自分の勉強用に、沖本竜義「経済・ファイナンスデータの計量経済分析」の章末問題をpythonで解いてみました。
jupyter notebook上で記述したものをほぼそのまま載せてあります。
ソースコードの細かい説明は省いてありますが、今後余裕があれば説明を加えようと思います。
こちらの記事は第7章の章末問題を解いたものになります。
第1章、第2章、第4章、第5章、第6章も公開しています。
今回、多変量GARCHモデルを扱えるpythonのモジュールが見当たらず、7.5をpythonで解答することを断念しました。もし、多変量GARCHモデルを扱えるモジュールをご存知の方がいましたらご教授いただけますと有り難いです。
また、第8章の章末問題にも挑戦しましたが、閾値モデルを扱えるモジュールが見当たらないこと及びマルコフ転換モデルをベクトルに対して扱えるモジュールが見当たらないことから、pythonで解答することを断念しました。もし、閾値モデルやマルコフ転換モデルを扱えるモジュールをご存知の方がいましたらご教授いただけますと有り難いです。
この辺まで来るとRには敵わないという感じでしょうか...
兎も角、今回で『pythonで「経済・ファイナンスデータの計量時系列分析」の章末問題を解く』シリーズは最後となります。ここまで読んでいただき、ありがとうございました。
各種設定・モジュールのインポート
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import acf
from statsmodels.stats.diagnostic import acorr_ljungbox
from arch import arch_model
import matplotlib as mpl
font = {"family":"IPAexGothic"}
mpl.rc('font', **font)
plt.rcParams["font.size"] = 12
7.4
(1)
ファイルをインポートする
msci = pd.read_csv('./input/msci_day.csv')
print(msci.shape)
msci.head()
(1391, 8)
| Date | ca | fr | ge | it | jp | uk | us | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2003/1/1 | 560.099 | 902.081 | 724.932 | 290.187 | 1593.175 | 791.076 | 824.583 |
| 1 | 2003/1/2 | 574.701 | 927.206 | 768.150 | 296.963 | 1578.214 | 797.813 | 852.219 |
| 2 | 2003/1/3 | 580.212 | 929.297 | 768.411 | 298.757 | 1578.411 | 800.175 | 851.935 |
| 3 | 2003/1/6 | 589.619 | 943.002 | 788.164 | 303.273 | 1619.700 | 803.966 | 871.515 |
| 4 | 2003/1/7 | 585.822 | 923.785 | 774.054 | 297.892 | 1590.951 | 793.625 | 865.992 |
Date列をdatetime型に変換してecoのDatetimeIndexとする
msci.index=pd.to_datetime(msci.Date.values)
msci.drop('Date',axis=1,inplace=True)
msci.head()
| ca | fr | ge | it | jp | uk | us | |
|---|---|---|---|---|---|---|---|
| 2003-01-01 | 560.099 | 902.081 | 724.932 | 290.187 | 1593.175 | 791.076 | 824.583 |
| 2003-01-02 | 574.701 | 927.206 | 768.150 | 296.963 | 1578.214 | 797.813 | 852.219 |
| 2003-01-03 | 580.212 | 929.297 | 768.411 | 298.757 | 1578.411 | 800.175 | 851.935 |
| 2003-01-06 | 589.619 | 943.002 | 788.164 | 303.273 | 1619.700 | 803.966 | 871.515 |
| 2003-01-07 | 585.822 | 923.785 | 774.054 | 297.892 | 1590.951 | 793.625 | 865.992 |
欠損データ(e.g. 2005-01-01)があるので、グラフの目盛用にその年で1番最初の日かどうかをカラムに加える
msci['is_year_start']=[msci.index[i].year!=msci.index[i-1].year for i in range(msci.shape[0])]
株式収益率(%)の系列を対数差分を用いて作成する
title=['ca','fr','ge','it','jp','uk','us']
for i in range(len(title)):
msci['per_%s'%title[i]]=np.log(msci[title[i]]).diff()
msci.head()
| ca | fr | ge | it | jp | uk | us | is_year_start | per_ca | per_fr | per_ge | per_it | per_jp | per_uk | per_us | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2003-01-01 | 560.099 | 902.081 | 724.932 | 290.187 | 1593.175 | 791.076 | 824.583 | True | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2003-01-02 | 574.701 | 927.206 | 768.150 | 296.963 | 1578.214 | 797.813 | 852.219 | False | 0.025736 | 0.027471 | 0.057907 | 0.023082 | -0.009435 | 0.008480 | 0.032966 |
| 2003-01-03 | 580.212 | 929.297 | 768.411 | 298.757 | 1578.411 | 800.175 | 851.935 | False | 0.009544 | 0.002253 | 0.000340 | 0.006023 | 0.000125 | 0.002956 | -0.000333 |
| 2003-01-06 | 589.619 | 943.002 | 788.164 | 303.273 | 1619.700 | 803.966 | 871.515 | False | 0.016083 | 0.014640 | 0.025381 | 0.015003 | 0.025822 | 0.004727 | 0.022723 |
| 2003-01-07 | 585.822 | 923.785 | 774.054 | 297.892 | 1590.951 | 793.625 | 865.992 | False | -0.006461 | -0.020589 | -0.018065 | -0.017902 | -0.017909 | -0.012946 | -0.006357 |
アメリカの株式収益率のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf(msci['per_us'][1:])[1:21])
ax.set_ylim(-0.2,0.2)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-2,3))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(msci.shape[0]-1),-1.96/np.sqrt(msci.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
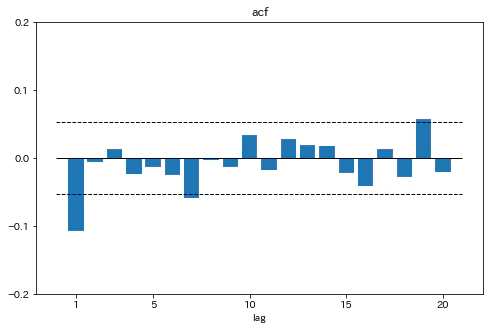
1期(と7期と19期)に大きな自己相関がみられる
(2)
アメリカの株式収益率の2乗の系列を作成する
msci['per_sq_us']=msci['per_us']**2
アメリカの株式収益率の2乗のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf(msci['per_sq_us'][1:])[1:21])
ax.set_ylim(-0.1,0.3)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-1,4))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(msci.shape[0]-1),-1.96/np.sqrt(msci.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
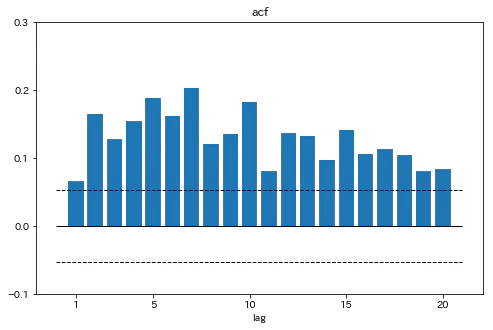
20期までの全てで大きな自己相関がみられる
(3)
アメリカの株式収益率のデータに対し、AR(1)-GARCH(1,1)モデルを推定する
(尚、系列の値を100倍しているのは、最適化を収束させるためです:https://quant.stackexchange.com/questions/32350/fitting-garch1-1-in-python-for-moderately-large-data-sets)
garch=arch_model(100*msci['per_us'][1:],mean='AR',lags=1,vol='GARCH',p=1,o=0,q=1,dist='studentst').fit()
Iteration: 1, Func. Count: 8, Neg. LLF: 1626.1493851808236
Iteration: 2, Func. Count: 20, Neg. LLF: 1624.472806709472
Iteration: 3, Func. Count: 31, Neg. LLF: 1624.1048230411657
Iteration: 4, Func. Count: 42, Neg. LLF: 1623.8180932803173
Iteration: 5, Func. Count: 52, Neg. LLF: 1623.5731061263423
Iteration: 6, Func. Count: 61, Neg. LLF: 1621.7085398302058
Iteration: 7, Func. Count: 70, Neg. LLF: 1621.477983394893
Iteration: 8, Func. Count: 79, Neg. LLF: 1621.1965432813513
Iteration: 9, Func. Count: 88, Neg. LLF: 1621.154364449716
Iteration: 10, Func. Count: 97, Neg. LLF: 1621.1441778563244
Iteration: 11, Func. Count: 105, Neg. LLF: 1621.1435809913812
Iteration: 12, Func. Count: 113, Neg. LLF: 1621.1434081176585
Iteration: 13, Func. Count: 121, Neg. LLF: 1621.1433861157093
Optimization terminated successfully. (Exit mode 0)
Current function value: 1621.1433861157084
Iterations: 13
Function evaluations: 121
Gradient evaluations: 13
結果を表示する
garch.summary()
| Dep. Variable: | per_us | R-squared: | 0.010 |
|---|---|---|---|
| Mean Model: | AR | Adj. R-squared: | 0.009 |
| Vol Model: | GARCH | Log-Likelihood: | -1621.14 |
| Distribution: | Standardized Student's t | AIC: | 3254.29 |
| Method: | Maximum Likelihood | BIC: | 3285.70 |
| No. Observations: | 1389 | ||
| Date: | Sun, Feb 18 2018 | Df Residuals: | 1383 |
| Time: | 23:55:20 | Df Model: | 6 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| Const | 0.0595 | 1.904e-02 | 3.127 | 1.765e-03 | [2.222e-02,9.684e-02] |
| per_us[1] | -0.0734 | 2.386e-02 | -3.076 | 2.101e-03 | [ -0.120,-2.661e-02] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | 5.7558e-03 | 3.979e-03 | 1.446 | 0.148 | [-2.044e-03,1.356e-02] |
| alpha[1] | 0.0490 | 1.471e-02 | 3.333 | 8.582e-04 | [2.020e-02,7.784e-02] |
| beta[1] | 0.9432 | 1.803e-02 | 52.322 | 0.000 | [ 0.908, 0.979] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| nu | 7.9484 | 2.074 | 3.833 | 1.267e-04 | [ 3.884, 12.013] |
(4)
アメリカの株式収益率のデータに対し、AR(1)-GJR(1,1)モデルを推定する
gjr=arch_model(100*msci['per_us'][1:],mean='AR',lags=1,vol='GARCH',p=1,o=1,q=1,dist='studentst').fit()
Iteration: 1, Func. Count: 9, Neg. LLF: 1608.311864669829
Iteration: 2, Func. Count: 21, Neg. LLF: 1607.6177366714319
Iteration: 3, Func. Count: 34, Neg. LLF: 1607.4674097311886
Iteration: 4, Func. Count: 46, Neg. LLF: 1607.2432887204382
Iteration: 5, Func. Count: 58, Neg. LLF: 1607.2321387222742
Iteration: 6, Func. Count: 68, Neg. LLF: 1605.550623830057
Iteration: 7, Func. Count: 78, Neg. LLF: 1605.0461425292215
Iteration: 8, Func. Count: 88, Neg. LLF: 1604.6568827154686
Iteration: 9, Func. Count: 98, Neg. LLF: 1604.4903663343728
Iteration: 10, Func. Count: 107, Neg. LLF: 1603.7963336935013
Iteration: 11, Func. Count: 116, Neg. LLF: 1603.7028334036809
Iteration: 12, Func. Count: 125, Neg. LLF: 1603.6926759295156
Iteration: 13, Func. Count: 134, Neg. LLF: 1603.6871967349107
Iteration: 14, Func. Count: 143, Neg. LLF: 1603.6858039263102
Iteration: 15, Func. Count: 152, Neg. LLF: 1603.6856369758025
Iteration: 16, Func. Count: 161, Neg. LLF: 1603.6856308684942
Optimization terminated successfully. (Exit mode 0)
Current function value: 1603.6856308684942
Iterations: 16
Function evaluations: 161
Gradient evaluations: 16
結果を表示する
gjr.summary()
| Dep. Variable: | per_us | R-squared: | 0.010 |
|---|---|---|---|
| Mean Model: | AR | Adj. R-squared: | 0.009 |
| Vol Model: | GJR-GARCH | Log-Likelihood: | -1603.69 |
| Distribution: | Standardized Student's t | AIC: | 3221.37 |
| Method: | Maximum Likelihood | BIC: | 3258.03 |
| No. Observations: | 1389 | ||
| Date: | Sun, Feb 18 2018 | Df Residuals: | 1382 |
| Time: | 23:55:20 | Df Model: | 7 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| Const | 0.0429 | 1.986e-02 | 2.158 | 3.092e-02 | [3.934e-03,8.180e-02] |
| per_us[1] | -0.0698 | 2.380e-02 | -2.933 | 3.360e-03 | [ -0.116,-2.315e-02] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | 6.4152e-03 | 7.926e-03 | 0.809 | 0.418 | [-9.119e-03,2.195e-02] |
| alpha[1] | 1.2537e-10 | 3.358e-02 | 3.734e-09 | 1.000 | [-6.581e-02,6.581e-02] |
| gamma[1] | 0.0857 | 3.043e-02 | 2.817 | 4.848e-03 | [2.608e-02, 0.145] |
| beta[1] | 0.9453 | 5.263e-02 | 17.962 | 3.868e-72 | [ 0.842, 1.048] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| nu | 8.8703 | 2.844 | 3.119 | 1.817e-03 | [ 3.296, 14.445] |
レバレッジ効果を表すgammaが正なのでレバレッジ効果は有効だと考えられる
(5)
残差について自己相関検定を行う
acf_=acf(gjr.resid[1:])[1:]
q_m=acorr_ljungbox(gjr.resid[1:])[0]
p_value=acorr_ljungbox(gjr.resid[1:])[1]
lag=range(1,41)
test=pd.DataFrame({'lag':lag,'autocorr':acf_,'Q(m)':q_m,'P_value':p_value})
test[['lag','autocorr','Q(m)','P_value']].iloc[0:10,:].T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| lag | 1.000000 | 2.000000 | 3.000000 | 4.000000 | 5.000000 | 6.000000 | 7.000000 | 8.000000 | 9.000000 | 10.000000 |
| autocorr | -0.039489 | -0.019336 | 0.013273 | -0.018904 | -0.023108 | -0.031006 | -0.062719 | -0.010821 | -0.006836 | 0.033678 |
| Q(m) | 2.170625 | 2.691466 | 2.937043 | 3.435585 | 4.181064 | 5.524131 | 11.023673 | 11.187490 | 11.252913 | 12.842065 |
| P_value | 0.140669 | 0.260349 | 0.401434 | 0.487740 | 0.523653 | 0.478545 | 0.137590 | 0.191300 | 0.258771 | 0.232637 |
残差のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf_[1:21])
ax.set_ylim(-0.1,0.1)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-1,2))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(gjr.resid.shape[0]-1),-1.96/np.sqrt(gjr.resid.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
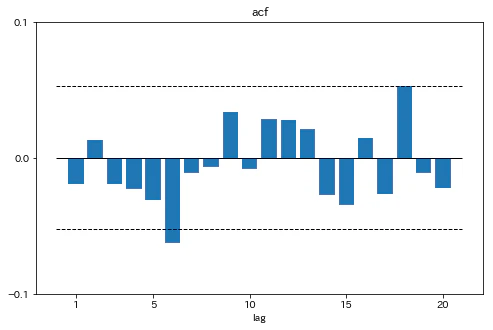
かばん検定の結果とコレログラムから、残差に大きな自己相関がないことが示唆された
(6)
アメリカの株式収益率のデータに対し、AR(1)-EGARCH(1,1)モデルを推定する
egarch=arch_model(100*msci['per_us'][1:],mean='AR',lags=1,vol='EGARCH',p=1,o=1,q=1,dist='studentst').fit()
Iteration: 1, Func. Count: 9, Neg. LLF: 1606.2314288376633
Iteration: 2, Func. Count: 22, Neg. LLF: 1604.722938615969
Iteration: 3, Func. Count: 35, Neg. LLF: 1604.5984134498178
Iteration: 4, Func. Count: 48, Neg. LLF: 1604.4955446095305
Iteration: 5, Func. Count: 61, Neg. LLF: 1604.4129540561485
Iteration: 6, Func. Count: 73, Neg. LLF: 1604.4099059723555
Iteration: 7, Func. Count: 83, Neg. LLF: 1603.58238963428
Iteration: 8, Func. Count: 95, Neg. LLF: 1603.5013215028691
Iteration: 9, Func. Count: 105, Neg. LLF: 1603.1026401369263
Iteration: 10, Func. Count: 114, Neg. LLF: 1603.0419397065198
Iteration: 11, Func. Count: 123, Neg. LLF: 1603.023758905803
Iteration: 12, Func. Count: 132, Neg. LLF: 1603.0226167218484
Iteration: 13, Func. Count: 141, Neg. LLF: 1603.022421728096
Iteration: 14, Func. Count: 150, Neg. LLF: 1603.0224056522998
Optimization terminated successfully. (Exit mode 0)
Current function value: 1603.0224049277822
Iterations: 14
Function evaluations: 151
Gradient evaluations: 14
結果を表示する
egarch.summary()
| Dep. Variable: | per_us | R-squared: | 0.010 |
|---|---|---|---|
| Mean Model: | AR | Adj. R-squared: | 0.009 |
| Vol Model: | EGARCH | Log-Likelihood: | -1603.02 |
| Distribution: | Standardized Student's t | AIC: | 3220.04 |
| Method: | Maximum Likelihood | BIC: | 3256.70 |
| No. Observations: | 1389 | ||
| Date: | Sun, Feb 18 2018 | Df Residuals: | 1382 |
| Time: | 23:55:21 | Df Model: | 7 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| Const | 0.0423 | 1.896e-02 | 2.230 | 2.574e-02 | [5.121e-03,7.943e-02] |
| per_us[1] | -0.0670 | 2.389e-02 | -2.803 | 5.071e-03 | [ -0.114,-2.013e-02] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | -5.1881e-03 | 3.896e-03 | -1.331 | 0.183 | [-1.282e-02,2.449e-03] |
| alpha[1] | 0.0639 | 1.808e-02 | 3.535 | 4.071e-04 | [2.848e-02,9.935e-02] |
| gamma[1] | -0.0937 | 2.074e-02 | -4.517 | 6.271e-06 | [ -0.134,-5.303e-02] |
| beta[1] | 0.9892 | 6.402e-03 | 154.511 | 0.000 | [ 0.977, 1.002] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| nu | 8.3047 | 2.295 | 3.619 | 2.957e-04 | [ 3.807, 12.802] |
レバレッジ効果を表すgammaが負なのでレバレッジ効果は有効だと考えられる
(7)
残差について自己相関検定を行う
acf_=acf(egarch.resid[1:])[1:]
q_m=acorr_ljungbox(egarch.resid[1:])[0]
p_value=acorr_ljungbox(egarch.resid[1:])[1]
lag=range(1,41)
test=pd.DataFrame({'lag':lag,'autocorr':acf_,'Q(m)':q_m,'P_value':p_value})
test[['lag','autocorr','Q(m)','P_value']].iloc[0:10,:].T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| lag | 1.000000 | 2.000000 | 3.000000 | 4.000000 | 5.000000 | 6.000000 | 7.000000 | 8.000000 | 9.000000 | 10.000000 |
| autocorr | -0.042277 | -0.019060 | 0.013367 | -0.018896 | -0.022973 | -0.030761 | -0.062600 | -0.010608 | -0.006909 | 0.033732 |
| Q(m) | 2.488034 | 2.994096 | 3.243181 | 3.741285 | 4.478069 | 5.799967 | 11.278587 | 11.436028 | 11.502862 | 13.097075 |
| P_value | 0.114715 | 0.223790 | 0.355629 | 0.442150 | 0.482823 | 0.445967 | 0.126920 | 0.178196 | 0.242807 | 0.218295 |
残差のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf_[1:21])
ax.set_ylim(-0.1,0.1)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-1,2))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(egarch.resid.shape[0]-1),-1.96/np.sqrt(egarch.resid.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
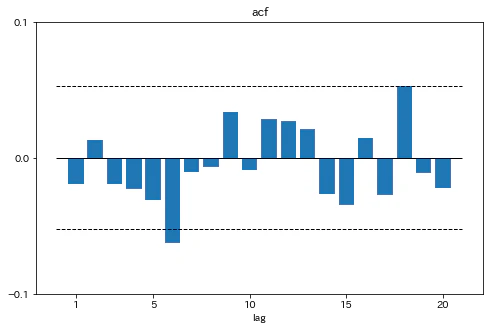
かばん検定の結果とコレログラムから、残差に大きな自己相関がないことが示唆された
(8)
他国の例として、日本について同様の分析を行ってみる
日本の株式収益率のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf(msci['per_jp'][1:])[1:21])
ax.set_ylim(-0.2,0.2)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-2,3))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(msci.shape[0]-1),-1.96/np.sqrt(msci.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
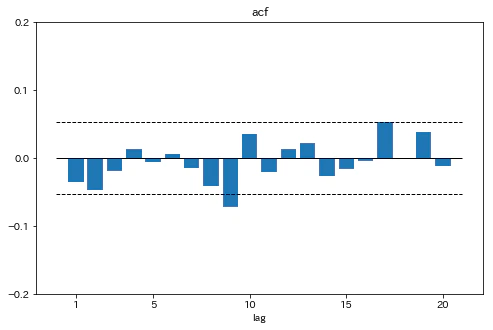
大きな相関はほぼみられない
日本の株式収益率の2乗の系列を作成する
msci['per_sq_jp']=msci['per_jp']**2
日本の株式収益率の2乗のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf(msci['per_sq_jp'][1:])[1:21])
ax.set_ylim(-0.1,0.3)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-1,4))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(msci.shape[0]-1),-1.96/np.sqrt(msci.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
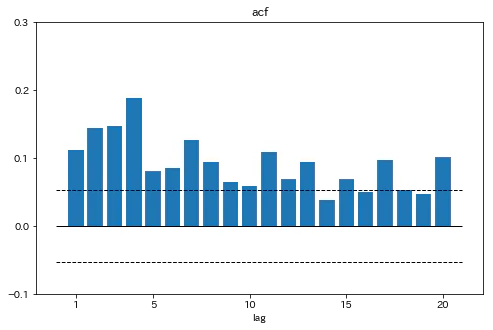
20期までのほぼ全てで大きな自己相関がみられる
日本の株式収益率のデータに対し、AR(1)-GARCH(1,1)モデルを推定する
garch=arch_model(100*msci['per_jp'][1:],mean='AR',lags=1,vol='GARCH',p=1,o=0,q=1,dist='studentst').fit()
Iteration: 1, Func. Count: 8, Neg. LLF: 2241.7021893723913
Iteration: 2, Func. Count: 21, Neg. LLF: 2239.6009631225484
Iteration: 3, Func. Count: 32, Neg. LLF: 2239.5669687725062
Iteration: 4, Func. Count: 42, Neg. LLF: 2239.41500078318
Iteration: 5, Func. Count: 53, Neg. LLF: 2239.372629045961
Iteration: 6, Func. Count: 62, Neg. LLF: 2238.6334134962735
Iteration: 7, Func. Count: 71, Neg. LLF: 2238.2828616416014
Iteration: 8, Func. Count: 80, Neg. LLF: 2237.9761251171585
Iteration: 9, Func. Count: 88, Neg. LLF: 2237.9050544390084
Iteration: 10, Func. Count: 96, Neg. LLF: 2237.891675885119
Iteration: 11, Func. Count: 104, Neg. LLF: 2237.891298489836
Iteration: 12, Func. Count: 112, Neg. LLF: 2237.8911050580737
Iteration: 13, Func. Count: 120, Neg. LLF: 2237.890817179561
Iteration: 14, Func. Count: 128, Neg. LLF: 2237.8907235573656
Iteration: 15, Func. Count: 136, Neg. LLF: 2237.890709586687
Optimization terminated successfully. (Exit mode 0)
Current function value: 2237.890708986084
Iterations: 15
Function evaluations: 137
Gradient evaluations: 15
結果を表示する
garch.summary()
| Dep. Variable: | per_jp | R-squared: | 0.001 |
|---|---|---|---|
| Mean Model: | AR | Adj. R-squared: | 0.000 |
| Vol Model: | GARCH | Log-Likelihood: | -2237.89 |
| Distribution: | Standardized Student's t | AIC: | 4487.78 |
| Method: | Maximum Likelihood | BIC: | 4519.20 |
| No. Observations: | 1389 | ||
| Date: | Sun, Feb 18 2018 | Df Residuals: | 1383 |
| Time: | 23:55:22 | Df Model: | 6 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| Const | 0.0633 | 3.015e-02 | 2.101 | 3.565e-02 | [4.249e-03, 0.122] |
| per_jp[1] | -0.0271 | 2.663e-02 | -1.017 | 0.309 | [-7.930e-02,2.510e-02] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | 0.0442 | 1.557e-02 | 2.836 | 4.566e-03 | [1.364e-02,7.467e-02] |
| alpha[1] | 0.0699 | 1.421e-02 | 4.922 | 8.573e-07 | [4.209e-02,9.780e-02] |
| beta[1] | 0.9034 | 1.776e-02 | 50.873 | 0.000 | [ 0.869, 0.938] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| nu | 11.0611 | 3.152 | 3.509 | 4.492e-04 | [ 4.884, 17.239] |
日本の株式収益率のデータに対し、AR(1)-GJR(1,1)モデルを推定する
gjr=arch_model(100*msci['per_jp'][1:],mean='AR',lags=1,vol='GARCH',p=1,o=1,q=1,dist='studentst').fit()
Iteration: 1, Func. Count: 9, Neg. LLF: 2233.229679269623
Iteration: 2, Func. Count: 22, Neg. LLF: 2232.928611427178
Iteration: 3, Func. Count: 35, Neg. LLF: 2232.841708242234
Iteration: 4, Func. Count: 46, Neg. LLF: 2232.6285781043343
Iteration: 5, Func. Count: 57, Neg. LLF: 2232.520062528829
Iteration: 6, Func. Count: 68, Neg. LLF: 2231.847921969732
Iteration: 7, Func. Count: 78, Neg. LLF: 2230.185568521398
Iteration: 8, Func. Count: 88, Neg. LLF: 2230.168176996417
Iteration: 9, Func. Count: 98, Neg. LLF: 2230.0392175172383
Iteration: 10, Func. Count: 107, Neg. LLF: 2230.019475088293
Iteration: 11, Func. Count: 116, Neg. LLF: 2229.9967310548327
Iteration: 12, Func. Count: 125, Neg. LLF: 2229.979300462734
Iteration: 13, Func. Count: 134, Neg. LLF: 2229.958753628938
Iteration: 14, Func. Count: 143, Neg. LLF: 2229.952478080927
Iteration: 15, Func. Count: 152, Neg. LLF: 2229.9518094040345
Iteration: 16, Func. Count: 161, Neg. LLF: 2229.951780382489
Iteration: 17, Func. Count: 170, Neg. LLF: 2229.9517777982396
Optimization terminated successfully. (Exit mode 0)
Current function value: 2229.9517777982396
Iterations: 17
Function evaluations: 170
Gradient evaluations: 17
結果を表示する
gjr.summary()
| Dep. Variable: | per_jp | R-squared: | 0.001 |
|---|---|---|---|
| Mean Model: | AR | Adj. R-squared: | 0.000 |
| Vol Model: | GJR-GARCH | Log-Likelihood: | -2229.95 |
| Distribution: | Standardized Student's t | AIC: | 4473.90 |
| Method: | Maximum Likelihood | BIC: | 4510.56 |
| No. Observations: | 1389 | ||
| Date: | Sun, Feb 18 2018 | Df Residuals: | 1382 |
| Time: | 23:55:22 | Df Model: | 7 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| Const | 0.0439 | 3.056e-02 | 1.435 | 0.151 | [-1.605e-02, 0.104] |
| per_jp[1] | -0.0156 | 2.777e-02 | -0.562 | 0.574 | [-7.004e-02,3.883e-02] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | 0.0659 | 2.402e-02 | 2.744 | 6.064e-03 | [1.884e-02, 0.113] |
| alpha[1] | 0.0176 | 1.494e-02 | 1.179 | 0.239 | [-1.167e-02,4.688e-02] |
| gamma[1] | 0.1083 | 4.011e-02 | 2.700 | 6.944e-03 | [2.966e-02, 0.187] |
| beta[1] | 0.8861 | 2.325e-02 | 38.110 | 0.000 | [ 0.841, 0.932] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| nu | 13.3231 | 4.560 | 2.922 | 3.480e-03 | [ 4.386, 22.260] |
レバレッジ効果を表すgammaが正なのでレバレッジ効果は有効だと考えられる
残差について自己相関検定を行う
acf_=acf(gjr.resid[1:])[1:]
q_m=acorr_ljungbox(gjr.resid[1:])[0]
p_value=acorr_ljungbox(gjr.resid[1:])[1]
lag=range(1,41)
test=pd.DataFrame({'lag':lag,'autocorr':acf_,'Q(m)':q_m,'P_value':p_value})
test[['lag','autocorr','Q(m)','P_value']].iloc[0:10,:].T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| lag | 1.000000 | 2.000000 | 3.000000 | 4.000000 | 5.000000 | 6.000000 | 7.000000 | 8.000000 | 9.000000 | 10.000000 |
| autocorr | -0.020387 | -0.047532 | -0.021293 | 0.011971 | -0.006298 | 0.005952 | -0.015552 | -0.042520 | -0.071958 | 0.033569 |
| Q(m) | 0.578543 | 3.725755 | 4.357805 | 4.557714 | 4.613085 | 4.662582 | 5.000718 | 7.530104 | 14.779644 | 16.358463 |
| P_value | 0.446884 | 0.155225 | 0.225330 | 0.335759 | 0.464897 | 0.587758 | 0.659876 | 0.480661 | 0.097169 | 0.089821 |
残差のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf_[1:21])
ax.set_ylim(-0.1,0.1)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-1,2))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(gjr.resid.shape[0]-1),-1.96/np.sqrt(gjr.resid.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
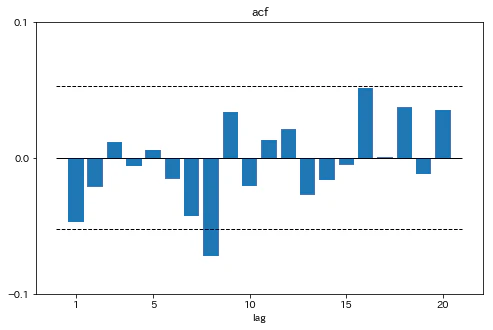
かばん検定の結果とコレログラムから、残差に大きな自己相関がないことが示唆された
日本の株式収益率のデータに対し、AR(1)-EGARCH(1,1)モデルを推定する
egarch=arch_model(100*msci['per_jp'][1:],mean='AR',lags=1,vol='EGARCH',p=1,o=1,q=1,dist='studentst').fit()
Iteration: 1, Func. Count: 9, Neg. LLF: 2235.3989385014665
Iteration: 2, Func. Count: 22, Neg. LLF: 2232.6544335552594
Iteration: 3, Func. Count: 35, Neg. LLF: 2232.024333146882
Iteration: 4, Func. Count: 49, Neg. LLF: 2231.816316045613
Iteration: 5, Func. Count: 61, Neg. LLF: 2230.9901837255084
Iteration: 6, Func. Count: 73, Neg. LLF: 2230.5593467621834
Iteration: 7, Func. Count: 85, Neg. LLF: 2230.544616375196
Iteration: 8, Func. Count: 94, Neg. LLF: 2230.4151623044745
Iteration: 9, Func. Count: 103, Neg. LLF: 2230.3997454528976
Iteration: 10, Func. Count: 112, Neg. LLF: 2230.3800568523693
Iteration: 11, Func. Count: 121, Neg. LLF: 2230.3655047749085
Iteration: 12, Func. Count: 130, Neg. LLF: 2230.351205705787
Iteration: 13, Func. Count: 139, Neg. LLF: 2230.346520815785
Iteration: 14, Func. Count: 148, Neg. LLF: 2230.3463070242783
Iteration: 15, Func. Count: 157, Neg. LLF: 2230.346284628481
Optimization terminated successfully. (Exit mode 0)
Current function value: 2230.346284628483
Iterations: 15
Function evaluations: 157
Gradient evaluations: 15
結果を表示する
egarch.summary()
| Dep. Variable: | per_jp | R-squared: | 0.001 |
|---|---|---|---|
| Mean Model: | AR | Adj. R-squared: | 0.000 |
| Vol Model: | EGARCH | Log-Likelihood: | -2230.35 |
| Distribution: | Standardized Student's t | AIC: | 4474.69 |
| Method: | Maximum Likelihood | BIC: | 4511.35 |
| No. Observations: | 1389 | ||
| Date: | Sun, Feb 18 2018 | Df Residuals: | 1382 |
| Time: | 23:55:22 | Df Model: | 7 |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| Const | 0.0329 | 3.050e-02 | 1.079 | 0.281 | [-2.688e-02,9.270e-02] |
| per_jp[1] | -0.0179 | 2.713e-02 | -0.661 | 0.509 | [-7.112e-02,3.524e-02] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| omega | 0.0182 | 7.770e-03 | 2.336 | 1.949e-02 | [2.922e-03,3.338e-02] |
| alpha[1] | 0.1567 | 2.346e-02 | 6.679 | 2.400e-11 | [ 0.111, 0.203] |
| gamma[1] | -0.0824 | 2.694e-02 | -3.059 | 2.220e-03 | [ -0.135,-2.961e-02] |
| beta[1] | 0.9618 | 1.418e-02 | 67.822 | 0.000 | [ 0.934, 0.990] |
| coef | std err | t | P>|t| | 95.0% Conf. Int. | |
|---|---|---|---|---|---|
| nu | 13.4900 | 4.671 | 2.888 | 3.878e-03 | [ 4.335, 22.645] |
レバレッジ効果を表すgammaが負なのでレバレッジ効果は有効だと考えられる
残差について自己相関検定を行う
acf_=acf(egarch.resid[1:])[1:]
q_m=acorr_ljungbox(egarch.resid[1:])[0]
p_value=acorr_ljungbox(egarch.resid[1:])[1]
lag=range(1,41)
test=pd.DataFrame({'lag':lag,'autocorr':acf_,'Q(m)':q_m,'P_value':p_value})
test[['lag','autocorr','Q(m)','P_value']].iloc[0:10,:].T
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| lag | 1.000000 | 2.000000 | 3.000000 | 4.000000 | 5.000000 | 6.000000 | 7.000000 | 8.000000 | 9.000000 | 10.000000 |
| autocorr | -0.018168 | -0.047669 | -0.021375 | 0.011909 | -0.006255 | 0.005903 | -0.015637 | -0.042730 | -0.071984 | 0.033357 |
| Q(m) | 0.459477 | 3.624803 | 4.261702 | 4.459549 | 4.514170 | 4.562842 | 4.904705 | 7.459204 | 14.714026 | 16.272994 |
| P_value | 0.497869 | 0.163262 | 0.234556 | 0.347371 | 0.477990 | 0.600971 | 0.671591 | 0.487992 | 0.099097 | 0.092080 |
残差のコレログラムをプロットする
fig,ax=plt.subplots(1,1,figsize=[8,5])
ax.bar(range(1,21),acf_[1:21])
ax.set_ylim(-0.1,0.1)
ax.set_xticks([1,5,10,15,20])
ax.set_yticks(np.asarray(range(-1,2))*0.1)
ax.hlines(0,0,21,linewidth=1)
ax.hlines([1.96/np.sqrt(egarch.resid.shape[0]-1),-1.96/np.sqrt(egarch.resid.shape[0]-1)],0,21,linestyles='dashed',linewidth=1)
ax.set_xlabel('lag')
ax.set_title('acf')
plt.show()
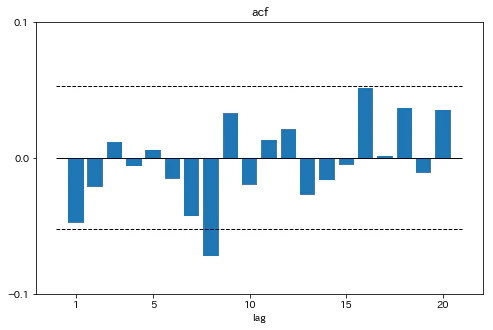
かばん検定の結果とコレログラムから、残差に大きな自己相関がないことが示唆された
7.5
DVEC,DBEKK,CCCの推定を行えるpythonのモジュールを見つけられなかったため、解答を断念しました
ご存知でしたらご教授いただけますと有り難いです...
参考サイト
ARCHのドキュメント
: http://arch.readthedocs.io/en/latest/index.html
arch_modelをフィッティングさせるときに最適化が収束しない時の対処法
:https://quant.stackexchange.com/questions/32350/fitting-garch1-1-in-python-for-moderately-large-data-sets