背景
だたの自分用のメモです。ほんと大したことじゃないですが、丸一日潰した原因になったので記事にまとめておきます。
学生研究の為ですが、Tesseractを手書き文字に対応させようと学習をさせてます(ocrd-trainを使ってます)。今はETL8GとETL9Gの手書き文字データセットを使って学習用データを用意したのですが、この量が多いこと。。。(良い事なのですが)
1行40文字でETL8GとETL9G合わせて大体18000行くらい出来ました。(データはだいたい20GB強)
最初はこの18000行を一気にgound-truthに置いて見たのですが、やはり正常に動かないw
という事で、ground-turthを300行の小分けにして学習させる事にしました。
pythonでmake trainingをそれぞれのground-truthに対し実行していく感じですね。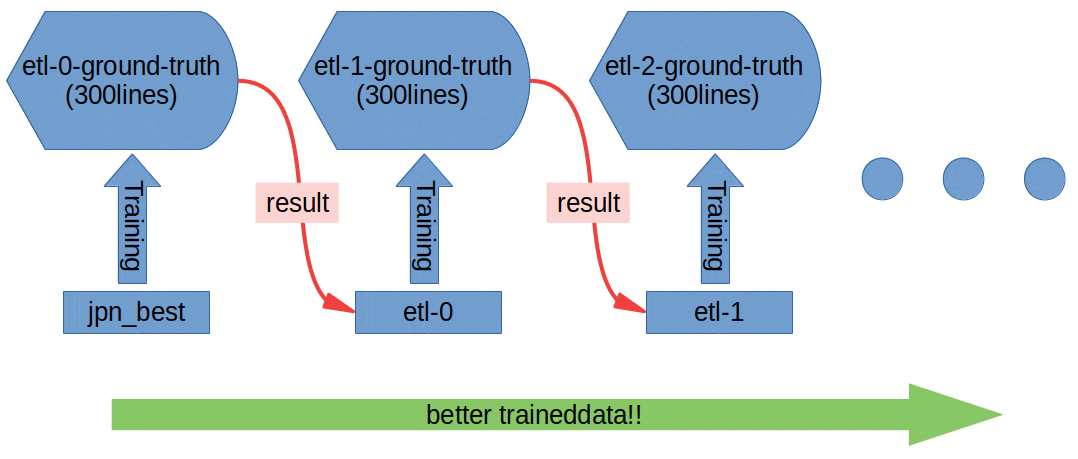
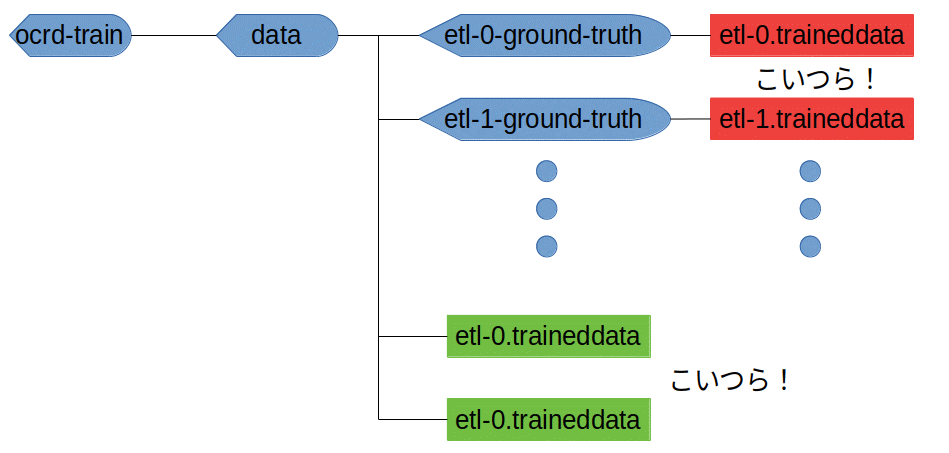
この処理をpythonのos.systemを使って書いていたのですが、途中結果のetl-XXX.traineddataをground-truth内のものを使ってました。下の図で言う赤色のやつです。
するとこんなエラーが出てきて私の2019年最後の日曜日は持ってかれました。
lstmtraining \
--debug_interval 0 \
--traineddata data/elt-1/s.traineddata \
--old_traineddata /root/tess1/ocrd-train/usr/share/tessdata/etl-0.traineddata \
--continue_from data/s/etl-0.lstm \
--model_output data/etl-1/checkpoints/etl-1 \
--train_listfile data/etl-1/list.train \
--eval_listfile data/etl-1/list.eval \
--max_iterations 10000
Failed to continue from: data/etl-0/etl-1.lstm
Makefile:228: recipe for target 'data/etl-1/checkpoints/etl-1_checkpoint' failed
make: *** [data/etl-1/checkpoints/etl-1_checkpoint] Error 1
んーーーー??なんじこりゃ?jpn_bestから1回目の学習はうまく行くんだけど2回目からこればっか。。。
これについて解決した事をまとめます。
原因調査
エラーを読めばだいたい察しはつくかと思いますが、
Failed to continue from: data/etl-0/etl-1.lstm
が原因でしょうね。ocrd-trainでは、学習元のxxx.traineddataを分解して、data/にその名前(xxx)のフォルダを作って格納しています。そして、分解後の名前はmake trainingで指定したモデルの名前になっています。つまり、jpn_best.traineddataを元(START_MODEL)にして、etl-0.traineddata(MODEL_NAME)を作ろうとした場合、
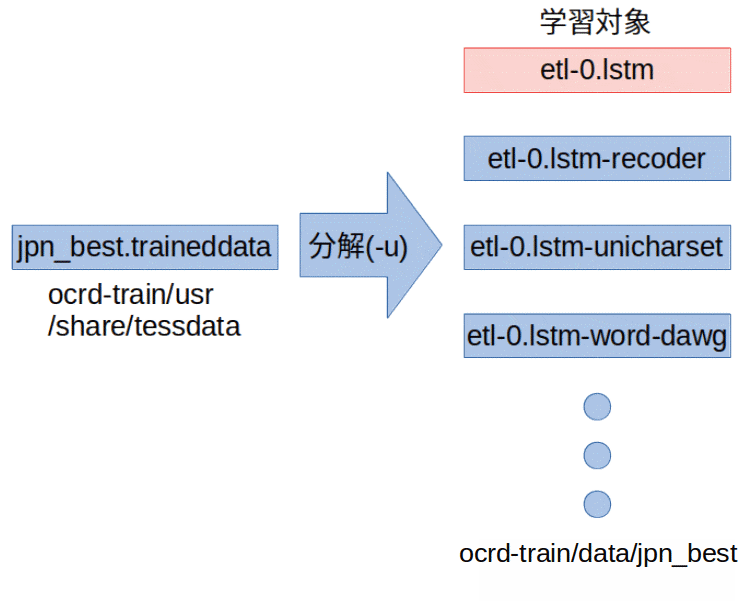
data/jpn_best/etl-0.xxx(xxxは.lstmとか.unicharsetとか.recoderとか)
が作成されるんですね(上の画像は本来そうなるという画像です)。つまり、このエラーは二回目の学習フローで、学習元のetl-0.traineddataからetl-0.lstmを抽出して改名したetl-1.lstmが無えぞという訳ですね。。。
んな訳あるかぁ!lstmファイルって学習後のLSTMの重みやぞ!!!
という訳で、使用した元データのetl-0.traineddataをcombine_tessdata(combine_tessdataのまとめ参照)の-dモードで中身を見てみると、、、
~/tess/ocrd-train/data/etl-0# combine_tessdata -d s.traineddata
Version string:4.1.1-rc2-20-g01fb
21:lstm-unicharset:size=38654, offset=192
22:lstm-recoder:size=10449, offset=38846
23:version:size=18, offset=49295
あれ、、、無い。。。lstmファイルが無い!!!って事はこれは学習後のデータじゃないって事ですね。ちなみに、この元データetl-0.traineddataは下の図で言う赤色のものを使いました。(etl-0フォルダ下にあるから何となくこっちの方がいいかなって。。。)
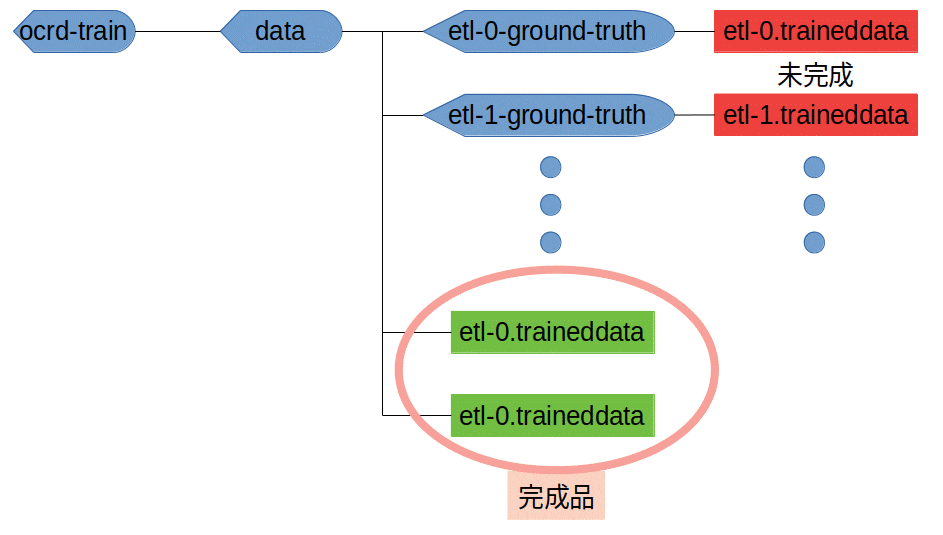
これが間違いでしたね。。。実はocrd-trainで学習した場合の完成データってデフォルトでは/data/直下に置かれることになってます。さっきの図でいう緑です。
という訳で、/data/直下のetl-0.traineddataを見ると、
~/tess/ocrd-train/data# combine_tessdata -d etl-all-0.traineddata
Version string:4.1.1-rc2-20-g01fb
17:lstm:size=12940819, offset=192
21:lstm-unicharset:size=173520, offset=12941011
22:lstm-recoder:size=46804, offset=13114531
23:version:size=18, offset=13161335
lstmありますね!これが完成品なんですねw
これを使うようにパスをちょっと変えたら普通に動きました!なんか単純なミスでがっかりしました。。。
結論
ocrd-trainではデフォルトで作成した学習データをocrd-train/data/直下に置く。
ocrd-train/data/xxx/にあるxxx.traineddataと間違えないように注意しよう!
おわりに
以上です。Tesseractの学習において日本語の解説が少ないと感じたので気になった事はどんどん記事にまとめていこうかと思います。
しかし、このエラーの解決策が今回の記事で解決できるとは限りません。xxx.lstmファイルを然るべき場所に置かなければ解決しないので注意してください。
あくまで、私のためのメモとして書きました。なのでこの記事を読んで何か不具合が起きても責任は取れませんが、誰かの参考程度になればとも思っております。