CNNの重み初期化にHeの初期値を使おうと思ったら、TensorFlow(Keras)のtf.initializers.he_normalを使う場合とtf.initializers.truncated_normal で学習結果が異なったので調べた話。
環境
- Python 3.7.3
- TensorFlow 1.14.0
- numpy 1.16.2
- matplotlib 3.0.3
Heの初期値
Heの初期値とは、活性化関数にReLUを使用するニューラルネットワークにおいて学習がうまく進むような重みの初期値の決め方で、Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classificationという論文の中で示されています。
この論文以前にXavierの初期値と呼ばれる重み初期化が提唱されていましたが、近年一般的なReLUや畳み込みニューラルネットワークに適していなかったことが背景にあります。
導出等は論文を参照していただくとして、結果はとてもシンプルで
Var = \frac{2}{N_{in}}
を満たす分散の正規分布から重みの初期値をサンプリングする、というものです。ここで$N_{in}$は重みの入力次元で、全結合層なら入力要素数、2次元の畳み込みならフィルターサイズと入力チャンネル数の積です。
現在ではReLUは標準的な活性化関数で、畳み込みニューラルネットワークも非常によく使われるということもあり、Heの初期値は重み初期化のスタンダードとなっています。
TensorFlow(Keras)で使う
tf.initializers.he_normalを使う
TensorFlowではHeの初期値がtf.initializers.he_normalとして実装されていて、簡単に使うことができます。
# tensorflowの場合
W_shape = [filter_row, filter_col, ch_in, ch_out]
initializer = tf.initializers.he_normal()
W = tf.get_variable(name='W', shape=W_shape, initializer=initializer)
h = tf.nn.conv2d(input, W, padding='SAME')
# kerasの場合
initializer = tf.initializers.he_normal()
h = K.layers.Conv2D(ch_out, [filter_row, filter_col], kernel_initializer=initializer)(input)
ただし、tf.initializers.he_normalは通常の正規分布ではなく、標準偏差の2倍でカットした切断正規分布からサンプリングする点に注意が必要です。
tf.initializers.truncated_normalから計算する
tf.initializers.he_normalを使わない場合は以下のようになります。公式実装に合わせて切断正規分布からサンプリングしています。
W_shape = [filter_row, filter_col, ch_in, ch_out]
stddev = (2 / (filter_row * filter_col * ch_in)) ** 0.5
initializer = tf.initializers.truncated_normal(mean=0.0, stddev=stddev)
W = tf.get_variable(name='W', shape=W_shape, initializer=initializer)
h = tf.nn.conv2d(input, W, padding='SAME')
2つのパターンを比較
tf.initializers.he_normalとtf.initializers.truncated_normalの分布を比較してみます。簡単のため、重みは全結合層を想定しています。また、標準偏差が1となることを期待して$N_{in}$を2としています。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
shape = [2, 50000]
seed = 1
# he_normalを使う場合
initializer = tf.initializers.he_normal(seed=seed)
tf_W = tf.get_variable(name='he_normal', shape=shape, initializer=initializer)
# truncated_normalを使う場合
stddev = (2 / shape[0]) ** 0.5
initializer = tf.initializers.truncated_normal(mean=0.0, stddev=stddev, seed=seed)
my_W = tf.get_variable(name='my_he_normal', shape=shape, initializer=initializer)
# 結果を比較
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
tf_W_value = sess.run(tf_W)
my_W_value = sess.run(my_W)
bins = np.arange(-3.0, 3.0, 0.2)
plt.figure()
plt.hist(tf_W_value.flatten(), bins=bins, label='he_normal')
plt.hist(my_W_value.flatten(), bins=bins, label='truncated_normal')
plt.legend()
plt.show()
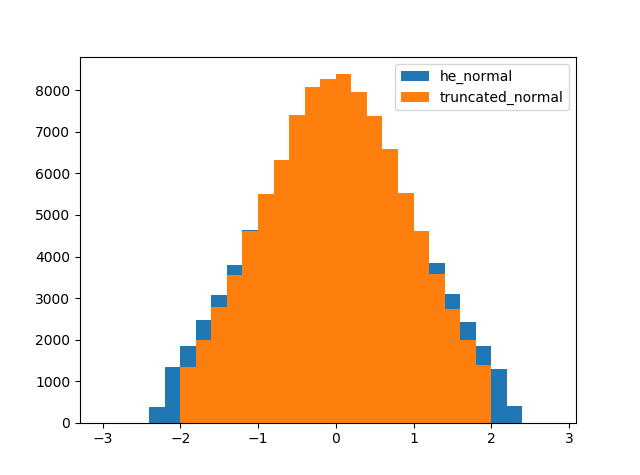
あれ…? 分布の裾がおかしいですね。
原因
公式のドキュメントを読んで違いが生まれる原因を探ります。
tf.initializers.he_normal のドキュメントを読む
keras公式では大した記述はありません。しかし、tensorflow公式では
It draws samples from a truncated normal distribution centered on 0 with standard deviation (after truncation) given by stddev = sqrt(2 / fan_in) where fan_in is the number of input units in the weight tensor.
とあり、正規分布を切断後の標準偏差をスケーリングすることがわかります。
tf.initializers.truncated_normal のドキュメントを読む
tf.initializers.he_normalを使わない場合ではtf.initializers.truncated_normalの標準偏差を指定したので、ドキュメントを確認してみると、
These values are similar to values from a random_normal_initializer except that values more than two standard deviations from the mean are discarded and re-drawn. This is the recommended initializer for neural network weights and filters.
とありますが、特に有益な情報はなさそう。
そこでソースコードを見てみると、中でtf.random.truncated_normalを呼び出しています。そちらのドキュメントを確認してみたところ、
stddev: A 0-D Tensor or Python value of type dtype. The standard deviation of the normal distribution, before truncation.
ありました。tf.initializers.truncated_normalでは、切断前の正規分布の標準偏差を指定するようです。
まとめ
tf.initializers.he_normalでは、切断後の正規分布の標準偏差をスケーリングするのに対し、tf.initializers.truncated_normalでは、切断前の正規分布の標準偏差を指定することがわかりました。
確かに結果のヒストグラムでは、tf.initializers.truncated_normalは絶対値が2以下の範囲に収まっていて、切断前の正規分布の標準偏差が1であることがわかります。一方で、tf.initializers.he_normalは絶対値が2以下の範囲からはみ出してしまっています。
tf.initializers.he_normalは切断正規分布を1つの確立分布として考えているのに対し、tf.initializers.truncated_normalでは、切断正規分布はあくまで正規分布をカットしただけ、って考えなのかもしれません。
この違いが学習に与える影響は未知数ですが、自分で24層のCNNを作って遊んでいた時には学習曲線に明確な違いが出たので、学習がうまくいかない時はもう一方の初期化のやり方を試してみるといいかもしれません。
公式ドキュメントとソースコード確認するの大事。
おまけ
tf.initializers.he_normal ってどうなってんの
tf.initializers.he_normalのソースコードを追ってみると、中でtf.initializers.VarianceScalingを呼び出しています。そちらのソースコードを確認してみると…
# constant taken from scipy.stats.truncnorm.std(a=-2, b=2, loc=0., scale=1.)
stddev = math.sqrt(scale) / .87962566103423978
return random_ops.truncated_normal(shape, 0.0, stddev, dtype, seed=self.seed)
力業で標準偏差を補正してtf.random.truncated_normalを呼び出してますね…
正規分布じゃなくて切断正規分布を使う理由って何よ
TensorFlowやTensorFlowバックエンドのKerasでは切断正規分布が標準的で、Heの初期値も切断正規分布で実装されていますが、PyTorchやChainerではそもそも切断正規分布が実装されておらず、Heの初期値は通常の正規分布で実装されているようです。
じゃあ切断正規分布を使うメリットって何よ?って話なのですが、StackOverflow等では、活性化関数にsigmoidやtanhを使う場合に、重みの初期値の絶対値が大きいと活性化関数の入力が大きくなって勾配が小さくなり、学習が遅くなってしまうことを防ぐため、との説明がありました。(明確な文献は見つけられなかったので、ご存知の方は教えていただけると嬉しいです。)
この場合、絶対値が大きい初期値を排除することが目的であり、切断後の標準偏差だと分布が広がってしまうので、切断正規分布の標準偏差は切断前の正規分布で考えるべきのように思えます。
しかし、これはあくまで活性化関数がsigmoidやtanhの場合であり、ReLUの場合には活性化関数の入力が大きくても勾配は変わらないので、この理屈は通じません。
そうなるとHeの初期値以前に、TensorFlowが切断正規分布を標準的としている意味がわかりません。
謎は深まるばかりじゃ…