Smart Home Concierge ~Sebastian~
最近流行りのAmazon EchoやGoogle Homeに対抗してみようと、Raspberry pi3ベースにしたAIスピーカー(スマートスピーカー)、名付けて__【Smart House Concierge ~Sebastian~】を自作してみました。
主に「ホームオートメーション」__を実現することを主眼に開発したものです。
2017年4月に初めてRaspberry pi3を購入してから約半年間、プログラム規模20[Kstep]を作りこみ、ようやくベースラインが完成したので、システムの概要と実際に使用してみた所感/課題点及びその対策方法について、述べていきたいと思います。
1.自作システム【Smart House Concierge ~Sebastian~】の概要
現状のシステム概要を下記図に表現します。
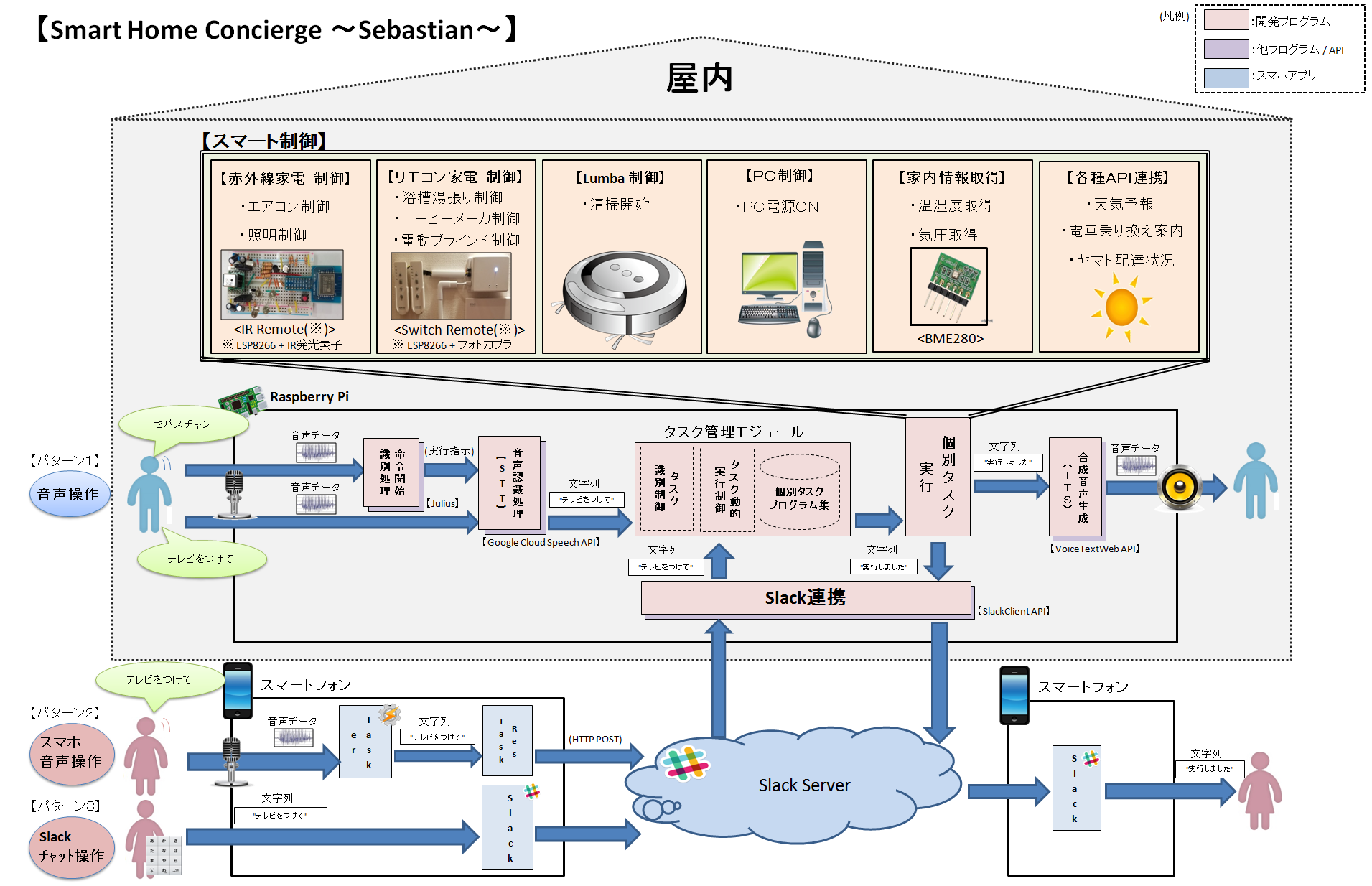
本システムはRaspberry p3に接続したUSBマイクを使った音声操作のほか、Slack及びTaskerと連携し、外部からでもスマホを使った音声操作、チャット操作が出来るようにしています。
開発言語はPythonを利用し、その他システムの実現にあたって利用した主要な各種アプリケーション/APIは下記の通りです。
- 音声→文字列変換(STT)(USBマイク用) : JuliusとGoogle Cloud Speech APIのハイブリッド
- 音声→文字列変換(STT)(スマホ用) : Tasker(Android標準音声認識エンジン)
- チャット(スマホ用) : Slack
- 合成音声生成(TTS) : VoiceTextWeb
- 形態素解析 :Mecab
個々の機能については、他の方々にて詳細を説明されているので、ここでは、プラットフォーム部分について少し説明したいと思います。
※個々の機能は、参考させて頂いたページのリンクを最下段に記載
今回の作成にあたって特に意識した点は、機能拡張性を十分に持たせることです。
そのため、プラットフォーム部分(入力→タスク識別→タスク動的実行)と__個別タスク部分__(例:テレビの電源をONにするプログラム)を明確に分離して開発しました。
上図の「タスク管理モジュール」がプラットフォームのコア部分です。本モジュールでは、インプットを「日本語文字列(例:"テレビをつけて")」で標準化することで、本体マイクからの音声認識、slackのほか、line等様々なインタフェースと親和性を持たせることができます。
個別タスクは、個々に開発したプログラムをデータベース(所定ディレクトリ)及び定義ファイルに登録し、pythonのgetattr関数を用いて、クラス名、メソッド名から動的に実行します。動的実行するための定義ファイルは、以下の2つを使います。
<① 個別タスク定義ファイル>
本定義ファイルでは、個別タスクを動的実行するために必要なクラス名、メソッド名等を定義します。下記例のように、初めに大番号にて、クラス名を定義し、メソッド毎にタスク識別番号(大番号.小番号)、機能名(参考)とメソッド名を定義しています。
# 1 テレビ制御 TVTask
=1.0 電源ON setPowerON
=1.1 電源OFF setPowerOFF
=1.2 ボリューム制御 setVolume
=1.3 チャンネル制御 setChannel
<② タスク識別定義ファイル>
本定義ファイルでは、インプットで与えられた日本語文字列から、個別タスクを識別するための単語列を定義します。「|」はor条件、「タブ」はand条件を意味しており、単語列を複数定義することで、使用する音声認識(STT)の種類や命令者の言語表現の違い等を吸収し、柔軟なタスク識別をすることが出来ます。
下記例では、"テレビをつけてくれる?"というインプットが与えられた場合、タスク識別番号「1.0」とマッチングが取れます。
# テレビ制御用
1.0 テレビ|TV つけて|付けて|ON|オン
1.1 テレビ|TV けして|消して|OFF|オフ
1.2 テレビ|TV 音量|ボリューム
1.3 チャンネル
以上の定義ファイルを用いることで、概ね下記の流れで個別タスクを動的に実行する一連の処理が出来上がります。
インプット:"テレビをつけてくれる?"
↓
個別タスク定義ファイルから検索 → 識別番号「1.0」を取得
↓
タスク識別定義ファイルからクラス名/メソッド名を取得 → クラス名:TVTask メソッド名:setPowerON
↓
getattr関数を使って取得したクラス名/メソッド名から指定のプログラムを実行
↓
テレビの電源がONになる
2.AIスピーカーの課題
実際に完成したシステムを使ってみた印象としては、__「便利といえば便利だけど、積極的に活用する意欲は出ない」__というのが率直な感想です。特に、開発当初はスマホによる操作を実装していない状態で使用しており、AIスピーカーは主に下記3点の課題があることが分かりました。
① 家電等を制御する場面は、家の中にいるよりも家の外にいる時のほうが需要がある
→ 家の中にいるときは、本システムを使わなくとも不便がない
② 本システムを使うより、自分でリモコンを使って操作したほうがぶっちゃけ早い
→ 「音声による命令 → 実行」までの一連の動作を行うより、自分でスイッチを押したほうが早い
③ 音声誤認識が少なからず発生し、ストレスが溜まる
→ 家族や友人と会話していると、誤認識によりシステムが勝手に喋りだすため耳障り
なかなか難しい問題ではありますが、上記はAIスピーカー全般的に言えることであり、何とかしてシステムの価値/有用性を高めようと試行錯誤しました。次章ではその対策について述べます。
3.対策
【課題① 家電等を制御する場面は、家の中にいるよりも家の外にいる時のほうが需要がある】
本課題については1章で述べた通り、スマホを用いて外部からでも命令できるよう機能拡張しました。その方法は様々ありますが、ここではSlackを用いたチャット操作により、外部からでも実行できるようにしています。また、利便性を高めるため、Taskerを用いて、スマホを使った音声認識でも操作できるようにしました※。
※スマホ標準(Android)の音声認識→認識文字列結果取得→SlackAPIを使ってslackへ投稿
これにより、下記例のように利用シーンが増えただけでなく、機能拡張性(チャットに特化した制御(電車乗換案内等))も向上しました。なお、当然ですがシステムは命令元のインタフェース(USBマイク or Slack)を判別し、処理結果(応答)を備え付けのスピーカーから出力するかSlackへ返信するか判断しています。
① "30分後にエアコンを25度冷房でつけて"
② "18時になったらお風呂のお湯を入れて"
③ "東京駅から新宿駅まで明日の12時頃到着で経路を探索して"
以下では、上記利用例③をSlackを使ってスマホから実行したデモ動画を掲載します。
<デモ1(Slackによる電車乗換案内)>
— masat12 (@imasataka2012) 2017年10月5日
【課題② 本システムを使うより、自分でリモコンを使って操作したほうがぶっちゃけ早い】
本問題に対する対策は非常に頭を悩ませました。どんなに処理を高速化しても図1に示すプロセス("セバスチャン"と発音→"命令を指示"→"実行")のリードタイムが発生するため、目の前にあるリモコンを取り上げてボタンを押す動作のほうが圧倒的に早い且つ自然です。
そこで思考を変えて、「複数の命令を一度に実行出来るようにすることで利用価値を向上させる」という観点で対策しました。1命令1実行だと上述の通り普段動作のほうが圧倒的ですが、例えば、「電気をつける+テレビをつける+エアコンをつける」という複数の命令を一度に実行できれば(※)、普段動作より勝ります。
※ここではマクロ機能を意味しているわけではありません。マクロ機能も利便性を向上させる一つの手段ですが、予め定義したパターンしか実行できないため、利用時の時間帯/場面や利用者の気分等に応じた要求を柔軟に対処することはできません。
以上の考えから、タスク管理モジュールに複数命令を識別する機能を実装しました。具体的には、形態素解析結果から表層解析を行い、1文章から1命令ごとに文章を分割し実行します。
インプット :"テレビをつけてそれと電気をつけてついでにエアコンをつけて"(※)
※Google Cloud Speech APIでは句読点の識別はされない
アウトプット:命令1:テレビをつけて
命令2:電気をつけて
命令3:エアコンをつけて
これにより、複数命令を一度に実行できるようになり、屋内にいてもシステムの利便性/利用価値が向上しました。以下では、実際に複数命令を実行したデモ動画を2つ掲載します。
<デモ2(複数命令による家電制御)>
"電気をつけて、それとテレビをつけて、あとパソコンの電源をいれて、
それとテレビをパソコン画面に切替えて、 あとエアコンを24度冷房でつけて、
それと15時なったらエアコンを消して、ついでに明日の18時頃の降水確率を教えて、
・・・よろしく!"
— masat12 (@imasataka2012) 2017年10月5日
<デモ3(複数命令によるタイマー制御)>
"5時になったらエアコンを24度冷房で設定して、それと7時になったらハニカムシェードを開けて、
それと7時30分になったらテレビをつけて"
※ハニカムシェード:電動ブラインドの製品名
— masat12 (@imasataka2012) 2017年10月5日
【課題③ 音声誤認識が少なからず発生し、ストレスが溜まる】
本課題は音声認識(STT)をアプリ/API(Julius/Google Cloud Speech API)で実装しているため、課題解決にあたっては、認識結果を再度独自に評価する必要があります。しかし、追加の処理を入れることでレスポンスの低下や認識精度のカバー率(Recall)低下等が懸念されるため、実装するに至っておりません。
現状は、代替案として、命令開始識別("セバスチャン"と発音)をする代わりに、本体に付けたタクトスイッチを押下することで、認識開始する仕様(切替え可能)で暫定対処しています。
4.今後
上述課題③に対する対策が暫定的なものであるため、認識結果を高速で再評価する処理(例:SVMを使った再評価 等)を慎重に検討した上で、対策していきたいと思います。
また、今後は自作だからこそ出来るニッチでユニークな機能を観点に、継続して機能拡張を図っていきたいと思います。
ちなみに、下記記事にて一般的な家電をAIスピーカやスマホ等と連携できる自作デバイスの作成方法について記載しておりますので、宜しければ読んでみてください。
<Qiitaその他記事>
どんな家電もIoTに対応!AIスピーカー等から操作できる小型デバイスの作成
参考
最後に、本システムを開発する上で参考にさせて頂いた主要記事を以下に記載します。
<Julius関連>
・ Julius で音声認識させてみた
<Google Cloud SPeech関連>
・ Google Cloud Speech APIでストリーミング音声認識
・ Google Cloud Speech gRPC API を使ってストリーム音声認識をしたい!
・ Raspberry PiでGoogle Cloud Speech APIを使う
<VoiceTextWeb API関連>
・ VoiceTextのWeb API(β版)が無料公開だそうですよ。高品質なテキスト読み上げ機能を試しました。
<Slack関連>
・ PythonでSlack botを作ってみる
・ PythonでSlackのボットを作成する
<Wifi赤外線学習リモコン関連>
・ 赤外線LEDリモコンの制作
・ データを送受信をするIoTデバイスの作り方 [ESP-WROOM-02版]
・ ESP8266利用の赤外線リモコン作成
・ 赤外線LEDでリモコンごっこ
・ バイポーラトラジスタ回路の設計
<リモコン家電制御関連>
・ ESP-WROOM-02を使った家電制御
<Wake on Lan 関連>
・ Wake on LAN a machine using Python
<オーディオVUメータ 関連>
・ Realtime Audio Visualization in Python