はじめに
動的モード分解(Dynamic Mode Decomposition: DMD)を使い、動画の背景を分離して、動体の動的モードのみの動画を作成します。
動的モード分解は、主成分分析とフーリエ変換を合わせたような方法です。動的モード分解の詳細解説は、以前書いた記事にリンクがあるので、リンク先を参照ください。
-https://qiita.com/matsxxx/items/5e4b272de821fb1c11e0
環境
- Windows 10 home (CPU:Core i7 Mem:16GB)
- Python(3.7.6)
- Opencv(4.1.1)
- Numpy(1.18.5)
- Scipy(1.5.2)
動的モード分解とは
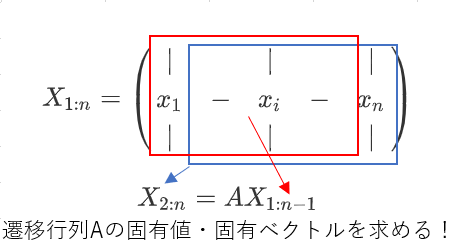
簡単に動的モード分解の手順を紹介をします。動的モード分解は、時系列データから遷移行列の固有値、固有ベクトルを求めて、動的モードを作り出すものです。次元と時間方向の特徴に分解できます。次元方向の特徴は、固有ベクトルに、時間方向の特徴は、固有値の複素数に現れます。
動的モード分解では、遷移行列の固有値、固有ベクトルが、現実的な計算量で求められるよう、実装されています。本記事では、Exact DMDで実装しています。
import scipy.linalg as la
# DMD定義
def dmd(X, Y, truncate=None):#X=X_{1:n-1} Y=X_{2:n}
u2,sig2,vh2 = la.svd(X, False)
r = len(sig2) if truncate is None else truncate
u = u2[:,:r]
sig = np.diag(sig2)[:r,:r]
v = vh2.conj().T[:,:r]
Atil = np.dot(np.dot(np.dot(u.conj().T, Y), v), la.inv(sig))
mu,w = la.eig(Atil)
phi = np.dot(np.dot(np.dot(Y, v), la.inv(sig)), w)#DMD mode
return mu, phi
動画
ここの動画のAtriumを利用しました。歩いている人がいる動画です。120frameから170frameを利用しています。歩いている人と背景を分離します。

import cv2
# 画像のパス
video_path = "./atrium_video.avi"
# 画像読み込み
cap = cv2.VideoCapture(video_path)
# 画像の解像度、フレームレート、フレーム数取得
wid = cap.get(cv2.CAP_PROP_FRAME_WIDTH)#横
hei = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)#縦
fps = cap.get(cv2.CAP_PROP_FPS)#フレームレート
count = cap.get(cv2.CAP_PROP_FRAME_COUNT)#フレーム数
dt = 1/fps#フレーム間秒数
print(f"wid:{wid}", f" hei:{hei}", f" fps:{fps}", f" count:{count}", f"dt:{dt}")
# 利用するフレーム
start_frame =120
end_frame = 170
# 画像解像度を1/4にする(計算量削減のため)
r = 4
# フレーム抜き出し
cat_frames = []
cap.set(cv2.CAP_PROP_POS_FRAMES,start_frame)
for i in range(end_frame - start_frame):
ret, img = cap.read()
if not ret:
print("no image")
break
buf = cv2.cvtColor(cv2.resize(img,(int(wid/r), int(hei/r))), cv2.COLOR_BGR2GRAY).flatten()#
cat_frames.append(buf)
cat_frames = np.array(cat_frames).T#DMDに利用する画像
cap.release()
動画の動的モード分解と背景・動体分離
動画を動的モード分解します。背景は、振動・振幅モードが振幅0、周波数0であるものとしています。動体は、背景以外のものとしています。
# DMDの計算
X1 = cat_frames[:,:-1]
X2 = cat_frames[:,1:]
mu, phi = dmd(X1,X2)
omega = np.log(mu)/dt#振動・振幅モード
# 背景と動体の判定
bg = np.abs(omega) < 1e-2 #背景の抽出
fg = ~bg #動体
phi_bg = phi[:,bg]#背景の動的モード
phi_fg = phi[:,fg]#動体の動的モード
omega_bg = omega[bg]#背景の振動・振幅モード
omega_fg = omega[fg]#動体の振動・振幅モード
背景成分以外の動的モードの再構成
以下の式で、動体モードの動画を再構成します。
$$
X_{dmd}^{fg} = \sum_{k=1}^{n}b_k^{fg}\phi_{k}^{fg}\exp(\omega_k^{fg}t)=\Phi^{fg} diag(\exp(\omega^{fg} t))\mathbf{b}^{fg}
$$
$\Phi^{fg}$ は動体の動的モード行列、$\omega^{fg}$は動体の振動・振幅モード、 動体の動的モード行列の疑似逆行列を、右から$\mathbf{b}^{fg}$の動画初期値に行列積をとった行列です。
# 再構築
phi_fg_pinv = la.pinv(phi_fg)#疑似逆行列。かなり時間がかかる。メモリが足りない場合は、rを大きくしてください。
X_fg = np.zeros((len(omega_fg), end_frame - start_frame), dtype='complex')
b = phi_fg_pinv @ cat_frames[:,0]#初期値
for tt in range(end_frame - start_frame):
X_fg[:,tt] = b * np.exp(omega_fg * dt * tt)
X_fg = phi_fg @ X_fg
# 輝度調整用
lum_max = np.abs(X_fg.real.max())
lum_min = np.abs(X_fg.real.min())
lum_diff = lum_max + lum_min
# 動画作成
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter("out_dmd_fg.mp4", fourcc, fps, (int(wid/r), int(hei/r)))
for tt in range(end_frame - start_frame):
a = X_fg[:,tt].real.reshape(int(hei/r), -1)
a = (a + lum_min)/lum_diff * 255
a = a.astype("uint8")
out_img = np.tile(a, (3,1,1)).transpose((1,2,0))#グレースケールを[wid, hei, 3]の行列に変換する
writer.write(out_img)
writer.release()
結果
背景がなくなり、人だけの動きとなっていることが確認できます。ただ、人の動きに残像が見えます。利用した動画の画像が、50枚しかないせいもあると思いますが、直線的な動きの分解は苦手なようです。


参考文献
- Jodoin, J.-P., Bilodeau, G.-A., Saunier, N., Urban Tracker: Multiple Object Tracking in Urban Mixed Traffic, Accepted for IEEE Winter conference on Applications of Computer Vision (WACV14), Steamboat Springs, Colorado, USA, March 24-26, 2014.
- JN Kutz, SL Brunton, BW Brunton, JL Proctor, "Dynamic mode decomposition: data-driven modeling of complex systems", 2016.
- Tu, Rowley, Luchtenburg, Brunton, and Kutz, "On Dynamic Mode Decomposition: Theory and Applications", *American Institute of Mathematical Sciences, 2014.
- J. Grosek and J.N. Kutz. "Dynamic mode decomposition for real-time background/foreground separation in video.", 2014.
全ソースコード
import numpy as np
import scipy.linalg as la
import cv2
# 画像のパス
video_path = "./atrium_video.avi"
# DMD定義
def dmd(X, Y, truncate=None):
u2,sig2,vh2 = la.svd(X, False)
r = len(sig2) if truncate is None else truncate
u = u2[:,:r]
sig = np.diag(sig2)[:r,:r]
v = vh2.conj().T[:,:r]
Atil = np.dot(np.dot(np.dot(u.conj().T, Y), v), la.inv(sig))
mu,w = la.eig(Atil)
phi = np.dot(np.dot(np.dot(Y, v), la.inv(sig)), w)#DMD mode
return mu, phi
# 画像読み込み
cap = cv2.VideoCapture(video_path)
# 画像の解像度、フレームレート、フレーム数取得
wid = cap.get(cv2.CAP_PROP_FRAME_WIDTH)#横
hei = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)#縦
fps = cap.get(cv2.CAP_PROP_FPS)#フレームレート
count = cap.get(cv2.CAP_PROP_FRAME_COUNT)#フレーム数
dt = 1/fps#フレーム間秒数
print(f"wid:{wid}", f" hei:{hei}", f" fps:{fps}", f" count:{count}", f"dt:{dt}")
# 利用するフレーム
start_frame =120
end_frame = 170
# 画像解像度を1/4にする(計算量削減のため)
r = 4
# フレーム抜き出し
cat_frames = []
cap.set(cv2.CAP_PROP_POS_FRAMES,start_frame)
for i in range(end_frame - start_frame):
ret, img = cap.read()
if not ret:
print("no image")
break
buf = cv2.cvtColor(cv2.resize(img,(int(wid/r), int(hei/r))), cv2.COLOR_BGR2GRAY).flatten()#
cat_frames.append(buf)
cat_frames = np.array(cat_frames).T
cap.release()
# DMDの計算
X1 = cat_frames[:,:-1]
X2 = cat_frames[:,1:]
mu, phi = dmd(X1,X2)
omega = np.log(mu)/dt
# 背景と動体以外判定
bg = np.abs(omega) < 1e-2 #背景の抽出
fg = ~bg #動体の抽出
phi_bg = phi[:,bg]#背景の動的モード
phi_fg = phi[:,fg]#動体の動的モード
omega_bg = omega[bg]#背景の振動・振幅モード
omega_fg = omega[fg]#動体の振動・振幅モード
# 動的モードの再構成
phi_fg_pinv = la.pinv(phi_fg)#疑似逆行列。メモリエラーが出る場合はrを大きくする
X_fg = np.zeros((len(omega_fg), end_frame - start_frame), dtype='complex')
b = phi_fg_pinv @ cat_frames[:,0]#初期値
for tt in range(end_frame - start_frame):
X_fg[:,tt] = b * np.exp(omega_fg * dt * tt)
X_fg = phi_fg @ X_fg
# 輝度調整用
lum_max = np.abs(X_fg.real.max())
lum_min = np.abs(X_fg.real.min())
lum_diff = lum_max + lum_min
# 動画作成
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter("out_dmd_fg.mp4", fourcc, fps, (int(wid/r), int(hei/r)))
for tt in range(end_frame - start_frame):
a = X_fg[:,tt].real.reshape(int(hei/r), -1)
a = (a + lum_min)/lum_diff * 255
a = a.astype("uint8")
out_img = np.tile(a, (3,1,1)).transpose((1,2,0))#グレースケールを[wid, hei, 3]の行列に変換する
writer.write(out_img)
writer.release()