はじめに
早いもので、PostgreSQL 12の新機能がもう色々と検証されています。
その中で自分的に気になった「COPY FROM」に追加された「WHERE句」を検証してみました。
そもそも「COPY」は外部ファイル(csvファイル)とテーブルのデータをやり取りする機能です。
テーブルを外部ファイルへ吐き出す(COPY TO) or 外部ファイルをテーブルへ取り入れる(COPY FROM)ことができます。
- PostgreSQL 10文書 ~COPY~
https://www.postgresql.jp/document/10/html/sql-copy.html
INSERTやfdwによるやり取りより高速に実行できることが「COPY」の利点です。
「COPY TO」は従来のバージョンでもWHERE句が使用できます。
「COPY FROM」でWHERE句絞り込みができるのはPostgreSQL 12からです。
実際に使ってみよう
今回、検証にはCentOS 7のPostgreSQL 12develを使用しました。
検証のために取り込み先のテーブルと、WHERE句で絞り込まれるcsvファイルを作成します。
=# CREATE TABLE sample1 (id INTEGER, name VARCHAR);
$ cat << EOF > sample1.csv
1,TARO,2003-10-30 11:23:40
2,HANAKO,2012-3-5 9:55:20
3,JON,1999-11-2 15:32:00
4,PETER,1990-7-27 22:31:05
5,MARY,2000-2-16 21:03:45
EOF
$ cat sample1.csv
1,TARO,2003-10-30 11:23:40
2,HANAKO,2012-3-5 9:55:20
3,JON,1999-11-2 15:32:00
4,PETER,1990-7-27 22:31:05
5,MARY,2000-2-16 21:03:45
csvファイルには番号、名前、そして日付データが入っています。
今回は日付データに対してWHERE句による絞り込みが可能か確かめます。
csvファイルの3列目には日付データが入っています。
絞り込み条件として2000年以降のデータのみをCOPYによりテーブルへロードします。
ここで3列目を指定する場合、ロード先のテーブルの列名を使用します。
sample1テーブルの3列目はuptimeなため、WHERE句は以下のようにuptimeを用いて絞り込みをします。
=# COPY sample1 FROM '/var/lib/pgsql/sample1.csv' WITH (FORMAT csv)
WHERE uptime >= '2000-1-1';
COPY 3
=# SELECT * FROM sample1;
id | name | uptime
----+--------+---------------------
1 | TARO | 2003-10-30 11:23:40
2 | HANAKO | 2012-03-05 09:55:20
5 | MARY | 2000-02-16 21:03:45
(3 行)
上記の通り、uptime列が2000/1/1以降の行のみがロードされました。
性能を検証してみた
続いては性能検証です。WHERE句による絞り込みでデータのロードが高速化することを確かめます。
大量行のcsvファイルから特定の行のみをWHERE句でロードする場合と、一括でロードした場合の性能を比較します。
検証準備
検証のためにテストテーブルと大量行のcsvファイルを作成します。
=# CREATE TABLE sample2 (id INTEGER, name VARCHAR);
$ i=5000000
$ paste -d, <(seq $i) <(cat /dev/urandom | tr -dc '[:alnum:]' | fold -w 42 | head -n $i) > sample2.csv
$ cat sample2.csv | head -n 5
1,FzNptDY0VAPR4LQ3cg0QEOmWxg2erBE9Qkx2heAcUn
2,i2KgSLlKw2aQi7MPwBs5xIQ0Ml4Kxh6eNivizLyo7J
3,weNBBXtCwS65xnxyCU7Bb7kNZJT3uR61WDRtQCJOio
4,EYovtxRsqspbaQV78Hyt9KtIaQdImvMT7npeqxhi3G
5,KJ21bDKO2V8544fsWWXcW871eZT0z1DM7T5c7zIPwm
※上記では先頭の5行しか呼び出していませんが、sample2.csvは500万行持つ243MBのcsvファイルです。
※大量行csvファイルの生成方法については補足で説明しています。
検証方法
今回は検証として複数回COPYを実行します。
実行時間を計測するた\timingを使用します。
=# \timing
またテーブルの状態を常に初期状態とするため次のようにDROP TABLE→CREATE TABLEした後に検証用COPY文を実行します。
=# DROP TABLE sample2;
=# CREATE TABLE sample2 (id INTEGER, name VARCHAR);
=# <検証用コピー文>
検証用COPY文
今回は以下の4つのパターンで検証・比較しました。
Ⅰ.一括ロード
WHERE句を付けずにCOPY文を実行します。
=# COPY sample2 FROM '/var/lib/pgsql/sample2.csv' WITH (FORMAT csv);
Ⅱ.WHEREあり一括ロード
WHERE句による負荷が存在するか確かめるため次のWHERE句が全て正となるCOPY文を実行します。
=# COPY sample2 FROM '/var/lib/pgsql/sample2.csv' WITH (FORMAT csv)
WHERE 1 = 1;
Ⅲ.WHEREによる約半分絞り込み
絞り込みの条件式は、"文字列に大文字「A」を含んでいる行"にします。
=# COPY sample2 FROM '/var/lib/pgsql/sample2.csv' WITH (FORMAT csv)
WHERE name LIKE '%A%';
文字列の長さは42文字であり、ランダム文字列には大文字小文字のアルファベット(26×2=52文字)と数字(10文字)が使われています。
よって、ランダム文字列に大文字「A」が含まれる確率は以下の通り計算できます。
(1-(61/62)^42)*100 = 49.4871222172
つまり約50%の確率でランダム文字列は大文字「A」を含むため、250万行のデータが絞り込まれることが予想されます。
実際に今回の検証で大文字「A」が含まれる行は2476443行(=約250万行)でした。
Ⅳ.WHEREによる10行絞り込み
WHERE句による負荷が存在するか確かめるため次のWHERE句が全て正となるCOPY文を実行します。
=# COPY sample2 FROM '/var/lib/pgsql/sample2.csv' WITH (FORMAT csv)
WHERE id <= 10;
検証結果
検証用SQLを10回ずつ実行し結果を見てみます。
- 表
| 実行時間(秒) | 1回目 | 2回目 | 3回目 | 4回目 | 5回目 | 6回目 | 7回目 | 8回目 | 9回目 | 10回目 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Ⅰ.一括ロード | 10.2 | 7.92 | 13.9 | 9.87 | 11.9 | 12.8 | 12.0 | 10.7 | 8.96 | 10.9 | 10.9 |
| Ⅱ.WHEREあり一括ロード | 12.2 | 14.8 | 10.5 | 10.2 | 9.72 | 17.8 | 11.2 | 9.87 | 11.2 | 9.98 | 11.7 |
| Ⅲ.WHEREによる約半分絞り込み | 8.32 | 5.78 | 8.64 | 5.74 | 7.86 | 7.05 | 8.70 | 7.34 | 7.14 | 6.25 | 7.28 |
| Ⅳ.WHEREによる10行絞り込み | 4.60 | 4.46 | 4.03 | 4.22 | 4.05 | 4.05 | 5.02 | 5.39 | 4.34 | 4.62 | 4.48 |
- グラフ
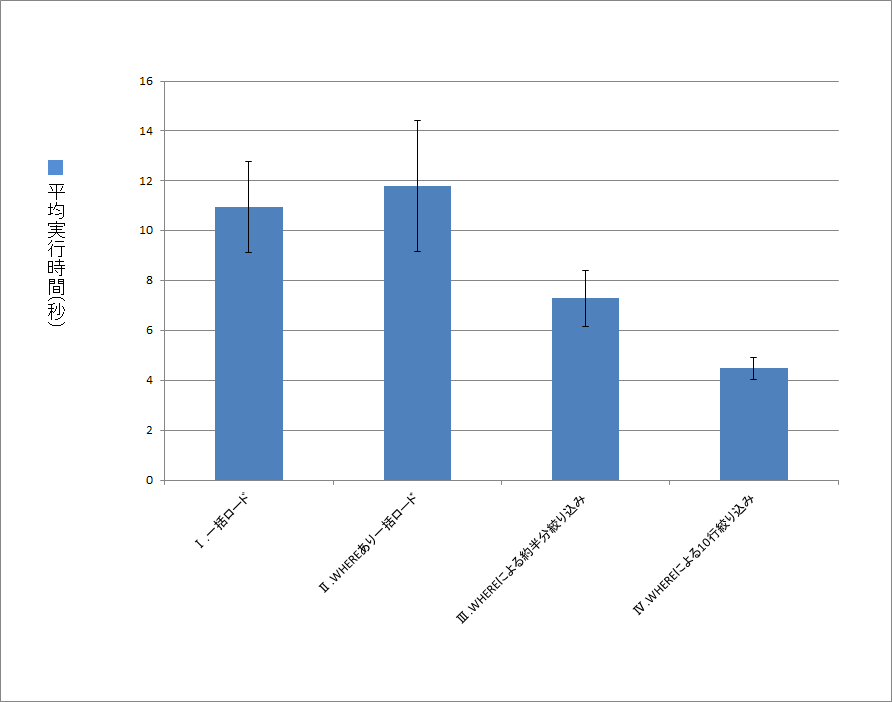
WHERE句の絞り込みによってロードするデータ量が減るほどに、実行時間が少なくなります。
ただし絞り込むために前提として、csvデータを全てバッファ上にあげる必要があためか、データ量と実行時間は単純に比例している訳ではなさそうです。
またⅠとⅡの比較から、WHERE句の付与そのものが大きなボトルネックになるわけではなさそうです。
※ただし今回の検証では実施していませんが、WHERE句が複雑な条件式を持つ場合は影響するかもしれません。
今後、大量のcsvデータから特定の範囲のみをPostgreSQLへロードする時は、WHERE句を使用することで時間短縮ができそうです。
(補足)大量行csvファイルの作り方
ランダムcsvファイル作成に用いている/dev/urandomは、Linuxが所有するランダム文字列を生成する疑似デバイスです。
cat /dev/urandom | tr -dc '[:alnum:]' | fold -w 42 | head -n $i
- /dev/urandom:ランダム文字列を延々に生成する疑似デバイス
- tr -dc 'XXXX':XXXX以外の文字列を削除
- [:alnum:]はアルファベットと数字の正規表現
- tr -dc '[:alnum:]':アルファベットと英数字以外削除
- fold -w X:X文字目で文字列を改行
- head -n X:先頭からX行目までを表示する。
今回はこの/dev/urandomを使い複雑なコマンドで大量行のcsvファイルを作成しています。
複数行のデータを作るなら素直にforを使えばよいのでは? と感じる人もいるかもしれません。
実際に私も最初は単純に次のようなfor文によるcsvファイル作成をしていました。
for ((i=0; i<=5000000; i++));
do
if [ $i -eq 0 ]; then
: > sample2.csv
else
(echo -n $i,;cat /dev/urandom | tr -dc '[:alnum:]' | fold -w 42 | head -n 1) >> sample2.csv;
fi
done
しかし上記の場合、10~30分経っても500万行のcsvファイルが生成されませんでした。
どうやらLinuxコマンドにおいて、for文は毎回指定されたコマンドを実行する関係上、非常に遅くなるそうです。
そのため文章ファイルの読み込み/書き込みにおいては、for文ではなく、grep等をうまく使い、一括でデータを操作することが高速化の道に繋がります。
その結果、下記のようにpasteやseqを用いて高速に大量行のcsvファイルを生成しました。
こちらはfor文と比較して数十秒で処理が完了しています。
$ i=5000000
$ paste -d, <(seq $i) <(cat /dev/urandom | tr -dc '[:alnum:]' | fold -w 42 | head -n $i) > sample2.csv
- paste -dX:複数のファイルを行単位で連結(連結文字は「X」が使われる)
- seq X:1からXまで連番を1行ずつ表示
参考にしたサイト
COPY FROMのWHERE句検証
-
Waiting for PostgreSQL 12 – Allow COPY FROM to filter data using WHERE conditions
https://www.depesz.com/2019/02/03/waiting-for-postgresql-12-allow-copy-from-to-filter-data-using-where-conditions/
COPY FROMのWHERE句について検証したブログです。今回この記事を読んで自分でも色々と試したくなりました。
リンク先には、新機能commitやメーリングリストでの議論のURLも貼られています。
大量行csvファイルの作成方法
-
俺的備忘録 〜なんかいろいろ〜
https://orebibou.com/2016/06/linux%E3%82%B3%E3%83%B3%E3%82%BD%E3%83%BC%E3%83%AB%E4%B8%8A%E3%81%A7%E3%83%A9%E3%83%B3%E3%83%80%E3%83%A0%E3%81%AA%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E3%83%87%E3%83%BC%E3%82%BF%E3%82%92%E4%BD%9C/
テスト用csvファイル作成の参考にさせていただきました。
ぶっちゃけここに載っていたコマンドを改造しただけです。
-
シェルスクリプトを何万倍も遅くしないためには —— ループせずフィルタしよう
https://qiita.com/8x9/items/f1156503694d3683e78d
テスト用csvファイルを作成するときの参考情報に使わせていただきました。
リンク先に記載されている通り、シェルスクリプトでのfor文はパフォーマンス的によくないようです。