背景
最近Tesseractの学習を行ってまして、その中でXXX.traineddataについて色々調べる機会が多々ありました。
そのXXX.traineddataを扱う上で良く使うコマンドがcombine_tessdataなのでまとめてみようかと思いました。
また、基本的に以下のwikiをまとめただけなので読める人はこっちを本家様を読んだほうが正確かと思います。
また、この記事は2019年12月25日時点で書かれており、OSはUbuntu18.04の使用を前提としてます。
combine_tessdataとは?
combine_tessdataはXXX.traineddataを分解したりXXX.lstmやXXX.lstm-unicharsetを結合する機能を持っています。
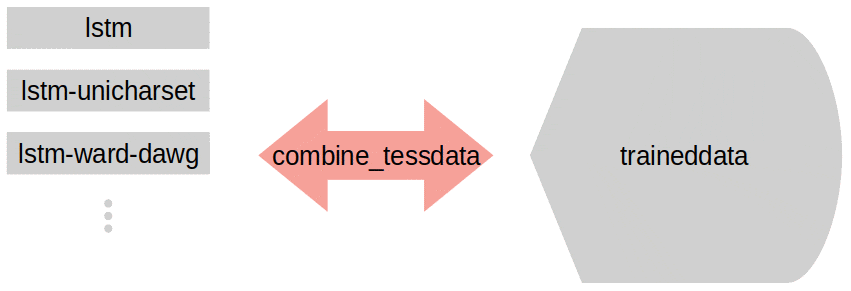
ちなみに、これらのファイルの意味とかについても後でまとめようかと思います。
使い方一覧
今回はcombine_tessdataの紹介なので、とりあえずtesseractが標準で用意しているjpn.traineddataを使います。
・jpn.trainedddata(Data Files for Version 4.00 (November 29, 2016)より)
それじゃ、このjpn.traineddataをデスクトップ上に移しましょう。
中身を見る(-d)
中身を見るのみのコマンドがあります。
combine_tessdata -d (見る対象)
と打ち込むと見る対象(jpn.traineddata)の中身がリストアップされます。実際に打ってみると、
$ combine_tessdata -d jpn.traineddata
Version string:Pre-4.0.0
0:config:size=2573, offset=192
1:unicharset:size=280627, offset=2765
2:unicharambigs:size=4676, offset=283392
3:inttemp:size=30618346, offset=288068
4:pffmtable:size=36561, offset=30906414
5:normproto:size=452735, offset=30942975
6:punc-dawg:size=2602, offset=31395710
7:word-dawg:size=1007922, offset=31398312
8:number-dawg:size=42, offset=32406234
9:freq-dawg:size=1146, offset=32406276
13:shapetable:size=664546, offset=32407422
16:params-model:size=699, offset=33071968
17:lstm:size=10299009, offset=33072667
18:lstm-punc-dawg:size=2602, offset=43371676
19:lstm-word-dawg:size=1005930, offset=43374278
20:lstm-number-dawg:size=50, offset=44380208
23:version:size=9, offset=44380258
これがjpn.traineddataの構成要素なんですね、どうやら3.X系と4.X系のどちらも対応しているみたいですね。
分解編
jpn.traineddataは完成品なので、これを分解してみます。
全部分解する(-u)
とりあえず全部分解するには、
combine_tessdata -u (分解対象) (分解先)
と実行します。分解対象とはjpn.traineddataの事で、分解先は分解後のファイル名(拡張子を抜いた名前まで)を入力します。
分解後のファイル名はjpn_unpackとしましょうか。
$combine_tessdata -u jpn.traineddata jpn_unpack
これでjpn.traineddataの中身が全て分解されましたね。デスクトップ上にはjpn_unpack.xxxのファイルがいっぱいありますね^^
確認してみると、さっき見たjpn.traineddataの構成要素全てが展開されているのが確認できると思います。
一部分解する(-e)
一部分解するには
combine_tessdata -e (分解対象) (取り出すデータ1) (取り出すデータ2) ・・・
と実行します。
$ combine_tessdata -e jpn.traineddata jpn_extra.lstm jpn_extra.unicharset
すると、jpn.traineddataのlstmとunicharsetのみがjpn_extraの名前になって取り出されています。(因みにunicharsetはエディタで開いて見ることができます)
結合編
次は結合していきます。
全部結合する( )
今、デスクトップ上にjpn_extra.lstmとjpn_extra.unicharsetの2つファイルがあります。これを結合するのですが、結合対象の判別にはファイル名を使用しているのに気をつけましょう。コマンドは
combine_tesssdata (結合対象についている名前)
です。やってみると、
$ combine_tessdata jpn_extra
すると、デスクトップ上にjpn_extra.traineddataができてますね。一応中身を見てると、、、
$ combine_tessdata -d jpn_extraVersion string:4.1.1-rc2-17-g6343
Version string:4.1.1-rc2-17-g6343
1:unicharset:size=280627, offset=192
17:lstm:size=10299009, offset=280819
23:version:size=18, offset=10579828
ちゃんとlstmとunicharsetが入ってますね。versionはとりあえず自動で作られるみたいですね。
一部結合する(-o)
まあ、流れ的に一部結合と書きましたが、実質上書き(無いものは追加)ですね。コマンドは
combine_tessdata -o (結合後対象) (結合前データ1) (結合前データ2)・・・
と打ちます。それじゃ、さっきのjpn_extra.traineddataにjpn_unpack.lstm-word-dawgとjpn_unpack.lstmの2つを結合しましょうか。
$ combine_tessdata -o jpn_extra.traineddata jpn_unpack.lstm-word-dawg jpn_unpack.lstm
それじゃ中身を見てみると、
$ combine_tessdata -d jpn_extra.traineddata
Version string:4.1.1-rc2-17-g6343
1:unicharset:size=280627, offset=192
17:lstm:size=10299009, offset=280819
19:lstm-word-dawg:size=1005930, offset=10579828
23:version:size=18, offset=11585758
lstm-word-dawgが追加されいますね。因みに、lstmはjpn_extra.lstmへjpn_unpack.lstmで上書きした事になってます。
容量をコンパクトにする(-c)
どうやらlstmファイルのみ圧縮可能なようです。コマンドは
combine_tessdata -c (圧縮対象)
で、行う前のjpn.traineddataの容量を確認してみると44.4MBで中身は
$ combine_tessdata -d jpn.traineddata
Version string:Pre-4.0.0
0:config:size=2573, offset=192
1:unicharset:size=280627, offset=2765
2:unicharambigs:size=4676, offset=283392
3:inttemp:size=30618346, offset=288068
4:pffmtable:size=36561, offset=30906414
5:normproto:size=452735, offset=30942975
6:punc-dawg:size=2602, offset=31395710
7:word-dawg:size=1007922, offset=31398312
8:number-dawg:size=42, offset=32406234
9:freq-dawg:size=1146, offset=32406276
13:shapetable:size=664546, offset=32407422
16:params-model:size=699, offset=33071968
17:lstm:size=10299009, offset=33072667
18:lstm-punc-dawg:size=2602, offset=43371676
19:lstm-word-dawg:size=1005930, offset=43374278
20:lstm-number-dawg:size=50, offset=44380208
23:version:size=9, offset=44380258
となっていて、lstmはsize=10299009となってますね。これを圧縮すると
$ combine_tessdata -c jpn.traineddata
Version string:Pre-4.0.0
0:config:size=2573, offset=192
1:unicharset:size=280627, offset=2765
2:unicharambigs:size=4676, offset=283392
3:inttemp:size=30618346, offset=288068
4:pffmtable:size=36561, offset=30906414
5:normproto:size=452735, offset=30942975
6:punc-dawg:size=2602, offset=31395710
7:word-dawg:size=1007922, offset=31398312
8:number-dawg:size=42, offset=32406234
9:freq-dawg:size=1146, offset=32406276
13:shapetable:size=664546, offset=32407422
16:params-model:size=699, offset=33071968
17:lstm:size=1577870, offset=33072667
18:lstm-punc-dawg:size=2602, offset=34650537
19:lstm-word-dawg:size=1005930, offset=34653139
20:lstm-number-dawg:size=50, offset=35659069
23:version:size=9, offset=35659119
こうなって、lstmはsize=1577870と、だいたい10分1程度に圧縮されています。
全体としては35.7MBでした。ちょっと少なくなってますね。
認識に影響はすると思いますが、試してないのでよくわからないです。
まとめ
自分用のメモのつもりで書きました。でも誰かの役に立ったら良いなと思います。
また、バージョンが上がると仕様も変わりますと思いますので注意してください。(2019年12月25日時点)
指摘等があったらコメントでお伝えくださるとありがたいです。
それでは以上です。