🐚 🐚 🐚 🐚
シェルスクリプトは遅すぎて使えない
普通の「速い言語」より何百、いや、何千倍も遅い
他のプログラミング言語を経験してからシェルスクリプトに入門し、このような感想を持つ方も多いのではないでしょうか。
実際、こういったことは往々にして起こり得ますので、「速い言語」を使うべきか否か見極めることは大事だと思います。
しかし、本当にシェルスクリプトというのは、そこまで遅いのでしょうか?
データ量が多い場合は常に最初から「速い言語」で書いた方がよいのでしょうか?
実は、そうとも限りません。
シェルスクリプトにはシェルスクリプトなりの「速い書き方」があります。
この「速い書き方」で処理できる問題に関しては、シェルスクリプトは「速い言語」なのです。
では、「速い書き方」とは何かというと、端的には「たくさん繰り返されるループはシェルスクリプトで記述しない」ことです。
以下でこれを説明します。
例題: カンマ区切りデータの2列目に含まれる小文字の母音("aeiou")を数える
例として、「カンマ区切りデータの2列目に含まれる小文字の母音("aeiou")を数える」という作業を考えます。
カンマ区切りとは、下のような形式です。
abc,atmark,123
def,colon,456
この場合は1行目の2列目が "atmark" で "a" が2つ、2行目の2列目が "colon" で "o" が2つですから、「4」が期待される出力です。
実装: Go言語(比較用)
シェルスクリプトとの比較のために Go言語で書いたものを用意しておきます。
コード
package main
import (
"bufio"
"bytes"
"os"
"strconv"
)
func main() {
scanner := bufio.NewScanner(os.Stdin)
out := bufio.NewWriter(os.Stdout)
defer func() {
out.Flush()
}()
var count int
for scanner.Scan() {
line := scanner.Bytes()
field2 := bytes.Split(line, []byte(","))[1]
for {
i := bytes.IndexAny(field2, "aeiou")
if i == -1 {
break
}
count++
field2 = field2[i+1:]
}
}
out.WriteString(strconv.Itoa(count))
out.WriteByte('\n')
}
実装 v1: 悪い例(シェルスクリプトのループで一行毎に読み込む)
上のGo言語バージョンで、1行毎に読み込んでいるのがこの箇所です。
for scanner.Scan() {
line := scanner.Bytes()
このような1行毎に何かするというありがちな処理には、各言語に色々とイディオムがあるかと思います。
Python ならば、こんな感じでしょうか。
for line in sys.stdin:
さて、こういったイディオムは for や while などのループである事が多いですが、これをそのままシェルスクリプトで行なってしまうと、下のようなコードになります。
# !/bin/sh
# とても悪い例
total=0
while read -r line; do
count=$(printf '%s' "$line" |awk -F, '{ print gsub(/[aeiou]/, "", $2) }')
total=$(( total + count ))
done
echo "$total"
入力の各行を read で 変数 line に読み込み、それを printf で awk に渡し、gsub 関数で母音を数えています。
これは、Go言語バージョンの何千倍も遅いです。
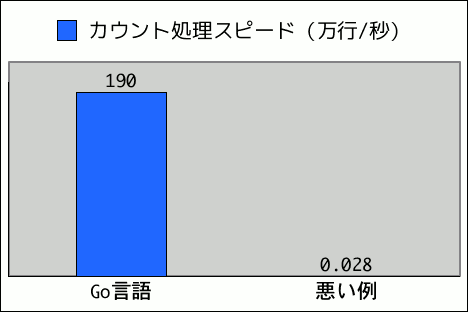
なぜ、ここまで遅いのか。
シェルスクリプトに不慣れな方は awk で正規表現を使っていることなどが気になるかも知れません。
しかし、これはそういったレベルの話では無く、根本的にループ自体がよくありません。
シェルはインタプリタでありコードの解釈〜実行が遅いということもありますし、何より各コマンドがループ毎(この場合は入力の一行毎)に実行されることになるのが致命的です。
つまり、シェルスクリプトの for や while ループで入力の各行を読み込んではいけません。
改善: コマンドの内部で勝手にループしてもらう
シェルスクリプトでループを記述しないならば、各行を読み込む処理はどう行えばよいでしょうか。
これは簡単で、多くのコマンドは何も指定しなくとも入力を行毎に読み込み、各行に処理を加えるようになっています。
コマンドの内部に暗黙のループがある、と考えてもよいでしょう。
例えば grep は、
grep 'foo' data.txt
のように使います。
これで全ての行を処理でき、なおかつ grep コマンドが起動するのは一度で済みます。
シェルスクリプトでループし、
# 行数分 grep が起動するので、とても遅い
while read -r line; do
printf '%s' "$line" |grep 'foo'
done <data.txt
のように書く必要は無いわけです。
実装 v2: awk(シェルスクリプトからループを無くして awk に任せる)
awk も入力を行毎に読み込んで各行を処理してくれますから、上の例題に戻り、ループを取り除いてみます。
# !/bin/sh
awk -F, '{total += gsub(/[aeiou]/, "", $2)} END{print total}'
合計を出力しているのは、END{print total} の部分です。
END が付いていますから、ここは行毎ではなく、最後に一回だけ実行されます。

悪い例から3千倍程度高速化され、実用可能なレベルになりました。
改善: コマンドをパイプでつなぐ
さて、ループが無くなり各コマンドが一度しか実行されなくなると、シェル変数に状態を保存したり、それを経由して値を受け渡したりが出来なくなります。
上のように、awk しか使わないなら awk の変数もありますし問題になりませんが、他のコマンドは使えないのでしょうか?
速いシェルスクリプトとはAwkスクリプトのことなのでしょうか?
そうではありません。
多くのコマンドが入力を標準入力から受け取り、出力を標準出力に渡すことが出来ます。
こういったコマンドを「フィルタコマンド」、「フィルタとして動作するコマンド」などと呼びます。
これにより、シェルスクリプトでは変数を用意して値をやりとりしなくとも、コマンドをパイプでつなぐことでデータの受け渡しができます。
実装 v3: cut + awk(列の切り出しを cut に任せる)
では、入力の2列目を切り出す処理を cut に任せてみます。
cut から awk へのデータの受け渡しをパイプで行ないます。
# !/bin/sh
cut -d, -f2 |awk '{total += gsub(/[aeiou]/, "")} END{print total}'
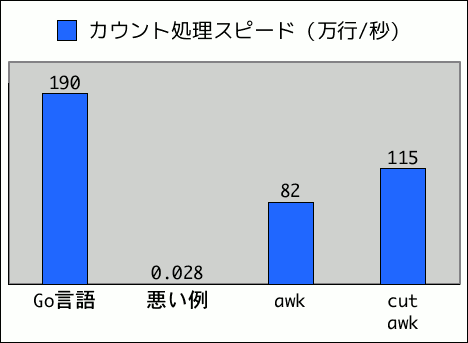
awk だけのバージョンから4割ほど速くなっています。
起動されるコマンドが増え、しかもそれらがパイプで通信していることを考えると速くなったのを意外に思われるかも知れませんが、以下の理由でよくあることです。
- 特定の処理専門のコマンドは、その処理に関して最適化されている
- コマンドが並列で実行され、マルチコアを生かせる
比較グラフの処理スピードはマルチコアのマシンで計測していますので、両方の効果が表われています。
実装 v4: cut + tr + awk(カウント対象文字の抽出を tr に任せる)
使うコマンドが増えても必ずしも遅くならず、むしろ速くなりそうですので、母音の抽出に tr を使ってみます。
# !/bin/sh
cut -d, -f2 |tr -dc 'aeiou\n' |awk '{total += length()} END{print total}'
tr -dc で指定した文字以外を削除しています。
awk が入力を行区切りで受け取るので、改行は残します。
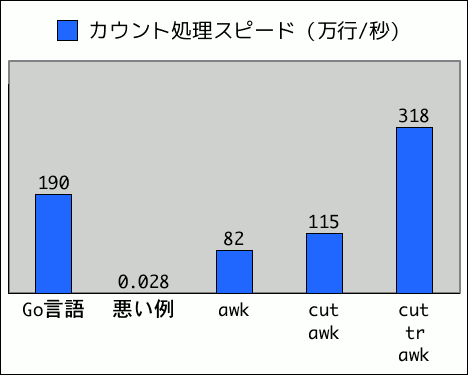
前バージョンから2.7倍ほど高速になり、Go言語バージョンを超えました。
実装 v5: cut + tr + wc(文字のカウントを wc に任せる)
今や、awk が行なっているのは文字のカウントだけです。
これには wc が適任ですので置き換えます。
# !/bin/sh
cut -d, -f2 |tr -dc 'aeiou' |wc -c
wc -c は改行も数えますので、tr の段階で忘れずに削除しておきます。
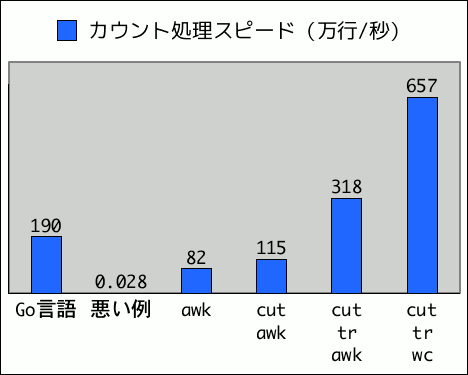
さらに倍以上の高速化で、最終的にGo言語バージョンよりも3.4倍程度速くなりました。
適当に
最初の実装と最後の実装には、2万3千倍以上の速度差があります。
うっかりと他の言語の感覚で、「まず一行ずつ読み込んで……」と丁寧なループを書いていると、ちょろっと書いたワンライナーより何万倍も遅くなってしまうのがシェルスクリプトなのです。
適当にやりましょう。
この記事のライセンス

この記事はCC BY-SA 4.0(クリエイティブ・コモンズ 表示 4.0 継承 国際 ライセンス)の元で公開します。