3年くらい前にWEB屋の自分が機械学習株価予想プログラムを開発した結果 | マサムネットって記事を書いたっきり、機械学習にも株にもあんまり手を付けていなかったのですが、この年末年始、思い切っていろいろ進めてみました。
それで、なかなかに良い感じの結果が得られたので、そのままサービスとして稼働するまでに至った技術的経緯を書いていきます。
サービスそのものへのリンクは、有料サービスですので宗教上の理由などでリンクしたら見られない人もいるかと思いますのでここには張りません。個人的な考えとしては、技術者が適切に稼げる仕組みを作っていくことは重要だと思いますが、つまりは有料だろうと成果物であるサービスへの案内くらい張ったらええやんと思うんですがここではそういうことを論じる場ではありませんのでとにかくサービスそのもののリンクは控えておこうと思います。とはいえ、実際のサービスを見ないと判断しようが無いという意見もあるかと思いますので、軽くたどっていけばサービスに辿り着くようなリンクを記事の最後の方に張っておきたいと思います。前置きはこれくらいにして、最終的にどういう構成になったか、紹介します。
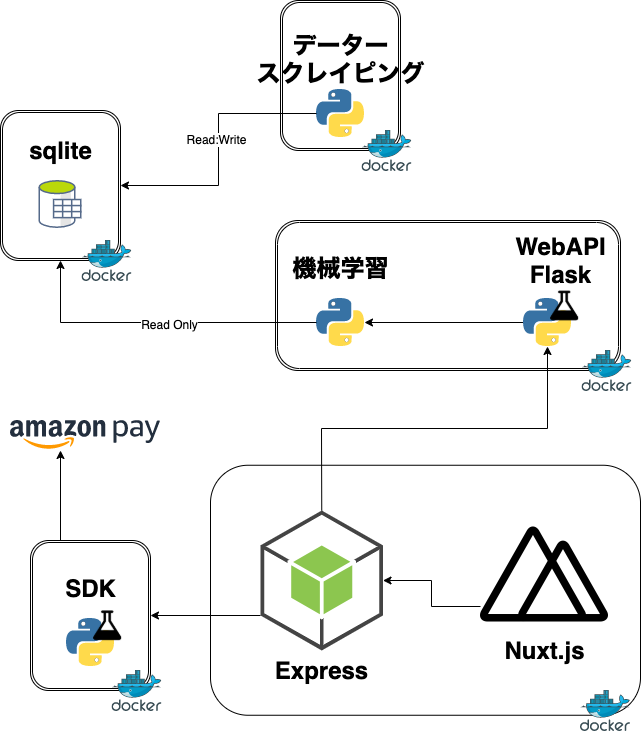
記事について何が言いたいかをひとことで言うと、機械学習の結果がよかったんで広く使ってもらおうとWEBサービスにしようとしたとき、Dockerが相性よかったのでその紹介をしたい、ということになります。
横断的にいろいろな技術を使用していますがどの技術も基本的なところしか使っていませんので、詳しい説明は不要かと思います。ですが、かといって「わかってるよね」の体で話を進めてしまうことに不安を覚える体質ですので、それぞれの技術の説明について少しだけ話をしていきます。
-
Docker
- 仮想コンテナ技術。ファイルのI/Oを利用して仮想的にマシンを閉じ込めておくヴァーチュアルマシン的な恩恵と、コンテナのように環境を積み重ねられる利便性がウケる。
-
Python
- なんか機械学習はPythonみたいな雰囲気。ソースコードそのものを納品するプログラマーよりも、プログラムを利用して算出されたデーターを基に何か答えを導き出す人に重宝されてる傾向。だったが、なんかもうプログラム詳しくない人にまでPythonの名前が行き渡ってしまい、これからの時代はパイソンとか言い出す人もいて色々としんどい。Pythonに罪はない。
-
Flask
- Pythonで作ったプログラムを外部に公開したいときにぱぱっと作れてとっても便利。
-
sqlite
- 簡単なSQL文を実行したいだけなのにCSVでやたら苦労した経験があって、でもRDBMS使うほどではないけど、というかむしろ使いたくはないときにやたら重宝する。後述するけどデーターの可搬性が高いので、スクレイピングにぴったりだと個人的に思う。
-
NuxtJS
- 餅は餅屋、という言葉があるとおり、可能ならフロントエンドはフロントエンドのフレームワークを使うと色々と捗る。
-
Express.js
- 餅は餅屋、という言葉があるとおり、フロントエンドと直接やりとりをするバックエンドは専用のフレームワークを使うと色々と捗る。ユーザーに提供したい導線と、システムが都合の良い導線は必ずしも一緒ではないので、そこらへんをどうやって吸収していくかがフロントエンドと直接やりとりするAPIの設計の鍵。NuxtJS単体でもサーバーサイドレンダリングの際にバックエンド処理ができるわけだが、個人的な経験上、サーバーサイドにNodeJSが使える条件なら、つまりサーバーサイドレンダリングできる環境でNuxtJSを動かそうとするならば、簡単なバックエンド処理でも変にNuxtJSだけで賄おうとせずに最初からExpress.jsの導入を検討すべき。
-
AmazonPay
- アマゾンがやってる少額課金向け決済サービス。今回初めて使ったんで、良いのか悪いのかいろいろ試している最中。paypalと迷ったんだけど日本になじみのありやすさでAmazonのほうを選んだかたち。個人的にはpaypalがもっと普及してくれると地方の少額課金決済盛り上げやすくて助かるのに、と思っている。
Docker編
Dockerに関しての話は、今さら私がここでくどくど説明するまでもないですが、かといって説明を省いても話が進みませんので誤解を恐れずにものすごく表面的なところだけ紹介しておきます。
Dockerが特徴的なのは、オーバーヘッドの少ない仮想化と、自由に積み重ねられる環境のコンテナ化のふたつです。仮想化とコンテナ化、この二つを覚えてください。Docker以前にもコンテナ仮想化の技術は存在していて、事実Dockerも0.9より前のバージョンでは外部のコンテナ仮想化ライブラリを使用していた歴史的経緯もあるので、Dockerだけがコンテナ仮想化の専売特許ではないのですが、Dockerの大きな特徴としてコンテナ仮想化があるという主従関係は成り立ちます。
まず仮想化。コンテナ仮想化以外の従来の仮想化のほとんどは仮想マシンという考えを用いて、CPUから何から何までを仮想的に用意しようとします。実行環境(もしくはゲスト環境とも呼ぶ)に対して、あたかもマシンがあるかのごとく振る舞う技術だったわけです。
そこにきてDockerはファイルのインプットとアウトプット、ここを仮想化させました。ファイルの読み書き部分をコントロールして、あたかもそこに専用のマシンがあるように振る舞うことで、実行環境を切り離したのです。これがオーバーヘッドの少なさを生んでいます。
次にコンテナ化。これは、電源を落としたらここまで巻き戻る、巻き戻りポイントを自由に設定できる、ということです。まっさらのWindowsで一回巻き戻りポイント作っておいて、電源を落とすたびインストールしたてのWindowsが立ち上がるPCを想像してみてください。
次に、それだけだと効率が悪いのでソリティアをインストールした巻き戻りポイントも作ったとします。最初のWindowsと、ソリティアがインストールされたWindows、Dockerでいうと2層目のコンテナが積み上げられました。
次にネットスケープナビゲーター4をインストールしようと思います。まっさらなWindowsにインストールしてもいいですし、ソリティアをインストールした環境にさらにインストールしてもいいかもしれません。どの環境に上積みするか選べるようになります。これがDockerのコンテナの積み上げです。
必要なものを必要なだけ自由に積み上げられて、電源を落とせば元通りにもなる、これがコンテナ化の便利な点です。
オーバーヘッドの少ない仮想化と、自由な環境が構築できていつでも戻せるコンテナ化。
これがDockerのいいところです。
今回はこの技術の恩恵をフルに活用します。
機械学習編
こんな構成で進めていきました。
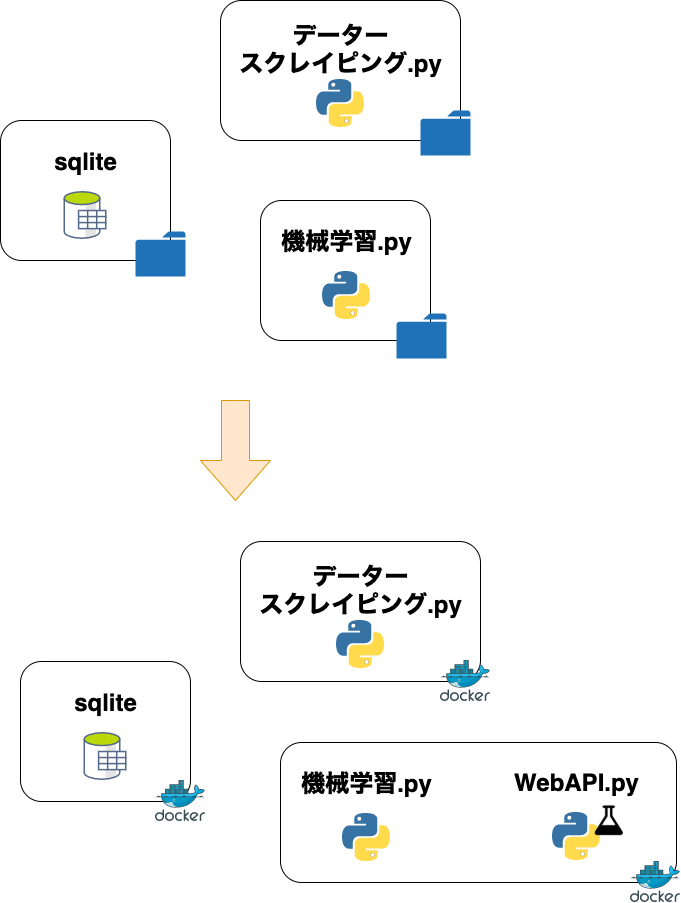
機械学習って、データーを集めて予想たてて計算して結果を基に検証して、また予想たてて、の繰り返しになりますので、開発中はどうしてもデーター集めと機械学習は行ったり来たりを繰り返すことが多いです。最初から、サービスとして公開される設計をすることは難しいはずです。
ですので、各動作をフォルダごとにわけておく程度の設計だけしておけば、あとは機械学習の部分だけ後付けでFlask使ってAPI化させやすかったです。
コツとしては、機械学習を繰り返していくうちにだんだんと「サービスとして公開できそうだな」と思い始めた時点で、APIの入り口を意識して関数にしておくと、あとからFlaskでそのままAPIにしやすいです。
また、後述するバックエンドを別建てでこしらえますので、FlaskはあとでDockerネットワーク内のローカルに閉じてしまえます。ここでのAPI側は最低限のサニタイズやバリデーションを行う程度で済むのも便利です。もちろん、Dockerのゲスト側からホストを乗っ取られるような脆弱性には気をつけないといけませんが、認証など済みの状態としてデーターのやりとりを行えますので、ここではほぼ何もしなくてもデーターを受け渡しできるのはとても強みとなります。
繰り返しますが、ほぼ何もしないといったのは、最低限のサニタイズやバリデーション、認証などはおこなった状態での話です。プレースホルダーを利用してのSQLや、何でもかんでもルート権限で実行しないとか、最低限普通にすべきことはおこなった上での話になりますのでご注意ください。普通とは何かという定義も大事ですが話が広がりすぎるので割愛させてください。
参考までに、実際に稼働させてるコードを公開します。コードが雑ですが、雑なコードで謙遜していては話が進みませんので先に進めます。言いたいことは、適切に閉じた中で管理できれば、こんな感じで受け渡しするだけのコードでも本番まで運用できます、ということです。
# %%
@app.route('/')
def index():
return jsonify({
'status':200,
'data': {}
})
# %%
@app.route('/count')
def count():
return jsonify({
'status':200,
'data': search_stock.get_last_data_count()
})
# %%
@app.route('/last-date')
def last_date():
return jsonify({
'status': 200,
'data': search_stock.get_last_date()
})
# %%
@app.route('/getstock/<code>')
def getstock(code):
low = int(request.args.get('low'))
high = int(request.args.get('high'))
isStockExist = search_stock.get_stock_name(code)
if isStockExist is None or isStockExist is '':
message = '{0} is not found'.format(code)
return jsonify({'message': 'error'}), 500
data = search_stock.get_stock_list(low, high, code)
return jsonify({
'status': 200,
'data': data
})
# %%
@app.route('/getresemble/<code>', methods=['POST'])
def get_resemble(code):
data = request.get_data()
json_data = json.loads(data)
stock_list = json_data['list']
isStockExist = search_stock.get_stock_name(code)
if isStockExist is None or isStockExist is '':
message = '{0} is not found'.format(code)
return jsonify({'message': 'error'}), 500
result = get_stock.start(code, stock_list)
return jsonify({
'status': 200,
'data': result,
})
# %%
if __name__ == "__main__":
app.run(host='0.0.0.0',port=5000,debug=True)
データー部分
なんでもかんでもDockerコンテナ化すればいいってもんじゃないんですが、データーもDockerコンテナ化しました。
最初は、データー部分はDockerからは外部ボリュームとしてマウントさせる予定だったのですが、ご存じの方も多いとおり、linuxでDockerからホストのボリュームをマウントしようとするとホスト側のroot権限が必要なんです。解決方法としては、Dockerコンテナ側をどうにかするか、Dockerホスト側をどうにかするかしかないんですが、私の場合、ここにGitlabのCI/CDで運用してるgitlab-runnerユーザーが存在してたり、そのgitlab-runnerをsudoで実行してる環境があったりして、つまり稼働する環境によってユーザーの状況がまちまちななので素直にDockerに閉じ込めました。
ここもDockerコンテナ化させてよかったのは、データーの可搬性も高まったので、後に続くスクレイピング部分とあわせて強力なスクレイピング環境が出来たことです。
いちおう参考までに、データー部分のDockerfileを紹介しておきます。
FROM busybox
WORKDIR /data
COPY . ./
VOLUME [ "/data" ]
ファイルをそのまま閉じ込めさえすればDB環境まるごと持ち歩けるのは、sqliteのいいところですね。
あと、株価データーのテーブル設計として、銘柄ごとにテーブルを分けるか、それともひとつのテーブルで銘柄コードを GROUP BY code みたいな運用でいくか、みたいな悩みポイントがあるんですが、どれも善し悪しがあって甲乙付けがたいです。今回はさっくりと、ひとつの銘柄ひとつのDB、で運用してみました。銘柄コード1234にアクセスするには、銘柄コード1234のDBにアクセスする形です。
銘柄を横断的にアクセスするのに少しオーバーヘッドがかかりますが、とにかくこれもまた善し悪しあって今回はこのようにしました。株価のDB設計の善し悪しについても、機会があればもう少し詳しく語ってみたいと思います。
sqliteのファイルまるごとDockerイメージで運用するデメリットとしては、データーを更新するたびにイメージを作り直す必要があるので、CI/CD環境をうまくやっておかないとイメージがどんどん貯まるようになることです。可搬性も言うほど高くなるわけではなく、なぜならDocker-in-Docker(DinD)を許容するかしないかの使い手の考え方によるところが多いですがDinDを使用しない場合、データーの更新はシェル上で行うことが前提なので結局実行環境を選ぶからです。それが嫌ならDinD環境をもっと突き詰めるしか無いんですが、このへんは将来プロダクション環境にどこまでチューニングしたDinDを持ってくるか、シェル環境下で安定させた方が良いのか、kubernetesまで視野に入れるならRDBMSで作り直した方が早かったりと、いろいろと考慮に入れる部分が多くなります。
ものすごく個人的な見方をすると、DinDはDocker公式がサポートするようになったとはいえもともとかなり想定外の使われ方だった歴史的経緯、DonDは下手したらホストOSのセキュリティホールになりかねない運用をしないといけないなど、DinDを取り巻く環境はまだ揃ってるとは言いがたいので、できるだけDockerfileはshellから触るようにしています。ものすごく便利で強力な技術であることは間違いないので、期待はとても大きいです。
そんなこんなの諸々をさっくりと見て見ぬふりして、とりあえず今は動かすことを優先させるときにsqliteでまるごとイメージを作るのは選択に入れても良いと思いました。
スクレイピング部分
今回扱うデーターは株価なので、スクレイピング環境の可搬性を高めることは最優先条件でした。常に最新のデーターをスクレイピングしたいですので、最初ここは迷わずDockerコンテナにしました。
何も考えず、コンテナ起動したらスクレイピングして、終わったらコンテナごと落ちる、ここまでを自動化できるので、非常に便利です。
これをそのままcrontabで回しても良いですし、時間が来たらEC2起動、EC2側が起動したら自動でコンテナ立ち上げて、スクレイピング終了したらコンテナごとEC2終了、までも簡単に作れるようになりました。
良いことずくめだったんですが、最終的にはスクレイピング部分の主な部分はDockerで実行できる場合とシェルで直接実行する場合と二種類用意しました。全ての環境でDockerが便利、とはいかなかったからです。
結局はDockerがマウントしたホスト側のボリュームがroot所有になる問題がここでも避けることが出来ず、そういう環境ではホスト側のシェルで実行した方がよかったからです。
ですので、シェルで直接実行できる場合、Pythonの実行環境をDockerでまかなう場合、スクレイピング環境までをDockerコンテナ内で行う場合、と最終的には3種類の環境を用意できるようにしました。
フロントエンド編
機械学習が捗って、この成果物を自分のものだけにするのはもったいない、ぜひWEBに公開して広くみんなにも使ってもらいたい!と思ったら、次はフロントエンドの開発になります。
私が個人的にフレームワークを選ぶときの目安として、バックエンドの開発が重いときはlaravelなどバックエンド用のフレームワークを、そうでないときはできるだけフロントエンドのフレームワークを選ぶ傾向にあります。もちろん、案件によっては稼働するサーバーに制限がある場合もあるのでこの限りでは無いですが、少なくとも自由に選べるならなるべくフロントエンドから構築していくようにします。
今回も、機械学習という一番複雑な部分はもう出来てるので、これ以上複雑なバックエンド処理は必要ないということで迷わずExpress.js + NuxtJSの構成を選びました。
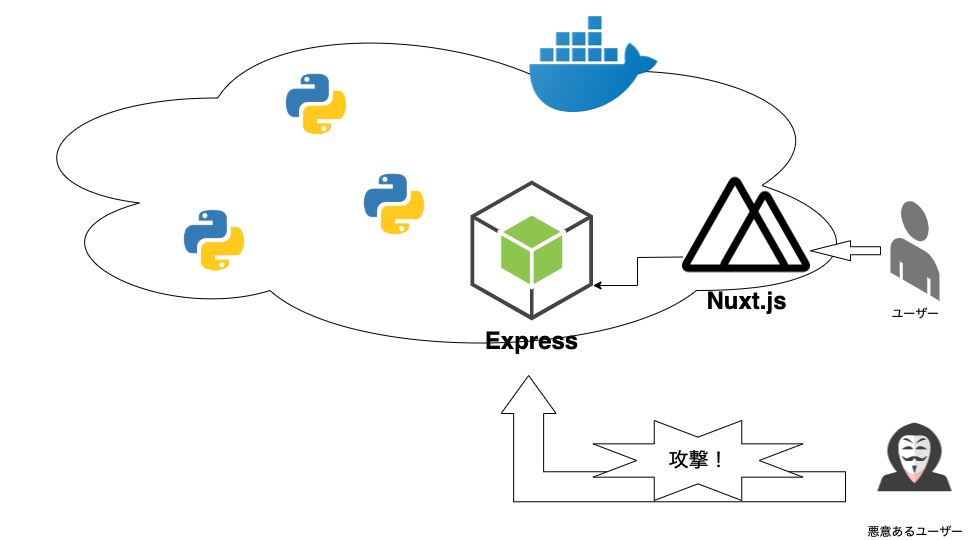
繰り返しになりますが、閉じられてるから安全と言いたいわけではないんです。ですが、表に見える部分はこれだけしか見せなくて済んで、中はどうなってるかを外側から知るには、カーネルからのハックなど何か別の方法を講じない限りは方法が無い、というのは、経験豊富なエンジニアほど設計のしやすさを感じると思います。
なんでもかんでもDockerコンテナ化させるのはよくないと思いますが、ここも最終的にはDockerコンテナ化しました。ここは特に開発中のトライアル&エラーが多いので、コンテナー化させて起動、ログをコンテナで確認、みたいなことをできるだけしたくなくて、特にドメインで実行環境も固定される部分だしホスト側のNode.jsで起動できないか、最後まで詰めた部分でした。
ですが最終的にはここも全てDockerコンテナに閉じ込めました。理由は、バックエンドとのやりとりをするときに、ネットワークの環境に左右されやすくなるのでここもまるっとDockerネットワークに閉じ込めてしまった方が便利だとわかったからです。
最終的にはDockerはhttpsとhttpの443ポートと80番ポートだけ開けといて、あとはDockerネットワークの内側でやりとりするような形にしました。
AmazonPay
ここが一番苦労して、Amazon側は丁寧な日本語の解説もいろんな言語のSDKも提供してくれているので、私のスキルが足りないからなのですが、かなり開発に時間を使いました。
まず、SDKは各種言語揃っているのですがNode.js用のものが無いので、Express.jsから直接やりとりできないか試すのに時間がかかりました。axiosを使ってAPIと直接やりとりできないか試したかったのですが、私の探し方が悪いのか、APIとの直接通信は簡単なサンプルしか見つからなくて、トライアル&エラーで正解を探し当てるのにとてつもなく時間を使いました。
というのも、AmazpnPayはあらかじめ登録されたドメイン配下にあるhttps配下からの通信しか受け付けないので、この時点でひとつ試そうとするとconsole.logひとつ追加するためにdevelopブランチにマージ→gitlab-runnerが走るのを待ってDockerコンテナ化→Docker
起動後、ブラウザで動作チェック→SSHされたサーバーのDocker logsで稼働コンテナのログを表示、を繰り返さなくてはならなくて、とても現実的で無いと知ったからです。
今後もっと良い方法が見つかるかも知れませんが、今の流れでできることといったら、提供されてるSDKでAPIを叩くAPIを作ることだったので、今回はPythonSDKを選びました。
フロントエンドのほうも、少し苦労しました。
読み込みと描画のタイミングが同じ前提の設計になっているため、モジュールだけあらかじめ読み込んでおいて描画のタイミングでUIを生成する、みたいなことが出来ないのです。さらにモジュールの破棄→生成のライフサイクルも考慮されているわけでもないので、描画のたびに読み込み直すように手直しするのも至難の業で、Vue.jsのライフサイクルを使ってある程度までは調整したものの作り手が想定してる動作でないため少し不安の残る実装となりました。
これは閲覧者が閲覧者の都合でカート画面を行ったり来たりする支払いボタンでは致命的で、再描画するにはリロードするしか無いこの作り手の都合は、AmazonPayボタンの少なくともスクラッチパッドがメンテされてた4年前で考えてみても設計が古いと言わざるを得ません。文句ばっかりになってしまいましたが、とても可能性のある決済サービスだと思うので、ぜひとも改善をしていただきたいところです。
何が言いたいかっていうとDockerでサービス化するのやりやすかった
今回、図らずも全てDockerコンテナでの運用になったのですが、最初に何も考えず作って、あとからコンテナ設計していく手法は機械学習のサービス化にとても親和性が高いと感じました。ひととおりコンテナになっていますので、今後サービスをスケールするときにkubernetesでの導入も容易かもしれないですし、いろいろと捗るのではないでしょうか。
今回、横断的にいろんな技術を導入していますが、どれも基本的なところしか触っていなくて、だから見方によってはするほどのものでもないのかもしれません。
ですが、機械学習をバリバリする人はDockerを使った簡単なデプロイのやり方を知らないかもしれないし、Nuxt.jsをバリバリこなす人がいい機械学習の活用方法を思いつくかもしれません。今回横断的に投入した技術の記録が、何かのヒントになれば幸いです。
今回は機械学習の方法そのものには触れませんでしたが、株価を機械学習でどう扱うのかはこちらに記事をわけて書いてあります。よかったらそちらのほうも参考にしてみてください。