タイトルは石見舞菜香風にしてみた。
JPEG画像は、工夫せずにトリミングなどの加工を行うと、再圧縮が発生して画像が劣化してしまう。
しかし、対応したソフトウエアを用いることで、再圧縮を回避して画像を劣化させず加工することができる。
既存のソフトウェアを用いた加工
無劣化でのJPEG画像の加工ができるソフトウェアには、たとえば以下のものがある。
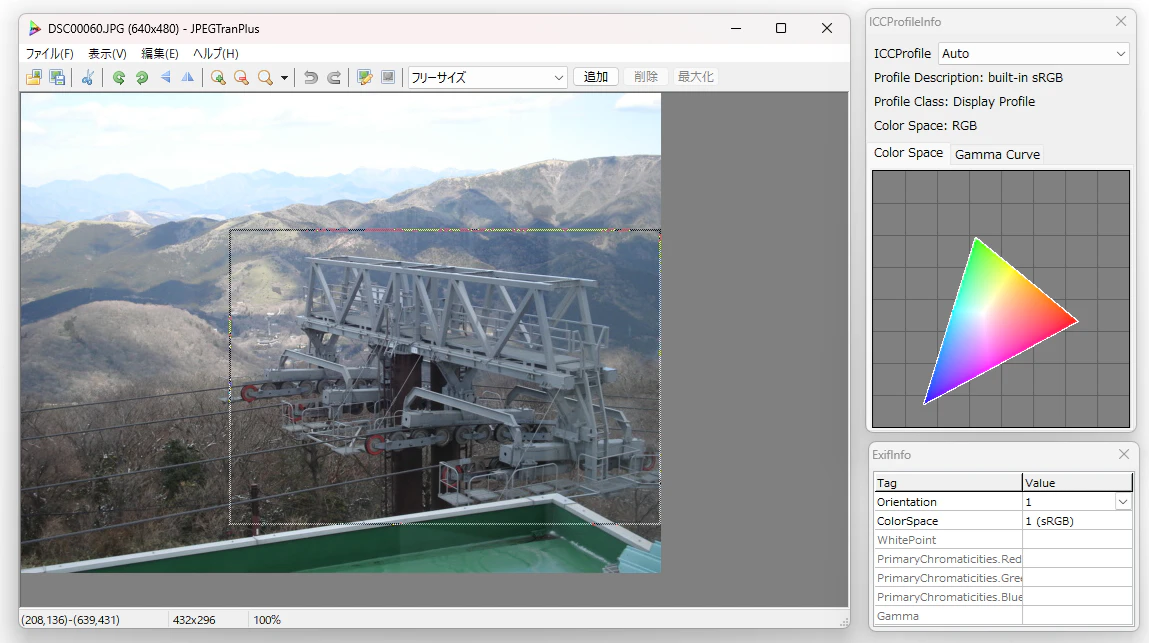
回転・反転・トリミング:JPEGTranPlus
画像の90度回転・左右反転・上下反転ができる。
また、マウスで範囲を選択してのトリミングもできる。
範囲を選択する際、選択中の座標 (範囲) とサイズがステータスバーに表示される。
座標は左上が (0, 0) である。
一度選択した後、選択範囲の端をドラッグすることで選択範囲を調整できる。
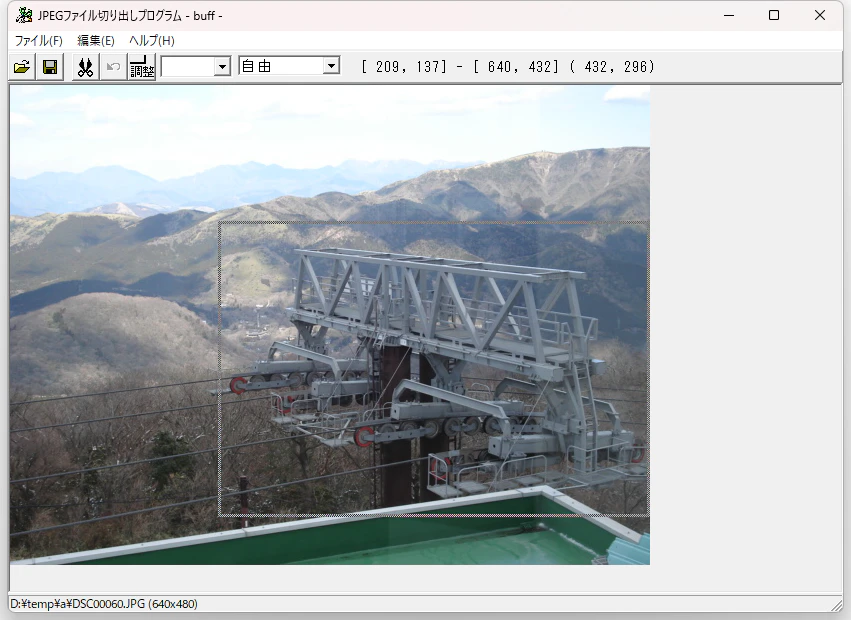
トリミング:buff
マウスで範囲を指定して、画像のトリミングができる。
範囲を選択すると、選択中の座標 (範囲) とサイズが画面右上に表示される。
座標は左上が (1, 1) である。
一度選択した後、選択範囲の端をドラッグすることで選択範囲を調整できる。
JPEGTranPlus ではトリミングに加えて回転や反転ができるが、buff はトリミングのみである。(回転は同シリーズの別のソフトウェアでできるらしい)
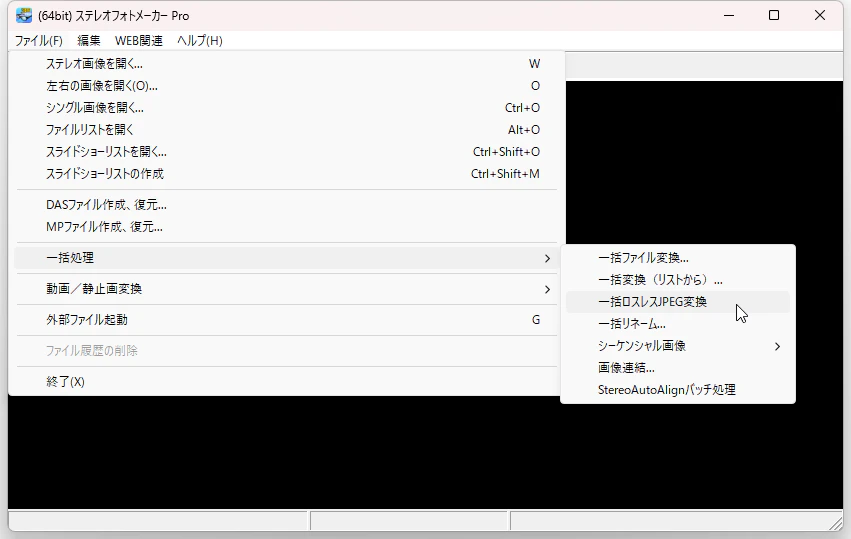
結合:ステレオフォトメーカー
StereoPhoto Maker
結合機能の説明:File/Multi Rename
メインの機能は様々な形式の立体視用データを作成することのようだが、JPEG画像を無劣化で結合する機能もある。
「ファイル → 一括処理 → 一括ロスレスJPEG変換」メニューで、この機能を呼び出すことができる。
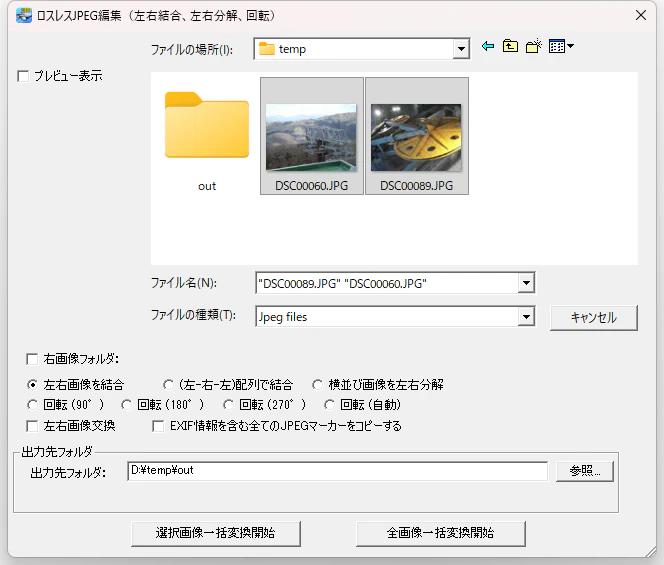
機能の画面を開いたら、まず結合する画像2枚を選択する。
そして、出力先フォルダを設定して、「選択画像一括変換開始」ボタンを押す。
すると、選択した画像が横並びで結合された画像が設定したフォルダに保存される。
保存する際のファイル名は、結合する最初の画像のファイル名となる。
結合の順番が期待と異なる場合は、「左右画像交換」にチェックを入れることで修正できる。
ただし、このソフトウェアには以下の制約があるようである。
- 画像を上下に結合できない (左右にしか結合できない)
- サイズが異なる画像を結合する場合、小さい方に合わせてトリミングしてから結合する (サイズが異なる画像をそのまま結合できない)
たとえば、「2枚の写真を、間に小さいスペーサを挟んで縦に結合する」場合、画像の回転やトリミングを行えるソフトウェアと組み合わせ、以下の手順によりできると思われる。
- 結合する写真とスペーサを、それぞれ左に90度回転した画像を用意する
- 回転したスペーサに余計な部分を足し、結合する写真以上のサイズにする
- 単色の場合、最初から写真のサイズ以上で作るとよい
- デザインがある場合、回転したスペーサ同士を左右に結合し、その結果同志をさらに左右に結合し……のようにして倍々で増やしていくとよさそう
- それぞれの回転した写真の右側に、結合する写真以上のサイズにしたスペーサを結合する
- このとき、スペーサの方が大きい場合は写真のサイズに切られるはずである
- 後で結合した際に上になる写真に結合したスペーサが切られるのを防ぐため、下になる写真にもスペーサを結合しておく
- 上になる写真の結合結果をトリミングし、スペーサを最終的に欲しいサイズにする
- トリミング結果と、下になる写真の結合結果を結合する
- 下になる写真の結合結果は、ここではトリミングしておかなくてよい
- この結合結果をトリミングし、下のスペーサを消す。さらに、右に90度回転する
加工を行うソフトウェアの開発を目指す
JPEG画像は、8×8のブロック単位で圧縮されることが知られている。
そのため、この「8×8のブロック」のデータを何らかの方法で取り出し、欲しい部分のデータのみを配置しなおすことで、無劣化でのトリミングや結合を行うことができると推測できる。
以下の操作は、単純にブロックのデータを再配置するだけでは行うことができず、データの加工が必要になると思われる。
- 画像の回転・反転
- 量子化テーブルが異なる画像の結合
JPEGファイルに関する資料
- JPEG画像の「中身」は一体どうなっているのか? - GIGAZINE
- JPEG画像の中をちょっとだけのぞいてみる #画像 - Qiita
- JPG ファイルフォーマット
- formats/image/jpeg.md at master · corkami/formats · GitHub
調査用のJPEGファイルの用意
構造をパースして圧縮データやその他のデータにたどり着く方法は後々調べるとして、今回は圧縮データの中身の調査を試みた。
調査を行うため、以下の方法でサンプルとなるJPEG画像を用意した。
- ペイントを用いて、8×8などの小さい画像を用意し、PNG形式で保存する
- 保存した画像を ImageMagick で変換する
- ペイントで、同じ画像をJPEG形式で保存する
ペイントで最初からJPEG形式で保存してしまうと、画像が劣化してしまい、ペイントと ImageMagick で同じデータをエンコードすることができなくなる。
たとえば、以下の画像を作成した。
| 内容 | ペイント | ImageMagick |
|---|---|---|
| 白1色 8×8 |  |
 |
| 緑1色 8×8 |  |
 |
| 白背景、左上に黒い点 8×8 |  |
 |
| 白背景、左上に黒い点がある 8×8のブロックを3個並べる |
 |
 |
| 緑背景、左上に黒い点がある 8×8のブロックを3個並べる |
 |
 |
ペイントで作成した画像では、ハフマン符号テーブルが長く、長いエンコードが使われていそうなため、エンコードされたデータの発見に役立つことが期待できる。
一方、ImageMagick で作成した画像では、ハフマン符号テーブルが比較的短く、最低限のデータが格納されていると思われる。
エンコード元の画像が同じでも、エンコードされた画像が同じとは限らず、同じデータが格納されていることは期待できない。
構成要素の数の観察
白と黒のみが使われた画像を ImageMagick でエンコードすると、構成要素の数は1個となり、グレイスケールで記録されていると推測できる。
一方、緑を用いたり、ペイントでエンコードした場合は、構成要素の数は3個となり、カラーで記録されていると推測できる。
ハフマン符号テーブルの観察
たとえば、ペイントで作成した「緑背景、左上に黒い点がある8×8のブロックを3個並べる」の画像のハフマン符号テーブルの一つは、以下のようになっていた。(TSXBIN で観察)
101 ★DHT[0] FF C4
103 SizeOfThis[0] 00 1F
105 Th 00
106 DCHaffman[0] 00 01 05 01 01 01 01 01 01 00 00 00 00 00 00 00
116 DCHaffman[16] 00 01 02 03 04 05 06 07 08 09 0A 0B
前述の GIGAZINE に載っている内容を参照すると、これは以下の情報を表しているようである。
- 2ビットのコード1個:
01 - 3ビットのコード5個:
02 03 04 05 06 - 4ビットのコード1個:
07 - 5ビットのコード1個:
08 - 6ビットのコード1個:
09 - 7ビットのコード1個:
0A - 8ビットのコード1個:
0B
ここのコードとして記録されているデータが符号のデータだとすると、どうにもハフマン符号の性質と合わなそうである。
よって、これは「それぞれの長さのコードで、以下のデータを表す」という意味だと推測できる。
符号の長さのみを記録したハフマン符号といえば、deflate で使われていた。
PNGのデコーダ実装を目指す (2) zlib (deflate) 圧縮データ #PNG - Qiita
ここで用いられているのも、似た技術である可能性が考えられる。
仮に同様の技術だとして、記録されているコードを前から順に割り当てると、以下のような木になる。
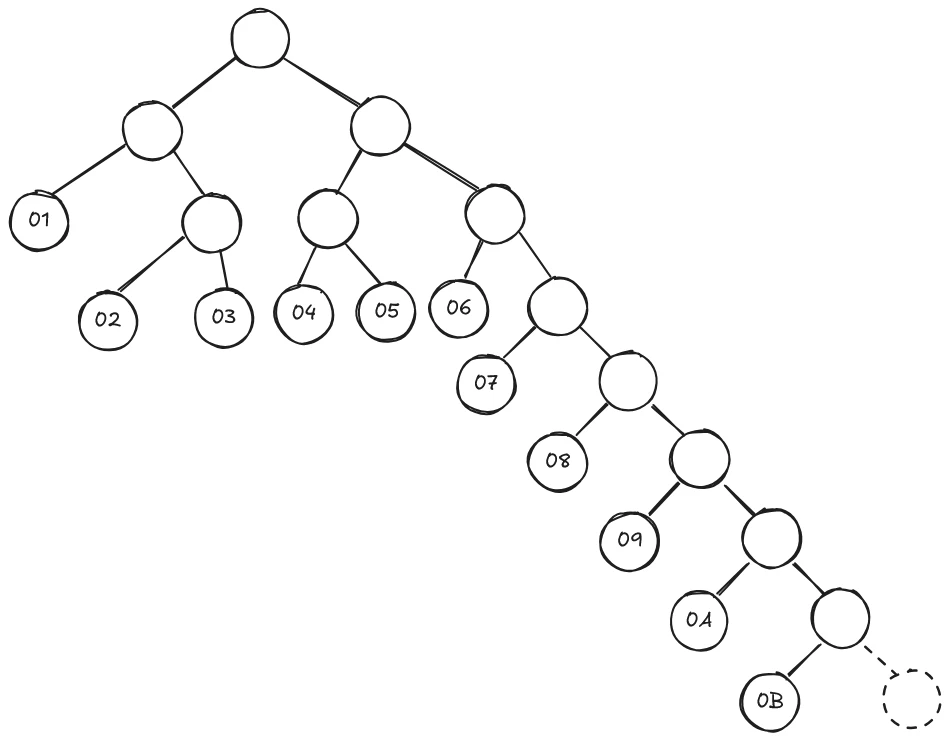
これを見ると、右に行き続けた際 (符号 11111111…) に、データが割り当てられていない部分に行ってしまうことがわかる。
ここは、データの終端などの特別な意味を持っているかもしれない。
圧縮データの観察
同じ、ペイントで作成した「緑背景、左上に黒い点がある8×8のブロックを3個並べる」の画像の圧縮データは、以下である。
2BF 圧縮データ(164B)[0] F4 FD 17 45 B3 F0 DE 8D 69 A7 69 D6 96 D6 1A 7D
2CF 圧縮データ(164B)[16] 84 29 6D 6B 6B 6D 12 C5 0D B4 48 A1 52 34 45 00
2DF 圧縮データ(164B)[32] 2A AA 80 00 00 00 00 02 8D 17 45 B3 F0 DE 8D 69
2EF 圧縮データ(164B)[48] A7 69 D6 96 D6 1A 7D 84 29 6D 6B 6B 6D 12 C5 0D
2FF 圧縮データ(164B)[64] B4 48 A1 52 34 45 00 2A AA 80 00 00 00 00 02 8A
30F 圧縮データ(164B)[80] 2B FC B2 75 24 EF 77 BE AF CD F7 FC 4F F1 5A 55
31F 圧縮データ(164B)[96] 67 2B F3 36 EE EE FC DF 77 E7 AB FB C3 45 D1 6C
32F 圧縮データ(164B)[112] FC 37 A3 5A 69 DA 75 A5 B5 86 9F 61 0A 5B 5A DA
33F 圧縮データ(164B)[128] DB 44 B1 43 6D 12 28 54 8D 11 40 0A AA A0 00 00
34F 圧縮データ(164B)[144] 00 00 00 A2 8A 2A 65 27 26 E5 27 76 C5 29 39 37
35F 圧縮データ(164B)[160] 29 3B B6 7F
同じ8×8のブロックを3個並べたので、ブロック単位で格納されているならば同じデータが3個あることが期待できると考えた。
そこで、これを CyberChef を用いてビット列に変換した。
Find / Replace, From Hex, To Binary - CyberChef
すると、以下のように同じデータが3個所に格納されていたが、その他のデータも格納されていた。
111101001111 未解明データ1
11010001011101000101101100111111000011011110100011010110100110100111011010011101 一致データ
01101001011011010110000110100111110110000100001010010110110101101011011010110110
11010001001011000101000011011011010001001000101000010101001000110100010001010000
000000101010101010101000000000000000000000000000000000000000000000101000
11010001011101000101101100111111000011011110100011010110100110100111011010011101 一致データ
01101001011011010110000110100111110110000100001010010110110101101011011010110110
11010001001011000101000011011011010001001000101000010101001000110100010001010000
000000101010101010101000000000000000000000000000000000000000000000101000
10100010101111111100101100100111010100100100111011110111011110111110101011111100 未解明データ2
11011111011111111100010011111111000101011010010101010110011100101011111100110011
01101110111011101110111111001101111101110111111001111010101111111011110000
11010001011101000101101100111111000011011110100011010110100110100111011010011101 一致データ
01101001011011010110000110100111110110000100001010010110110101101011011010110110
11010001001011000101000011011011010001001000101000010101001000110100010001010000
000000101010101010101000000000000000000000000000000000000000000000101000
10100010100010101001100101001001110010011011100101001001110111011011000101001010 未解明データ3
01001110010011011100101001001110111011011001111111
エンコードされた画像をよく見ると、そもそも3個の8×8のブロックの画像は同じになっておらず、微妙な違いがあった。
そのため、格納されているデータも似る可能性はあっても、完全に一致はしないと思われる。
また、処理を追加し、各バイトのビット列としての解釈を反転してみた。
Find / Replace, 5 more - CyberChef
すると、反転しないときに見られたような、3個の長いブロックの一致は見られなかった。
よって、各バイトは反転せず、MSBからLSBに向かって読むと推測できる。
このデータでは現れていないが、圧縮データ内にバイト 0xff が現れる際は、後ろに 0x00 を追加して 0xff 0x00 で表すらしい。
また、0xff の後ろに 0xd0 ~ 0xd7 がある場合は、restart marker である。
JPEGファイルの終端は、0xff 0xd9 で表す。
まとめ
今回推測したこと
- ハフマン符号は、deflate で用いられているのと似た技術で、長さの表から符号 (木) を構築して用いる
- 長さの表から得られるハフマン符号の木にはデータに割り当てられない部分が存在し、終端などの特殊なデータを表す可能性が考えられる
- 圧縮データは、各ブロックを表すデータを並べて格納する
- 圧縮データ内の各バイトは、MSBからLSBに向かって読む
これらはあくまで推測であり、正しいと確定していない。
今後調査したい内容
- ハフマン符号テーブルは「DC」と「AC」の2種類があるが、圧縮データ内でどのように使い分けられているか?
- 複数の構成要素がある場合、圧縮データ内でどのように並ぶか?
- ハフマン符号の木のデータに割り当てられない部分の使い方は?
- 圧縮データ内に、ハフマン符号で表されていないヘッダ・フッタなどはあるか?
- restart marker の意味・扱い方は?
おわりに
JPEGファイルの無劣化での加工を行うことができるとするソフトウェアをいくつか紹介し、これらを用いて2個の写真を細いスペーサを挟んで結合する方法を考えた。
また、JPEGファイルの無劣化での加工の実装を目指し、小さいJPEGファイルを用意して圧縮データの構造の観察を試みた。