<科目> 深層学習
[深層学習: Day1 NN ]
(https://qiita.com/matsukura04583/items/6317c57bc21de646da8e)
[深層学習: Day2 CNN ]
(https://qiita.com/matsukura04583/items/29f0dcc3ddeca4bf69a2)
[深層学習: Day3 RNN]
(https://qiita.com/matsukura04583/items/9b77a238da4441e0f973)
[深層学習: Day4 強化学習・Tensor Flow]
(https://qiita.com/matsukura04583/items/50806b750c8d77f2305d)
深層学習: Day1 NN (講義の要約)
-
ニューラルネットワーク(NN)でできること
-
回帰
- 結果予想
- 株価予想
- 売上予想
- ランキング
- 競馬順位予想
- 人気順位予想
- 結果予想
-
分類
- 猫写真の判別
- 手書き文字認識
- 花の種類分類
-
ニューラルネットワーク︓回帰(連続する実数値を取る関数の近似)
-
【回帰分析】
•線形回帰
•回帰木
•ランダムフォレスト
•ニューラルネットワーク(NN) -
ニューラルネットワーク︓分類(性別(男or女)や動物の種類
など離散的な結果を予想するための分析) -
【分類分析】
•ベイズ分類
•ロジスティック回帰
•ランダムフォレスト
•ニューラルネットワーク(NN)
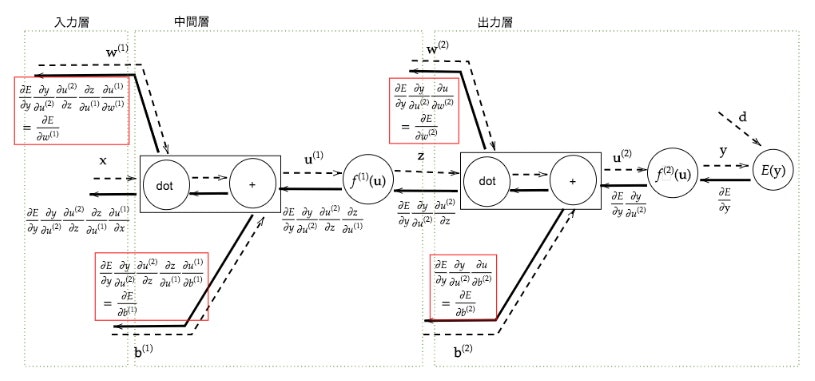
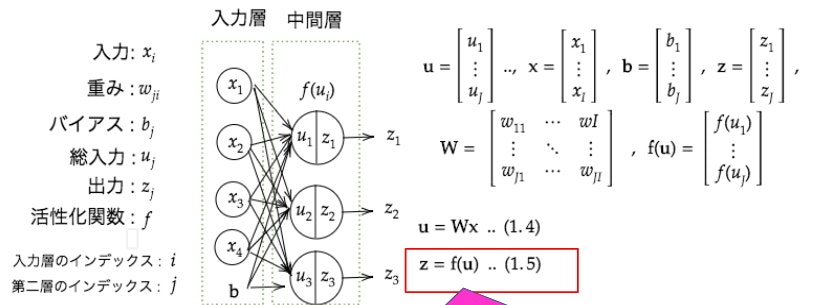
Section1) 入力層〜中間層
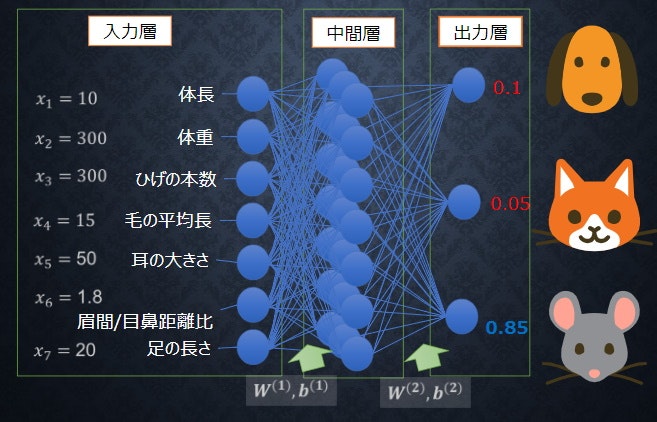
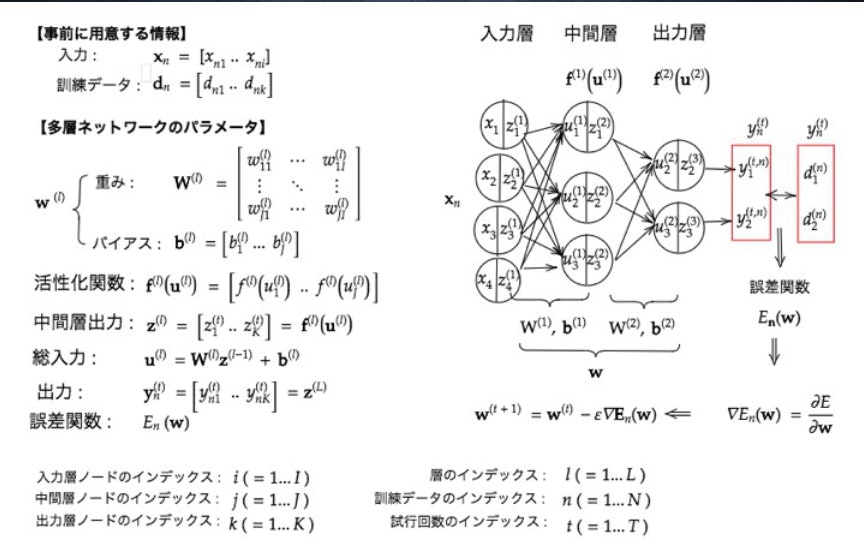
- 重みをラージWであらわして、バイアスbで表して、両方を合わせて示唆する場合は、スモールwで表しているのがややこしいポイント。
- 中間層は無限に設定できる。
Section2) 活性化関数
- ニューラルネットワークにおいて、次の層への出力の大きさを決める非線形の関数。
- 入力値の値によって、次の層への信号のON/OFFや強弱を定める働きを持つ。
-
中間層用の活性化関数
- ステップ関数
数式
f(x) = \left\{
\begin{array}{ll}
1 & (x \geq 0) \\
0 & (x \lt 0)
\end{array}
\right.
def
step_function(x):
if x > 0:
return 1
else:
return 0
- シグモイド(ロジスティック)関数
数式
f(u) = \frac{1}{1+e^{-u}}
def sigmoid(x):
return 1/(1 + np.exp(-x))
0 ~ 1の間を緩やかに変化する関数で、ステップ関数ではON/OFFしかない状態に対し、信号の強弱を伝えられるようになり、予想ニューラルネットワーク普及のきっかけとなった。
課題
大きな値では出力の変化が微小なため、勾配消失問題を引き起こす事があった。
- ReLU関数
f(x) = \left\{
\begin{array}{ll}
x & (x \gt 0) \\
0 & (x \leq 0)
\end{array}
\right.
def relu(x):
return
np.maximum(0, x)
今最も使われている活性化関数
勾配消失問題の回避とスパース化に貢献することで良い成果をもたらしている。
※ 勾配消失問題
・スパース化については確率的勾配降下法の解説後に詳しく触れる予定
-
出力層用の活性化関数
- ソフトマックス関数
- 恒等写像
- シグモイド関数(ロジスティック関数)
Section3) 出力層
3-1 誤差関数
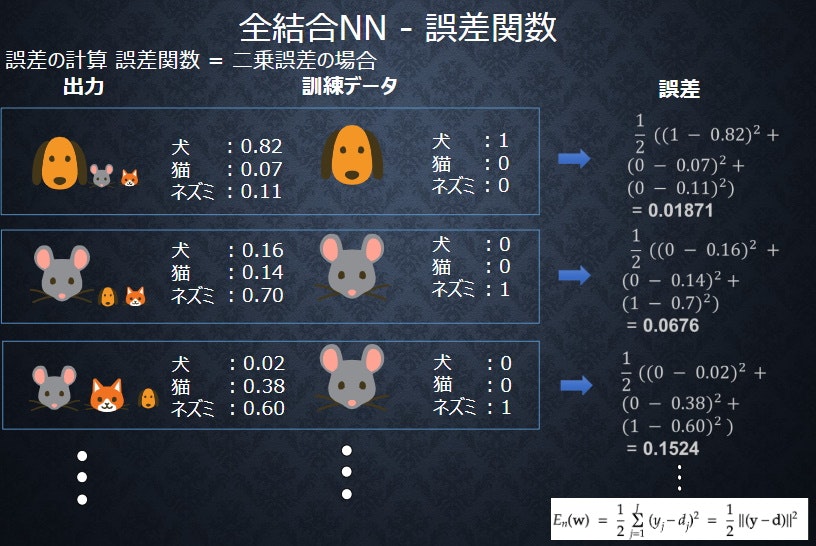
誤差の計算 誤差関数= 二乗誤差の場合
En(w)=\frac{1}{2}\sum_{j=1}^{I} (y_j-d_j)^2 = \frac{1}{2}||(y-d)||^2
3-2 出力層の活性化関数
- 出力層の中間層との違い
- 【値の強弱】
- 中間層︓しきい値の前後で信号の強弱を調整
- 出力層︓信号の大きさ(比率)はそのままに変換
- 【確率出力】
- 分類問題の場合、出力層の出力は0 ~ 1 の範囲に限定し、総和を1とする必要がある
- 出力層と中間層で利用される活性化関数が異なる

- 【値の強弱】
- 交差エントロピー
En(w)=-\sum_{i=1}^Id_ilog y_i
# クロスエントロピー
def cross_entropy_error(d, y):
if y.ndim == 1:
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size
One-hot ベクトルとは、(0,1,0,0,0,0) のように、1つの成分が1で残りの成分が全て0であるようなベクトルのことです。
(参考)One-hotベクトルとはで調べたサイト
Section4) 勾配降下法
- 勾配降下法
- 全結合NN–勾配降下法
- 学習を通して誤差を最小にするネットワークを作成すること
- 誤差E(w)を最小化するパラメータの発見が目的
- 勾配降下法を利用してパラメータを最適化
- 学習率$\varepsilon$によって学習の効果が大きく変わる
$\nabla E=\frac{\partial E}{\partial W}=[\frac{\partial E}{\partial w_1}・・・\frac{\partial E}{\partial w_M}]$
勾配降下法の学習率の決定、収束性向上のためのアルゴリズムについて複数の
論文が公開されている
+ Momentum
+ AdaGrad
+ Adadelta
+ Adam
- 全結合NN–勾配降下法
- 確率的勾配降下法
- $W^{(t+1)} =W^{(t)}-\varepsilon\nabla E (\varepsilon は学習率)$・・・勾配降下法
勾配降下法は全サンプルの平均誤差
- $W^{(t+1)} =W^{(t)}-\varepsilon\nabla E (\varepsilon は学習率)$・・・勾配降下法
$W^{(t+1)} =W^{(t)}-\varepsilon\nabla En (\varepsilon は学習率)$・・・確率的勾配降下法
確率的勾配降下法は、ランダムに抽出したサンプルの誤差
+ 確率的勾配降下法のメリット
+ データが冗⻑な場合の計算コストの軽減
+ 望まない局所極小解に収束するリスクの軽減
+ オンライン学習ができる
+ (参考)確率的勾配降下法の解説サイト
-
ミニバッチ勾配降下法
+
$W^{(t+1)} =W^{(t)}-\varepsilon\nabla En (\varepsilon は学習率)$・・・確率的勾配降下法
確率的勾配降下法は、ランダムに抽出したサンプルの誤差
$W^{(t+1)} =W^{(t)}-\varepsilon\nabla Et (\varepsilon は学習率)$・・・ミニバッチ勾配降下法
$E_t=\frac{1}{N_t}\sum_{n\in D_t}E_n$
$N_t=|D_t|$
ミニバッチ勾配降下法は、ランダムに抽出したデータの集合()ミニバッチ)$D_t$に属するサンプルの平均誤差<br>
ミニバッチ勾配降下法のメリット
確率的勾配降下法のメリットを損なわず、計算機の計算資源を有効利用できる
→ CPUを利用したスレッド並列化やGPUを利用したSIMD並列化
Section5) 誤差逆伝播法
誤差勾配の計算–誤差逆伝播法
【誤差逆伝播法】算出された誤差を、出力層側から順に微分し、前の層前の層へと伝播。最小限の計算で各パラメータでの微分値を解析的に計算する手法
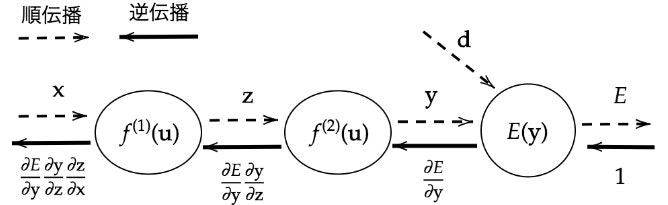
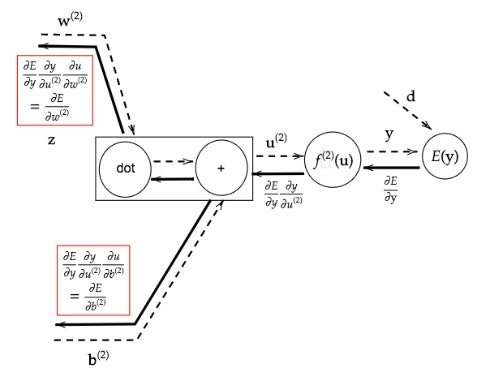
計算結果(=誤差)から微分を逆算することで、不要な再帰的計算を避けて微分を算出できる
# 誤差逆伝播
def backward(x, d, z1, y):
print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ
delta2 = functions.d_sigmoid_with_loss(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
print_vec("偏微分_dE/du2", delta2)
print_vec("偏微分_dE/du2", delta1)
print_vec("偏微分_重み1", grad["W1"])
print_vec("偏微分_重み2", grad["W2"])
print_vec("偏微分_バイアス1", grad["b1"])
print_vec("偏微分_バイアス2", grad["b2"])
return grad
確認テストの考察
【P10】ディープラーニングは、結局何をやろうとしているか2行以内で述べよ。 また、次の中のどの値の最適化が最終目的か。 全て選べ。
①入力値[ X] ②出力値[ Y] ③重み[W]④バイアス[b] ⑤総入力[u] ⑥中間層入力[ z] ⑦学習率[ρ]
⇒【考察】ディープラーニングは、結局、誤差を最小化するパラメータを確定することを目的としている。どの値の最適化が最終目的かというと③重み[W] ④バイアス[b]を最適化しようとしている。
【P12】次のネットワークを紙にかけ。
- 入力層︓2ノード1層
- 中間層︓3ノード2層
- 出力層: 1ノード1層
⇒【考察】
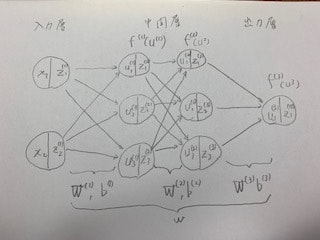
自分で書いてみると、分かりやすい。
【P19】確認テスト
この図式に動物分類の実例を入れてみよう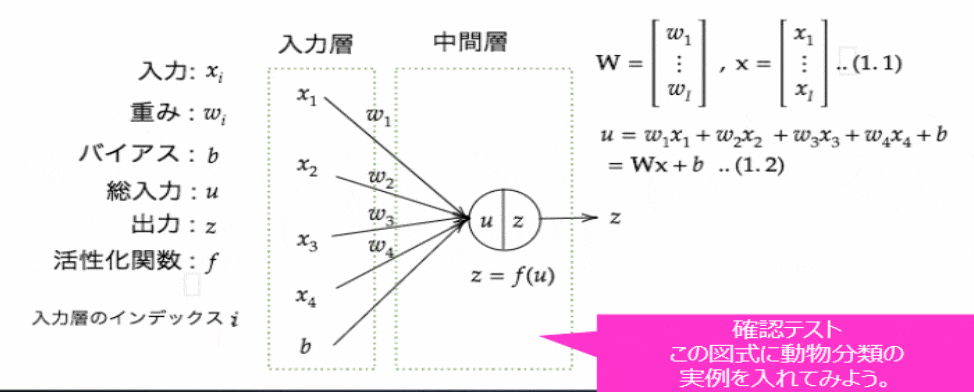
⇒【考察】
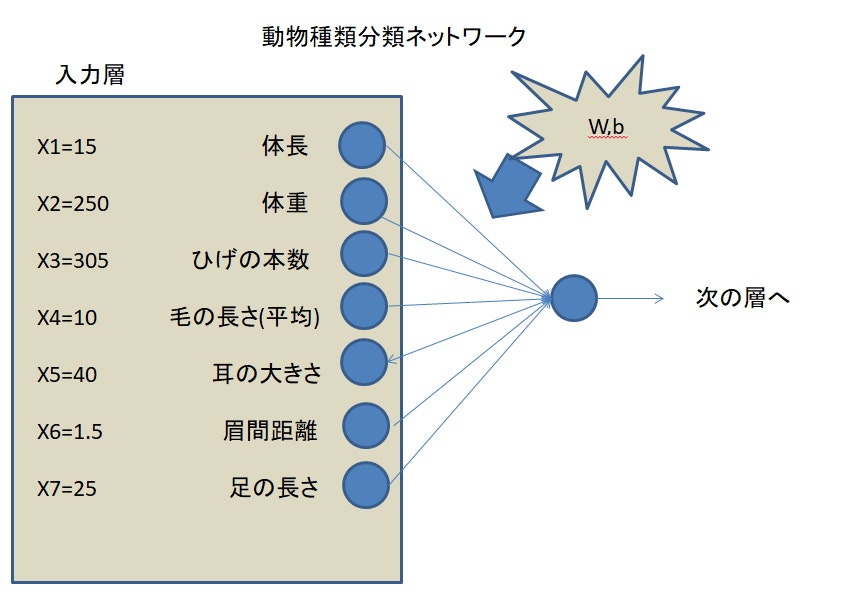
【P21】確認テスト
この式をpythonで書け
u=w_1x_1+w_2x_2+w_3x_3+w_4x_4+b=Wx+b..(1.2)
⇒【考察】
u1=np.dot(x,W1)+b1
【P23】確認テスト
中間層を表すコードを抜き出せ
⇒【考察】
# 隠れ層の総入力
u1 = np.dot(x, W1) + b1
# 隠れ層の総出力
z1 = functions.relu(u1)
- RELU関数は別途解説。
【P26】確認テスト
線形と非線形の違いを図にかいて簡易に説明せよ。
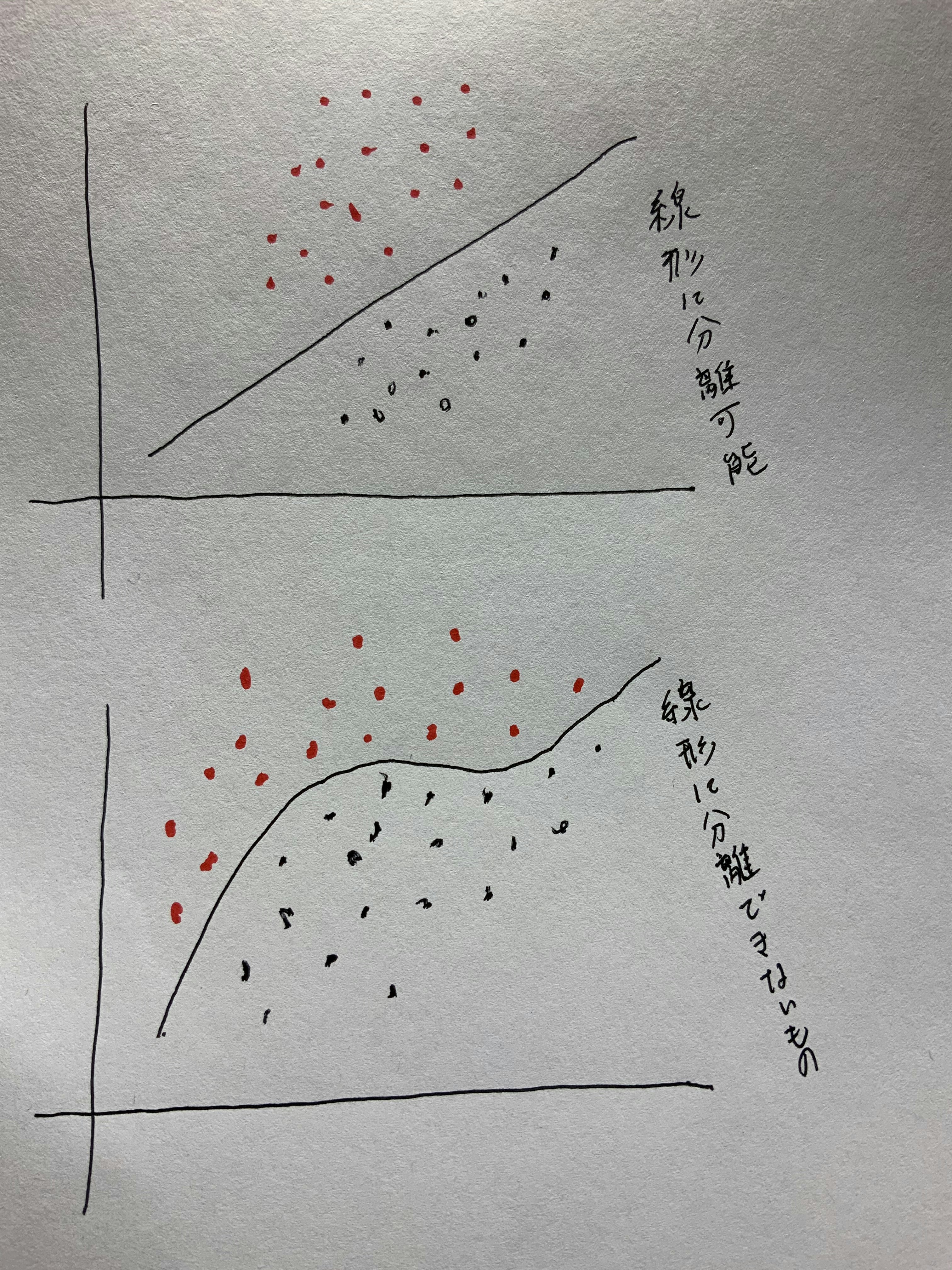
【P34】確認テスト
全結合NN-単層・複数ノード
配布されたソースコードより該当する箇所を抜き出せ。
⇒【考察】
活性化関数f(u)がシグモイド関数なのでこの部分となる。
z1 = functions.sigmoid(u)
【P34】確認テスト
誤差の計算 誤差関数= 二乗誤差の場合
En(w)=\frac{1}{2}\sum_{j=1}^{I} (y_j-d_j)^2 = \frac{1}{2}||(y-d)||^2
・なぜ、引き算でなく二乗するか述べよ
・下式の1/2はどういう意味を持つか述べよ
⇒【考察】
・分散をプラスで表すため
・1/2は平均値をとっている
(参考)ここのサイトがわかりやすかった
最小二乗法の意味と計算方法 - 回帰直線の求め方
※本来ならば分類問題の場合誤差関数にクロスエントロピー誤差を用いるのでコードは
loss =cross_entropy_error(d,y)
となるが今回は説明の便宜上誤差関数に平均二乗誤差を用いているためコードは
loss = functions.mean_squared_error(d, y)
となる
【P51】確認テスト(S3_2 出力層_活性化関数)
ソフトマックス関数
①f(i,u)=\frac{e^{u_i}②}{\sum_{k=1}^{k}e^{u_k}③}
①~③の数式に該当するソースコードを示し、一行ずつ説明せよ
def softmax(x):
if x.ndim == 2:#2次元だった場合
x = x.Tx
x = x-np.max(x, axis=0)
y = np.exp(x) /np.sum(np.exp(x), axis=0)
return y.T
x = x -np.max(x) # オーバーフロー対策
return np.exp(x) / np.sum(np.exp(x))
①・・・・y(return y.Tより転置を返している)
②・・・・np.exp(x) 部分
③・・・・np.sum(np.exp(x), axis=0) 部分
(学習参考)NumPyの軸(axis)と次元数(ndim)とは何を意味するのか
【P53】確認テスト(S3_2 出力層_活性化関数)
交差エントロピー
①~②の数式に該当するソースコードを示し、一行づつ処理の説明をせよ。
```math
En(w)=-\sum_{i=1}^Id_ilog y_i
$En(w)$・・・①の部分
$-\sum_{i=1}^Id_ilog y_i$・・・②の部分
⇒【考察】
・return-np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size
・1/2は平均値をとっている
# クロスエントロピー
def cross_entropy_error(d, y):
if y.ndim == 1:
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size
$En(w)$・・・①の部分 はreturn値
$-\sum_{i=1}^Id_ilog y_i$・・・②の部分
-np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_sizeの部分。
- 『1e-7』を足しているのは、log部分がゼロにならないように微細な数字を足している。
- 教師データがone-hotベクトルの場合かそうでない場合(教師データが整数など)か重要。one-hotベクトルでない場合はkerasを利用した別関数を使う必要がある。
【P56】確認テスト(S4 勾配降下法)
勾配降下法関数の該当するソースコードを探してみよう。
$W^{(t+1)} =W^{(t)}-\varepsilon\nabla E_n (\varepsilon は学習率)$・・・・①
$\nabla E=\frac{\partial E}{\partial W}=[\frac{\partial E}{\partial w_1}・・・\frac{\partial E}{\partial w_M}]$・・・・②
⇒【考察】
# 誤差
loss = functions.cross_entropy_error(d, y)
grad = backward(x, d, z1, y)# ②の部分にあたる
for key in ('W1', 'W2', 'b1', 'b2'):
network[key] -= learning_rate * grad[key] # ①の部分にあたる
【P65】確認テスト(S4 勾配降下法)
オンライン学習とは何かまとめよ。
⇒【考察】
オンライン学習とは、新しく取得したデータのみで学習モデルが作成できること。既存のデータを活用せずとも回すことができる。
【P69】確認テスト(S4 勾配降下法)
この数式の意味を図に書いて説明せよ。
+
$W^{(t+1)} =W^{(t)}-\varepsilon\nabla Et (\varepsilon は学習率)$・・・ミニバッチ勾配降下法
⇒【考察】
(〇〇〇) (〇〇〇) (〇〇〇)
セット1 セット2 セット3
この場合、任意のデータセット1つをミニバッチの集合として誤差を足し合わせ、1/3する。
$E_t=\frac{1}{N_t}\sum_{n\in D_t}E_n$
$N_t=|D_t|$
【P78】確認テスト(S5 誤差逆伝播法)
誤差逆伝播法では不要な再帰的処理を避ける事が出来る。既に行った計算結果を保持しているソースコードを抽出せよ。
# 誤差逆伝播
def backward(x, d, z1, y):
print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ ##ここでシグモイド関数とクロスエントロピーを合わせた関数の導関数を算出、『delta2』に代入
delta2 = functions.d_sigmoid_with_loss(d, y)
# b2の勾配 ## 『delta2』を利用している
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配 ## 『delta2』を利用している
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ ## 『delta2』を利用している
delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
print_vec("偏微分_dE/du2", delta2)
print_vec("偏微分_dE/du2", delta1)
print_vec("偏微分_重み1", grad["W1"])
print_vec("偏微分_重み2", grad["W2"])
print_vec("偏微分_バイアス1", grad["b1"])
print_vec("偏微分_バイアス2", grad["b2"])
return grad
【P83】2つの空欄に該当するソースコードを探せ(S5 誤差逆伝播法)
$\frac{\partial E}{\partial y}$ $\frac{\partial y}{\partial u}$
# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
$\frac{\partial E}{\partial y}$ $\frac{\partial y}{\partial u}$ $\frac{\partial u}{\partial w _{ji}^{(2)}}$
# 出力層でのデルタ
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
演習
DN06_Jupyter演習
######################################
# 試してみよう #
######################################
# 順伝播(単層・単ユニット)
# 重み
# W = np.array([[0.1], [0.2]])
## 試してみよう_配列の初期化
# W = np.zeros(2)
W = np.ones(2) #こちらを選択
# W = np.random.rand(2)
# W = np.random.randint(5, size=(2))
print_vec("重み", W)
# バイアス
# b = 0.5
## 試してみよう_数値の初期化
b = np.random.rand() # 0~1のランダム数値 #こちらを選択
# b = np.random.rand() * 10 -5 # -5~5のランダム数値
print_vec("バイアス", b)
# 入力値
x = np.array([2, 3])
print_vec("入力", x)
# 総入力
u = np.dot(x, W) + b
print_vec("総入力", u)
# 中間層出力
z = functions.relu(u)
print_vec("中間層出力", z)
*** 重み ***
[1. 1.]
*** バイアス ***
0.15691869859919338
*** 入力 ***
[2 3]
*** 総入力 ***
5.156918698599194
*** 中間層出力 ***
5.156918698599194
######################################
# 試してみよう #
######################################
# 順伝播(単層・複数ユニット)
# 重み
# W = np.array([
[0.1, 0.2, 0.3],
[0.2, 0.3, 0.4],
[0.3, 0.4, 0.5],
[0.4, 0.5, 0.6]
# ])
## 試してみよう_配列の初期化
# W = np.zeros((4,3))
W = np.ones((4,3)) #こちらを選択
# W = np.random.rand(4,3)
# W = np.random.randint(5, size=(4,3))
print_vec("重み", W)
# バイアス
b = np.array([0.1, 0.2, 0.3])
print_vec("バイアス", b)
# 入力値
x = np.array([1.0, 5.0, 2.0, -1.0])
print_vec("入力", x)
# 総入力
u = np.dot(x, W) + b
print_vec("総入力", u)
# 中間層出力
z = functions.sigmoid(u)
print_vec("中間層出力", z)
*** 重み ***
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
*** バイアス ***
[0.1 0.2 0.3]
*** 入力 ***
[ 1. 5. 2. -1.]
*** 総入力 ***
[7.1 7.2 7.3]
*** 中間層出力 ***
[0.99917558 0.99925397 0.99932492]
######################################
# 試してみよう #
######################################
# 多クラス分類
# 2-3-4ネットワーク
# !試してみよう_ノードの構成を 3-5-4 に変更してみよう
# ウェイトとバイアスを設定
# ネートワークを作成
def init_network():
print("##### ネットワークの初期化 #####")
#試してみよう
#_各パラメータのshapeを表示
#_ネットワークの初期値ランダム生成
network = {}
network['W1'] = np.array([
[0.1, 0.4, 0.7, 0.1, 0.3],
[0.2, 0.5, 0.8, 0.1, 0.4],
[0.3, 0.6, 0.9, 0.2, 0.5]
])
network['W2'] = np.array([
[0.1, 0.6, 0.1, 0.6],
[0.2, 0.7, 0.2, 0.7],
[0.3, 0.8, 0.3, 0.8],
[0.4, 0.9, 0.4, 0.9],
[0.5, 0.1, 0.5, 0.1]
])
network['b1'] = np.array([0.1, 0.2, 0.3, 0.4, 0.5])
network['b2'] = np.array([0.1, 0.2, 0.3, 0.4])
print_vec("重み1", network['W1'] )
print_vec("重み2", network['W2'] )
print_vec("バイアス1", network['b1'] )
print_vec("バイアス2", network['b2'] )
return network
# プロセスを作成
# x:入力値
def forward(network, x):
print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 1層の総入力
u1 = np.dot(x, W1) + b1
# 1層の総出力
z1 = functions.relu(u1)
# 2層の総入力
u2 = np.dot(z1, W2) + b2
# 出力値
y = functions.softmax(u2)
print_vec("総入力1", u1)
print_vec("中間層出力1", z1)
print_vec("総入力2", u2)
print_vec("出力1", y)
print("出力合計: " + str(np.sum(y)))
return y, z1
## 事前データ
# 入力値
x = np.array([1., 2., 3.])
# 目標出力
d = np.array([0, 0, 0, 1])
# ネットワークの初期化
network = init_network()
# 出力
y, z1 = forward(network, x)
# 誤差
loss = functions.cross_entropy_error(d, y)
## 表示
print("\n##### 結果表示 #####")
print_vec("出力", y)
print_vec("訓練データ", d)
print_vec("誤差", loss)
ネットワークの初期化
*** 重み1 ***
[[0.1 0.4 0.7 0.1 0.3]
[0.2 0.5 0.8 0.1 0.4]
[0.3 0.6 0.9 0.2 0.5]]
*** 重み2 ***
[[0.1 0.6 0.1 0.6]
[0.2 0.7 0.2 0.7]
[0.3 0.8 0.3 0.8]
[0.4 0.9 0.4 0.9]
[0.5 0.1 0.5 0.1]]
*** バイアス1 ***
[0.1 0.2 0.3 0.4 0.5]
*** バイアス2 ***
[0.1 0.2 0.3 0.4]
順伝播開始
*** 総入力1 ***
[1.5 3.4 5.3 1.3 3.1]
*** 中間層出力1 ***
[1.5 3.4 5.3 1.3 3.1]
*** 総入力2 ***
[4.59 9.2 4.79 9.4 ]
*** 出力1 ***
[0.00443583 0.44573018 0.00541793 0.54441607]
出力合計: 1.0
結果表示
*** 出力 ***
[0.00443583 0.44573018 0.00541793 0.54441607]
*** 訓練データ ***
[0 0 0 1]
*** 誤差 ***
0.6080413107681358
######################################
# 試してみよう #
######################################
#
# 回帰
# 2-3-2ネットワーク
# !試してみよう_ノードの構成を 3-5-4 に変更してみよう
# ウェイトとバイアスを設定
# ネートワークを作成
def init_network():
print("##### ネットワークの初期化 #####")
network = {}
network['W1'] = np.array([
[0.1, 0.4, 0.7, 0.1, 0.3],
[0.2, 0.5, 0.8, 0.1, 0.4],
[0.3, 0.6, 0.9, 0.2, 0.5]
])
network['W2'] = np.array([
[0.1, 0.6, 0.1, 0.6],
[0.2, 0.7, 0.2, 0.7],
[0.3, 0.8, 0.3, 0.8],
[0.4, 0.9, 0.4, 0.9],
[0.5, 0.1, 0.5, 0.1]
])
network['b1'] = np.array([0.1, 0.2, 0.3, 0.4, 0.5])
network['b2'] = np.array([0.1, 0.2, 0.3, 0.4])
print_vec("重み1", network['W1'] )
print_vec("重み2", network['W2'] )
print_vec("バイアス1", network['b1'] )
print_vec("バイアス2", network['b2'] )
return network
# プロセスを作成
def forward(network, x):
print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 隠れ層の総入力
u1 = np.dot(x, W1) + b1
# 隠れ層の総出力
z1 = functions.relu(u1)
# 出力層の総入力
u2 = np.dot(z1, W2) + b2
# 出力層の総出力
y = u2
print_vec("総入力1", u1)
print_vec("中間層出力1", z1)
print_vec("総入力2", u2)
print_vec("出力1", y)
print("出力合計: " + str(np.sum(z1)))
return y, z1
# 入力値
x = np.array([1., 2., 3.])
network = init_network()
y, z1 = forward(network, x)
# 目標出力
d = np.array([2., 3.,4.,5.])
# 誤差
loss = functions.mean_squared_error(d, y)
## 表示
print("\n##### 結果表示 #####")
print_vec("中間層出力", z1)
print_vec("出力", y)
print_vec("訓練データ", d)
print_vec("誤差", loss)
ネットワークの初期化
*** 重み1 ***
[[0.1 0.4 0.7 0.1 0.3]
[0.2 0.5 0.8 0.1 0.4]
[0.3 0.6 0.9 0.2 0.5]]
*** 重み2 ***
[[0.1 0.6 0.1 0.6]
[0.2 0.7 0.2 0.7]
[0.3 0.8 0.3 0.8]
[0.4 0.9 0.4 0.9]
[0.5 0.1 0.5 0.1]]
*** バイアス1 ***
[0.1 0.2 0.3 0.4 0.5]
*** バイアス2 ***
[0.1 0.2 0.3 0.4]
順伝播開始
*** 総入力1 ***
[1.5 3.4 5.3 1.3 3.1]
*** 中間層出力1 ***
[1.5 3.4 5.3 1.3 3.1]
*** 総入力2 ***
[4.59 9.2 4.79 9.4 ]
*** 出力1 ***
[4.59 9.2 4.79 9.4 ]
出力合計: 14.6
結果表示
*** 中間層出力 ***
[1.5 3.4 5.3 1.3 3.1]
*** 出力 ***
[4.59 9.2 4.79 9.4 ]
*** 訓練データ ***
[2. 3. 4. 5.]
*** 誤差 ***
8.141525
######################################
# 試してみよう #
######################################
# 2値分類
# 2-3-1ネットワーク
# !試してみよう_ノードの構成を 5-10-1 に変更してみよう
# ウェイトとバイアスを設定
# ネートワークを作成
def init_network():
print("##### ネットワークの初期化 #####")
network = {}
network['W1'] = np.array([
[0.1, 0.3, 0.5,0.1, 0.3, 0.5,0.1, 0.3, 0.5, 0.6],
[0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.7],
[0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.7],
[0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.7],
[0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.2, 0.4, 0.6,0.7]
])
network['W2'] = np.array([
[0.1],
[0.1],
[0.1],
[0.1],
[0.1],
[0.1],
[0.1],
[0.1],
[0.1],
[0.1]
])
network['b1'] = np.array([0.1, 0.3, 0.5,0.1, 0.3, 0.5,0.1, 0.3, 0.5, 0.6])
network['b2'] = np.array([0.1])
return network
# プロセスを作成
def forward(network, x):
print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 隠れ層の総入力
u1 = np.dot(x, W1) + b1
# 隠れ層の総出力
z1 = functions.relu(u1)
# 出力層の総入力
u2 = np.dot(z1, W2) + b2
# 出力層の総出力
y = functions.sigmoid(u2)
print_vec("総入力1", u1)
print_vec("中間層出力1", z1)
print_vec("総入力2", u2)
print_vec("出力1", y)
print("出力合計: " + str(np.sum(z1)))
return y, z1
# 入力値
x = np.array([1., 2., 3., 4., 5.])
# 目標出力
d = np.array([1])
network = init_network()
y, z1 = forward(network, x)
# 誤差
loss = functions.cross_entropy_error(d, y)
## 表示
print("\n##### 結果表示 #####")
print_vec("中間層出力", z1)
print_vec("出力", y)
print_vec("訓練データ", d)
print_vec("誤差", loss)
ネットワークの初期化
順伝播開始
*** 総入力1 ***
[ 3. 6.2 9.4 3. 6.2 9.4 3. 6.2 9.4 11. ]
*** 中間層出力1 ***
[ 3. 6.2 9.4 3. 6.2 9.4 3. 6.2 9.4 11. ]
*** 総入力2 ***
[6.78]
*** 出力1 ***
[0.99886501]
出力合計: 66.8
結果表示
*** 中間層出力 ***
[ 3. 6.2 9.4 3. 6.2 9.4 3. 6.2 9.4 11. ]
*** 出力 ***
[0.99886501]
*** 訓練データ ***
[1]
*** 誤差 ***
0.0011355297129812408
⇒【考察】
中間層の大きさによって出力結果が大きく変わってしまう事がわかった。ユニット数はどうやって決めるのか?中間層の決定はむずかしと感じました。入力層のユニットの数は、データの次元に一致させる必要があるので迷うことはありません。そして出力層のユニットの数も、分類したクラスの数だけ準備するので考える必要はありません。中間層を膨大に増やせば、近似がうまくいくのか調べたいと思います。また、重みやバイアスの設定が難しいとも感じました。
DN15_Jupyter演習2
####################################
# 試してみよう #
####################################
# サンプルとする関数
# yの値を予想するAI
def f(x):
y = 3 * x[0] + 2 * x[1]
return y
# 初期設定
def init_network():
# print("##### ネットワークの初期化 #####")
network = {}
nodesNum = 10
network['W1'] = np.random.randn(2, nodesNum)
network['W2'] = np.random.randn(nodesNum)
network['b1'] = np.random.randn(nodesNum)
network['b2'] = np.random.randn()
# print_vec("重み1", network['W1'])
# print_vec("重み2", network['W2'])
# print_vec("バイアス1", network['b1'])
# print_vec("バイアス2", network['b2'])
return network
# 順伝播
def forward(network, x):
# print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
u1 = np.dot(x, W1) + b1
#z1 = functions.relu(u1)
## 試してみよう
z1 = functions.sigmoid(u1) #シグモイドを選択して試す
u2 = np.dot(z1, W2) + b2
y = u2
# print_vec("総入力1", u1)
# print_vec("中間層出力1", z1)
# print_vec("総入力2", u2)
# print_vec("出力1", y)
# print("出力合計: " + str(np.sum(y)))
return z1, y
# 誤差逆伝播
def backward(x, d, z1, y):
# print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ
delta2 = functions.d_mean_squared_error(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
#delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
## 試してみよう #シグモイドを選択して試す
delta1 = np.dot(delta2, W2.T) * functions.d_sigmoid(z1)
delta1 = delta1[np.newaxis, :]
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
x = x[np.newaxis, :]
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
# print_vec("偏微分_重み1", grad["W1"])
# print_vec("偏微分_重み2", grad["W2"])
# print_vec("偏微分_バイアス1", grad["b1"])
# print_vec("偏微分_バイアス2", grad["b2"])
return grad
# サンプルデータを作成
data_sets_size = 100000
data_sets = [0 for i in range(data_sets_size)]
for i in range(data_sets_size):
data_sets[i] = {}
# ランダムな値を設定
# data_sets[i]['x'] = np.random.rand(2)
## 試してみよう_入力値の設定 # こちらを選択して試す
data_sets[i]['x'] = np.random.rand(2) * 10 -5 # -5〜5のランダム数値
# 目標出力を設定
data_sets[i]['d'] = f(data_sets[i]['x'])
losses = []
# 学習率
learning_rate = 0.07
# 抽出数
epoch = 1000
# パラメータの初期化
network = init_network()
# データのランダム抽出
random_datasets = np.random.choice(data_sets, epoch)
# 勾配降下の繰り返し
for dataset in random_datasets:
x, d = dataset['x'], dataset['d']
z1, y = forward(network, x)
grad = backward(x, d, z1, y)
# パラメータに勾配適用
for key in ('W1', 'W2', 'b1', 'b2'):
network[key] -= learning_rate * grad[key]
# 誤差
loss = functions.mean_squared_error(d, y)
losses.append(loss)
print("##### 結果表示 #####")
lists = range(epoch)
plt.plot(lists, losses, '.')
# グラフの表示
plt.show()
 ⇒【考察】
Relu関数からシグモイド関数に変えたことによりグラフの0に近い方の分散が広がった。また、-5〜5のランダム数を選択したことにより<全体的に分散が広がった。選択する関数などにより結果が大きく違う事がわかった。
⇒【考察】
Relu関数からシグモイド関数に変えたことによりグラフの0に近い方の分散が広がった。また、-5〜5のランダム数を選択したことにより<全体的に分散が広がった。選択する関数などにより結果が大きく違う事がわかった。
修了課題
DN16_修了課題(製作課題)
- (課題)IRISデータを使って、DeepLearninngを作成せよ
設計
IRISデータを訓練データとテストデータに2:1に分けて学習させて予測するモデルを作成。
+ 入力層:4次元
- 隠れ層:6次元
- 出力層:3次元(3クラス分類問題のため)
- 各層の間の結合:Dense(全結合)
- 入力層→隠れ層の活性化関数:relu
- 隠れ層→出力層の活性化関数:softmax
- 最適化:勾配降下法
- 損失関数:交差エントロピー


import numpy as np
# ハイパーパラメータ
INPUT_SIZE = 4 #入力ノードの数
HIDDEN_SIZE =6 #中間層(隠れ層)のニューロン数
OUTPUT_SIZE =3 #出力層のニューロン数
TRAIN_DATA_SIZE = 50 # 150個のデータのうちTRAIN_DATA_SIZE個を訓練データとして使用。残りは教師データとして使用。
LEARNING_RATE = 0.1 # 学習率
EPOCH = 1000 # 繰り返しの学習回数(エポック数)
# データを読み込み
#
# Iris datasetはこちらか入手。見出しつきで種類ごとに整列されているデータなので、150個のデータを3種類、10件づつに混じるようにCSVデータを準備。
# https://gist.github.com/netj/8836201
x = np.loadtxt('/content/drive/My Drive/DNN_code/data/iris.csv', delimiter=',',skiprows=1, usecols=(0, 1, 2, 3))
raw_t = np.loadtxt('/content/drive/My Drive/DNN_code/data/iris.csv', delimiter=',',skiprows=1,dtype="unicode", usecols=(4,))
t = np.zeros([150])
for i in range(0,150):
vari = raw_t[i]
#print(vari,raw_t[i],i)
if ("Setosa" in vari):
t[i] = int(0)
elif ("Versicolor" in vari):
t[i] = int(1)
elif ("Virginica" in vari):
t[i] = int(2)
else:
print("エラー",i)
# a = [3, 0, 8, 1, 9]
a = t.tolist()
a_int = [int(n) for n in a]
# print(a_int)
# a_one_hot = np.identity(10)[a_int]
a_one_hot = np.identity(len(np.unique(a)))[a_int]
# print(a_one_hot)
train_x = x[:TRAIN_DATA_SIZE]
train_t = a_one_hot[:TRAIN_DATA_SIZE]
test_x = x[TRAIN_DATA_SIZE:]
test_t = a_one_hot[TRAIN_DATA_SIZE:]
# print("train=",TRAIN_DATA_SIZE,train_x,train_t)
# print("test=",test_x,test_t)
# 重み・バイアス初期化 # Heの初期値(ReLU利用のため)
W1 = np.random.randn(INPUT_SIZE, HIDDEN_SIZE) / np.sqrt(INPUT_SIZE) * np.sqrt(2)
W2 = np.random.randn(HIDDEN_SIZE, OUTPUT_SIZE)/ np.sqrt(HIDDEN_SIZE) * np.sqrt(2)
# 初期値ゼロから調整
b1 = np.zeros(HIDDEN_SIZE)
b2 = np.zeros(OUTPUT_SIZE)
# ReLU関数
def relu(x):
return np.maximum(x, 0)
# ソフトマックス関数
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # オーバーフロー対策
return np.exp(x) / np.sum(np.exp(x))
# 交差エントロピー誤差
def cross_entropy_error(y, t):
if y.shape != t.shape:
raise ValueError
if y.ndim == 1:
return - (t * np.log(y)).sum()
elif y.ndim == 2:
return - (t * np.log(y)).sum() / y.shape[0]
else:
raise ValueError
# 順伝搬
def forward(x):
global W1, W2, b1, b2
return softmax(np.dot(relu(np.dot(x, W1) + b1), W2) + b2)
# テストデータの結果
test_y = forward(test_x)
print("学習前=",(test_y.argmax(axis=1) == test_t.argmax(axis=1)).sum(), '/', 150 - TRAIN_DATA_SIZE)
# 学習ループ
for i in range(EPOCH):
# 順伝搬withデータ保存
y1 = np.dot(train_x, W1) + b1
y2 = relu(y1)
train_y = softmax(np.dot(y2, W2) + b2)
# 損失関数計算
L = cross_entropy_error(train_y, train_t)
if i % 100 == 0: #100の剰余
print("L=",L)
# 勾配計算
a1 = (train_y - train_t) / TRAIN_DATA_SIZE
b2_gradient = a1.sum(axis=0)
W2_gradient = np.dot(y2.T, a1)
a2 = np.dot(a1, W2.T)
a2[y1 <= 0.0] = 0
b1_gradient = a2.sum(axis=0)
W1_gradient = np.dot(train_x.T, a2)
# パラメータ更新
W1 = W1 - LEARNING_RATE * W1_gradient
W2 = W2 - LEARNING_RATE * W2_gradient
b1 = b1 - LEARNING_RATE * b1_gradient
b2 = b2 - LEARNING_RATE * b2_gradient
# 結果表示
# 最終訓練データのL値
L = cross_entropy_error(forward(train_x), train_t)
print("最終訓練データのL値=",L)
# テストデータの結果
test_y = forward(test_x)
print("学習後=",(test_y.argmax(axis=1) == test_t.argmax(axis=1)).sum(), '/', 150 - TRAIN_DATA_SIZE)
(結果)
学習前= 42 / 100
L= 4.550956552060894
L= 0.3239415165787326
L= 0.2170679838829666
L= 0.04933110713361697
L= 0.0273865499319481
L= 0.018217122389043848
L= 0.013351028977015358
L= 0.010399165844496665
L= 0.008444934117102367
L= 0.007068429052588092
最終訓練データのL値= 0.0060528995955394386
学習後= 89 / 100
⇒【考察】
- Q1.課題の目的とは?どのような工夫ができそうか
課題の目的は全体を通したディープラーニングの基本的な仕組みの学習。中間層の数やハイパーパラメータの調整で工夫ができる。 - Q2.課題を分類タスクで解く場合の意味は何か
分類タスクの場合には、訓練データとテストデータの生成が学べる。 - Q3.IRISデータとは何か2行でのべよ
機械学習やディープラーニングを学習するために揃えられたデータ。
3種類のアヤメの分類を題材に4つの特徴量が提供されている。