はじめに
どうもお久しぶりです。今回はTesseractのLSTM学習をWindowsのWSLを使って行おう、という記事を書いてみたいと思います。私は1年前とても苦しんだのですが、Tesseractの学習機能はどうもUbuntuを前提としていて、OSを入れ替えたりデュアルブートにしたりしたりと面倒な事をしていました。しかし、WindowsにはUbuntuのターミナルが入れられるそうで、WSLをインストールすれば可能という事を知りました。
なので、
「Tesseractの学習機能を使いたいけどOS入れ替えとかしたくない。。。」
「どうにかWindows上でできないか」
とか思ってる人向けに記事を書きます。
〇参考
・Windows 10でLinuxを使う(@whim0321様)
・WSLとwindows間のファイル連携(@quzq様)
という記事を参考にさせて頂きました。丁寧な解説ありがとうございます。
WSLの準備
インストール
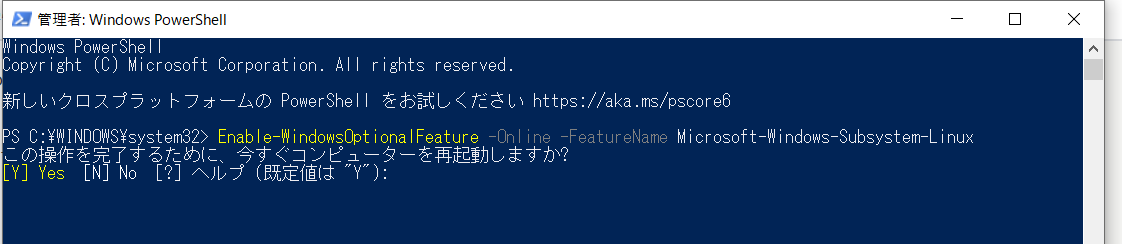
まずWSLの準備をします。PowerShellを”管理者として”開いて、以下のコマンドを入力してください。
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
すると、↓のような画面になるのでYを入力してEnterを押してください。
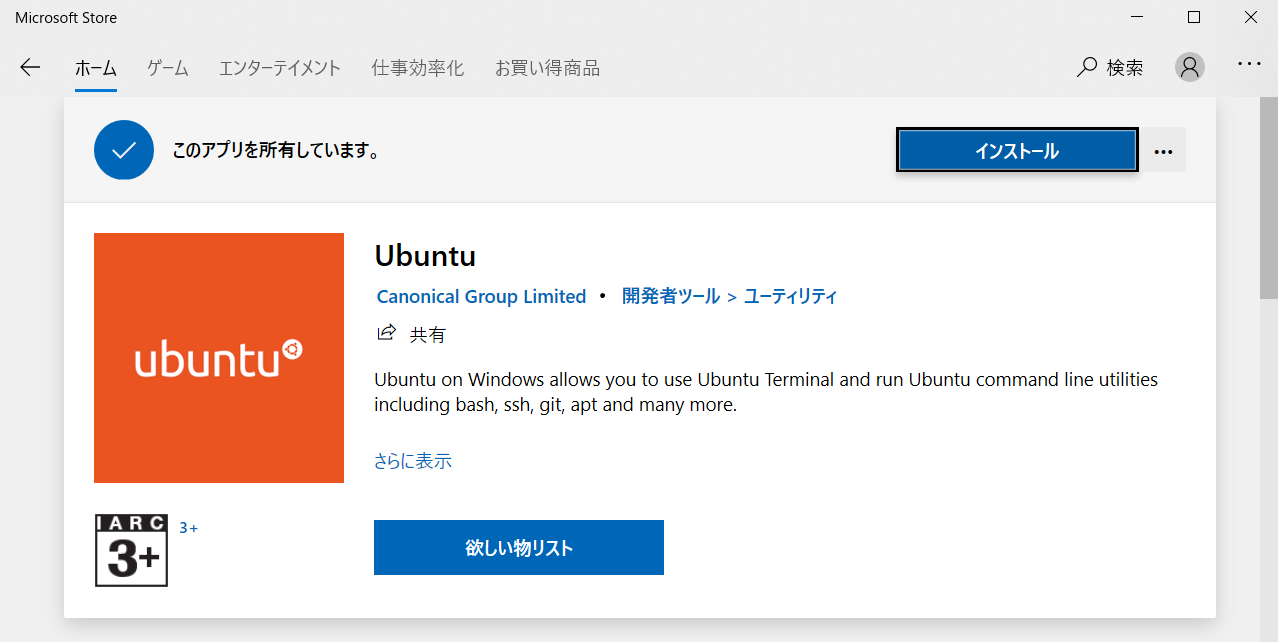
処理が終了したら、Microsoft Storeを開いてUbuntuと検索してください。そしてインストールをクリック。
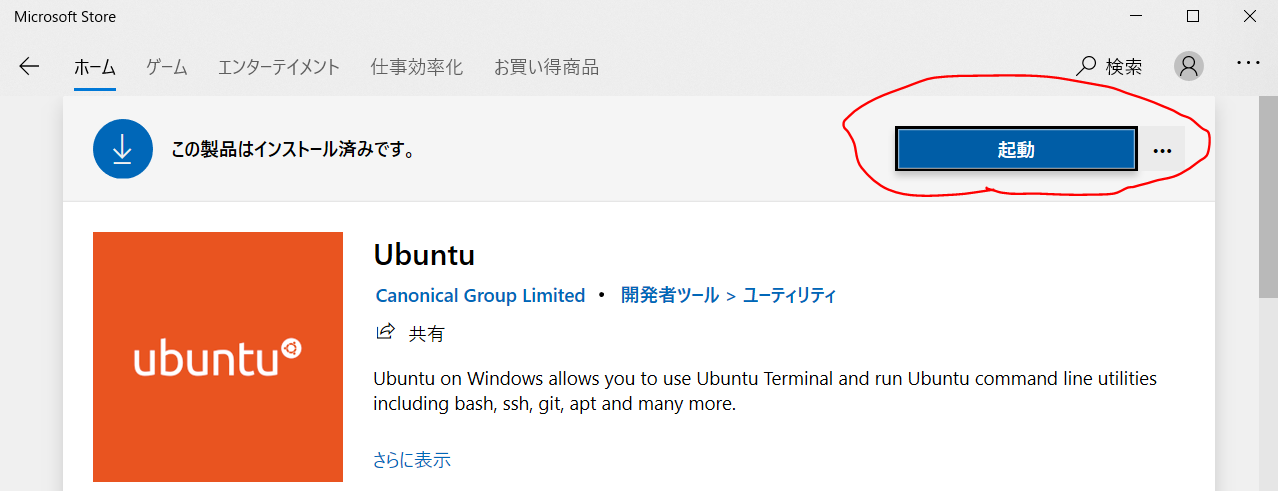
しばらくすると、↓の画面になり起動ボタンが押せるようになるのでクリック。
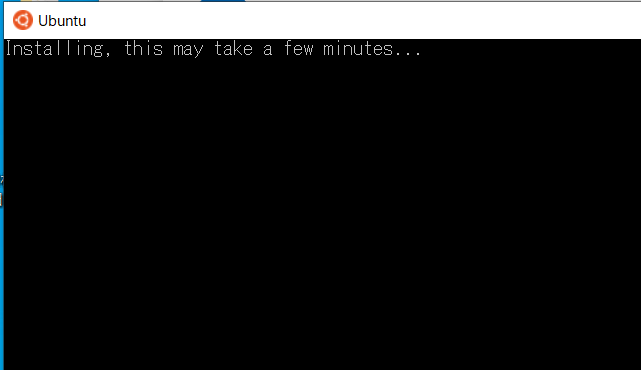
これでUbuntuのターミナルが入りました。最初はInstallの処理を行っているので、しばらく待ちましょう。
しばらくするとユーザー名とパスワードの設定が求められます。適当に決めて入力してください。パスワードは2回聞かれます。
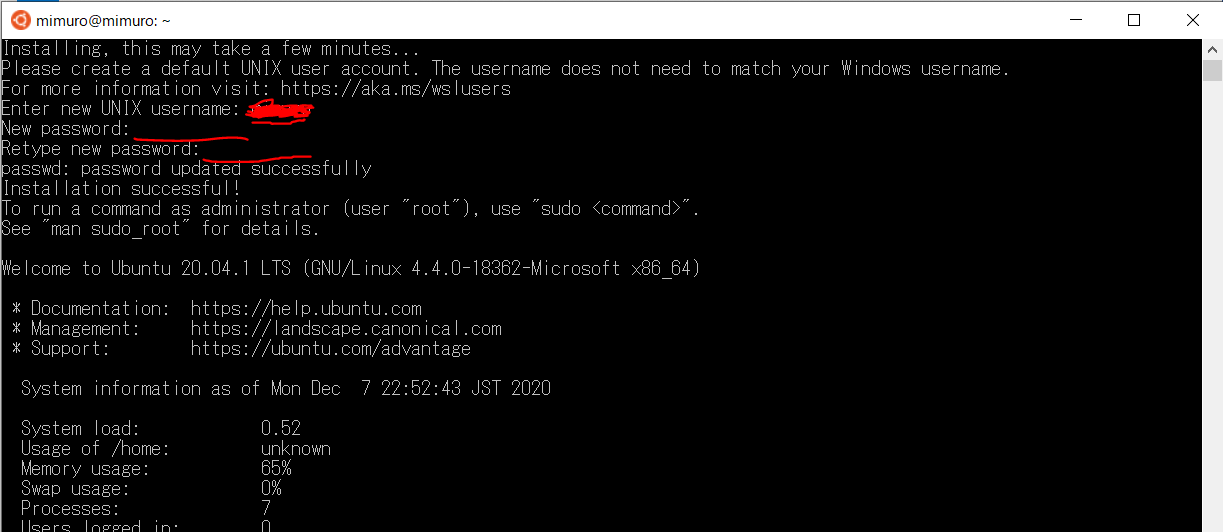
これでインストールは終了なのですが、以下のコマンドを実行して、最新の状態に保ちましょう。(私は結構時間がかかりました。)
sudo apt update
sudo apt upgrade
そして、後に必要になるGitとpythonもインストールしましょう。pythonのインストールは結構時間がかかります。
sudo apt install git
sudo apt install -y python
sudo apt install python3-pip
Windowsのエクスプローラとの連携
先の作業でWSLのインストールが終了しました。しかしターミナル上の操作に限られてしまうのはあまりに不便なので、いつも皆さんが使っているエクスプローラと連携しましょう。簡単です。
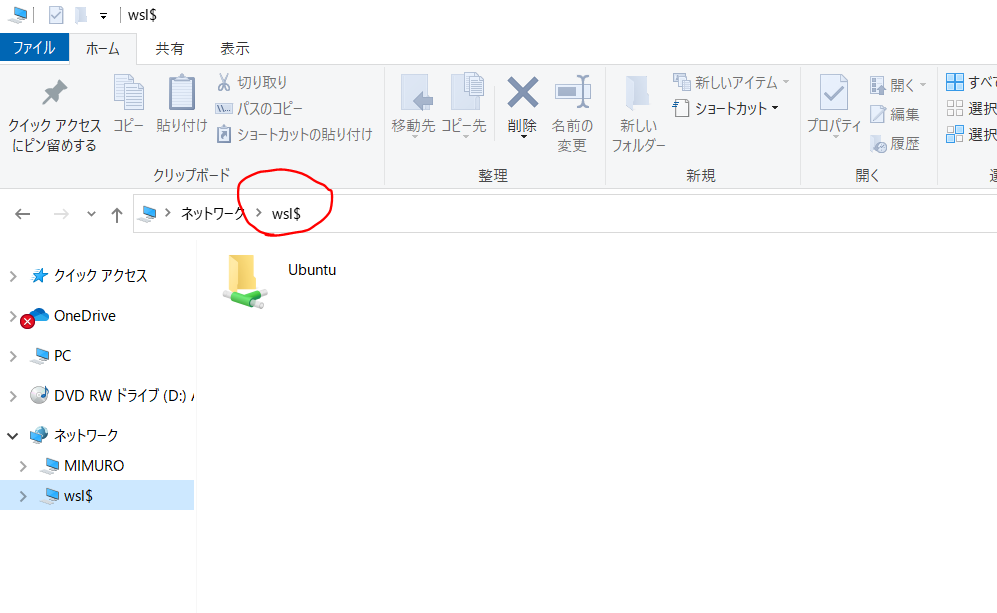
エクスプローラを開いて、パスの欄に\\wsl$と入力すると↓の画面になって、Ubuntuのフォルダがいじれるようになります。適当にスタートメニューに追加とかしておくと作業しやすいです。
ocrd-trainの準備
事前準備
まずUbuntuのターミナル上で以下のコマンドを打ってroot権限になってください。
sudo su -
んで以下のコマンドを入力してください。これを入力しないとNote, selecting 'python-is-python2' instead of 'python'というエラーが出ます。詳しくは以下のURLを見てください。
・https://lornajane.net/posts/2020/the-python-is-python2-package-on-ubuntu-focal-fossa
sudo apt install python-is-python3
そしてここから、ocrd-trainに必要なインストールをしていきます。
# Alexander Pozdnyakov氏のPPA
$ add-apt-repository ppa:alex-p/tesseract-ocr -y && apt update
# Tesseract本体
$ apt install -y tesseract-ocr
# 必要なライブラリをインストールします
$ apt install -y python imagemagick libsm6 libxext64
$ pip3 install numpy matplotlib pillow
ocrd-trainのインストール
これで準備は整いました!最後の仕上げとしてocrd-trainをインストールしていきます。また、ここからはrootディレクトリではなく、ユーザーのディレクトリで作業を行います。rootディレクトリで作業を行ってしまうと、エクスプローラからアクセスできなくなるかも、です。
という訳で、
sudo su "ユーザー名"
でユーザーディレクトリへ移行してください。それで、以下のコマンドで作業用ディレクトリとocrd-trainのcloneをしてください。
# 作業用のディレクトリ
mkdir tess
cd tedd
# ocrd-trainのclone
git clone --depth 1 https://github.com/OCR-D/ocrd-train.git
学習テスト
ここでは学習の動作が出来るかテストします。学習対象の画像はサンプルからたった2枚の画像です。エクスプローラからサンプルデータの解凍をしましょう。エクスプローラからubuntu/home/hogehoge/tess/ocrd-trainへアクセスして
zipファイルのocrd-testset.zipを解凍します。
そしてocrd-train\data\配下にfooとfoo-ground-truthのディレクトリを作成してください。
それで、回答したデータの中から、
・alexis_ruhe01_1852_0035_019.tif
・alexis_ruhe01_1852_0035_019.gt.txt
・alexis_ruhe01_1852_0087_027.tif
・alexis_ruhe01_1852_0087_027.gt.txt
をfoo-ground-truthへコピーします。(サンプルデータの中でもうまく動作しないものがあります。私の環境では、上記のデータでは動作しました)
いよいよです。以下のコマンドを打てば学習データの作成がはじまります。
make training MODEL_NAME=foo
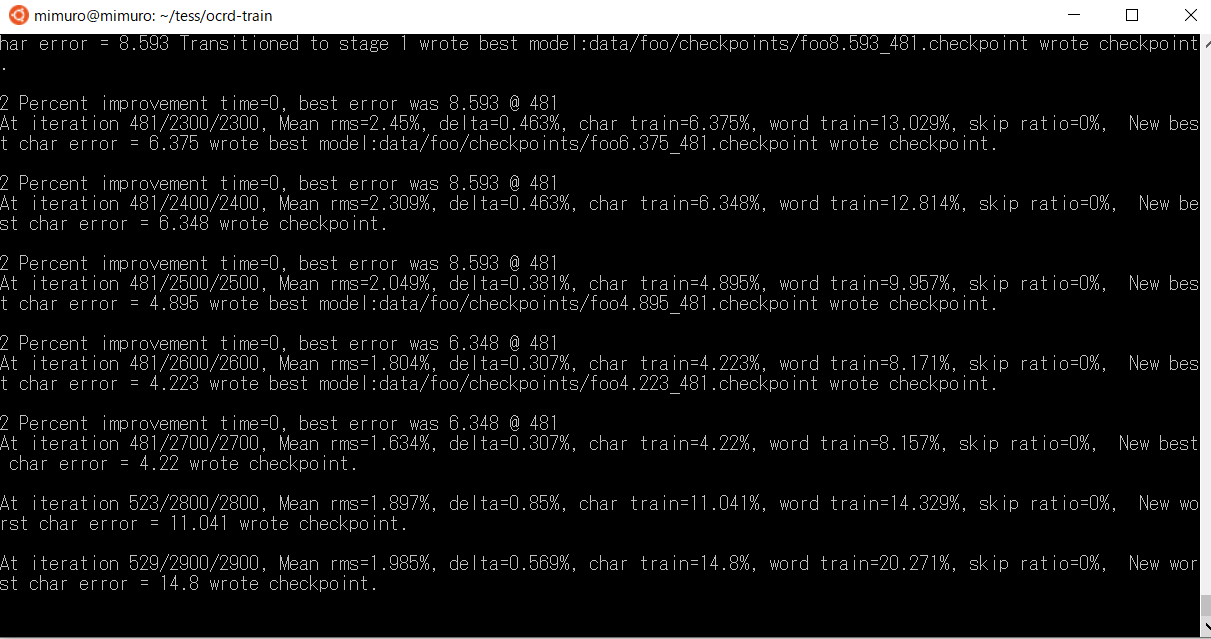
こんな画面が出てくれば、順調に学習が進んでいる証拠です。
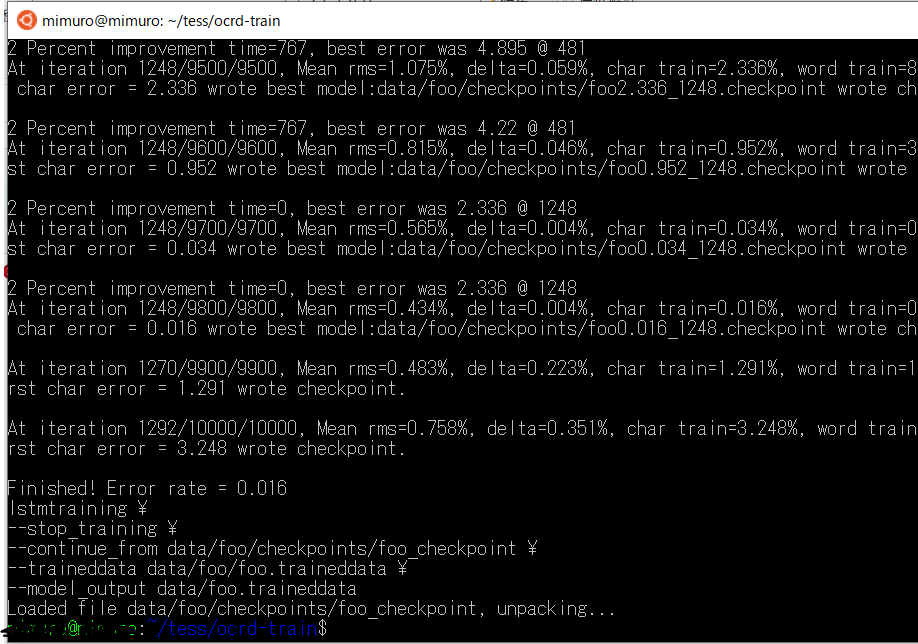
学習が終わるとこんな感じの画面になります。30分ぐらいかかりました。
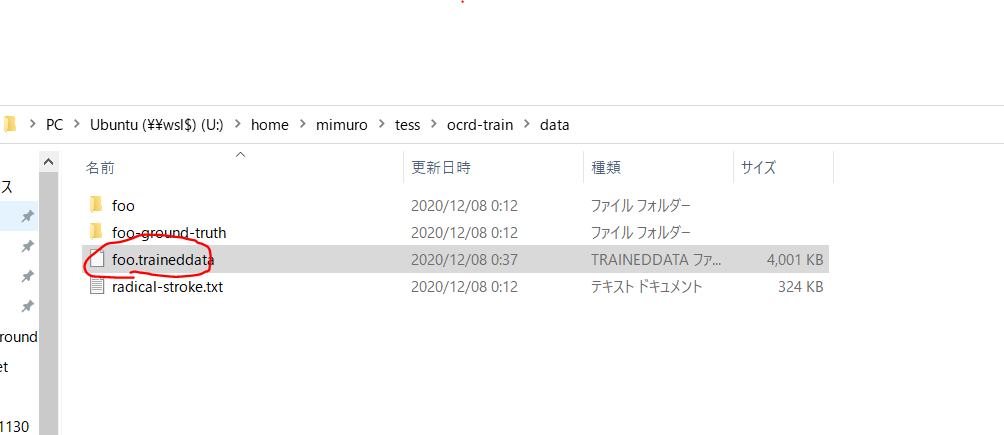
そして、ディレクトリocrd-train\data\配下に作成されたfoo.traineddataが完成品です。
※学習後のデータの出力先には注意してください。
・ocrd-trainので学習データの出力先(Failed to continue from: data/xxx/xxx.lstm)
自分で用意したデータを学習する
みなさんがやりたいのはこれだと思います。これまでの作業でocrd-trainが動作する事は確認できたと思うので、以下のステップを踏んで、オリジナルの学習データを作ってみてください。学習データですので、文章の画像と正解のテキストデータを用意することになります。また、正解のテキスト(手順3)はutf-8で書き込んでください。そうしないと(多分)エラーが出ます。
今回作成するモデルの名前はTRAININGとしていますが、適当に変えて頂いてかまいません。(その場合は手順1と4のTRAININGを適宜変更してください)
1.ocrd-train\data\配下にTRAININGとTRAINING-ground-truthのディレクトリを作成
2.学習対象の画像(1行ごとの文章画像)をファイル名training_image.gitで用意する。(training_imageは適当にしていただいて構いません)
3. 2.の画像に対するテキストをファイル名training_image.gt.txtへ書き込む。(training_imageは学習対象の画像ファイルの拡張子無しの名前の事です)
4. 2.と3.をTRAINING-ground-truthへコピーし、以下のコマンドを実行する。
make training MODEL_NAME=TRAINING
おわりに
久しぶりにTesseractについての記事を書きました。最近研究で使いそうになっているので、やりやすいやり方を探していて、WSL使えばいんじゃね?ってなったので忘れないようにまとめました。リモートでの課題提出も増えTeamsを使う機会が増えた事もあり、なるべくWindows上で済ませたかったのです。
同じことで詰まっている誰かのためになれば幸いです。それでは!!