前回の記事
画像を貼ったPDFファイルを作る #PDF出力 - Qiita
では、基本的なPDFファイルの構造 (作り方)、およびPDFへのラスター画像の貼り方を確認した。
今回は、PDFにラスター画像を貼る際に役立つ、前回扱わなかった機能を確認する。
参考資料
仕様書
PDFの仕様書は、以下で公開されている。(PDFファイル)
Document management — Portable document format — Part 1: PDF 1.7
冒頭と末尾をざっと確認した限りでは、「いかなる部分もコピーしてはならない」などのような制限は無さそうで、通常の著作物と同様に扱えそうである。
以降、この記事で「仕様書」といえばこれを指す。
その他の参考資料
-
PDF by Hand - Kobu.Com
- 前回の記事でも参照した。基本的なPDFの作成方法の参考になる
-
PDF Tools Online - Validate PDF
- PDFの記述が正しいかをチェックできる。ただしもうすぐサ終?
-
Convert PDF to PNG for free: PDF to PNG converter | Acrobat
- PDFを画像に変換できる。他のコンバータでは変換できてしまうPDFでも白紙が出力されることがあり、PDFの誤りに気付くための一助になりうる
ストリームに対するフィルタ
ストリーム (画像のデータ本体などのバイナリデータ) は、そのままバイナリを埋め込んで表現することもできるが、フィルタを用いて表現することもできる。
フィルタは、仕様書の 7.4 Filters で定義され、ストリームをデコードする方法を記述する。
/Filter/FlateDecode
フィルタは1個のストリームに対し複数使用することもでき、この場合配列 (フィルタの列を [] で囲んだもの) で表す。
/Filter[/ASCII85Decode/FlateDecode]
デコードする方法を記述するので、配列の中身はエンコード時に行った操作の逆順で記述する。
たとえば、以下のフィルタが使用できる。
| フィルタ | 意味 |
|---|---|
/ASCIIHexDecode |
十六進文字列で記述されたデータをデコードする (CyberChef の From Hex に近い) |
/ASCII85Decode |
Base85 で記述されたデータをデコードする (CyberChef の From Base85 に近い) |
/FlateDecode |
zlib/deflate 圧縮されたデータを展開する (CyberChef の Zlib Inflate) |
/DCTDecode |
JPEG 画像をデコードする (JPEG baseline 形式、PDF 1.3 以降ではプログレッシブも可) |
/ASCIIHexDecode でデコードされるデータ (エンコードされたデータ) では、十六進文字列の後ろにデータの終端を表す > をつける。
/ASCII85Decode でデコードされるデータ (エンコードされたデータ) では、Base85 エンコードした文字列の後ろにデータの終端を表す ~> をつける。
なお、データの最初には、<~ などの余計な文字列はつけない。
画像の回転 (変換行列)
PDFに画像を貼る際には、変換行列 (transformation matrices) を用いて位置やサイズを指定する。
前回の記事ではおまじない的に位置とサイズの指定方法を確認したが、今回は変換行列の指定による効果をより詳しく確認し、画像を回転させて貼れるようにする。
基本形
変換行列の値をいじって画像にどのような影響が出るかを調べる前に、まずは基本の形を用意する。
%PDF-1.2
1 0 obj
<</Type/XObject/Subtype/Image/Width 64/Height 64/BitsPerComponent 8/Length 262
/ColorSpace/DeviceRGB/Filter[/ASCII85Decode/FlateDecode]
>>
stream
Gb"0P;%CGs#_:kTh4o6OB@7UV"PL)9TC+(T0W?B@"JLn<@Q[.rr&iA,r^-tjBF7"PSVkBf;L
mg!'F=JTIRrSp1FN%Cp]$bU?2VhBkPL279>CH6rU&H[qXs1+Y@#%nrVH3Qf<8PrIf9-9?PTb
!hWMg/Vu@8`:CYi=HYSQGpAZN80:r">Sa6\)4+E-4lYleV1OiTSrrr,"ml/tiCq@@kV*NnPP
n^J$?VFnf^V7oSOhV&`heml.Nt(X=mtS$a"rAB,ci~>
endstream
endobj
2 0 obj
<<
/Font <<>>
/XObject<</Image 1 0 R>>
/ProcSet[/PDF/ImageC]
>>
endobj
3 0 obj
<</Length 275>>
stream
q
42.51968503937021 0 0 42.51968503937021 65.19685039370069 14.173228346456694 cm
/DeviceRGB CS 0.01 w 0.75 0.75 0.75 SC
0 0 m 0 3 l 3 3 l 3 0 l 0 0 l
1 0 m 1 3 l 2 0 m 2 3 l
0 1 m 3 1 l 0 2 m 3 2 l
S
q
1.000000 0.000000 0.000000 1.000000 1.000000 1.000000 cm
/Image Do
Q
Q
endstream
endobj
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding padding padding padding
%
4 0 obj
<</Type/Page/Parent 5 0 R/Contents 3 0 R>>
endobj
5 0 obj
<<
/Type/Pages
/Resources 2 0 R
/MediaBox[0 0 257.952755905512 155.905511811024]
/Count 1
/Kids[4 0 R]
>>
endobj
6 0 obj
<</Type/Catalog/Pages 5 0 R>>
endobj
7 0 obj
<<
/Title (image test)
>>
endobj
xref
0 8
0000000000 65535 f
0000000010 00000 n
0000000445 00000 n
0000000525 00000 n
0000001000 00000 n
0000001059 00000 n
0000001181 00000 n
0000001227 00000 n
trailer
<<
/Root 6 0 R
/Info 7 0 R
/Size 8
>>
startxref
1269
%%EOF
オブジェクト1では、前章で紹介したフィルタを用い、画像データを定義している。
オブジェクト3では、グリッドを描画し、その中央部に画像を描画している。
このとき、数値を変えてもデータの長さに影響が出ないよう、桁数を多めに確保した。
オブジェクト3の後ろにはコメント (仕様書の 7.2.3 Comments) によるパディングを用意し、オブジェクト3を書き換えても他のオブジェクトの位置をずらさなくてすむようにした。
その他の部分の詳細は、前回の記事を参考にしてほしい。
改行コードはLFである。(CRLFを用いるとバイト数が変わり、オブジェクトの位置がずれてしまう)
グリッドの描画のため、以下の描画コマンドを用いた。
| コマンド | 意味 |
|---|---|
/DeviceRGB CS |
線の描画に用いる色空間を DeviceRGB に設定する |
0.01 w |
描画に用いる線の太さを 0.01 に設定する |
0.75 0.75 0.75 SC |
描画に用いる線の色を明るい灰色に設定する |
<x> <y> m |
パスの描画位置を (x, y) に移動する |
<x> <y> l |
現在の描画位置から (x, y) に線を引くパスを追加する |
S |
現在のパスに沿って線を描画する |
このサンプルを
PDF から PNG に変換
で画像に変換すると、以下の画像が得られた。
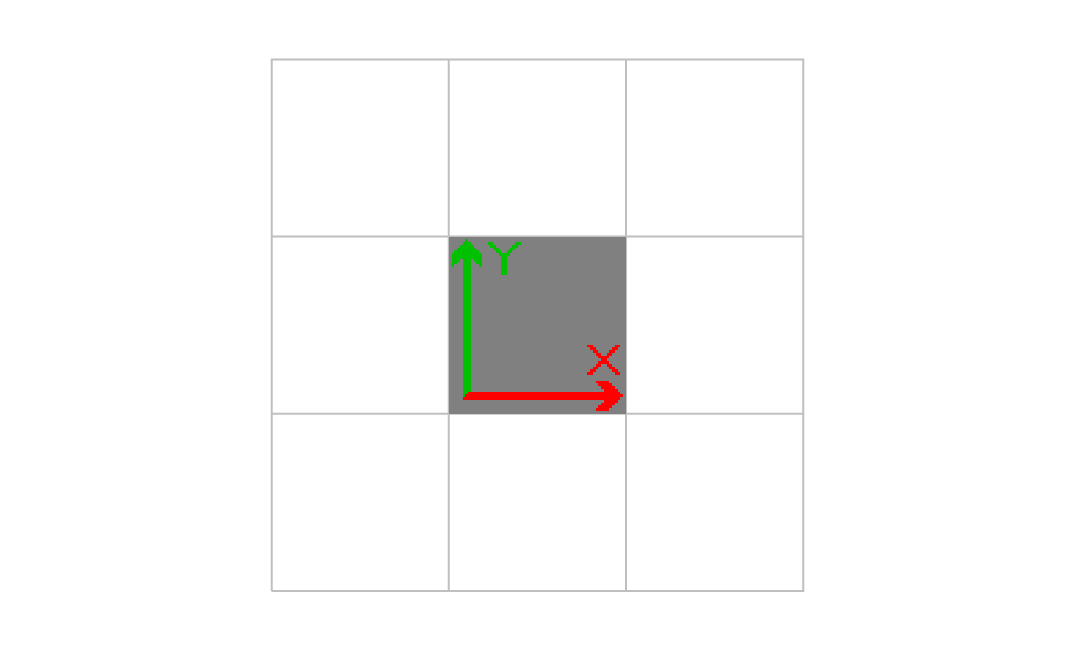
変換行列の値の変化による影響
上記サンプルで、画像を描画する位置を指定している
1.000000 0.000000 0.000000 1.000000 1.000000 1.000000 cm
の部分のそれぞれの値を 0.5 ずつ増やし、その影響をみてみる。
1番目の値
1.500000 0.000000 0.000000 1.000000 1.000000 1.000000 cm
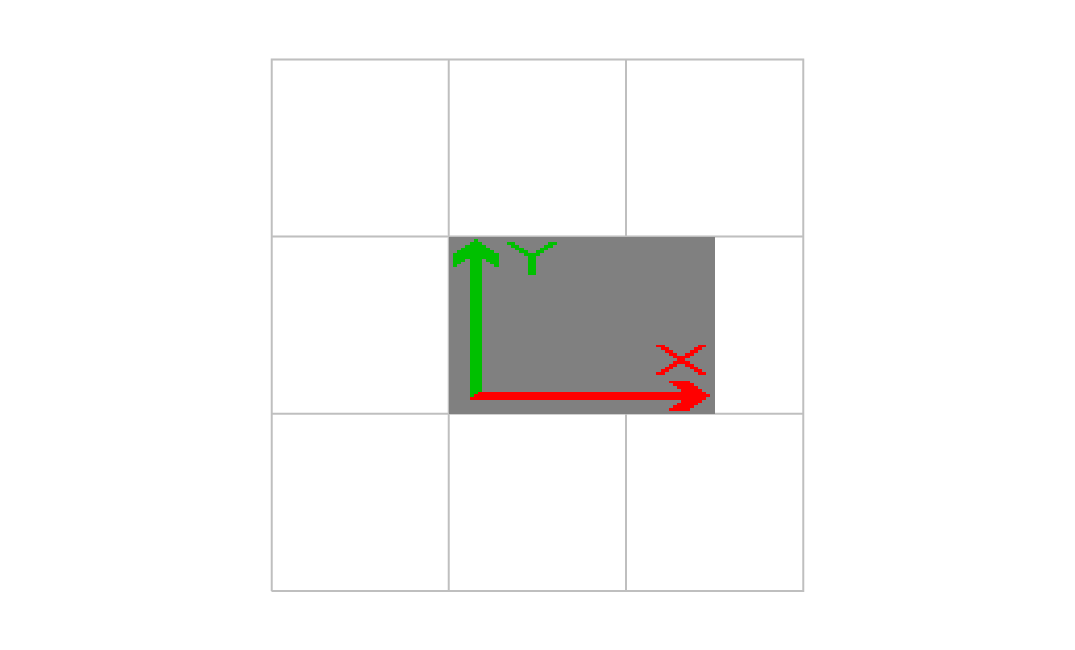
画像が右に伸びた。
2番目の値
1.000000 0.500000 0.000000 1.000000 1.000000 1.000000 cm
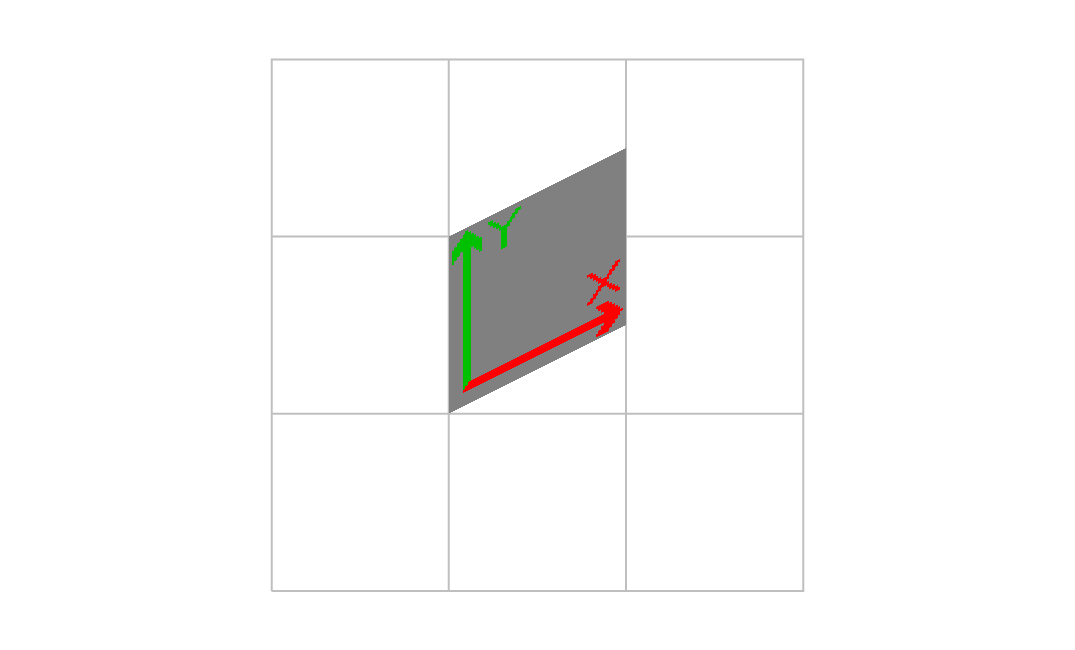
画像が右に進むにしたがって、上にずれた。
3番目の値
1.000000 0.000000 0.500000 1.000000 1.000000 1.000000 cm
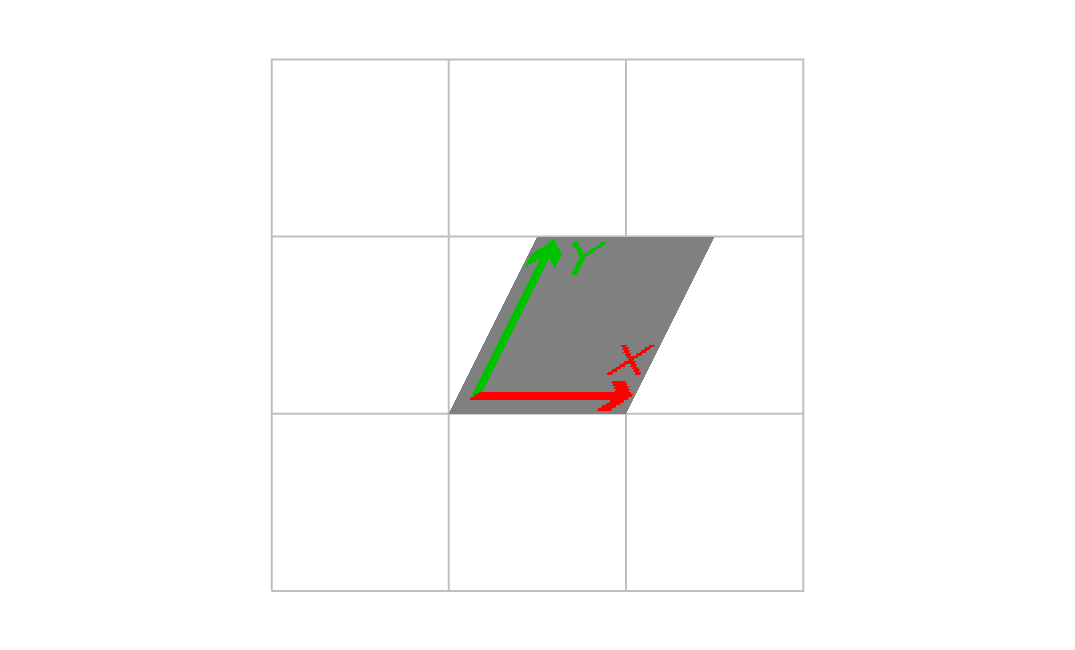
画像が上に進むにしたがって、右にずれた。
4番目の値
1.000000 0.000000 0.000000 1.500000 1.000000 1.000000 cm
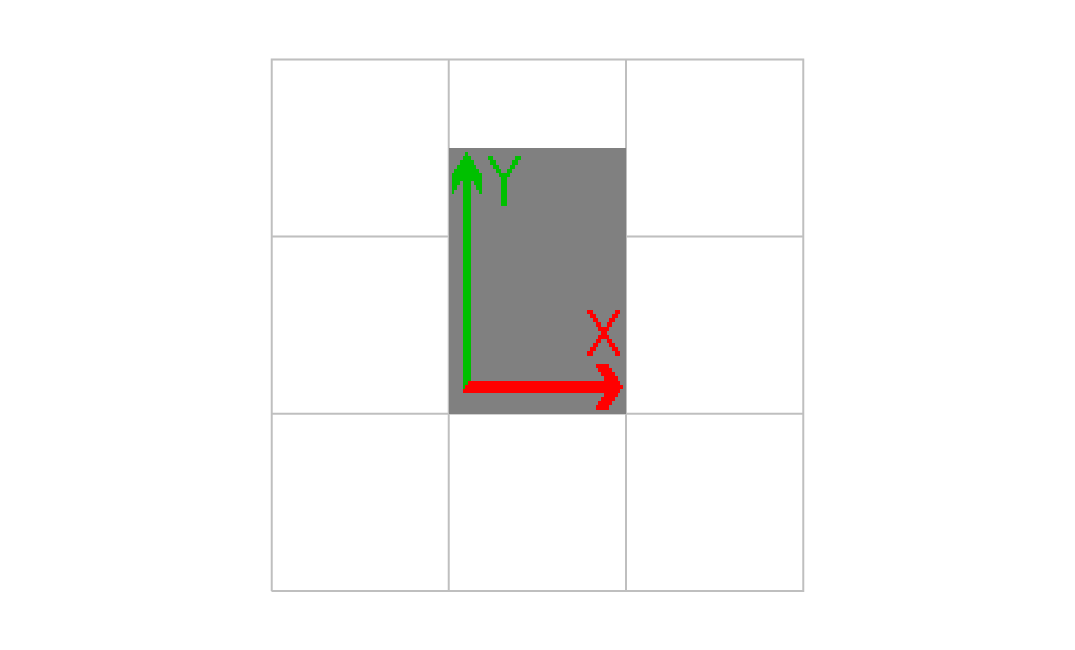
画像が上に伸びた。
5番目の値
1.000000 0.000000 0.000000 1.000000 1.500000 1.000000 cm
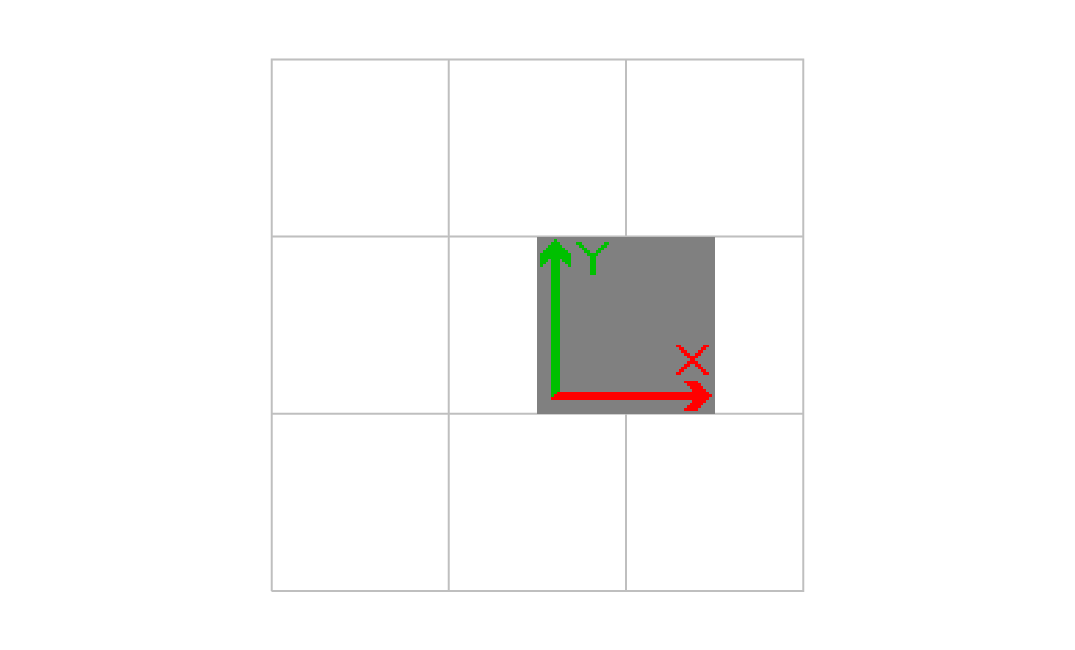
画像の左下の位置が右にずれた。
6番目の値
1.000000 0.000000 0.000000 1.000000 1.000000 1.500000 cm
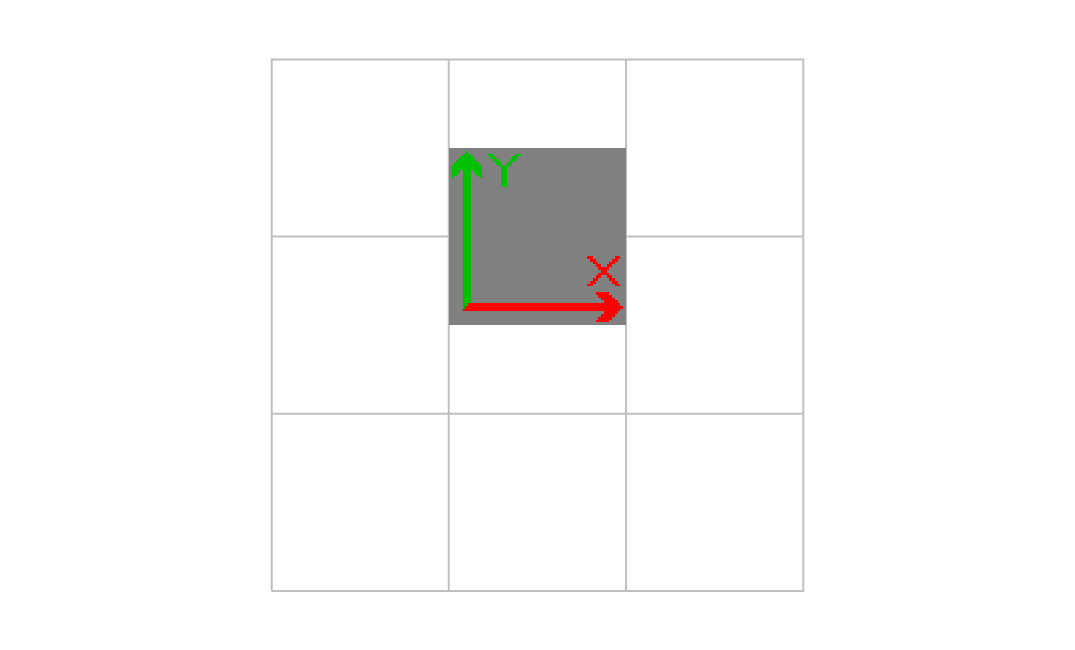
画像の左下の位置が上にずれた。
変換行列の値の解釈
上記観察結果から、変換行列は値を2個ずつ組 (x, y) にし、前から順に以下のように解釈できそうである。
- 画像の左下から右下に向かうベクトル
- 画像の左下から左上に向かうベクトル
- 座標系の原点 (左下) から画像の左下に向かうベクトル
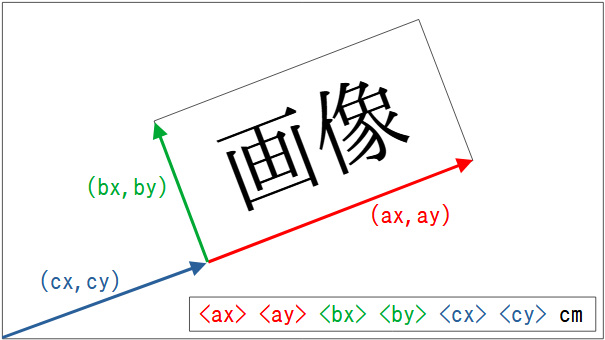
たとえば、画像を90度左回転して貼るには、変換行列を以下のように指定すればよい。
0 幅 -高さ 0 回転後右下x座標 回転後右下y座標 cm
画像を90度左回転すると、画像の右に向かうベクトルは上向きに、上に向かうベクトルは左向きになる。
また、画像の左下だった角は右下になる。
よって、このような指定となる。
これを実際に上記サンプルで確かめてみる。
0.000000 1.000000 -1.00000 0.000000 2.000000 1.000000 cm
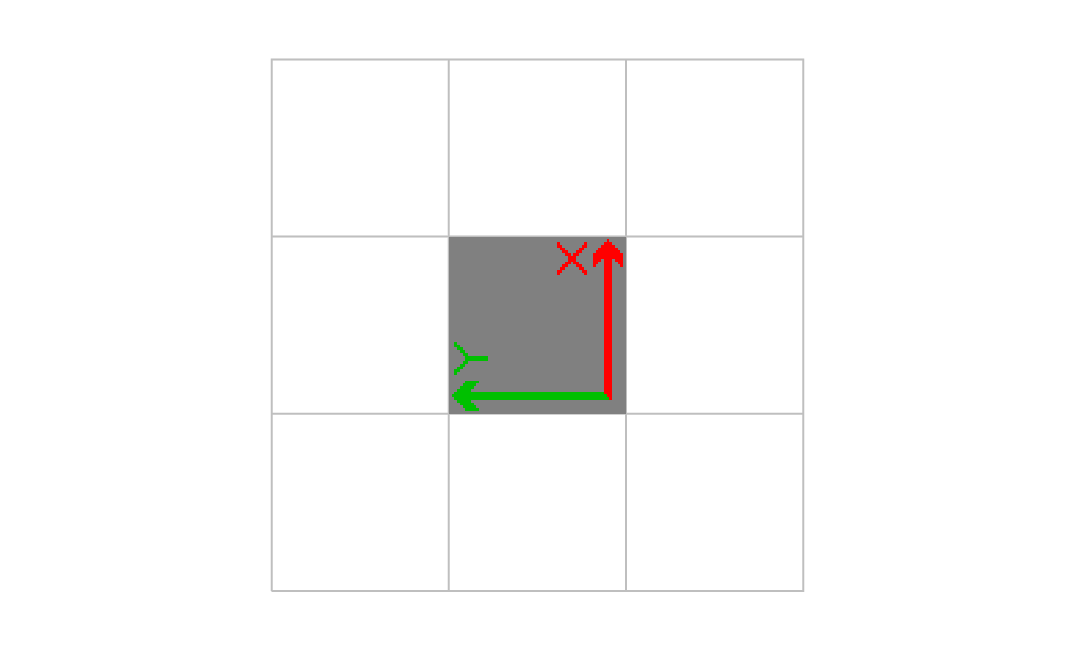
たしかに、画像が左に90度回転した。
ここでは扱わないが、三角関数などを用いて同様に各ベクトルを計算することで、画像を任意の位置に任意の角度回転させて貼ることができるはずである。
2値画像の描画
/ColorSpace/DeviceGray を指定することで、グレースケール画像を記述できる。
さらに、/BitsPerComponent 1 を指定することで、1ピクセルを1ビットで表現する白黒画像を記述できる。
このとき、画像データは以下の表現方法を用いる。
- 各バイトの中では、左のピクセルほど上位ビット、右のピクセルほど下位ビットとなる
- 各行をバイト列で表し、各行を表す最後のバイトの下位ビットは使わないことがある
- すなわち、各行の最初のピクセルのデータは、各行を表す最初のバイトの最上位ビットから記述される
- 黒をビット
0、白をビット1で表現する
例として、東雲フォント (shnmk14.bdf) の「猫」のデータを埋め込み、表示してみた。
普通に描画
%PDF-1.2
1 0 obj
<</Type/XObject/Subtype/Image/Width 14/Height 14/BitsPerComponent 1/Length 71
/ColorSpace/DeviceGray/Filter/ASCIIHexDecode
>>
stream
0910
4910
37fc
1110
3110
4800
0bf8
1a48
2a48
4bf8
0a48
0a48
33f8
1000
>
endstream
endobj
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding padding padding padding
% padding p
2 0 obj
<<
/Font <<>>
/XObject<</Image 1 0 R>>
/ProcSet[/PDF/ImageB]
>>
endobj
3 0 obj
<</Length 238>>
stream
q
42.51968503937021 0 0 42.51968503937021 65.19685039370069 14.173228346456694 cm
/DeviceRGB cs 0.50 0.75 1.00 sc
0 0 m 0 3 l 3 3 l 3 0 l 0 0 l
f
q
0.00 0.75 0.00 sc
2.000000 0.000000 0.000000 2.000000 0.500000 0.500000 cm
/Image Do
Q
Q
endstream
endobj
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding padding padding padding
% padding
4 0 obj
<</Type/Page/Parent 5 0 R/Contents 3 0 R>>
endobj
5 0 obj
<<
/Type/Pages
/Resources 2 0 R
/MediaBox[0 0 257.952755905512 155.905511811024]
/Count 1
/Kids[4 0 R]
>>
endobj
6 0 obj
<</Type/Catalog/Pages 5 0 R>>
endobj
7 0 obj
<<
/Title (image test)
>>
endobj
xref
0 8
0000000000 65535 f
0000000010 00000 n
0000000400 00000 n
0000000480 00000 n
0000001000 00000 n
0000001059 00000 n
0000001181 00000 n
0000001227 00000 n
trailer
<<
/Root 6 0 R
/Info 7 0 R
/Size 8
>>
startxref
1269
%%EOF
今回は、白で描画されていることがわかりやすいよう、背景を塗りつぶした上に画像を描画した。
そのために、変換行列のサンプルで用いたコマンドに加えて、以下のコマンドを用いた。
| コマンド | 意味 |
|---|---|
/DeviceRGB cs |
stroke 以外の描画に用いる色空間を DeviceRGB に設定する |
<r> <g> <b> sc |
stroke 以外の描画に用いる色を設定する |
PDF から PNG に変換 で変換すると、以下の表示になった。

0 のビットにあたる部分が黒で、1 のビットにあたる部分が白で描画されていることがわかる。
白黒反転して描画
/Decode[1 0] を追加すると、画像を白黒反転して描画できる。
1 0 obj
<</Type/XObject/Subtype/Image/Width 14/Height 14/BitsPerComponent 1/Length 71
/ColorSpace/DeviceGray/Filter/ASCIIHexDecode/Decode[1 0]
>>
stream
0910
4910
37fc
1110
3110
4800
0bf8
1a48
2a48
4bf8
0a48
0a48
33f8
1000
>
endstream
endobj
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding padding padding padding

塗色で描画 (マスク)
/ColorSpace/DeviceGray のかわりに /ImageMask true を指定すると、画像をマスクとして用い、「黒」の部分を stroke 以外の描画用の色で塗り、「白」の部分をそのまま残すことができる。
「白」「黒」は、これまでみてきたビットと /Decode の指定に従う。
(仕様書 8.9.6.2 Stencil Masking)
1 0 obj
<</Type/XObject/Subtype/Image/Width 14/Height 14/BitsPerComponent 1/Length 71
/ImageMask true/Filter/ASCIIHexDecode/Decode[1 0]
>>
stream
0910
4910
37fc
1110
3110
4800
0bf8
1a48
2a48
4bf8
0a48
0a48
33f8
1000
>
endstream
endobj
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding padding padding padding
% pad

上の /Decode で白黒反転するサンプルの描画結果と比べて、白いところは描画せず、黒いところを緑で描画できている。
画像の補間
デフォルトでは、画像は各ピクセル (四角形) をそれぞれのピクセルに割り当てられた単色で塗ることにより表示され、解像度が低い画像はギザギザになることがある。
/Interpolate true を指定することで、画像の補間を行い、なめらかに表示させることができる。
(仕様書 8.9.5.3 Image Interpolation)
例として、上記「白黒反転して描画」のサンプルにこの指定を追加してみた。
1 0 obj
<</Type/XObject/Subtype/Image/Width 14/Height 14/BitsPerComponent 1/Length 71
/ColorSpace/DeviceGray/Filter/ASCIIHexDecode/Decode[1 0]/Interpolate true
>>
stream
0910
4910
37fc
1110
3110
4800
0bf8
1a48
2a48
4bf8
0a48
0a48
33f8
1000
>
endstream
endobj
% padding padding padding padding padding padding padding padding padding
% padding padding padding padding padding padding paddi

各ピクセルの境界がぼやかされて表示されている。
補間の方法は規定されておらず、ビューアによって異なる表示になる可能性があり、補間が行われない可能性もある。
PNG画像のデータの利用
仕様書の 7.4.4.4 LZW and Flate Predictor Functions より、PDFで用いる画像データでは、PNGで用いる predictors を用いることができることがわかる。
さらに、
Portable Network Graphics (PNG) Specification (Third Edition) 7.2 Scanlines
を見ると、PNGで用いられる scanlines の表現方法 (上位ビットから下位ビットに向かい、行の最後のバイトの余った下位ビットは使わない) はPDFと同じようである。
そのため、zlib/deflate 圧縮されていることも含め、PNG画像の IDAT チャンクのデータをそのままPDFの画像データとして使用できそうである。
実際、/FlateDecode フィルタのパラメータを設定することで、PNG画像の IDAT チャンクのデータをそのまま使用できるようになる。
使用できるのは、フルカラー (2) およびグレースケール (0) 形式のPNG画像であり、かつインターレースがかかっていないものである。
アルファチャンネルを含む画像は、PDFでは色データと透明度データは分けて格納するため、使用できない。
インデックスカラーは、PDFの /Indexed 色空間 (8.6.6.3 Indexed Colour Spaces) に対応させることができるかもしれないが、今回は扱わない。
フィルタのパラメータを設定するには、/DecodeParms を用いる。
(Params ではなく、Parms である)
/Filter で指定したフィルタに対応するパラメータを指定する。
/Filter でフィルタを複数指定した場合は、パラメータも配列 ([~] で囲む) で、フィルタの指定と同じ順番で指定する。
パラメータは、辞書 (名前と値が交互に並んだ列を <<~>> で囲む) で指定する。
パラメータを指定しない (パラメータをとらない、または全てデフォルト値を用いる) フィルタに対応する位置には、null を指定する。
PNG画像の IDAT チャンクのデータをPDFの画像データとして用いるには、/FlateDecode フィルタに以下のパラメータを指定する。
| パラメータ名 | 値 |
|---|---|
/Predictor |
15 (PNG の predictor を用いることを表す) |
/Colors |
画像データのチャンネル数 |
/BitsPerComponent |
画像データの1サンプルのビット数 |
/Columns |
画像の横幅 (ピクセル数) |
サンプルサイズ・チャンネル数・横幅は画像そのものの情報でも指定しており、冗長に感じるが、とにかくここでも指定しないといけないようである。
フィルタはあくまでストリームのデータの変換方法を指定するものであり、その利用先は画像とは限らないため、画像として用いるときの情報とは独立している?
たとえば、128×128ピクセルの8ビットフルカラー画像の IDAT チャンクをBase85エンコードしたものを用いる場合、フィルタとパラメータを以下のように指定する。
/Filter[/ASCII85Decode/FlateDecode]
/DecodeParms[
null
<</Predictor 15 /Colors 3 /BitsPerComponent 8 /Columns 128>>
]
以下は、前回の記事の img2pdf.py と同様に画像をPDFファイルの中心に貼るプログラムである。
(画像ファイルをPDFのオブジェクトに変換する部分以外は、使い回しである)
今回は、PNGファイルの IDAT チャンクの内容をそのまま使えることを示すため、入力はPNGファイルに限定し、IDAT チャンクの内容をそのままPDFファイルに埋め込むようにした。
インデックス画像・インターレース画像・アルファチャンネルがある画像には非対応である。
サンプルサイズが16ビットの画像にも対応できるよう、出力するバージョンは PDF 1.5 とした。
import sys
page_width_mm = 210
page_height_mm = 297
img_mm_per_pixel = 0.254
def mm_to_pt(length_mm):
return length_mm / 25.4 * 72
if len(sys.argv) < 3:
sys.stderr.write("Usage: png2pdf.py input-file output-file")
sys.exit(1)
pdf_objects = [None]
with open(sys.argv[1], "rb") as f:
png_data = f.read()
if png_data[0:8] != b"\x89PNG\r\n\x1a\n":
raise Exceiton("not PNG file")
png_width = None
png_height = None
png_depth = None
png_num_colors = None
png_colortype = None
idat_data = b""
ptr = 8
while ptr < len(png_data):
chunk_length = int.from_bytes(png_data[ptr:ptr+4], byteorder="big")
chunk_name = png_data[ptr+4:ptr+8]
chunk_data = png_data[ptr+8:ptr+8+chunk_length]
ptr += chunk_length + 12
if chunk_name == b"IHDR":
if png_width is not None:
raise Exception("multiple IHDR found")
png_width = int.from_bytes(chunk_data[0:4], byteorder="big")
png_height = int.from_bytes(chunk_data[4:8], byteorder="big")
png_depth = chunk_data[8]
if chunk_data[9] == 0:
png_colortype = "/DeviceGray"
png_num_colors = 1
elif chunk_data[9] == 2:
png_colortype = "/DeviceRGB"
png_num_colors = 3
else:
raise Exception("unsupported color type %d" % chunk_data[9])
if chunk_data[10:13] != b"\0\0\0":
raise Exception("unsupported Compression / Filter / Interlace")
elif chunk_name == b"IDAT":
idat_data += chunk_data
if png_width is None:
raise Exception("IHDR not found")
img_obj_no = len(pdf_objects)
img_obj = (
("<</Type/XObject/Subtype/Image/Width %d/Height %d" % (png_width, png_height)) +
("/BitsPerComponent %d/Length %d" % (png_depth, len(idat_data))) +
("/Filter/FlateDecode/ColorSpace%s" % png_colortype) +
("/DecodeParms<</Predictor 15/Colors %d/BitsPerComponent %d/Columns %d>>>>\nstream\n" %
(png_num_colors, png_depth, png_width))
).encode() + idat_data + b"\nendstream"
pdf_objects.append(img_obj)
res_obj_no = len(pdf_objects)
res_obj = (
"<</Font<<>>/XObject<</Image %d 0 R>>/ProcSet[/PDF/ImageC/ImageB]>>" % img_obj_no
).encode()
pdf_objects.append(res_obj)
contents_obj_no = len(pdf_objects)
img_width_mm = png_width * img_mm_per_pixel
img_height_mm = png_height * img_mm_per_pixel
contents_data = (
"q %.15f 0 0 %.15f %.15f %.15f cm /Image Do Q" % (
mm_to_pt(img_width_mm),
mm_to_pt(img_height_mm),
mm_to_pt((page_width_mm - img_width_mm) / 2),
mm_to_pt((page_height_mm - img_height_mm) / 2)
)
).encode()
contents_obj = (
"<</Length %d>>\nstream\n" % len(contents_data)
).encode() + contents_data + b"\nendstream"
pdf_objects.append(contents_obj)
pagelist_obj_no = len(pdf_objects)
pdf_objects.append(None)
page_obj_no = len(pdf_objects)
page_obj = (
"<</Type/Page/Parent %d 0 R/Contents %d 0 R>>" % (
pagelist_obj_no,
contents_obj_no
)
).encode()
pdf_objects.append(page_obj)
pagelist_obj = (
("<</Type/Pages/Resources %d 0 R" % res_obj_no) +
("/MediaBox[0 0 %.15f %.15f]" % (mm_to_pt(page_width_mm), mm_to_pt(page_height_mm))) +
("/Count 1/Kids[%d 0 R]>>" % page_obj_no)
).encode()
pdf_objects[pagelist_obj_no] = pagelist_obj
catalog_obj_no = len(pdf_objects)
catalog_obj = (
"<</Type/Catalog/Pages %d 0 R>>" % pagelist_obj_no
).encode()
pdf_objects.append(catalog_obj)
info_obj_no = len(pdf_objects)
info_obj = (
"<</Title (image test)>>"
).encode()
pdf_objects.append(info_obj)
pdf_data = b"%PDF-1.5\n"
xref = ("xref\n0 %d\n" % len(pdf_objects)).encode()
for idx, obj in enumerate(pdf_objects):
if obj is None:
xref += b"0000000000 65535 f\n"
else:
xref += ("%010d 00000 n\n" % len(pdf_data)).encode()
pdf_data += ("%d 0 obj\n" % idx).encode() + obj + b"\nendobj\n"
xref_pos = len(pdf_data)
pdf_data += xref
pdf_data += (
"trailer\n<</Root %d 0 R/Info %d 0 R/Size %d>>\nstartxref\n%d\n%%%%EOF\n" % (
catalog_obj_no,
info_obj_no,
len(pdf_objects),
xref_pos
)
).encode()
with open(sys.argv[2], "wb") as f:
f.write(pdf_data)
まとめ
今回は、PDFに画像を貼る際に使える、以下の機能を紹介した。
- 変換行列による画像の位置・サイズ・角度の指定
- 2値画像の描画 (白黒・塗色)
- 画像を補間する指示
- PNGの
IDATチャンクのデータの利用 (predictor)