1.はじめに
ステイホーム期間中に「ゼロから作るDeep learning② 自然言語処理編」を読みました。
何とか最後までたどり着きましたが、このテキストには応用例があまり記載されていません。
そこで、テキストのコードを活用して、スパムフィルタ(文書分類モデル)を作成してみます。
本検討はQiitaの記事ゼロから作るRNNによる文章分類モデルを参考にしました。
2.データ
Kaggleにある「SMS Spam Collection Dataset」を利用します。
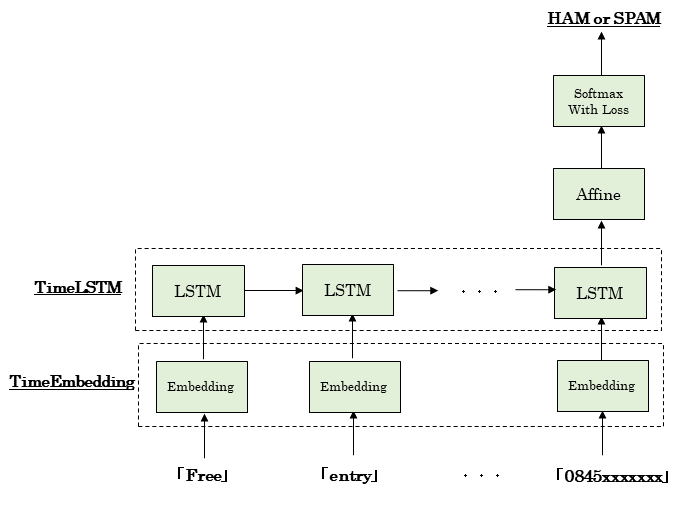
3.モデルの概要
- LSTMによる文書分類
- テキストの6章のコードを活用
- 最後のLSTMから出てきた隠れ状態ベクトルhをAffine変換で2値化し、Softmax関数で正規化する。
4.実装
- Google Colabの準備
# coding: utf-8
from google.colab import drive
drive.mount('/content/drive')
- モジュールのインポート
import sys
sys.path.append('drive/My Drive/Colab Notebooks/spam_filter')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn import metrics
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
%matplotlib inline
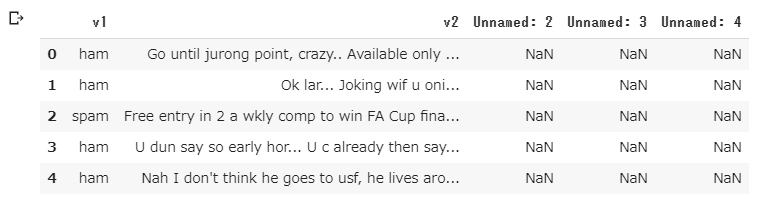
- CSVファイルをpandasで読み込んで最初の5行を表示
1列目はラベル(ham or spam)、2列目がメッセージ、3~5列は空行です。
spamのメッセージは「大当たり! すぐにxxxまで連絡して」的なものが多いようです。
df = pd.read_csv('drive/My Drive/Colab Notebooks/spam_filter/dataset/spam.csv',encoding='latin-1')
df.head()
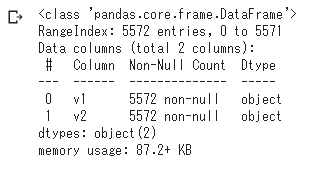
- 空行を削除して情報表示
メッセージの総数は5572
df.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'],axis=1,inplace=True)
df.info()
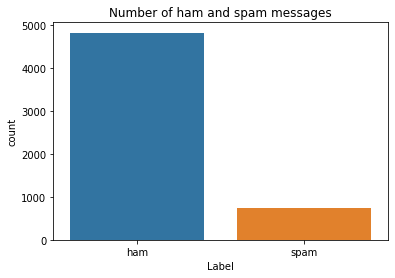
- hamとspamの総数
hamがspamの6倍くらい多い
sns.countplot(df.v1)
plt.xlabel('Label')
plt.title('Number of ham and spam messages')
- scikit-learnでラベルエンコーディング
- kerasのTokenizerでメッセージをトークン化
X = df.v2
Y = df.v1
le = LabelEncoder()
Y = le.fit_transform(Y)
max_words = 1000
max_len = 150
tok = Tokenizer(num_words=max_words)
tok.fit_on_texts(X)
word_to_id = tok.word_index
X_ids = tok.texts_to_sequences(X)
X_ids_pad = sequence.pad_sequences(X_ids,maxlen=max_len)

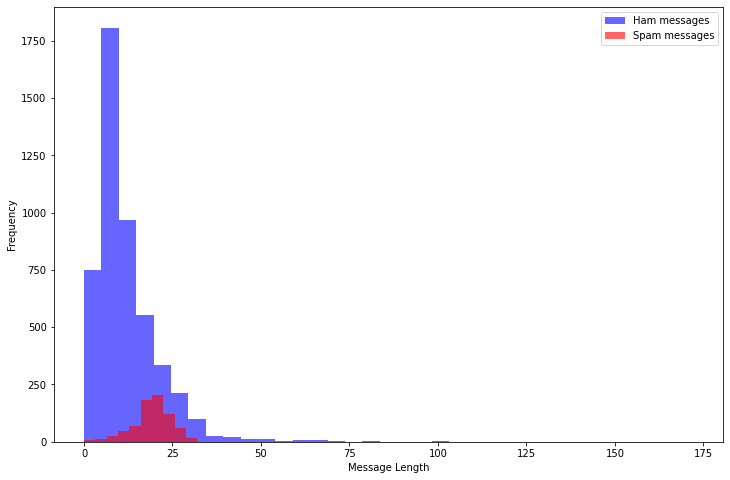
- 各メッセージの語数をヒストグラムで表示
最大でも100語程度で、Spamの方が長いものが多い。
message_len = [len(v) for v in X_ids]
df['message_len']=message_len
plt.figure(figsize=(12, 8))
df[df.v1=='ham'].message_len.plot(bins=35, kind='hist', color='blue',
label='Ham messages', alpha=0.6)
df[df.v1=='spam'].message_len.plot(kind='hist', color='red',
label='Spam messages', alpha=0.6)
plt.legend()
plt.xlabel("Message Length")
モデルの実装
- sigmoid関数、softmax関数、cross_entropy_error関数の定義
テキストから変更なし。
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
- Affine、Softmax、SoftmaxWithLoss、Embeddingの各レイヤーの定義
テキストから変更なし。
class Affine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
W, b = self.params
out = np.dot(x, W) + b
self.x = x
return out
def backward(self, dout):
W, b = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
db = np.sum(dout, axis=0)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class Softmax:
def __init__(self):
self.params, self.grads = [], []
self.out = None
def forward(self, x):
self.out = softmax(x)
return self.out
def backward(self, dout):
dx = self.out * dout
sumdx = np.sum(dx, axis=1, keepdims=True)
dx -= self.out * sumdx
return dx
class SoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.y = None # softmaxの出力
self.t = None # 教師ラベル
def forward(self, x, t):
self.t = t
self.y = softmax(x)
# 教師ラベルがone-hotベクトルの場合、正解のインデックスに変換
if self.t.size == self.y.size:
self.t = self.t.argmax(axis=1)
loss = cross_entropy_error(self.y, self.t)
return loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx *= dout
dx = dx / batch_size
return dx
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
np.add.at(dW, self.idx, dout)
return None
- TimeEmbedding、LSTM、TimeLSTMの各レイヤーの定義
テキストから変更なし。
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class LSTM:
def __init__(self, Wx, Wh, b):
'''
Parameters
----------
Wx: 入力`x`用の重みパラーメタ(4つ分の重みをまとめる)
Wh: 隠れ状態`h`用の重みパラメータ(4つ分の重みをまとめる)
b: バイアス(4つ分のバイアスをまとめる)
'''
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params
N, H = h_prev.shape
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache
tanh_c_next = np.tanh(c_next)
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)
dc_prev = ds * f
di = ds * g
df = ds * c_prev
do = dh_next * tanh_c_next
dg = ds * i
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2)
dA = np.hstack((df, dg, di, do))
dWh = np.dot(h_prev.T, dA)
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.c = None, None
self.dh = None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype='f')
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
self.h, self.c = h, c
def reset_state(self):
self.h, self.c = None, None
- Rnnlmクラスの定義
最後に出てきた隠れ状態ベクトルhをAffine変換して2値化し、Softmax関数で正規化する。
class Rnnlm():
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100, out_size=2):
V, D, H, O = vocab_size, wordvec_size, hidden_size, out_size
rn = np.random.randn
# 重みの初期化
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, O) / np.sqrt(H)).astype('f')
affine_b = np.zeros(O).astype('f')
# レイヤの生成
self.embed_layer = TimeEmbedding(embed_W)
self.lstm_layer = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine_layer = Affine(affine_W, affine_b)
self.loss_layer = SoftmaxWithLoss()
self.softmax_layer = Softmax()
# すべての重みと勾配をリストにまとめる
self.params = self.embed_layer.params + self.lstm_layer.params + self.affine_layer.params
self.grads = self.embed_layer.grads + self.lstm_layer.grads + self.affine_layer.grads
def predict(self, xs):
self.reset_state()
xs = self.embed_layer.forward(xs)
hs = self.lstm_layer.forward(xs)
xs = self.affine_layer.forward(hs[:,-1,:]) # 最後の隠し層をAffine変換
score = self.softmax_layer.forward(xs)
return score
def forward(self, xs, t):
xs = self.embed_layer.forward(xs)
hs = self.lstm_layer.forward(xs)
x = self.affine_layer.forward(hs[:,-1,:]) # 最後の隠し層をAffine変換
loss = self.loss_layer.forward(x, t)
self.hs = hs
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
dhs = np.zeros_like(self.hs)
dhs[:,-1,:] = self.affine_layer.backward(dout) # 最後の隠し層にAffine変換の誤差逆伝搬を設定
dout = self.lstm_layer.backward(dhs)
dout = self.embed_layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()
- OptimizerとしてSGDの定義
テキストから変更なし
class SGD:
'''
確率的勾配降下法(Stochastic Gradient Descent)
'''
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for i in range(len(params)):
params[i] -= self.lr * grads[i]
ここから学習
- データを学習データ(85%)と試験データ(15%)に分離
X_train,X_test,Y_train,Y_test = train_test_split(X_ids_pad,Y,test_size=0.15)
- ハイパーパラメータ等の設定
# ハイパーパラメータの設定
vocab_size = len(word_to_id)+1
batch_size = 20
wordvec_size = 100
hidden_size = 100
out_size = 2 # hamとspamの2値問題
lr = 1.0
max_epoch = 10
data_size = len(X_train)
# 学習時に使用する変数
max_iters = data_size // batch_size
# Numpy配列に変換する必要がある
x = np.array(X_train)
t = np.array(Y_train)
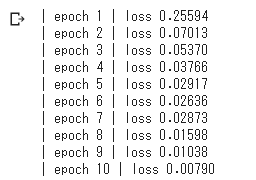
- 学習
- ミニバッチでメッセージを20ずつ処理
- テキストにあるTruncated BPTTは適用していない。
total_loss = 0
loss_count = 0
loss_list = []
# モデルの生成
model = Rnnlm(vocab_size, wordvec_size, hidden_size, out_size)
optimizer = SGD(lr)
for epoch in range(max_epoch):
for iter in range(max_iters):
# ミニバッチの取得
batch_x = x[iter*batch_size:(iter+1)*batch_size]
batch_t = t[iter*batch_size:(iter+1)*batch_size]
# 勾配を求め、パラメータを更新
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
avg_loss = total_loss / loss_count
print("| epoch %d | loss %.5f" % (epoch+1, avg_loss))
loss_list.append(float(avg_loss))
total_loss, loss_count = 0,0
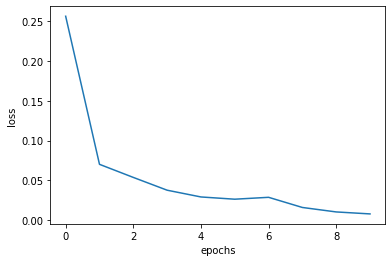
x = np.arange(len(loss_list))
plt.plot(x, loss_list, label='train')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
- 試験データの推論
result = model.predict(X_test)
Y_pred = result.argmax(axis=1)
- 正答率
98%!
Kaggleの他の人のノートブックと比べても悪くない。
# calculate accuracy of class predictions
print('acc=',metrics.accuracy_score(Y_test, Y_pred))
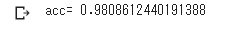
- 混同行列
# print the confusion matrix
print(metrics.confusion_matrix(Y_test, Y_pred))

5.まとめ
今回、このツールの作成のために試行錯誤することで、テキストの理解を深めることができました。
もし同じようにゼロから作るディープラーニング②を読まれた方がいたら、サンプルプログラムを活用して、何らかのアプリを作成してみることをお勧めします。
おまけ
自作smsで判定
一つ目は野球の試合を一緒に見に行こうと誘うもの。
二つ目は、自作Spam(訳さなくてよい)。
意外にも?ちゃんと判定できてる。
texts_add = ["I'd like to watch baseball game with you. I'm wating for your answer.",
"Do you want to meet new sex partners every night? Feel free to call 09077xx0721."
]
X_ids_add = tok.texts_to_sequences(texts_add)
X_ids_pad_add = sequence.pad_sequences(X_ids_add,maxlen=max_len)
result = model.predict(X_ids_pad_add)
Y_pred = result.argmax(axis=1)
print(Y_pred)
