Introduction -はじめに-
はじめまして。
私は外資系企業で秘書として働きながら、機械学習を学んでいる24歳です。
Microsoft officeのword/excelなどは日常的に使っていますが、プログラミングについては全くの初心者です。3ヶ月間AidemyさんのAIアプリ開発講座を受講し、成果物としてこのブログを作成しています。私のようにエンジニアを目指す方がつまづいた時に、このブログが”ちょこっと”参考になれば大変嬉しい限りです。
Taget -目標-
今回挑戦したのは、「アベンジャーズヒーローの画像識別 」です。
ここで"アベンジャーズ(Avengers)"について簡単にご紹介いたします。
『アベンジャーズ』(原題: Marvel's The Avengers)は、マーベル・コミックの同名のスーパーヒーローチームをベースにした、2012年のアメリカのスーパーヒーロー映画である。
Avengers(Wikipadiaより引用)
私はアベンジャーズを含むマーベル映画作品の大ファンです。だからより多くの人にその魅力を知ってほしい…!しかし、、「登場人物が多すぎてよくわからない。。。」という意見も多いのが現状です。そこで、すぐにそのヒーローの名前と特徴、その人物が持つスーパーパワーがわかったらとても便利ではないか!と思い、今回このアプリを作成するに至りました。
作成したアプリ
実際に作成したアベンジャーズヒーローの画像識別をするアプリがこちらです。
それでは上記のアプリ作成の過程を見ていきましょう。
Contents -内容-
1. 画像収集
2.画像の処理
3.画像の読み込み
4.転移学習
5.結果グラフの可視化
6.実装結果
Step1. 画像収集
今回はアベンジャーズのキャラクターのうち、比較的メインである以下の5人の識別に挑戦します。
- Captain America(キャプテン・アメリカ)- Chris Evans
- Thor(ソー)- Chris Hemsworth
- Hulk(ハルク)- Mark Ruffalo
- Iron man(アイアインマン) - Robert Downey Jr.
- Black Widow(ブラック・ウィドウ) - Scarlett Johansson
画像は次の2つの方法を使って集めていきます。
①スクレイピング
これはキーワード検索を利用してそのワードでヒットした画像をウェブ上から収集する方法です。
下の方法で5人分の画像を取得していきます。
参考サイト:
Pythonでスクレイピング! icrawler大量の画像を自動でダウンロード
画像データをキーワード検索で効率的に収集する方法(Python「icrawler」のBing検索)
#icrawlerのインストール
!pip install icrawler
#pythonライブラリの「icrawler」でBing用モジュールをインポート
from icrawler.builtin import BingImageCrawler
#ダウンロードした画像を保存する先のディレクトリを指定(「Captain_America」というディレクトリに保存する場合)
crawler = BingImageCrawler(storage={'root_dir': 'Captain_America'})
#検索するキーワードとダウンロード数の指定
crawler.crawl(keyword='Chris Evans クリス エバンス captain america', max_num=300)
⭐️ポイント⭐️
-
storage={'root_dir': 'ディレクトリ名'} とすることで、ダウンロードされた画像が下のように指定した名前のディレクトリに保存されます。

- Keyword='' では、英語だけでなく日本語でも探すことが可能です。
- 「max_num」 で指定した数値がダウンロードする画像の枚数となります。
②Kaggleの画像を利用する
『Kaggle』というウェブサイトがあり、画像のデータセットを取得したり、参考コードなどを閲覧することができます。ここで自分が集めたい画像のデータセットが見つかれば、スクレイピングで取得した画像に加えて、このデータセットからダウンロードしたものも含めれば、さらに画像数を増やすことができます。とても便利なサイトですので、画像収集の際に是非チェックしてみることをお勧めします!
Step2. 画像の処理
画像収集方法②Kaggleから取得した画像は、すでに顔だけにクロップされており、かつ重複したものはなかったためそのまま使用することができました。しかし、スクレイピングで取得した画像には重複したものや関連性のない不要な画像もあったため、それを手作業で削除したあと、両方のデータを1つのフォルダにまとめました。
(上段:Kaggleから取得、下段:スクレイピングで取得)
Step3. 画像の読み込み
はじめにモデル構築のコード全体を記載し、その後、私がつまづいた部分とそこから学んだTakeawayをご紹介していきます。まずは、「画像読み込み」の過程から触れてきます。
import os #osモジュール(os機能がpythonで扱えるようにする)
import cv2 #画像や動画を処理するオープンライブラリ
import numpy as np #python拡張モジュール
import matplotlib.pyplot as plt#グラフ可視化
import pandas as pd
import tensorflow
from tensorflow.keras.utils import to_categorical #正解ラベルをone-hotベクトルで求める
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input #全結合層、過学習予防、平滑化、インプット
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデル
from tensorflow.keras.models import Model, Sequential #線形モデル
from tensorflow.keras import optimizers #最適化関数
#画像の格納
path_CE = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/chris_evans/') if not filename.startswith('.')]
path_CH = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/chris_hemsworth/') if not filename.startswith('.')]
path_MR = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/mark_ruffalo/') if not filename.startswith('.')]
path_RDJ =[filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/robert_downey_jr/') if not filename.startswith('.')]
path_SJ = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/scarlett_johansson/') if not filename.startswith('.')]
#50x50のサイズに指定
image_size = 50
#画像を格納するリスト作成
img_CE = []
img_CH = []
img_MR = []
img_RDJ = []
img_SJ = []
for i in range(len(path_CE)):
img = cv2.imread('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/chris_evans/' + path_CE[i])
img = cv2.resize(img,(image_size, image_size))
img_CE.append(img)
for i in range(len(path_CH)):
img = cv2.imread('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/chris_hemsworth/' + path_CH[i])
img = cv2.resize(img,(image_size, image_size))
img_CH.append(img)
for i in range(len(path_MR)):
img = cv2.imread('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/mark_ruffalo/' + path_MR[i])
img = cv2.resize(img,(image_size, image_size))
img_MR.append(img)
for i in range(len(path_RDJ)):
img = cv2.imread('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/robert_downey_jr/' + path_RDJ[i])
img = cv2.resize(img,(image_size, image_size))
img_RDJ.append(img)
for i in range(len(path_SJ)):
img = cv2.imread('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/scarlett_johansson/' + path_SJ[i])
img = cv2.resize(img,(image_size, image_size))
img_SJ.append(img)
#np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_CE + img_CH+ img_MR + img_RDJ + img_SJ)
#正解ラベルの作成
y = np.array([0]*len(img_CE) + [1]*len(img_CH) + [2]*len(img_MR) + [3]*len(img_RDJ) + [4]*len(img_SJ))
#配列のラベルをシャッフルする
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#学習データと検証データを用意
X_train = X[:int(len(X)*0.9)]
y_train = y[:int(len(y)*0.9)]
X_test = X[int(len(X)*0.9):]
y_test = y[int(len(y)*0.9):]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#モデルの入力画像として用いるためのテンソールのオプション
input_tensor = Input(shape=(image_size, image_size, 3))
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#モデルの定義 *活性化関数relu
#転移学習の自作モデル
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='relu'))
#top_model.add(Dropout(0.5))
#top_model.add(Dense(32, activation='sigmoid'))
#top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
#入力はvgg.input, 出力はtop_modelにvgg16の出力を入れたもの
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:19]:
layer.trainable = False
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer="adam",
metrics=['accuracy'])
# 学習の実行
history = model.fit(X_train, y_train, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
#精度の評価
score = model.evaluate(X_test, y_test, batch_size=64, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
#acc, val_accのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker=".")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker=".")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#loss, val_lossのプロット
plt.plot(history.history["loss"], label="loss", ls="-", marker=".")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker=".")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#モデルを保存
model.save("my_new_model.h5")
つまずきポイント① 画像データの格納
#画像の格納
path_CE = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/chris_evans/') if not filename.startswith('.')]
path_CH = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/chris_hemsworth/') if not filename.startswith('.')]
path_MR = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/mark_ruffalo/') if not filename.startswith('.')]
path_RDJ =[filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/robert_downey_jr/') if not filename.startswith('.')]
path_SJ = [filename for filename in os.listdir('/content/drive/MyDrive/Pictures_Aidemy/cropped_images/scarlett_johansson/') if not filename.startswith('.')]
上記のようにマイドライブに保存した画像をそれぞれのpath_XXに格納していくのですが、Mac特有の現象で「if not filename.startswith('.') 」の記載がないと、image以外のファイルも取得されてエラーが出てしまうので、注意が必要です。
つまずきポイント② 正解ラベルの作成
#正解ラベルの作成
y = np.array([0]*len(img_CE) + [1]*len(img_CH) + [2]*len(img_MR) + [3]*len(img_RDJ) + [4]*len(img_SJ))
コンピューターは全てのデータを数値で認識するため、それぞれの画像も「クリス・エヴァンスの画像=0」、「クリス・ヘムズワースの画像=1」、「マーク・ラファロの画像=2」という風に数値で表してコンピューターに認識させます。
つまずきポイント③ 学習データと検証データの割合
#学習データと検証データを用意
X_train = X[:int(len(X)*0.9)]
y_train = y[:int(len(y)*0.9)]
X_test = X[int(len(X)*0.9):]
y_test = y[int(len(y)*0.9):]
学習データと検証データの割合(train:test)は、①7:3、 ②8:2、 ③9:1 の3パターンを試しました。今回は総データ数があまりたくさんなかったため、学習データの方にある程度多く比率を充てないと上手く学習が進みませんでした。結果的には割合を③9:1にしたときに最も精度が高くなりました。
Step4.転移学習
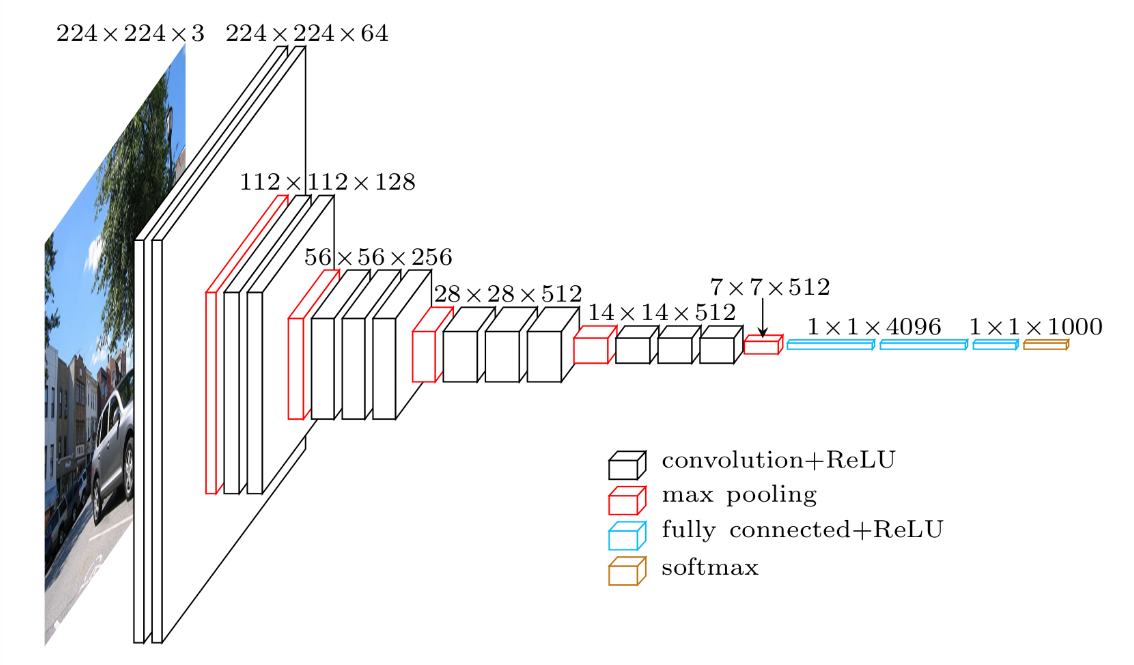
すでに学習済みのモデル (*VGG16) を使い転移学習を行うことで、少ない画像かつ短時間で学習モデルの構築を可能にします。
「VGG16」 とは、ImageNet という大量の画像データセットから学習された畳み込みが13層、全結合層が3層の合計16層からなるニューラルネットワークです。1000カテゴリの分類を学習したモデルです。
つまずきポイント④ vgg16の設定
#転移学習のモデルとしてVGG16を使用
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
- VGG16の最終層は自作の 「include_top= False」 とすることで、VGG16の出力層側にある3つの全結合層を含まないようにします。
- 引数「weights='imagenet'」とするとImageNetで学習済みの重みのデータが読み込まれます。
つまずきポイント⑤ 自作モデルの作成
#転移学習の自作モデル
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='relu'))
#top_model.add(Dropout(0.5))
#top_model.add(Dense(32, activation='sigmoid'))
#top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
- ここでの学びは、「データ数量が少ないときにDropoutの回数が多すぎると、学習が進まない」 ということです。
最初はDropoutを3回入れて実行してみました。ところが全体のデータ数が少ないため、学習があまり進みませんでした。そもそもDropoutとは、過学習を抑制する方法として使われるため、学習データ数が少ない今回のような場合には1回で十分ということです。
参考サイト:ディープラーニング初心者が知りたいKerasにおけるdropoutの使い方
つまずきポイント⑥ 重みの固定
#vgg16による特徴抽出部分の重みを固定(以降に新しい層(top_model)が追加)
for layer in model.layers[:19]:
layer.trainable = False
- ここでVGG16の全層の重みを固定しています。つまり、VGG16側の層の重みは学習時に変更されません。
- VGG16全ての層を学習内容に取り入れるとデータ量も多くなり時間もかかりますが、その分精度の高いモデルの特徴抽出を利用できるため、モデル全体の精度も高めることができます。
つまずきポイント⑦ コンパイル
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer="adam",
metrics=['accuracy'])
- 損失関数(loss) や 最適化(optimizer) 、評価関数(metrics) はモデルをコンパイルする際に必要なパラメータです。
- 損失関数とは「ニューラルネットワークによる予測値と正解値との差」を表すため、lossの値が0に近いほど精度が高いと言えます。
- 「categorical_crossentropy」とは多クラス分類に用いられる損失関数です。
これを使う場合には整数の目的値からカテゴリカルな目的値に変換する必要があり、Kerasのto_categoricalを使います。
(※たとえば 正解ラベルが0〜3の4種類で与えられる場合、次のように表されます。)
0 は [1,0,0,0]
1 は [0,1,0,0]
2 は [0,0,1,0]
3 は [0,0,0,1] - 全体のコード内にある以下の部分が、正解ラベルYの要素を0と1からなるリストに変換しています。
#正解ラベルをone-hotベクトルで求める
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
- Optimizer(最適化アルゴリズム)には「adam」を指定しました。
- 評価関数に 正解率("acc"または"accuracy") を選ぶと、損失関数や出力テンソルの情報から自動でKerasにあるデフォルトの"categorical_accuracy"を判断してくれるようです。
参考サイト:<損失関数>損失関数の利用方法 , Kerasによるものすごくシンプルな深層学習の例
<最適化>【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法
<評価関数>Keras入門(4)】Kerasの評価関数(Metrics)
つまずきポイント⑧ 学習の実行
# 学習の実行
history = model.fit(X_train, y_train, batch_size=32, epochs=80, verbose=1, validation_data=(X_test, y_test))
model.fit() で学習を実行することができます。以下がそれぞれの要素の説明です。
- history とは、モデルのfitメソッドの戻り値。
- batch_size とは、ネットワークに渡す入力を分ける数(※機械学習分野の慣習として、「2のn乗」(32, 64, 128...)が使われることが多いようです。)
- epochs とは、学習する回数。
- verbose とは、詳細表示モードの設定(0:表示なし、1:ログをプログレスバーで出力、2:エポックごとに1行のログを出力)
- validation_data とは、評価用データの指定。コード内では(X_test, y_test)は検証データを指定しています。
Step.5 結果グラフの可視化
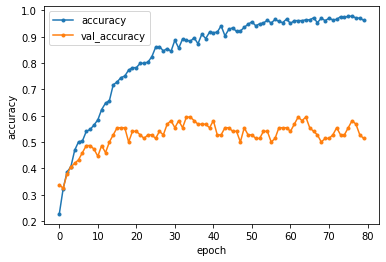
matplotlib.pyplotモジュールを使用して、訓練データと検証データの両方の学習過程を可視化します。(※ブルー:訓練データ、オレンジ:検証データ)
-
こちらが「正解率(accuracy)」の変動を表したグラフです。
epochs数80回学習させた結果、Test accuracy: 0.5135135054588318で、
このモデルの正解率は、約51% となりました。
-
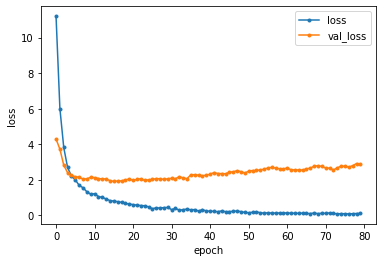
こちらが「損失関数の値(loss)」の変動を表したグラフです。
損失の値はできるだけ0に近づけたいところですが、約10エポック目以降はオレンジの損失値があまり小さくならず、ブルーとの損失値との差が徐々に広がっています。(=過学習が発生してる!)
最終的にはTest loss: 2.8769121170043945で、このモデルの損失関数の値は、約2.87 となりました。
Step.6 実装結果
きちんと送信した画像が読み込まれ、結果が表示されました!

↓試しにキャプテン・アメリカの画像を送信してみると…

正しい答えであるキャプテン・アメリカと識別されました!
ただし、精度はそこまで高くないので答えを間違えることもありましたが、きちんと画像識別アプリを実装することができました。
Conclusion -まとめ-
精度が上がらなかった要因としては、分類クラスが5個なのに対して、圧倒的に学習データ数が少なかったことだと思います。
スクレイピングで画像を集めたときに、ヒーローものということもあってか背景にいろいろな障害物が入っていたり、大人数で写っている画像が多かったです。そのような画像を今回は排除して学習をしましたが、kaggleから取得したデータセットのように全ての画像を顔だけに切り抜いたもので統一したら、精度が上がるかもしれないなと感じました。
この課題を通して、機械学習で高い精度を求めるにはデータ数とデータ処理がかなり重要であることを実感しました。
また、パラメータには今回使用したもの以外にも複数あるため、それぞれの特徴やどのような場合にどれが適しているのかといった検討が自分の中である程度つけられるように理解を深める必要があるなと思いました。
機械学習を使ったアプリを一から作成したことで、ほんの少し自分の自信になった気がします。と同時に、日常に潜み私たちの生活をサポートしている世のAIの精度の高さに改めて感動しました。
私もいつかそんな素晴らしモノを世へ送り出す一員になることを目指して、これからも学びを深めていきたいと思います。