はじめに
最近ゼロから作るDeep Learning ❷ ―自然言語処理編が発売されて深層学習による自然言語処理がますます身近になってきました。
今回はこの本のコンセプトとコードを拝借して、RNNによる文章学習とラベル分類を行うモデルをフロムスクラッチで作成しました。
概要
RNNは系列情報を扱えるニューラルネットワークです。今回は、単語の並ぶ方向を時系列方向として訓練します。下図のようにID化した単語をEmbedding層(埋め込み層)に入力し、単語情報をテンソルに変換します。埋め込んだ単語をRNNユニットに入力します。RNNユニットは前のユニットがはきだした内部状態テンソルhを受け取り、単語の入力と合わせて内部状態を計算し、次のRNNユニットにはきだします。
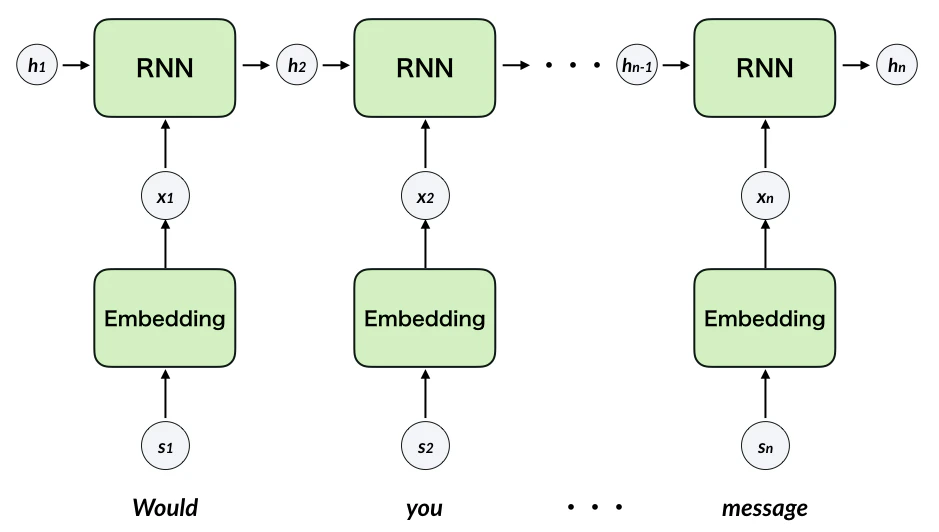
RNNの詳細な内部構造は下図のようになっています。
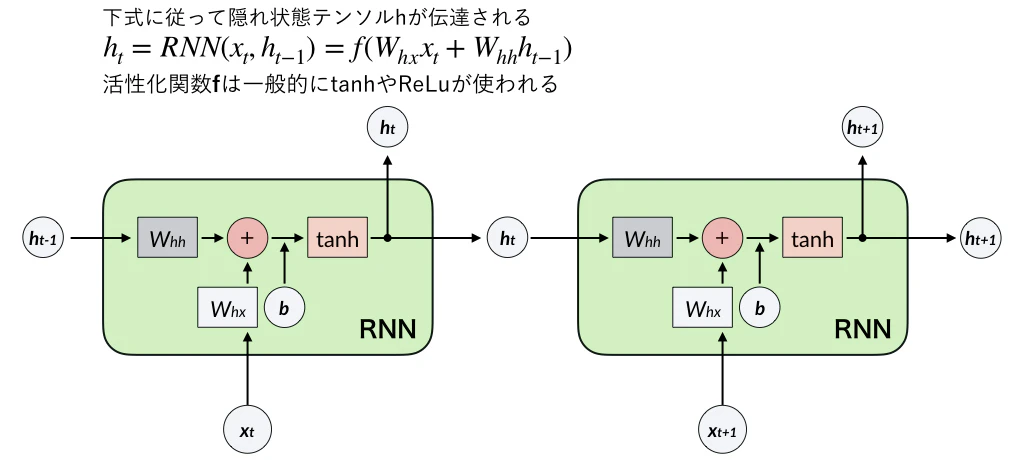
このタスクで用いるネットワーク構成は
- Embedding層:単語情報を埋め込み行列に変換する
- RNN層:今回は入力系列の長さ分だけRNN層を連ねる
- Affine層:重み行列と入力行列をかけて平滑化する(softmaxに渡すため)
- SoftmaxWithLoss層:softmax関数で各ラベルに対する確率を計算し、CrossEntropyでLossを返す
今回はChainerのLSTMを使ってラベル分類をしているこちらのサイトを参考にして、同じように文章が疑問文かどうかを判定するモデルをシンプルなRNNで構築してみます。
文章データ
こちらのサイトの英文データを拝借しました.
data = [
["Could I exchange business cards, if you don’t mind?", 1],
["I'm calling regarding the position advertised in the newspaper.", 0],
["I'd like to apply for the programmer position.", 0],
["Could you tell me what an applicant needs to submit?", 1],
["Could you tell me what skills are required?", 1],
["We will assist employees with training and skill development.", 0],
["What kind of in-house training system do you have for your new recruits?", 1],
["For office equipment I think rental is better.", 0],
["Is promotion based on the seniority system?", 1],
["What's still pending from February?", 1],
["Which is better, rental or outright purchase?", 1],
["General Administration should do all the preparations for stockholder meetings.", 0],
["One of the elevators is out of order. When do you think you can have it fixed?", 1],
["General Administration is in charge of office building maintenance.", 0],
["Receptionists at the entrance hall belong to General Administration.", 0],
["Who is managing the office supplies inventory?", 1],
["Is there any difference in pay between males and females?", 1],
["The General Administration Dept. is in charge of office maintenance.", 0],
["Have you issued the meeting notice to shareholders?", 1],
["What is an average annual income in Japan?", 1],
["Many Japanese companies introduced the early retirement system.", 0],
["How much did you pay for the office equipment?", 1],
["Is the employee training very popular here?", 1],
["What kind of amount do you have in mind?", 1],
["We must prepare our financial statement by next Monday.", 0],
["Would it be possible if we check the draft?", 1],
["The depreciation of fixed assets amounts to $5 million this year.", 0],
["Please expedite the completion of the balance sheet.", 0],
["Could you increase the maximum lending limit for us?", 1],
["We should cut down on unnecessary expenses to improve our profit ratio.", 0],
["What percentage of revenue are we spending for ads?", 1],
["One of the objectives of internal auditing is to improve business efficiency.", 0],
["Did you have any problems finding us?", 1],
["How is your business going?", 1],
["Not really well. I might just sell the business.", 0],
["What line of business are you in?", 1],
["He has been a valued client of our bank for many years.", 0],
["Would you like for me to show you around our office?", 1],
["It's the second door on your left down this hall.", 0],
["This is the … I was telling you about earlier.", 0],
["We would like to take you out to dinner tonight.", 0],
["Could you reschedule my appointment for next Wednesday?", 1],
["Would you like Japanese, Chinese, Italian, French or American?", 1],
["Is there anything you prefer not to have?", 1],
["Please give my regards to the staff back in San Francisco.", 0],
["This is a little expression of our thanks.", 0],
["Why don’t you come along with us to the party this evening?", 1],
["Unfortunately, I have a prior engagement on that day.", 0],
["I am very happy to see all of you today.", 0],
["It is a great honor to be given this opportunity to present here.", 0],
["The purpose of this presentation is to show you the new direction our business is taking in 2009.", 0],
["Could you please elaborate on that?", 1],
["What's your proposal?", 1],
["That's exactly the point at issue here.", 0],
["What happens if our goods arrive after the delivery dates?", 1],
["I'm afraid that's not accpetable to us.", 0],
["Does that mean you can deliver the parts within three months?", 1],
["We can deliver parts in as little as 5 to 10 business days.", 0],
["We've considered all the points you've put forward and our final offer is $900.", 0],
["Excuse me but, could I have your name again, please?", 1],
["It's interesting that you'd say that.", 0],
["The pleasure's all ours. Thank you for coimng today.", 0],
["Could you spare me a little of your time?", 1],
["That's more your area of expertise than mine, so I'd like to hear more.", 0],
["I'd like to talk to you about the new project.", 0],
["What time is convenient for you?", 1],
["How’s 3:30 on Tuesday the 25th?", 1],
["Could you inform us of the most convenient dates for our visit?", 1],
["Fortunately, I was able to return to my office in time for the appointment.", 0],
["I am sorry, but we have to postpone our appointment until next month.", 0],
["Great, see you tomorrow then.", 0],
["Great, see you tomorrow then.", 1],
["I would like to call on you sometime in the morning.", 0],
["I'm terribly sorry for being late for the appointment.", 0],
["Could we reschedule it for next week?", 1],
["I have to fly to New York tomorrow, can we reschedule our meeting when I get back?", 1],
["I'm looking forward to seeing you then.", 0],
["Would you mind writing down your name and contact information?", 1],
["I'm sorry for keeping you waiting.", 0],
["Did you find your way to our office wit no problem?", 1],
["I need to discuss this with my superior. I'll get back to you with our answer next week.", 0],
["I'll get back to you with our answer next week.", 0],
["Thank you for your time seeing me.", 0],
["What does your company do?", 1],
["Could I ask you to make three more copies of this?", 1],
["We have appreciated your business.", 0],
["When can I have the contract signed?", 1],
["His secretary is coming down now.", 0],
["Please take the elevator on your right to the 10th floor.", 0],
["Would you like to leave a message?", 1],
["It's downstairs in the basement.", 0],
["Your meeting will be held at the main conference room on the 15th floor of the next building.", 0],
["Actually, it is a bit higher than expected. Could you lower it?", 1],
["Would you mind sending or faxing your request to me?", 1],
["About when are you publishing this book?", 1],
["May I record the interview?", 1],
["We offer the best price anywhere.", 0],
]
実装
各Layerの構造を記載していく。
# 各Layerの設定
import numpy as np
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
for i, word_id in enumerate(self.idx):
dW[word_id] += dout[i]
return None
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2)
db = np.sum(dt, axis=0)
dWh = np.dot(h_prev.T, dt)
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
class Affine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
W, b = self.params
out = np.dot(x, W) + b
self.x = x
return out
def backward(self, dout):
W, b = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
db = np.sum(dout, axis=0)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
分類機はsoftmax関数を使用。損失関数はCrossEntropyを用いる。
# クラス分類層と損失関数の定義
# 分類機はSoftmaxなので、他クラス分類の場合はoutput_sizeをクラス数に変更するだけで良いです。
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
result = -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
return result
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
class SoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.y= None # softmaxの出力
self.t = None # 教師ラベル
def forward(self, x, t):
self.t = t
self.y = softmax(x)
# 教師ラベルがone-hotベクトルの場合、正解のインデックスに変換
if self.t.size == self.y.size:
self.t = self.t.argmax(axis=1)
loss = cross_entropy_error(self.y, self.t)
return loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx *= dout
dx = dx / batch_size
return dx
class RnnModel:
def __init__(self, vocab_size, embed_size, hidden_size, out_size):
# クラスの初期化
# :param vocab_size: 単語数
# :param embed_size: 埋め込みベクトルサイズ
# :param hidden_size: 隠れ層サイズ
# :param out_size: 出力層サイズ
V, E, H, O = vocab_size, embed_size, hidden_size, out_size
rn = np.random.randn
self.H = H
self.embed_W = (rn(V,E) / 100).astype("f")
self.rnn_Wx = (rn(E,H) / np.sqrt(E)).astype("f")
self.rnn_Wh = (rn(H,H) / np.sqrt(H)).astype("f")
self.rnn_b = np.zeros(H).astype("f")
self.affine_W = (rn(H,O) / np.sqrt(H)).astype("f")
self.affine_b = np.zeros(O).astype("f")
# 内部状態行列
self.h = None
self.layers = [
Embedding(self.embed_W),
RNN(self.rnn_Wx, self.rnn_Wh, self.rnn_b),
Affine(self.affine_W, self.affine_b)
]
self.embedding_layer = self.layers[0]
self.rnn_layer = self.layers[1]
self.affine_layer = self.layers[2]
self.loss_layer = SoftmaxWithLoss()
self.params, self.grads = [],[]
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, x):
N,T = x.shape
H = self.H
x = x.T
self.h = np.zeros((N,H), dtype="f")
for time, word in enumerate(x):
e = self.embedding_layer.forward(word)
rnn_layer = RNN(self.rnn_Wx, self.rnn_Wh, self.rnn_b)
self.h = rnn_layer.forward(e, self.h)
y = self.affine_layer.forward(self.h)
y = softmax(y)
return y
def forward(self, x, t):
N, T = x.shape
H = self.H
self.x = x
x = x.T
self.layers = []
self.hs = np.empty((N,T,H), dtype="f")
self.h = np.zeros((N,H), dtype="f")
for time, word in enumerate(x):
e = self.embedding_layer.forward(word)
layer = RNN(self.rnn_Wx, self.rnn_Wh, self.rnn_b)
self.h = layer.forward(e, self.h)
self.hs[:,time,:] = self.h
self.layers.append(layer)
y = self.affine_layer.forward(self.h)
loss = self.loss_layer.forward(y, t)
return loss
def backward(self, dh=1):
dh = self.loss_layer.backward(dh)
dh = self.affine_layer.backward(dh)
x = self.x.T
for i, word in enumerate(reversed(x)):
time = len(x) - 1 - i
layer = self.layers[time]
dx, dh = layer.backward(dh)
dx = self.embedding_layer.backward(dx)
return dx
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
OptimizerはAdamを使います。スパースなベクトルを扱う場合は、AdaGradやAdamなどの相性が良いようです。(ここが参考になります)
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = [], []
for param in params:
self.m.append(np.zeros_like(param))
self.v.append(np.zeros_like(param))
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for i in range(len(params)):
self.m[i] += (1 - self.beta1) * (grads[i] - self.m[i])
self.v[i] += (1 - self.beta2) * (grads[i]**2 - self.v[i])
params[i] -= lr_t * self.m[i] / (np.sqrt(self.v[i]) + 1e-7)
続いて、テキストの前処理関数をいくつか用意します。
import re
import numpy as np
# テキストから不要な要素を取り除く
def convert_sentence_to_words(sentence):
stopwords = ["i", "a", "an", "the", "and", "or", "if", "is", "are", "am", "it", "this", "that", "of", "from", "in", "on"]
sentence = sentence.lower() # 小文字化
sentence = sentence.replace("\n", "") # 改行削除
sentence = re.sub(re.compile("[!-\/:-@[-`{-~]"), " ", sentence) # 記号をスペースに置き換える
sentence = sentence.split(" ") # スペースで区切る
sentence_words = []
for word in sentence:
if (re.compile(r"^.*[0-9]+.*$").fullmatch(word) is not None):
continue
if word in stopwords:
continue
sentence_words.append(word)
return sentence_words
# 単語をIDに変換する単語辞書を生成する
def create_word_id_dict(sentence_list):
word_to_id = {}
for sentence in sentence_list:
sentence_words = convert_sentence_to_words(sentence)
for word in sentence_words:
if word not in word_to_id:
word_to_id[word] = len(word_to_id)
return word_to_id
# 文章をID列に変換する
def convert_sentences_to_ids(sentence_list, word_to_id):
sentence_id_vec = []
for sentence in sentence_list:
sentence_words = convert_sentence_to_words(sentence)
sentence_ids = []
for word in sentence_words:
if word in word_to_id:
sentence_ids.append(word_to_id[word])
else:
sentence_ids.append(-1)
sentence_id_vec.append(sentence_ids)
return sentence_id_vec
# 文章はそれぞれ長さが違うので、前パディングして固定長の系列にする
# 前パディングなのは、RNNの構造上、後ろにあるデータのほうが反映されやすいため
def padding_sentence(sentence_id_vec):
max_sentence_size = 0
for sentence_vec in sentence_id_vec:
if max_sentence_size < len(sentence_vec):
max_sentence_size = len(sentence_vec)
for sentence_ids in sentence_id_vec:
while len(sentence_ids) < max_sentence_size:
sentence_ids.insert(0,-1)
return sentence_id_vec
訓練
# ハイパーパラメータの設定
vocab_size = len(word_to_id)
embed_size = 200
hidden_size = 200
out_size = 2
lr = 1e-3
batch_size = 5
max_epochs = 300
data_size = len(data)
max_iters = data_size // batch_size
model = RnnModel(vocab_size, embed_size, hidden_size, out_size)
optimizer = Adam(lr)
# Numpy配列に変換する必要がある
x = np.array(sentence_id_vec)
t = np.array([label[1] for label in data])
total_loss = 0
loss_count = 0
for epoch in range(max_epochs):
for iters in range(max_iters):
batch_x = x[iters*batch_size:(iters+1)*batch_size]
batch_t = t[iters*batch_size:(iters+1)*batch_size]
loss = model.forward(batch_x, batch_t)
model.backward()
optimizer.update(model.params, model.grads)
total_loss += loss
loss_count += 1
if (iters+1) % 10 == 0:
avg_loss = total_loss / loss_count
print("| epoch %d | iter %d / %d | loss %.5f" % (epoch+1, iters, max_iters, avg_loss))
total_loss, loss_count = 0,0
評価
test_data = [
["All products come with a 10-year warranty.", 0],
["It sounds good, however, is made to still think; seem to have a problem.", 0],
["Why do you need to change the unit price?", 1],
["Could you please tell me the gist of the article you are writing?", 1]
]
test_sentence_list = [s[0] for s in test_data]
test_sentence_id_vec = convert_sentences_to_ids(test_sentence_list, word_to_id)
test_sentence_id_vec = padding_sentence(test_sentence_id_vec)
for test_sentence_id in test_sentence_id_vec:
query = np.array(test_sentence_id).reshape(1,15)
result = model.predict(query)
print(result)
print(result.argmax())
▼結果
[[0.5272751 0.4727249]]
0
[[0.60909534 0.39090466]]
0
[[0.11664882 0.88335115]]
1
[[0.46186632 0.5381337 ]]
1
それなりに評価できそうですね。
まとめ
以上、ゼロからRNNで文章分類モデルを構築してみました。
今回は単純なRNNでしたが、RNNユニットをLSTMユニットに取り替えればLSTMネットワークになりますし、Attention機構を組み込んだ場合の性能も気になります。
次は、CNNによる文章分類をゼロから作ってみたいですね。