この投稿は、JustSystems Advent Calendar 2017 の 17日目に公開する記事です。
世の中、どこにどんなSlow Queryが潜んでいるかわかったものではありません。今回もPostgreSQL利用サービスで遭遇したSlowQuery退治の実話です。
襲来〜少しの違和感
M: DBServerのピーク負荷があがってきてるな
K: 今は新規獲得のプロモーションで、Webアクセス自体が急伸中だから
M: DBServerは既存有償会員しか来れないところだぞ
K: 既存会員もCM見て休眠からアクティブに戻る人がいるのでは?
M: 無いとはいわないが、それで説明がつく上昇よりは大きい感じがする
K: ちょっと診ましょう
MackerelのグラフをSlackに貼り付けながら、自問自答して、たまにSlackにもその内容を記入していきます。
見慣れぬTop ~ps_stats_statement
PostgreSQL Advent Calendar 2017の17日目でpg_stats_statement が検出してくれなかった Slow Queryの話をしていますが、特殊ケースに穴があったって、依然として頼りになるヤツです。
select CEIL(total_time/calls) as ave_time, rows,
LEFT(REPLACE(REPLACE(query,chr(10),' '), ' ', ''), 80)
from pg_stat_statements order by ave_time DESC limit 20;
| ave_time | rows | left |
|---|---|---|
| 294 | 133250 | WITH courses_of_month AS ( SELECT id FROM course_p WHERE |
| 227 | 387089 | WITH courses_of_month AS ( SELECT id FROM course_p WHERE |
I: どのぐらいマズいですかね、これ
M: ave_time で 294msec もあるのがいるので、このSQLを調査します
M: callsを見ると1人1日1回程度のAPIのようで、すぐには大きな問題に発展しないでしょう
M: pg_stats_statementで初めてみるSQLだ。ノーマークだったぞ
EXPLAIN ANALYZE
ログからひとつ実例拾って、そのパラメータでEXPLAIN ANALYZEしてみます。
explain (costs off, analyze)
WITH courses_of_month AS (
SELECT id
FROM course_p
WHERE g = 3 AND y = 2017 AND m = 11 AND c = 1 AND a = false
), results AS (
SELECT id, course_p_id
FROM course_r
WHERE
s_begin < cast('2017-xx-xx' as timestamp)
AND
c_id = xxxxxxxxx
)
SELECT courses_of_month.id
FROM courses_of_month
LEFT JOIN results ON results.course_p_id = courses_of_month.id
WHERE results.id IS NULL;
Hash Right Join (actual time=380.602..380.602 rows=0 loops=1)
Hash Cond: (results.course_p_id = courses_of_month.id)
Filter: (results.id IS NULL)
Rows Removed by Filter: 91
CTE courses_of_month
-> Bitmap Heap Scan on course_p (actual time=2.344..3.249 rows=27 loops=1)
Recheck Cond: (((y = 2017) AND (g = 3) AND (c = 1) AND (NOT a))))
# 一部省略...
CTE results
-> Append (actual time=0.201..371.378 rows=1680 loops=1)
-> Seq Scan on course_r (actual time=0.001..0.001 rows=0 loops=1)
Filter: ((s_begin < '2017-xx-xx 00:00:00'::timestamp without time zone) AND (c_id = xxxxxxxxx))
-> Index Scan using course_r_xx_c_id_idx on course_r_xx (actual time=0.198..368.658 rows=1680 loops=1)
Index Cond: (c_id = xxxxxxxxx)
Filter: (s_begin < '2017-xx-xx 00:00:00'::timestamp without time zone)
-> CTE Scan on results (actual time=0.205..375.174 rows=1680 loops=1)
-> Hash (actual time=3.335..3.335 rows=27 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 2kB
-> CTE Scan on courses_of_month (actual time=2.350..3.305 rows=27 loops=1)
Planning time: 26.985 ms
Execution time: 381.078 ms
ちゃんと再現できた。
Seq Scan が1ヵ所あるけれど、これはcourse_rがパーティション分割されていて、行数0の親テーブルについてのものなので、問題ない。
まっとうな実行計画ですね。
Cache、逃げ出した後
続けてもう一回同じEXPLAIN ANALYZE すると、あれ?速い。SQL、パラメータ、実行計画みんな同じなのに。
actual time に大差がついたのは Index Scan
...
Index Scan using course_r_xx_c_id_idx on course_r_xx (actual time=0.026..4.062 rows=1670 loops=1)
...
Planning time: 2.919 ms
Execution time: 13.570 ms
続けて3回目も速い。しばらく時間をあけての4回目は遅い。
IndexとScan対象が全部Cache Hitなら速い。Cache Missがあると遅い。そういうことだな。
人の造りしもの〜退職者のSQL
WITH句の名前に識別性の高いのがついていたので、ソースの特定はすぐできました。
M: 直近で変更した形跡はない
M: 最終更新は2013、まだSubversionだった頃だよ
O: このクエリーを呼び出すに至ったリクエストって何なんでしょう?
M: クエリのコミットコメントによると、○○○○を出すときの判定に使っています。 2013年からあるSQLがslow化 したというのが深刻で、現在のRAM実装量が不足してきたってことです。
O: CPUがボトルネックだったのが、 今度はメモリがボトルネック になってきていると
M: 今回のSQLは1人1日1回程度の頻度だったので、兆候検出-SQL改修も間に合いそうですが、頻度の高いSQLでこういうのを踏み抜くと…
せめてSQLらしく
APIの要件から考えるとこんなにDBががんばるところじゃないはず。SQLにまずいところがあるに違いない。
M: ああ、results句が無駄。利用者の過去のレコード全部を取り出しているけれど、必要なのはほとんど当月分だけ。1670件取り出して残したのは27件。ここが無駄にページキャッシュ効率を落としている
M: 直接 LEFT JOIN course_r でいいのでは
M: 古くからのお客さんほど、レコードがたまっているので、最初の方のもう誰も見ないところをfetchしてページキャッシュ効率を落としてる
WITH courses_of_month AS (
SELECT id
FROM course_p
WHERE g = 3 AND y = 2017 AND m = 11 AND c = 1 AND a = false
)
SELECT courses_of_month.id
FROM courses_of_month
LEFT JOIN course_r r
ON c_id = xxxxxxxxx
AND r.course_p_id = courses_of_month.id
AND s_begin < cast('2017-xx-xx' as timestamp)
WHERE r.id IS NULL;
- テーブル全域のスカスカなIndex Scanで作る中間結果1670行が無くなる
- 替わりに
(c_id, course_p_id, s_begin)の複合キーインデックスの scan 36回 - その範囲なら全部Cache Hit してくれそう
こみこみ3msecになりました。
Nested Loop Left Join (actual time=0.419..0.997 rows=31 loops=1)
Filter: (r.id IS NULL)
Rows Removed by Filter: 6
CTE courses_of_month
-> Bitmap Heap Scan on course_p (actual time=0.354..0.419 rows=36 loops=1)
# ...
-> CTE Scan on courses_of_month (actual time=0.364..0.512 rows=36 loops=1)
-> Append (actual time=0.010..0.010 rows=0 loops=36)
-> Seq Scan on course_r r (actual time=0.001..0.001 rows=0 loops=36)
Filter: ((s_begin < '2017-xx-xx 00:00:00'::timestamp without time zone) AND (c_id = xxxxxxx) AND (course_p_id = courses_of_month.id))
-> Index Scan using course_r_xx_c_id_course_p_id_s_begin_idx on course_r_xx r_1 (actual time=0.004..0.004 rows=0 loops=36)
Index Cond: ((c_id = xxxxxx) AND (course_p_id = courses_of_month.id) AND (s_begin < '2017-xx-xx 00:00:00'::timestamp without time zone))
Planning time: 2.119 ms
Execution time: 1.178 ms
実装当時の2013年だと、「テーブル全域のスカスカなIndex Scan」も、 テーブルが小さかったので、SQLの粗が見えなかった んでしょうね。Index Scan になっていたから、 Seq Scan統計にも出てこなかった。 平均実行時間も Cache Missが増えなければ、スロークエリログにも出てこないレベルだった。
束の間の平和
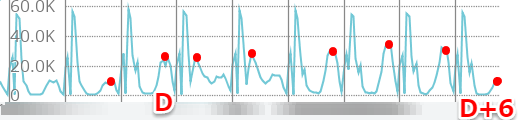
M: ピークのdisk read がD-day に急増 D+4 に気がついて、D+6に対策してぐっと下がりました。
S: 有 能
M: 深夜バッチのスパイクが邪魔
S: Mackerelならその時間帯を外して前日比も簡単
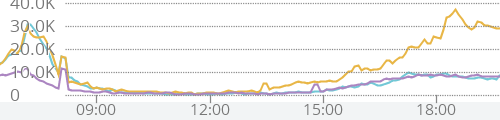
S: 水色がD+6, 橙がD+5, 紫がD-1
M: 有 能
O: 1週間前に戻ってきた感じですね
S: 12月の山を倒した
O: 障害の予兆を検知して、事前に抑え込んだ事例として共有・開示を
M: またひとつ徳を積んでしまった。
まとめ
- 結果の正しいSQLでも、中間結果が無駄に大きいなどの、潜在性能不具合がありうる
- Seq ScanがないSQLでも、潜在性能不具合がありうる
- そいつらはある日 突然浮上してくる
- 今回上陸は許したが第2形態のうちに始末できた
- 無駄ページキャッシュがパラメータ違いの同じSQLの邪魔をしているうちは大丈夫でも、高頻度SQLのキャッシュを奪い始めたら大惨事
- 「あのSQLが、最後の一匹とは思えない。」
- SSD Array の AWS EBS でも Cache Hit/Miss の差は 10msec : 300msec の30倍差になりうる
- このサービスは Disk Read IO を監視しないといけないところまでDBが成長してしまった
- 次は垂直分割/水平分割だ