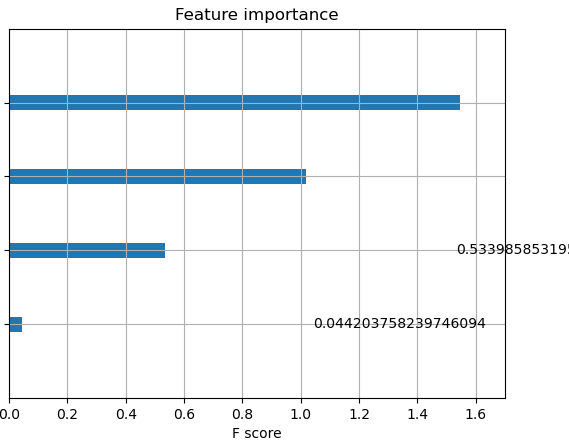
feature importanceはすべての説明変数について算出できないのでしょうか?
Q&A
Closed
解決したいこと
基本的な質問で申し訳ないのですが、
説明変数は30個くらいあるのに、feature importanceで表示されるのは一部の変数だけでした。
関連が深い項目しか表示されないのでしょうか?
以下はコードですが、これはシグネイトの林型分類のために書いたコードで、
これを改変して実際に解析したいデータに当てはめてみました。
import xgboost as xgb
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
forest = pd.read_csv("./python/train2.csv")
import seaborn as sns
forest_corr = forest.corr()
print(forest_corr)
sns.heatmap(forest_corr,vmax=1, vmin=-1, center=0)
import matplotlib.pyplot as plt
plt.show()
#訓練データとテストデータの取得
from sklearn.model_selection import train_test_split
#ここではA.B.C...で省略していますが、説明変数が30個あります。
forest_data = pd.DataFrame(forest, columns=["A", "B", "C", "D","E", "F", "G",
"H"])
print(forest_data)
forest_target=pd.Series(forest["Cover_Type"])
print(forest_target)
#訓練データとテストデータの取得(テストが0.2,訓練が0.8)
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(forest_data,
forest_target,
test_size=0.2,
shuffle=True)
#xgboost用の型に変換する
dtrain = xgb.DMatrix(train_x, label=train_y)
#パラメータの設定 max_depth:木の最大深度 eta:学習率 objective:学習目的 num_class:クラス数
param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softmax', 'num_class':3}
#学習
num_round = 10
bst = xgb.train(param, dtrain, num_round)
#予測
dtest = xgb.DMatrix(test_x)
pred = bst.predict(dtest)
#精度の確認
from sklearn.metrics import accuracy_score
from sklearn.metrics import r2_score
score = accuracy_score(test_y, pred)
print('score:{0:.4f}'.format(score))
#重要度の可視化
xgb.plot_importance(bst)
plt.show()
print(pred.shape)
print(pred)
print(test_y, pred)
print(r2_score(test_y,pred))
自分で試したこと
feature importanceに表示される項目が1個だったり3個だったりします。
すべての項目について貢献度を知りたいと思うのですが、
表示されていないものは全く貢献していないということなのでしょうか?
原因としてデータが30セットしかないことも影響していると思いますが、
よくわかりません。
アドバイスを頂けると助かります。
よろしくお願いいたします。
0 likes