつらがocrd-trainに渡すデータになるわけですね。
5, ocrd-trainに4で作成したデータセットを渡し、jpn_bestを元に再学習させる
手順4でデータセットが作れたと思います。これをocrd-trainに移していきます。移動先は自分でディレクトリを作らなければなりません。場所は /root/tess/ocrd-train/data/ 上に(モデルの名前)-ground-truthのフォルダを作成します。(最近デフォルトがこれに変わったと思います)
今回のモデルの名前はkuzusiにします。つまりkuzusi-ground-truthを作ればよいのです。
# ocrd-trainに(モデルの名前)-ground-truthを作る
$ cd ../../tess/ocrd-train/data
$ mkdir kuzusi-ground-truth
# /root/tess/kuzusi/dataに移動
$ cd && cd tess/kuzusi/data
# Tif画像とTextファイルを全てocrd-trainに移動させる
$ mv *.tif ../../tess/ocrd-train/data/kuzusi-ground-truth
$ mv *.txt ../../tess/ocrd-train/data/kuzusi-ground-truth
これでデータセットの移動が完了しました。
いよいよ学習です!ocrd-trainに移動して実行してみましょう!
# ocrd-trainに移動
$ cd && cd tess/ocrd-train
$ nohup time -f "Run time = %E\n" make training MODEL_NAME=kuzusi START_MODEL=jpn_best >> train.log 2>&1 &
# 実行状況をモニタリングします
$ tail -f train.log
実際は
make training MODEL_NAME=kuzusi START_MODEL=jpn_best
でも動くのですが、処理に時間がかかるので端末を閉じても実行を中断しないようにnohupを使っています。
あと、START_MODEL=jpn_bestが再学習させる対象のデータです。
これで端末上にログがいっぱい出て学習が開始されます。数時間すると学習が終わるのでお目当てだったkuzusuPlus.traineddataが出来上がっているのを確認しましょう。(2019年12月19日時点ではモデル名にPlusがつくそうです)
そうしたらkuzusiPlus.traineddataをtesseractが認識できる場所に移動してあげましょう。
# kuzusiPlus.trainddataをtesseractへ移動
$ cd data/kuzusi
$ cp kuzusiPlus.traineddata $TESSDATA_PREFIX/
これで学習の手順すべてが終わりました。Tesseractを確認してみると、
$ tesseract --list-langs
Error opening data file /usr/share/tesseract-ocr/4.00/tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
List of available languages (3):
jpn_best
kuzusiPlus
osd
とkuzusiPlusをしっかり認識してますね(なんかエラーが出てますが、これは標準のeng.traineddataを入れてあげれば直ります)
認識結果
試しに学習で使ったデータセットからTif画像を引っ張ってきて認識させてみましょう。
/root/tess/ocrd-train/data/kuzusi-ground-truth/ の kuzusi.0.tif を
適当な場所に移動させましょう(デスクトップとかでいいでしょう)画像はこんな感じで
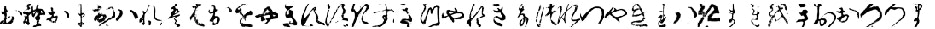
正解のテキストは以下です。
おれおまおはれははおをやきすすきすきつやれきなつれつやきれはきまれをきおおつつま
まず、学習させた物を使ってみると
$ tesseract -l kuzusiPlus kuzusi.0.tif stdout
Failed to load any lstm-specific dictionaries for lang kuzusiPlus!!
Page 1
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 272
お れ お ま お は れ は は お を や き す す き す き つ や れ き な つ れ つ や き れ は き ま れ を き お お つ つ ま
まあ、だいたい認識できてますね。
それじゃあ学習前のjpn_best.traineddataを使ってみると、
$ tesseract -l jpn_best kuzusi.0.tif stdout
Page 1
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 272
か か 姜 か まる ハハ いれ る くる か を 全 き 人 層 する さや きる 休 秘 の や らら お あい 給 ョ 払え ちか の の
崩し文字が漢字と認識されてしまっている部分がありますね。やっぱりちゃんと学習できてるっぽいですね。
以上です。お疲れ様でした。
ちなみに、
Failed to load any lstm-specific dictionaries for lang kuzusPlus!!
について気になる人は、解決法(仮)をまとめてみました。よければ読んで下さい。
ocrd-train(Tesseract)の学習で辞書が見つからない(Failed to load any lstm-specific dictionaries for lang XXX!!)
私自身の投稿がはじめてなので、何か間違っているかもしれないです。
それと、私はtesseractについてあまり理解できていません。
基本的に質問には答えられないです。申し訳ないです。