TypeScriptサポート
Supabase Javascript Client
Supabaseクライアントの生成
import { createClient } from '@supabase/supabase-js'
// Create a single supabase client for interacting with your database
const supabase = createClient('https://xyzcompany.supabase.co', 'public-anon-key')
Supabaseクライアントの必須項目
supabaseUrl(必須):プロジェクトダッシュボードで作成したときに提供される一意のSupabase URL。
supabaseKey(必須):プロジェクトダッシュボードで作成したときに提供される一意のSupabaseキー。
Supabaseクライアントのオプション項目
authのオプション
認証オブジェクト
autoRefreshToken(オプション)
ログイン済みユーザーのトークンを自動的に更新するかどうかを指定するブール値。デフォルトはtrue。
detectSessionInUrl(オプション)
URLからセッションを検出するかどうかを指定するブール値。OAuthログインのコールバックに使用されます。デフォルトはtrue。
flowType(オプション)
flowTypeプロパティを使用することで、Supabaseクライアントが使用するOAuthフローを指定することができます。
デフォルトでは、implicit flowが使用されます。
デフォルトでは、implicit flowを使用します。
ただし、モバイルアプリケーションやサーバーサイドアプリケーションでは、PKCEが推奨されています。
PKCEを使用することで、より安全なOAuth認証を実現することができます。
OAuthフローは、認証サーバーとクライアントアプリケーション間での認証と認可を行うためのプロトコルです。
PKCE(Proof Key for Code Exchange)は、OAuth 2.0の認証フローの一つで、Webアプリケーションやモバイルアプリケーションなど、クライアントが公開されたクライアントシークレットを使用せずに、より安全な認証を実現するための仕組みです。
PKCEは、認証コードを取得する前に、ランダムな文字列(code_verifier)を生成し、ハッシュ関数を使用して変換した値(code_challenge)を作成します。このcode_challengeを、認証コードを取得する際に、認証サーバーに送信します。認証サーバーは、code_challengeを保存し、認証コードを発行します。その後、クライアントは、認証コードを使用してアクセストークンを取得するために、code_verifierを使用してcode_challengeを再計算し、認証サーバーに送信します。認証サーバーは、再計算されたcode_challengeと保存されたcode_challengeを比較し、一致する場合にのみアクセストークンを発行します。
このように、PKCEは、ランダムな文字列を使用して、認証コードを取得する前と後に、認証サーバーとクライアント間で秘密情報を共有することなく、より安全な認証を実現することができます。PKCEは、モバイルアプリケーションやサーバーサイドアプリケーションなど、公開されたクライアントシークレットを使用できない場合に特に有用です。
persistSession(オプション):ログイン済みセッションをストレージに永続化するかどうかを指定するブール値。デフォルトはtrue。
storage(オプション):ログイン済みセッションを保存するために使用されるストレージプロバイダー。
storageKey(オプション):ローカルストレージにトークンを保存するために使用されるオプションのキー名。
dbのオプション
テーブルが属するPostgresスキーマ。Supabaseで公開されているスキーマのリストに含まれている必要があります。デフォルトはpublicです。
schema(オプション):スキーマ名。
globalのオプション
fetch(オプション):カスタムfetch実装。
headers(オプション):クライアントを初期化するためのオプションヘッダー。
realtime(オプション):realtime-jsインスタンスに渡されるオプション。
Supabaseの型の生成
SupabaseのDB内にあるすべての型を生成します。
Next.jsの場合 src/typesフォルダを作成しておきます。
supabase start
supabase gen types typescript --local > src/types/database.types.ts
※ Docker Desktopを起動させておきます。(ローカル開発時)
※ src/typesフォルダは作成しておくこと(型の生成場所は自由)
※ DBのテーブルを変更した場合は、再度型を生成する必要があります。(重要)
↑上記コマンドでSupabaseから型を取得すると、
↓中身はこうなっています。
//一部抜粋
Row: {
content: string | null;
user_id: string | null;
id: string;
created_at: string | null;
};
Insert: {
content?: string | null;
user_id?: string | null;
id?: string;
created_at?: string | null;
};
Update: {
content?: string | null;
user_id?: string | null;
id?: string;
created_at?: string | null;
};
Row
説明: テーブルの行を取得する時に使用される型、select文を実行するときに、Rowの型を指定して取得したデータを型付けすることができます。
Insert インサートにはInsertを使用する
説明: テーブルに行を挿入するために使用される型、insert文を実行するときに、Insertの型を指定して挿入するデータを型付けすることができます。
Update
説明: テーブルの行を更新するために使用される型、update文を実行するときに、Updateの型を指定して更新するデータを型付けすることができます。
※Rowとか説明もなしに書かれていて、何がどうなっているのかわかりにくいですが、select文を実行するときに、Rowの型を指定して取得したデータを型付けすることができます。
↓実際の使い方、database.types.tsという型を生成したファイルから
interface Database {
public: {
Tables: {
movies: {
Row: {} // The data expected to be returned from a "select" statement.
Insert: {} // The data expected passed to an "insert" statement.
Update: {} // The data expected passed to an "update" statement.
}
}
}
}
↑型ファイルdatabase.types.tsの中身はこうなっています。
↓このように型をimportします。
import type { Database } from './lib/database.types';
↓実際に型ファイルを使用してデータを取得するコード例
データベースからpublic.moviesテーブルの全データ.select('*')を取得しています。
これが基本形です。
import { createClient } from '@supabase/supabase-js';
import type { Database } from './lib/database.types';
const supabaseUrl = 'https://your-supabase-url.com';
const supabaseKey = 'your-supabase-key';
const supabase = createClient(supabaseUrl, supabaseKey);
async function getMovies() {
const { data, error } = await supabase
.from<Database['public']['Tables']['movies']['Row']>('public.movies')
.select('*');
if (error) {
console.error(error);
return;
}
console.log(data);
}
getMovies();
↑TypeScriptの場合は、fromメソッドに型を渡す必要があります。
TypeScriptのジェネリック型を使用して、型を渡すことができます。
.from<Database['public']['Tables']['movies']['Row']>
Rowを渡しているのでSQL文でいうselectでデータを取得するとわかります。
Rowは型を生成するごとに変わります。
// 一部抜粋
Row: {
content: string | null;
user_id: string | null;
id: string;
created_at: string | null;
};
※この部分はドキュメントの説明が足りないので色々と調べる必要がありました。
Injecting type definitions
import { createClient } from '@supabase/supabase-js'
import { Database } from 'lib/database.types'
// ↓ジェネリック型を使用して、型を渡すことができます。
const supabase = createClient<Database>(
process.env.SUPABASE_URL,
process.env.SUPABASE_ANON_KEY
)
このようにDBで生成した方を読み込ませて、ジェネリック型を使用することで createClient<Database> で型を指定してあげることで、型が適用される。
このコードでは、Supabaseクライアントを作成する際に、createClient関数にジェネリック型を指定しています。これにより、Supabaseクライアントが使用する型がDatabase型になり、型安全性が向上します。また、Database型は、DBで生成した型定義を読み込んでいるため、正しい型が適用されるようになっています。
Type hints
export async function getMovies() {
return await supabase.from('movies').select(`id, title`)
}
type MoviesResponse = Awaited<ReturnType<typeof getMovies>>
export type MoviesResponseSuccess = MoviesResponse['data']
export type MoviesResponseError = MoviesResponse['error']
このコードでは、Supabaseクライアントのfromメソッドを使用して、moviesテーブルからidとtitleの列を選択するクエリを実行しています。getMovies関数は、このクエリを実行し、成功した場合はdataオブジェクトを、失敗した場合はerrorオブジェクトを返します。
MoviesResponse型は、getMovies関数の戻り値の型を表します。Awaitedユーティリティ型を使用して、getMovies関数の戻り値のPromise型から、実際の戻り値の型を取得しています。
MoviesResponseSuccess型は、MoviesResponse型のdataプロパティの型を表します。これにより、getMovies関数が成功した場合に返されるデータの型を取得することができます。
MoviesResponseError型は、MoviesResponse型のerrorプロパティの型を表します。これにより、getMovies関数が失敗した場合に返されるエラーの型を取得することができます。
このように、TypeScriptの型ヒントを使用することで、Supabaseクライアントから返されるデータの型を正確に指定することができます。
Nested tables
このコードでは、Supabaseクライアントのfromメソッドを使用して、moviesテーブルからid、title、およびactorsテーブルのすべての列を選択するクエリを実行しています。
Actors型は、actorsテーブルの行の型を表します。Database型は、DBで生成した型定義を読み込んでいるため、Actors型は、Database型から取得することができます。
MoviesResponse型は、getMovies関数の戻り値の型を表します。Awaitedユーティリティ型を使用して、getMovies関数の戻り値のPromise型から、実際の戻り値の型を取得しています。
MoviesResponseSuccess型は、MoviesResponse型のdataプロパティの型を表します。&演算子を使用して、actorsプロパティを追加しています。これにより、getMovies関数が成功した場合に返されるデータの型を取得することができます。actorsプロパティの型は、Actors型の配列です。
このように、TypeScriptの型ヒントを使用することで、Supabaseクライアントから返されるデータの型を正確に指定することができます。また、ネストされたテーブルの場合には、自分で型を構築することができます。
Fetch data
※ SQL文でいうselectでデータを取得するに相当します。
Supabaseクライアントのselectメソッドを使用して、テーブルまたはビューからデータを取得する方法です。
selectメソッドは、カンマで区切られた列名を指定することで、取得する列を指定することができます。また、customName:columnNameの形式で列名を変更することもできます。
※ この Fetch data は特に説明が長いです。
Fetch data オプション
count
countプロパティには、
exact、planned、estimatedの3つの値を指定することができます。
exact
正確なが遅いカウントアルゴリズムが使用されます。内部でCOUNT(*)が実行されます。
planned
近似値が高速に計算されるカウントアルゴリズムが使用されます。内部でPostgresの統計情報が使用されます。
estimated
低い数値では正確なカウントが使用され、高い数値では近似値が使用されます。
head (boolean)
true, false
true
dataは返されません。
※ カウントのみが必要な場合に便利です。
false
デフォルト値です。
Fetch data使用例
全データの取得方法 (Getting your data)
# Code
const { data, error } = await supabase
.from('countries')
.select()
# Data source
create table
countries (id int8 primary key, name text);
insert into
countries (id, name)
values
(1, 'Afghanistan'),
(2, 'Albania'),
(3, 'Algeria');
# Response
{
"data": [
{
"id": 1,
"name": "Afghanistan"
},
{
"id": 2,
"name": "Albania"
},
{
"id": 3,
"name": "Algeria"
}
],
"status": 200,
"statusText": "OK"
}
特定のデータ項目の取得方法 (Selecting specific columns)
nameだけ抜き出す。(idは不要)
# Code
const { data, error } = await supabase
.from('countries')
.select('name')
# Data source
create table
countries (id int8 primary key, name text);
insert into
countries (id, name)
values
(1, 'Afghanistan'),
(2, 'Albania'),
(3, 'Algeria');
# Response
{
"data": [
{
"name": "Afghanistan"
},
{
"name": "Albania"
},
{
"name": "Algeria"
}
],
"status": 200,
"statusText": "OK"
}
外部キーを使用して関連データを抜き出す (Query foreign tables)
テーブルに外部キーと関係がある場合、関連するテーブルにも問い合わせることができます。
# Code
const { data, error } = await supabase
.from('countries')
.select(`
name,
cities (
name
)
`)
# Data source
create table
countries (id int8 primary key, name text);
create table
cities (
id int8 primary key,
country_id int8 not null references countries,
name text
);
insert into
countries (id, name)
values
(1, 'Germany'),
(2, 'Indonesia');
insert into
cities (id, country_id, name)
values
(1, 2, 'Bali'),
(2, 1, 'Munich');
# Response
{
"data": [
{
"name": "Germany",
"cities": [
{
"name": "Munich"
}
]
},
{
"name": "Indonesia",
"cities": [
{
"name": "Bali"
}
]
}
],
"status": 200,
"statusText": "OK"
}
結合テーブルを介した外部テーブルのクエリ方法 (Query foreign tables through a join table)
外部テーブルを結合テーブルを介してクエリする方法について。
結合テーブルは、外部キーを含む複合主キーの一部である必要があります。
この例では、usersテーブルとteamsテーブルがあり、users_teamsテーブルが結合テーブルとして使用されています。
users_teamsテーブルは、user_idとteam_idの2つの外部キーを持ち、複合主キーとして定義されています。
selectメソッドでは、usersテーブルからname列を取得し、teamsテーブルからname列を取得しています。
teamsテーブルは、users_teamsテーブルを介してusersテーブルと関連付けられています。
dataプロパティには、name列とteams列が含まれています。teams列には、name列が含まれています。
statusプロパティには、HTTPステータスコードが含まれています。statusTextプロパティには、HTTPステータスコードに対応するテキストが含まれています。
# Code
const { data, error } = await supabase
.from('users')
.select(`
name,
teams (
name
)
`)
# Data source
create table
users (
id int8 primary key,
name text
);
create table
teams (
id int8 primary key,
name text
);
-- join table
create table
users_teams (
user_id int8 not null references users,
team_id int8 not null references teams,
-- both foreign keys must be part of a composite primary key
primary key (user_id, team_id)
);
insert into
users (id, name)
values
(1, 'Kiran'),
(2, 'Evan');
insert into
teams (id, name)
values
(1, 'Green'),
(2, 'Blue');
insert into
users_teams (user_id, team_id)
values
(1, 1),
(1, 2),
(2, 2);
# Response
{
"data": [
{
"name": "Kiran",
"teams": [
{
"name": "Green"
},
{
"name": "Blue"
}
]
},
{
"name": "Evan",
"teams": [
{
"name": "Blue"
}
]
}
],
"status": 200,
"statusText": "OK"
}
同じ外部テーブルを複数回クエリする方法 (Query the same foreign table multiple times)
同じ外部テーブルを複数回クエリする必要がある場合は、参加する列の名前を使用して、どの結合を使用するかを識別します。また、各列にエイリアスを付けることもできます。
この例では、usersテーブルが2回参照されています。messagesテーブルには、sender_idとreceiver_idの2つの外部キーがあり、それぞれusersテーブルのid列を参照しています。
selectメソッドでは、messagesテーブルからcontent列を取得し、sender_id列とreceiver_id列をusersテーブルのname列に参照しています。
fromとtoは、それぞれsender_idとreceiver_idのエイリアスです。
dataプロパティには、content列、from列、to列が含まれています。
from列とto列には、それぞれname列が含まれています。
statusプロパティには、HTTPステータスコードが含まれています。
statusTextプロパティには、HTTPステータスコードに対応するテキストが含まれています。
# Code
const { data, error } = await supabase
.from('messages')
.select(`
content,
from:sender_id(name),
to:receiver_id(name)
`)
# Data source
create table
users (id int8 primary key, name text);
create table
messages (
sender_id int8 not null references users,
receiver_id int8 not null references users,
content text
);
insert into
users (id, name)
values
(1, 'Kiran'),
(2, 'Evan');
insert into
messages (sender_id, receiver_id, content)
values
(1, 2, '👋');
# Response
{
"data": [
{
"content": "👋",
"from": {
"name": "Kiran"
},
"to": {
"name": "Evan"
}
}
],
"status": 200,
"statusText": "OK"
}
外部テーブルをフィルタリングする方法 (Filtering through foreign tables)
supabaseクライアントのselectメソッドを使用して、citiesテーブルからname列とcountriesテーブルの全列を取得し、countriesテーブルのname列がEstoniaである行のみをフィルタリングしています。
dataプロパティには、name列とcountries列が含まれています。
countries列には、name列が含まれていますが、フィルタリング条件に一致する行がないため、nullが返されています。
外部テーブルの列でフィルタリング条件が満たされない場合、外部テーブルは[]またはnullを返しますが、親テーブルはフィルタリングされません。
親テーブルの行もフィルタリングしたい場合は、!innerヒントを使用する必要があります。!innerヒントを使用すると、外部テーブルのフィルタリング条件が満たされない場合、親テーブルの行もフィルタリングされます。
# Code
const { data, error } = await supabase
.from('cities')
.select('name, countries(*)')
.eq('countries.name', 'Estonia')
# Data source
create table
countries (id int8 primary key, name text);
create table
cities (
id int8 primary key,
country_id int8 not null references countries,
name text
);
insert into
countries (id, name)
values
(1, 'Germany'),
(2, 'Indonesia');
insert into
cities (id, country_id, name)
values
(1, 2, 'Bali'),
(2, 1, 'Munich');
# Response
{
"data": [
{
"name": "Bali",
"countries": null
},
{
"name": "Munich",
"countries": null
}
],
"status": 200,
"statusText": "OK"
}
関連するテーブルのカウントを使用したクエリ (Querying foreign table with count)
cities(count)を使用することで、citiesテーブルの各国に関連する行の数を取得できます。このクエリの結果、countriesテーブルの各行には、citiesテーブルの各国に関連する行の数が含まれるようになります。
また、このクエリでは、countriesテーブルとcitiesテーブルの関係を表す外部キー制約が設定されています。citiesテーブルのcountry_id列は、countriesテーブルのid列を参照しています。これにより、citiesテーブルの各行がどの国に関連しているかを特定することができます。
このクエリの結果は、以下のようになります。
この結果では、countriesテーブルの各行には、idとnameの2つの列が含まれます。また、citiesテーブルの各国に関連する行の数が含まれるようになります。この例では、citiesテーブルのcountry_id列が693694e7-d993-4360-a6d7-6294e325d9b6である行が4つあるため、cities配列には{"count": 4}が含まれます。
関連するテーブルの行数を取得するには、countプロパティを使用します。
# Code
const { data, error } = await supabase
.from('countries')
.select(`*, cities(count)`)
# Data source
create table countries (
"id" "uuid" primary key default "extensions"."uuid_generate_v4"() not null,
"name" text
);
create table cities (
"id" "uuid" primary key default "extensions"."uuid_generate_v4"() not null,
"name" text,
"country_id" "uuid" references public.countries on delete cascade
);
with country as (
insert into countries (name)
values ('united kingdom') returning id
)
insert into cities (name, country_id) values
('London', (select id from country)),
('Manchester', (select id from country)),
('Liverpool', (select id from country)),
('Bristol', (select id from country));
# Response
[
{
"id": "693694e7-d993-4360-a6d7-6294e325d9b6",
"name": "United Kingdom",
"cities": [
{
"count": 4
}
]
}
]
行数取得の使用例 (Querying with count option)
countriesテーブルからすべての行を取得し、行の数を取得しています。selectメソッドの第2引数に{ count: 'exact', head: true }を指定することで、行の数を取得できます。countプロパティには、行の数が含まれます。
また、このクエリでは、countriesテーブルに3つの行があることが前提となっています。insert文を使用して、countriesテーブルに3つの行を挿入しています。
# Code
const { count, error } = await supabase
.from('countries')
.select('*', { count: 'exact', head: true })
# Data source
create table
countries (id int8 primary key, name text);
insert into
countries (id, name)
values
(1, 'Afghanistan'),
(2, 'Albania'),
(3, 'Algeria');
# Response
{
"count": 3,
"status": 200,
"statusText": "OK"
}
JSONデータのクエリ例 (Querying JSON data)
usersテーブルからすべての行を取得し、address列のcityプロパティを取得しています。
address->cityを使用することで、address列のJSONオブジェクトからcityプロパティを取得できます。
また、このクエリでは、usersテーブルに1つの行があることが前提となっています。
insert文を使用して、usersテーブルに1つの行を挿入しています。
dataプロパティには、id、name、およびaddress列のcityプロパティが含まれるオブジェクトが含まれます。
また、statusプロパティにはHTTPステータスコードが含まれます。
この例では、ステータスコードは200であり、statusTextプロパティにはステータスコードに対応するテキストが含まれます。
JSONカラムの中でデータを選択し、フィルタリングすることができます。
# Code
const { data, error } = await supabase
.from('users')
.select(`
id, name,
address->city
`)
# Data source
create table
users (
id int8 primary key,
name text,
address jsonb
);
insert into
users (id, name, address)
values
(1, 'Avdotya', '{"city":"Saint Petersburg"}');
# Response
{
"data": [
{
"id": 1,
"name": "Avdotya",
"city": "Saint Petersburg"
}
],
"status": 200,
"statusText": "OK"
}
Insert、Update、Upsert、Delete これらはFetch data(select文)似たようなので省略
公式ドキュメントのURLのみ貼り付けておきます。
Insert data
Update data
Upsert data
Delete data
Call a Postgres function
関数呼び出しを実行する。
SupabaseのJavaScriptクライアントでPostgreSQLの関数を呼び出す方法です。
関数は、データベース内のロジックをどこからでも実行することができ、パスワードのリセットや更新などのように、データがそれほど変更が必要ない場合に便利です。
関数を呼び出すには、supabaseオブジェクトのrpcメソッドを使用します。
rpcメソッドには、呼び出す関数の名前と、オプションの引数が含まれます。
以下は、hello_worldという名前の関数を呼び出す例です。
import { createClient, SupabaseClient } from '@supabase/supabase-js';
const supabaseUrl = 'https://your-supabase-url.com';
const supabaseKey = 'your-supabase-key';
const supabase: SupabaseClient = createClient(supabaseUrl, supabaseKey);
async function callHelloWorld() {
const { data, error } = await supabase.rpc<{ message: string }>('hello_wor ld');
if (error) {
console.error(error);
return;
}
console.log(data);
}
callHelloWorld();
# Data source
create function hello_world() returns text as $$
select 'Hello world';
$$ language ;
# Response
{
"data": "Hello world",
"status": 200,
"statusText": "OK"
}
この例では、rpcメソッドに'hello_world'を指定して、hello_worldという名前の関数を呼び出しています。
関数が返すデータは、dataプロパティに含まれます。
errorプロパティには、エラーが発生した場合にエラーオブジェクトが含まれます。
また、options引数には、countとheadという2つのオプションが含まれます。
countオプションは、関数が返す行数を数える方法を指定します。
headオプションは、dataプロパティを返さず、行数だけを返すようにします。
フィルターの使用について (Using filters)
※ ここも特に長いです。
フィルタを使用すると、特定の条件に一致する行のみを返すことができます。
フィルタは、select()、update()、upsert()、delete()クエリで使用することができます。
Postgres の関数がテーブル応答を返す場合にも、フィルタを適用することができます。
↓省略
## Column is equal to a value (列は値と等しい)
## Column is not equal to a value (列は値と等しくない)
## Column is greater than a value (列はある値より大きい)
## Column is greater than or equal to a value (列は値より大きいか等しい)
## Column is less than a value (列は値より小さい)
## Column is less than or equal to a value (列は値より小さいか等しい)
## Column matches a pattern (列がパターンにマッチします)
## Column matches a case-insensitive pattern (列は大文字と小文字を区別しないパターンにマッチする)
## Column is a value (列は値です)
## Column is in an array (列が配列に含まれます)
## Column contains every element in a value (列は値の全要素を含む)
## Contained by value (値に含まれます)
## Greater than a range (ある範囲より大きい)
## Greater than or equal to a range (ある範囲より大きいか等しい)
## Less than a range (ある範囲より小さい)
## Less than or equal to a range (範囲より小さい、または範囲に等しい)
## Mutually exclusive to a range (相互に排他的な範囲)
## With a common element (共通の要素を持つ)
## Match a string (文字列と一致する)
## Match an associated value (関連する値にマッチする)
## Don't match the filter (フィルタにマッチしない)
## Match at least one filter (少なくとも1つのフィルタにマッチする)
## Match the filter (フィルタに一致する)
↑省略
Using modifiers
フィルタは、行レベルで機能し、特定の条件に一致する行のみを返すことができます。フィルタを使用することで、行の形状を変更することなく、特定の条件に一致する行のみを取得することができます。修飾子は、この定義に合わないすべてのもので、応答の形式を変更することができます(たとえば、CSV文字列を返すことができます)。
修飾子は、フィルタの後に指定する必要があります。一部の修飾子は、行を返すクエリ(たとえば、テーブル応答を返す関数のselect()またはrpc())にのみ適用されます。
PostgreSQLのフィルタと修飾子について説明しています。フィルタは、行レベルで機能し、特定の条件に一致する行のみを返すことができます。修飾子は、フィルタの後に指定することができ、応答の形式を変更することができます。
↓省略
## Return data after inserting (挿入後のデータを返す)
## Order the results (結果を順番に並べる)
## Limit the number of rows returned (返される行数を制限する)
## Limit the query to a range (クエリーの範囲を限定する)
## Set an abort signal (アボートシグナルを設定する)
## Retrieve the query as one row (クエリーを1行で取得する)
## Retrieve the query as 0-1 rows (クエリーを0~1行で取得する)
## Retrieve the query as a CSV string (クエリをCSV文字列で取得する)
## Override type of successful response (成功したレスポンスの種類を上書きする)
↑省略
Auth
Create auth client (server-side)
import { createClient } from '@supabase/supabase-js'
const supabase = createClient(supabase_url, anon_key, {
auth: {
autoRefreshToken: false,
persistSession: false,
detectSessionInUrl: false
}
})
↓省略
## Overview (概要)
## Create a new user (ユーザーを新規に作成する)
## Sign in a user (ユーザーのサインイン)
## Sign in a user through OTP (OTPによるサインイン)
## Sign in a user through OAuth (OAuthによるサインイン)
## Sign in a user through SSO (SSOによるサインイン)
## Sign out a user (ユーザーからサインアウトする)
## Send a password reset request (パスワードリセットリクエストを送信する)
## Verify and log in through OTP (OTPによる認証とログイン)
## Retrieve a session (セッションを取得する)
## Retrieve a new session (新しいセッションを取得する)
## Retrieve a user (ユーザーを取得する)
## Update a user (ユーザーを更新する)
## Send a password reauthentication nonce (パスワード再認証用Nonceの送信)
## Resend an OTP (OTPの再送信)
## Set the session data (セッションデータを設定する)
## Listen to auth events (auth イベントを聞く)
## Exchange an auth code for a session (セッションのAuthコードを交換する)
## Auth MFA (Auth MFA)
## Auth Admin (管理者認証)
↑省略
ここより下は古い情報 2023年6月1日
ちょっと触ってみた所結構変わってるので・・・
Docker でのローカル開発環境の想定
まず、ローカル側で Supabase の開発環境を作り
そこでテストをして、その成果をリモートサーバーに送り開発を進めていく。
ローカル開発環境を構築するのに Docker 技術を使うが、Dockerfileの知識はほぼ必要なくコマンド一発でローカル開発環境の構築が出来る。
※注意点
Supabase は 2022 年 8 月に
supabase-js v2(Supabase クライアント)
supabase CLI v1 (Supabase コマンドラインインターフェース)
がメジャーバージョンアップを行い、少し破壊的変更が入っている。
2022 年 7 月以前の情報だとそのままでは動かないコマンドが少しある。
環境
Windows10
VScode
Git
Docker Desktop ※必須
https://www.docker.com/products/docker-desktop/
Supabase アカウント
https://app.supabase.com/
Supabase ローカル開発環境を構築
PC にローカル開発環境を構築するために Supabase CLI が必要になる。
Supabase CLI を使用すると
Supabase CLI
まず最初にSupabase CLIをローカル環境にインストールします。
Supabase CLIは2022年8月に Version1 に到達したのでそれ以前の Version とはコマンドが異なる場合があります。
Installing and Updating | Supabase
https://www.supabase.jp/docs/reference/cli/installing-and-updating
インストール
scoop bucket add supabase https://github.com/supabase/scoop-bucket.git
scoop install supabase
更新
scoop update supabase
※現在開発が活発に行われているので、更新は頻繁に行ったほうが良い
2022 年 9 月 4 日 ver 1.4
ドキュメント
日本語版(有志による翻訳)
ローカル開発環境 | Supabase
https://www.supabase.jp/docs/guides/local-development
英語版(最新の情報ならこちら)
Local Development | Supabase
https://supabase.com/docs/guides/cli/local-development
新しくディレクトリを作りそこで実行する
supabase login
mkdir [your-project]
cd [your-project]
git init
# プロジェクト初期化
supabase init
# 起動
supabase start
supabase login は 1 度だけで ok
supabase init を実行するとそのディレクトリ内に supabase のディレクトリができ、そのなかに設定ファイルやマイグレーションファイル、Seed ファイルなどが入る。
最初からやり直したいときは supabase ディレクトリを削除するだけでリセットできる。
同じ場所に Next.js などを置くと開発しやすい。
事前準備は色々といるが
supabase startコマンドこれ 1 つを実行するだけでローカル開発環境が立ち上がる。
次回からは
supabase start
supabase stop
の 2 つだけで立ち上げたり落とす事ができる。
ローカル開発環境での値
Supabase のローカル開発環境の値はどこで Docker を立ち上げても同じになります。
ローカル開発環境の
DB の名前とパスワード
API URL も DB URL も Studio URL も Inbucket URL も
anon key も service_role key も同じになります。
> supabase status
supabase local development setup is running.
API URL: http://localhost:54321
DB URL: postgresql://postgres:postgres@localhost:54322/postgres
Studio URL: http://localhost:54323
Inbucket URL: http://localhost:54324
anon key: ey***************Ts
service_role key: ey****************AcU
.env.localファイルについて
環境設定ファイルは沢山種類があるが、基本的に使うのはこのファイルだけ。
開発にあると便利な2つのサーバー
開発時にあると便利なサーバーを2つ用意する、ローカルのPC内のDockerから立ち上げるローカル開発環境と、
ネット上にあるSupabase から利用できるリモートサーバー
ローカル開発環境で開発をして、リモートサーバーを本番用とする。
.evn.localファイルを切り替えることでローカル開発環境内のDBでもリモートサーバーのDBでもどちらでも利用できる。
ローカル開発環境で環境変数を設定する場合、
.env.localファイルを作成する
(※つまづいて、時間を浪費した箇所)
.envファイルはつくらず、Vercelサーバーに環境変数を入力する場所があるのでそこに書き込む。
※Vercelサーバーを使う場合
Dashboard – Vercel
https://vercel.com/dashboard
# リモート開発環境利用時のDB用の環境変数
NEXT_PUBLIC_SUPABASE_URL=http://localhost:54321
NEXT_PUBLIC_SUPABASE_API_KEY=ey*****NHzTs
# リモートサーバー利用時のDB用の環境変数
# NEXT_PUBLIC_SUPABASE_URL=https://[project-ref].supabase.co
# NEXT_PUBLIC_SUPABASE_API_KEY=eyJh****nMw
解説
リモート開発環境のDB用の環境変数は固定、どこのDockerでも、立ち上げると同じ値になる。
罠
ここで時間を取られたので詳しく記録を残しておく。
NEXT_PUBLIC_SUPABASE_URL と NEXT_PUBLIC_SUPABASE_API_KEY は、
この2つの値はDBクライアントを動かすための値。
http://localhost:54323/project/default/api
このページの
API URL
http://supabase_kong_[ローカル開発環境のプロジェクト名]:8000
この値が罠だった。(どこかのサーバー上にデプロイした時に使うのかもしれないが)
実際にクライアントを作るためには、ローカル開発環境では supabase status で表示される API URL の方を使用する。
ローカル開発環境のAPIのIntroductionに書いてある API URL(右サイドバー)
http://localhost:54323/project/default/api
http://supabase_kong_[ローカル開発環境のプロジェクト名]:8000
リモートサーバーのAPIのIntroductionに書いてある API URL(右サイドバー)
https://app.supabase.com/project/[project-id]/api
https://[project-id].supabase.co
この2つのページは内容は同じだか、ローカル開発環境の API URL を使うと動かない、リモートサーバーの方を使うとクライアントでアクセスできる。
(クライアントは supabase-js で作る。)
マイグレーションファイルの作成
テーブルの作成
Supabase Studio
http://localhost:54323
テーブルを作ってみる
SQL Editor
create table employees (
id integer primary key generated always as identity,
name text
);
RUNボタンを押す
Table Editorでテーブルを確認する
テーブルにデータを入力する
supabase/seed.sql
insert into public.employees (name)
values
('Erlich Backman'),
('Richard Hendricks'),
('Monica Hall');
supabase db reset
マイグレーションファイルを作成する
supabase migration new test001
新しく作るのでこの中身は実質何も無し、
diffコマンドは
supabase db diff file001 -f file001
前回のマイグレーションファイルとの差分を出してくれる
マイグレーションやシードファイルに沿ってテーブルを元に直してくれる
supabase db reset
supabase コマンド reset stop
リセットする手段として
supabase db reset
supabase stop
基本的にこの2つがある
supabase db resetはマイグレーションファイルにそってテーブルを再構築してくれる。そして入力してあったデータは消えてしまう。
supabase stop
は Docker のコンテナ起動自体を停止させる。
再度
supabase start
コマンドで立ち上げると
マイグレーションファイルに沿ってテーブルを再構築してくれる。
実質的な違いはないがsupabase db resetの方がリセット作業時間が短くて済む。
テーブルの設定を保存しておきたい場合はマイグレーションのコマンドを実行する。
個人の実験だが
マイグレーションファイルを全部削除してから
supabase db reset
をするとテーブル設定が全て消える。
削除したマイグレーションファイルを復活させてから
supabase db reset
を実行するとテーブルは復活する。
しかしテーブルの中身のデータまでは復活しない。
中身のデータもsupabase db resetコマンド実行時に復活させるには
supabase/seed.sqlファイル
というファイルを作っておく必要がある。
設計情報の保存方法(マイグレーション)
データベースの変更は
すべて「マイグレーション」によって管理されます。
マイグレーションを実行すると今までのテーブル設計情報がファイルに保存できる。
データベースのマイグレーションとは、
時間の経過に伴うデータベースの変更を
追跡する方法です。
最初に
リモートサーバー側でプロジェクトを作った時に保存しておいたパスワード
Database Password [プロジェクト名]
このパスワードはプロジェクト作成時のみにしか表示されないのでメモを取っておく必要がある。
マイグレーションファイルの作成するための準備
※リモートとやり取りするためには必須。
ローカル開発環境で作り上げたものをリモートに反映させるために必要。
Supabase の情報にアクセスするための設定は
supabase link コマンドを使ってリモートサーバーとつなげる必要がある。
それにはsupabase linkにデータベースのパスワードとプロジェクト ID を入力する必要がある。
supabase link -p ************ --project-ref ********************
--project-ref はリモートサーバーの後ろの英文字列を使用する。
https://app.supabase.com/project/[project-id]
https://app.supabase.com/project/********************
※リモートサーバーのリンクに失敗する場合
>npx supabase link --project-ref [project-id]
Enter your database password:
Error: failed to connect to `host=db.[project-id].supabase.co user=postgres database=postgres`: dial error (dial tcp 127.0.0.1:6543: connectex: No connection could be made because the target machine actively refused it.)
Try rerunning the command with --debug to troubleshoot the error.
このようにエラーが出る、そんな時は
supabase CLIをインストールして、データベースパスワードも一緒に入力する。
supabase link --project-ref [project-id] --password [Database Password]
のように入力すると通ることがある。(n=1の解決方法)
リンクの設定が完了すると
今までのマイグレーションリストが表示できるようになる。
このリストコマンドはローカル開発環境とリモートサーバー両方のマイグレーションファイルのリストを表示してくれる。
マイグレーションのリスト
リスト表示
supabase migration list -p ************
マイグレーションのリストを表示するにのデータベースのパスワードが必要になる。
マイグレーションファイルの作成方法
初回
migration newコマンドを使用する
supabase migration new [マイグレーションファイルの接尾語]
例
supabase migration new test001
を実行すると
[タイムスタンプ]_[マイグレーションファイルの接尾語].sql
実行例
20220829182819_test001.sql
という形式でマイグレーションファイルが作成される。
2 回目以降
次回からは diff コマンドを使用して設計データの差分を取っていく。
supabase db diff -f file01
を実行すると
実行例
20220829183122_file01.sql
というマイグレーションファイルが作成される。
Supabase のブランチ
Usage | Supabase
https://supabase.com/docs/reference/cli/usage#supabase-db-branch
データベース設計に関しては Supabase はブランチを切ることが出来る。
ブランチを切るとは分岐点をつくり現在のルート(道)とは別の枝道(ブランチ)を新たに作るということだ。
ブランチは
supabase db branch
とコマンドを見ればわかるように
Supabase のデータベースだけのブランチ機能となっている。
現在 Web プログラマー必須の技術 git があるが、
その git のブランチと一緒だが、git ほど高性能ではない。
supabase db branch -h
とヘルプを覗くと
create Create a branch
delete Delete a branch
list List branches
switch Switch the active branch
と 4 つのコマンドだけ、
supabase db branch create
新しくブランチを作る。
supabase db branch delete
ブランチを削除する。
supabase db branch list
現在あるブランチのリストを表示する。
supabase db branch switch
ブランチ間の移動する。
typescript の型生成
Usage | Supabase
https://supabase.com/docs/reference/cli/usage#supabase-gen-types-typescript
typescript の型を作るコマンド
Supabase で作ったテーブルの型
ローカル開発環境
supabase gen types typescript --local
リモートサーバー
supabase gen types typescript --db-url [string]
実行例
export type Json =
| string
| number
| boolean
| null
| { [key: string]: Json }
| Json[];
export interface Database {
public: {
Tables: {
notices: {
Row: {
content: string | null;
user_id: string | null;
id: string;
created_at: string | null;
};
Insert: {
content?: string | null;
user_id?: string | null;
id?: string;
created_at?: string | null;
};
Update: {
content?: string | null;
user_id?: string | null;
id?: string;
created_at?: string | null;
};
};
todos: {
Row: {
title: string | null;
user_id: string | null;
id: string;
created_at: string | null;
};
Insert: {
title?: string | null;
user_id?: string | null;
id?: string;
created_at?: string | null;
};
Update: {
title?: string | null;
user_id?: string | null;
id?: string;
created_at?: string | null;
};
};
};
Functions: {};
};
}
その他の Supabase CLI コマンド
まだ未確認のコマンドは有るが、いまだ使い方がよくわからないコマンド群。
completion Generate the autocompletion script for the specified shell
functions Manage Supabase Edge functions
orgs Manage Supabase organizations
secrets Manage Supabase secrets
まだマニュアルを読んでいない、充実していないのでよくわからない。
Supabase リモートサーバー
Supabase | Supabase
https://app.supabase.com/
リモートサーバーでプロジェクトを作るのは
ググればたくさん出てくるので省略
デプロイ
ローカル開発環境で作ったDBのスキーマ情報をリモートサーバーへデプロイ(シンクロさせる方法)する。
ローカル開発環境とリモートサーバーをつなげる。
supabase link --project-ref <project-id>
supabase link --project-ref ********* -p ******
-pはリモートサーバーのデータベースパスワードのオプション
DROP
リモートサーバー側で色々とテーブルを作っていた場合それらを全てDROPしなければローカル開発環境のテーブル設定と衝突を起こしてしまうので、その場合はDROPコマンドを使ってテーブル設定をきれいにする必要がある。
リモートサーバー側のDB設定を全てDROPする。
DROP SCHEMA supabase_migrations CASCADE;
※初めての時だけで2回目以降は下記のPUSHコマンドだけでいける(はず)。
PUSH
ローカル開発環境のテーブル設定をリモートサーバー側に反映させる。
supabase db push -p ******
テーブルの大きさ、差分にもよるが、リモートサーバーに反映されるまで30秒ぐらいかかる
ローカルのテーブルで設定した値で、
テーブル設定情報のみリモートサーバーにコピーされる。
テーブルの中に書いた値はコピーされない。
Apollo staudio
Apolloスタジオから操作する
Explorer | Sandbox | Studio
https://studio.apollographql.com/sandbox/explorer
ApolloスタジオのSupabase設定を入力する
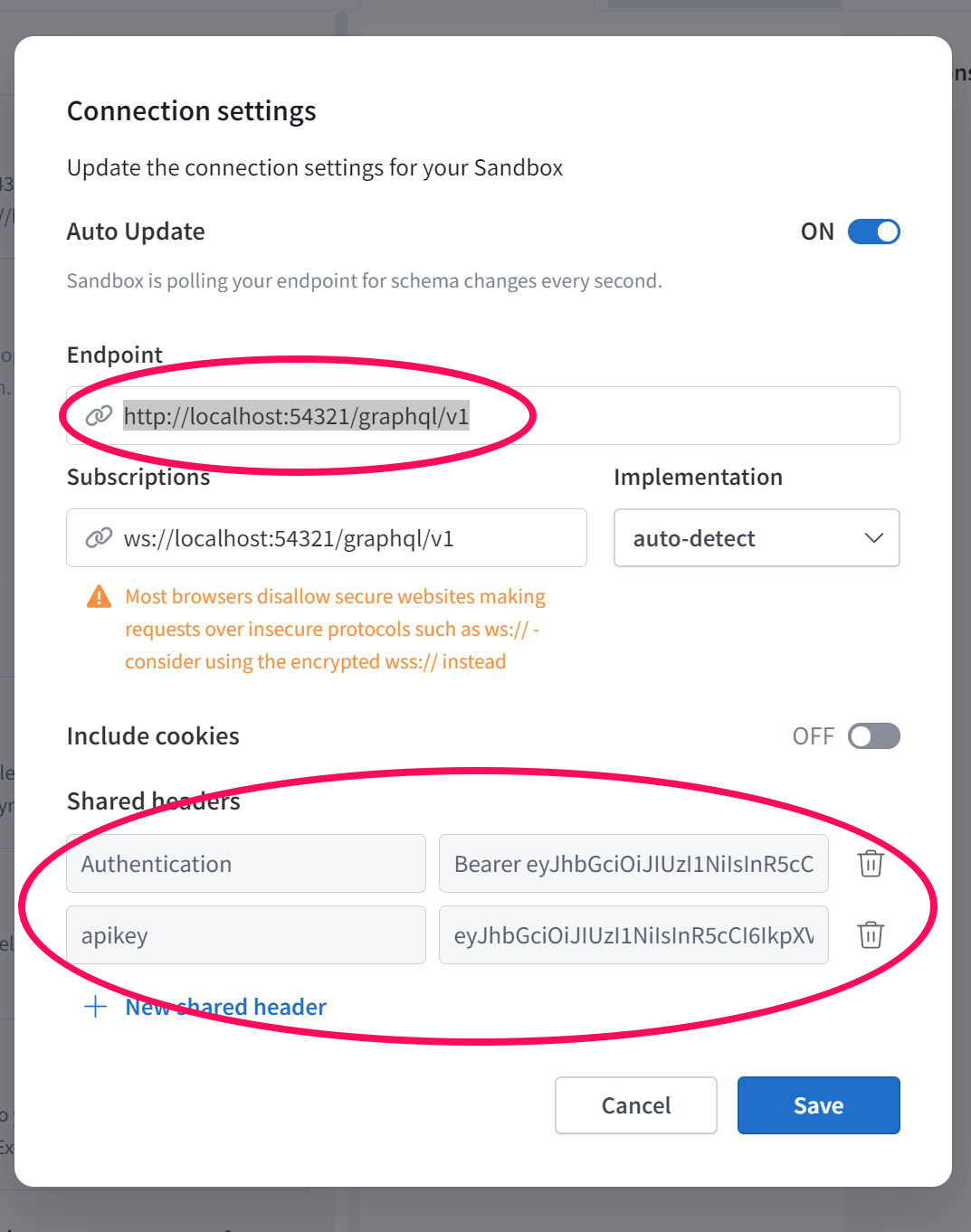
Endpoint
http://localhost:54321/graphql/v1
Authentication
Bearer eyJhbGciOiJIUzI1NiIs******************************************************************_4qj0ssLNHzTs
apikey
eyJ****************************************************************************************HzTs
入力したsaveボタンを押す
※ローカルの[anon key]はみんな同じ値になる。
※Authenticationは ”Bearer [anon key]”になる。
ローカルのkyeなど全ての情報はどこでビルドしても同じになる
リモートサーバーで作られる全てのkeyは隠さなければならない。
ローカルの情報
> supabase status
supabase local development setup is running.
API URL: http://localhost:54321
DB URL: postgresql://postgres:postgres@localhost:54322/postgres
Studio URL: http://localhost:54323
Inbucket URL: http://localhost:54324
anon key: eyJ**********************************************************s_4qj0ssLNHzTs
service_role key: eyJhbGci**********************************************************AhKpNLAcU
GraphQLを使ってみる
コマンドQueryを使ってみる
Operation
query Query {
employeesCollection {
edges {
node {
id
name
}
}
}
}
入力後 Queryボタンを押す。
コマンドMutationを使ってみる。
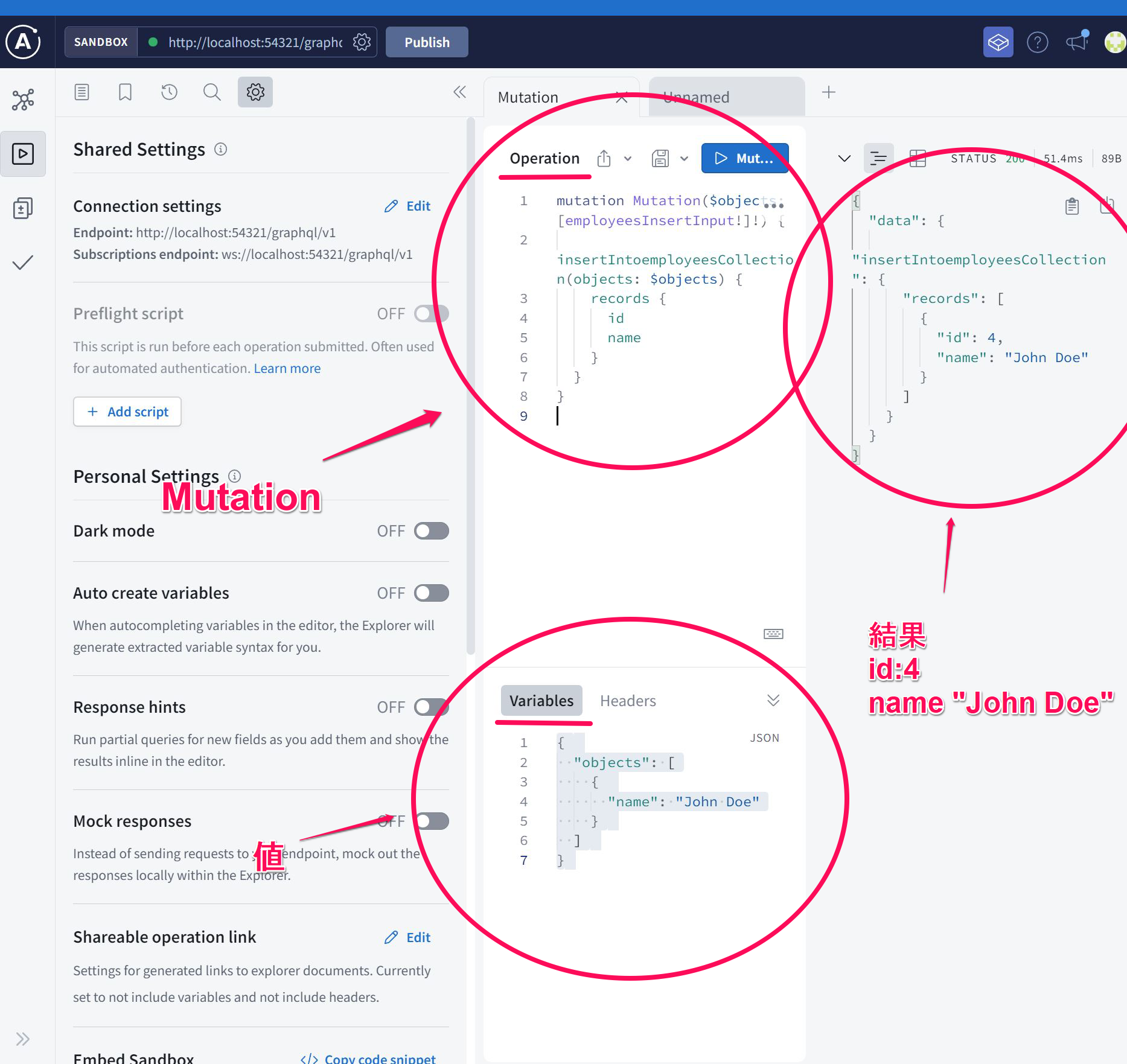
Operation
mutation Mutation($objects: [employeesInsertInput!]!) {
insertIntoemployeesCollection(objects: $objects) {
records {
id
name
}
}
}
Variables
{
"objects": [
{
"name": "John Doe"
}
]
}
入力後Mutationボタンを押す。
Mutationは
入力更新削除ができる
今回はidとnameの追加
idは自動的にインクリメンタル(IDの数値が自動増加)する。
nameは文字列を指定する。
GraphQL API
スキーマ再構築
API | Supabase
https://www.supabase.jp/docs/guides/api#graphql-api-1
SQLスキーマからGraphQLスキーマを
再構築するには、
select graphql.rebuild_schema();
を呼び出します。
SQLスキーマを変更した後は、
必ずGraphQLスキーマを再構築するようにしてください。
参考
GraphQL が Supabase で利用可能になりました
https://supabase.com/blog/graphql-now-available
create table "Account"(
"id" serial primary key,
"email" varchar(255) not null,
"createdAt" timestamp not null,
"updatedAt" timestamp not null
);
-- Rebuild the GraphQL Schema Cache
select graphql.rebuild_schema();
ローカル開発環境のやり直し
ローカル開発環境 は Docker のイメージからコンテナを作り、Supabase Studioで作ったテーブルなどの情報をボリュームに保存している。
コンテナはイメージからビルド(作り上げた)ものなで立ち上げるごとにリセットされる。
なので、テーブルなどを作ってもリセットコマンド(supabase db reset)で破棄される。
テーブル情報を保存するにはマイグレーションファイルを作る。
ローカル開発環境でテーブルなどを作った差分を消さずに保存しておきたい場合は、Docker のボリュームに記録されている。
この Supabase は自動でボリュームに保存される設定になっている。
supabase 停止&コンテナ削除
手順
Supabase を止める
supabase stop
Docker のすべてのコンテナを停止する
docker stop $(docker ps -q)
Docker のすべてのコンテナを削除する
docker rm $(docker ps -q -a)
Docker のすべてのボリュームを削除する
docker volume prune
イメージは DockerHub からダウンロードするだけで復活可能、コンテナはイメージから作るのでこれも復活可能。
ボリュームを削除すると今までの作業が全て消えます。
(マイグレーションファイルなどが残っていれば DB 設計部分は復活するかも知れませんが、未確認。)
イメージの一覧表示
docker images -a
Docker のすべてのイメージを削除する。
docker rmi $(docker images -q)
イメージはタグが複数ついていると一括して削除できないので 1 つづつ削除していく。
個別イメージの削除
docker rmi イメージId
Supabase を開始する。
supabase start
このコマンドは Docker イメージがローカルに保存されていなければDocker Hubに自動で取りに行く。
Docker Hubとは Docker イメージの公式保管場所
現在の設定を表示
supabase status
pgAdmin 4 (DBクライアント)
pgAdmin 4 Download
pgAdmin 4 インストール
pgAdmin 4 自体のインストール方法はネット上にたくさんあるので省略。
pgAdmin 4 は初めて起動するとき
マスターパスワードを必ず設定する必要がある。
これは Supabase とは関係なく、Pgadmin4 専用の設定。
マスターパスワードを設定する。
pgAdmin 4からSupabase への接続情報を取得する
supabase start
で起動させておく
このコマンドを実行すると
> supabase start
Started supabase local development setup.
API URL: http://localhost:54321
DB URL: postgresql://postgres:postgres@localhost:54322/postgres
Studio URL: http://localhost:54323
Inbucket URL: http://localhost:54324
anon key: eyJh**********************************************************ssLNHzTs
service_role key: eyJh**********************************************************AhKpNLAcU
※Supabaseでのローカル開発環境のsupabase statusで出力される情報はどのDockerビルドでも同じになる。
この情報は Docker から supabase が立ち上がっているなら
supabase status
で再度表示可能。
上記情報の解説
API URL は Web サービスを使用するユーザーがブラウザから Supabase にアクセスする時の出入り口。
DB URL は postgresql クライアントから Supabase に入る時の設定
DBクライアントの接続設定
ローカル開発環境への接続設定
設定方法は
pgAdmin 4 はサーバーグループというグループの下に
各サーバーを管理していく。
サーバーグループはデフォルトのまま使用する。
サーバーグループの上で右クリック
作成>サーバーを選択する
そうすると設定入力画面が出てくるので
2 行目のタブの一般
名称を適当に入力する。
2 行目のタブの接続
下記の通り入力する
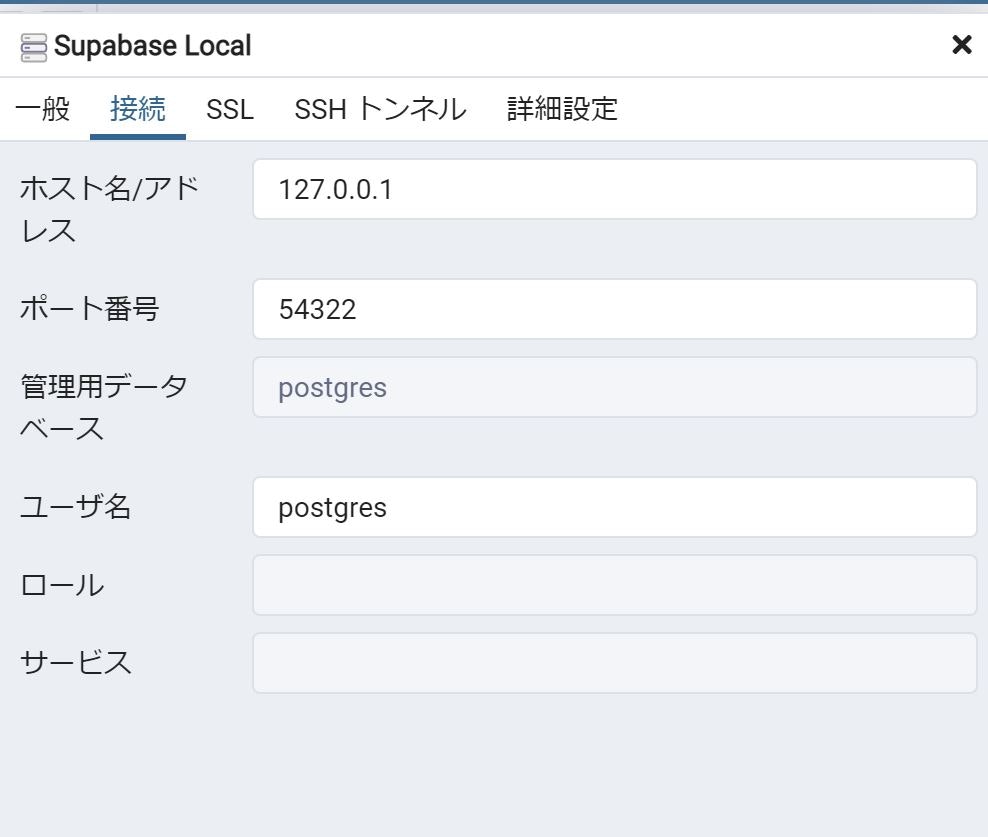
デフォルトではユーザー名、パスワード共に
postgres
になっている。
画面通りに入力したら
右下の保存ボタンをクリック。
接続が成功すると
と、いろいろ情報が見れるようになる。
リモートサーバーへの接続設定
つづいてリモートサーバーの設定を行います。
サーバーグループの上で右クリックをして
作成>サーバー
を選択。
2行目のタブの一般で
名称を入力
2行目のタブの接続で
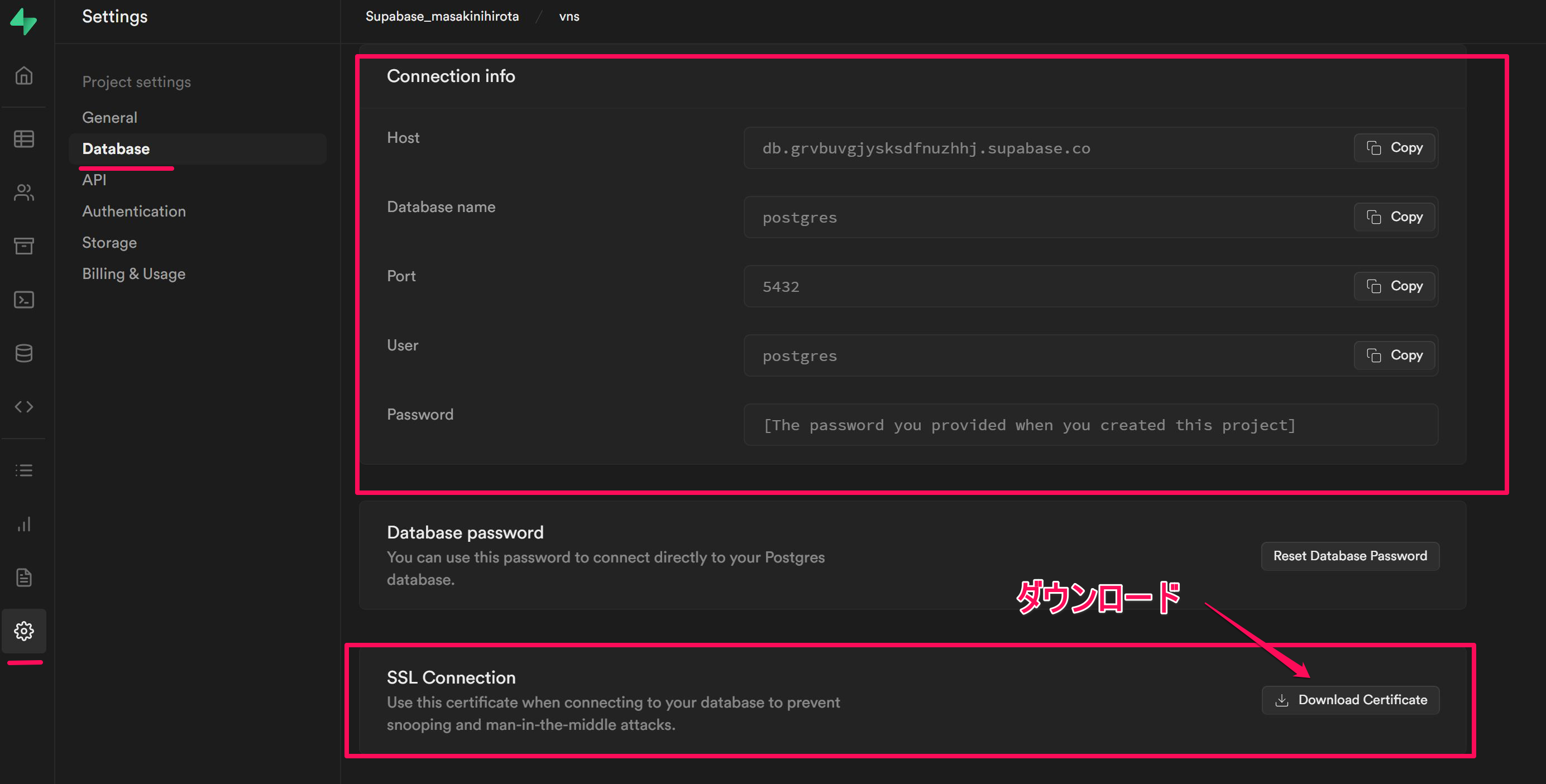
上記の通り下記に記入する。
SSL Connection の Download Certificate ダウンロードボタンを押して、ファイルを保存する。
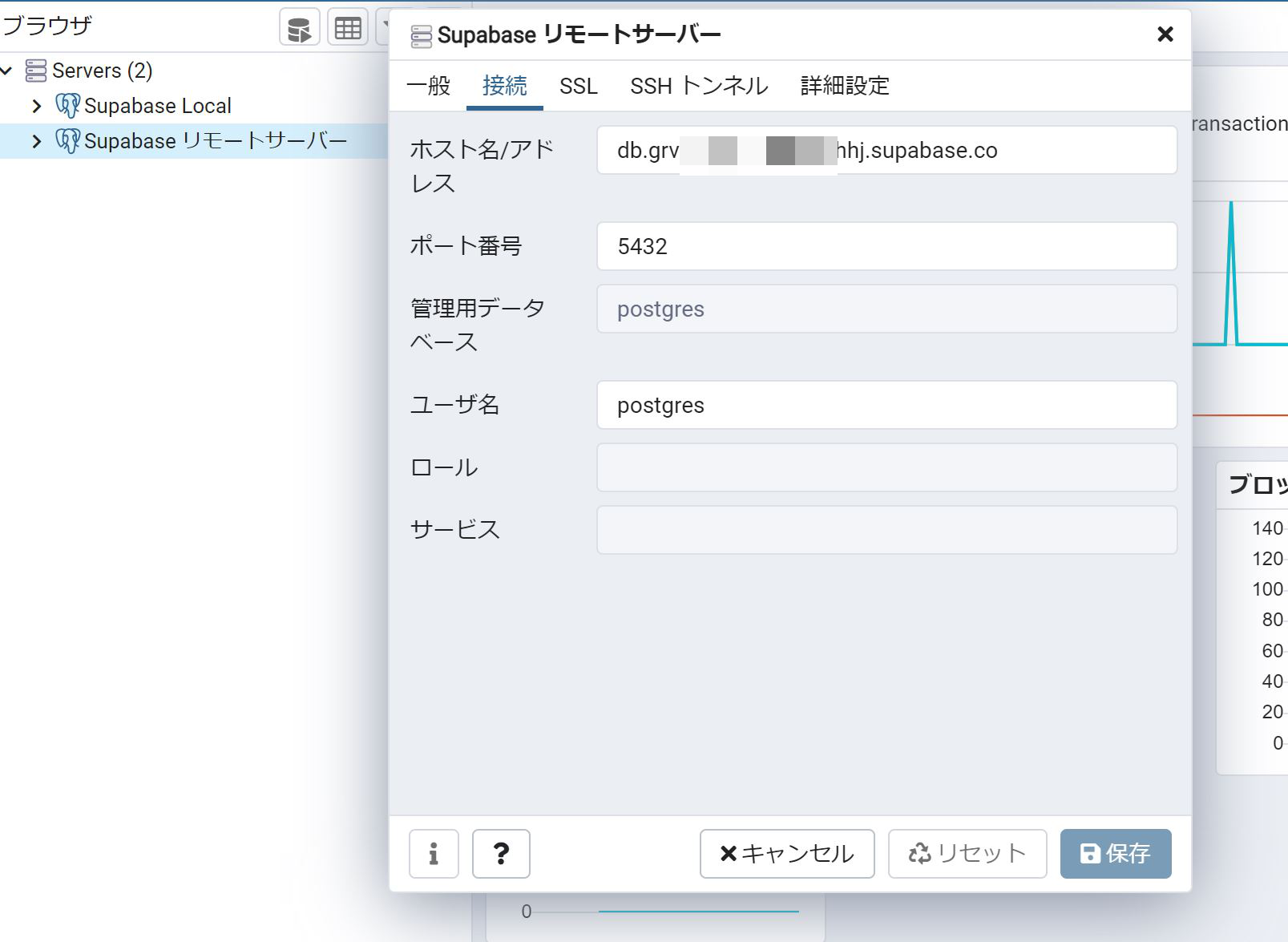
2行目のタブの SSL で
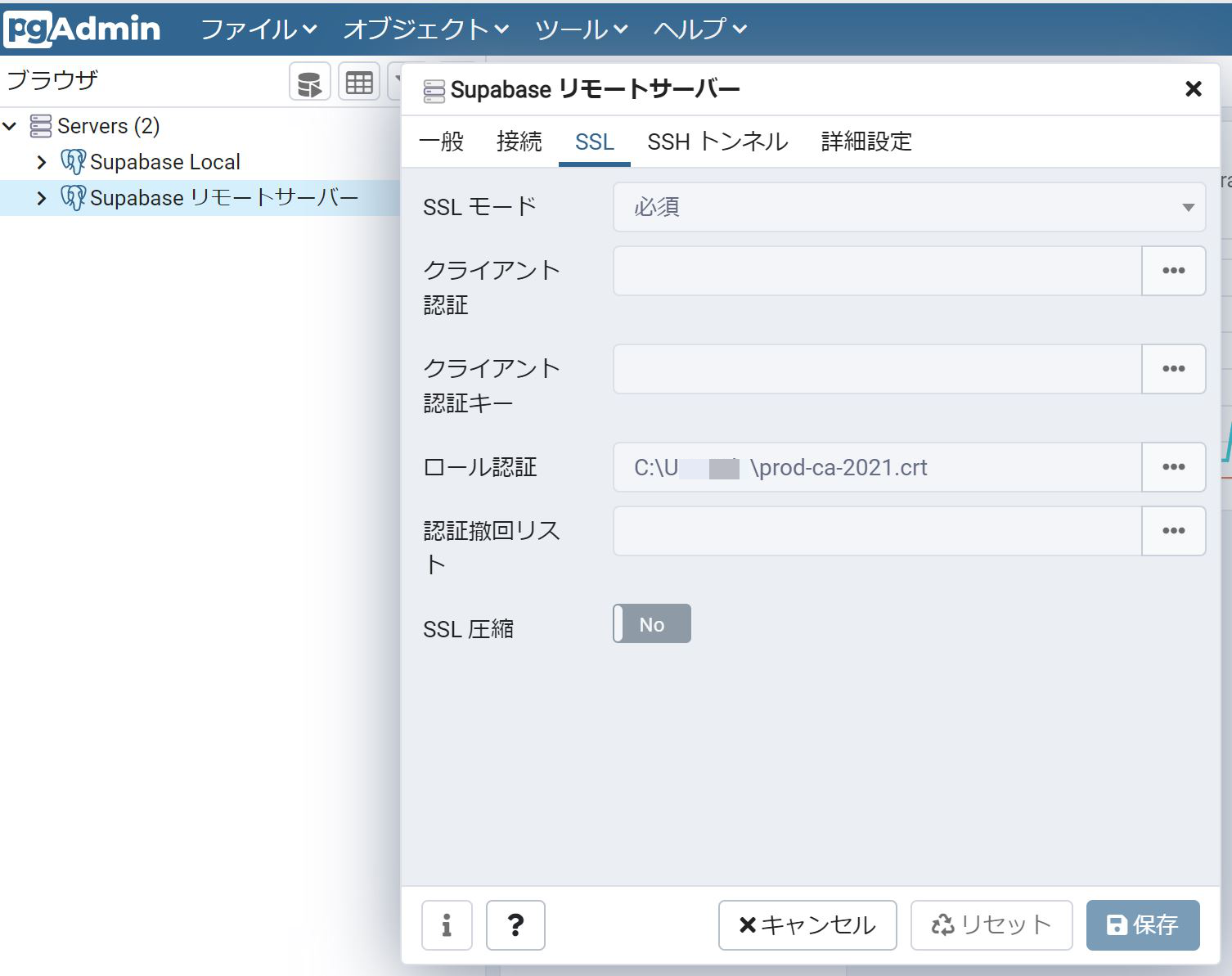
SSL モードを必須にする。
ロール認証にダウンロードしたファイルを指定する。
保存ボタンを押して成功すると、リモートサーバーの情報が色々と見れるようになる。
DBeaver (DBクライアント)
pgAdmin 4 ではER図を見る機能がついてなかったので、DBeaverを使用することにしました。
DBeaverの接続方法は、
Supabaseのローカルへの接続設定
ターミナルから
supabase statusで情報が得られる。
> supabase status
supabase local development setup is running.
API URL: http://localhost:54321
DB URL: postgresql://postgres:postgres@localhost:54322/postgres
Studio URL: http://localhost:54323
Inbucket URL: http://localhost:54324
JWT secret: super-secret-jwt-token-with-at-least-32-characters-long
anon key: eyJhb*********************************************************************************************************************_I0
service_role key: eyJhb*************************************************************************************************************1IU
トップバー
データベース(D)>新しい接続
PostgreSQLのアイコンを選択
Port: 54322
パスワード: postgres
この2つの項目を入力後、テスト接続で接続できるか試します。
成功すれば反応が返ってきます。
Supabaseのサーバーへの接続設定
Host: 「**********************」 Port: 54322
ユーザー名 postgres
パスワード 「**************」
これで左下にある接続テストボタンを押して接続が成功するかどうかを確認します。
ER図の確認方法
データベース>postgres>スキーマ
スキーマを選ぶ
今回の場合はpublicスキーマを選択
テーブル>テーブル名
ここで右側の領域に移って
ER図タブを選択する
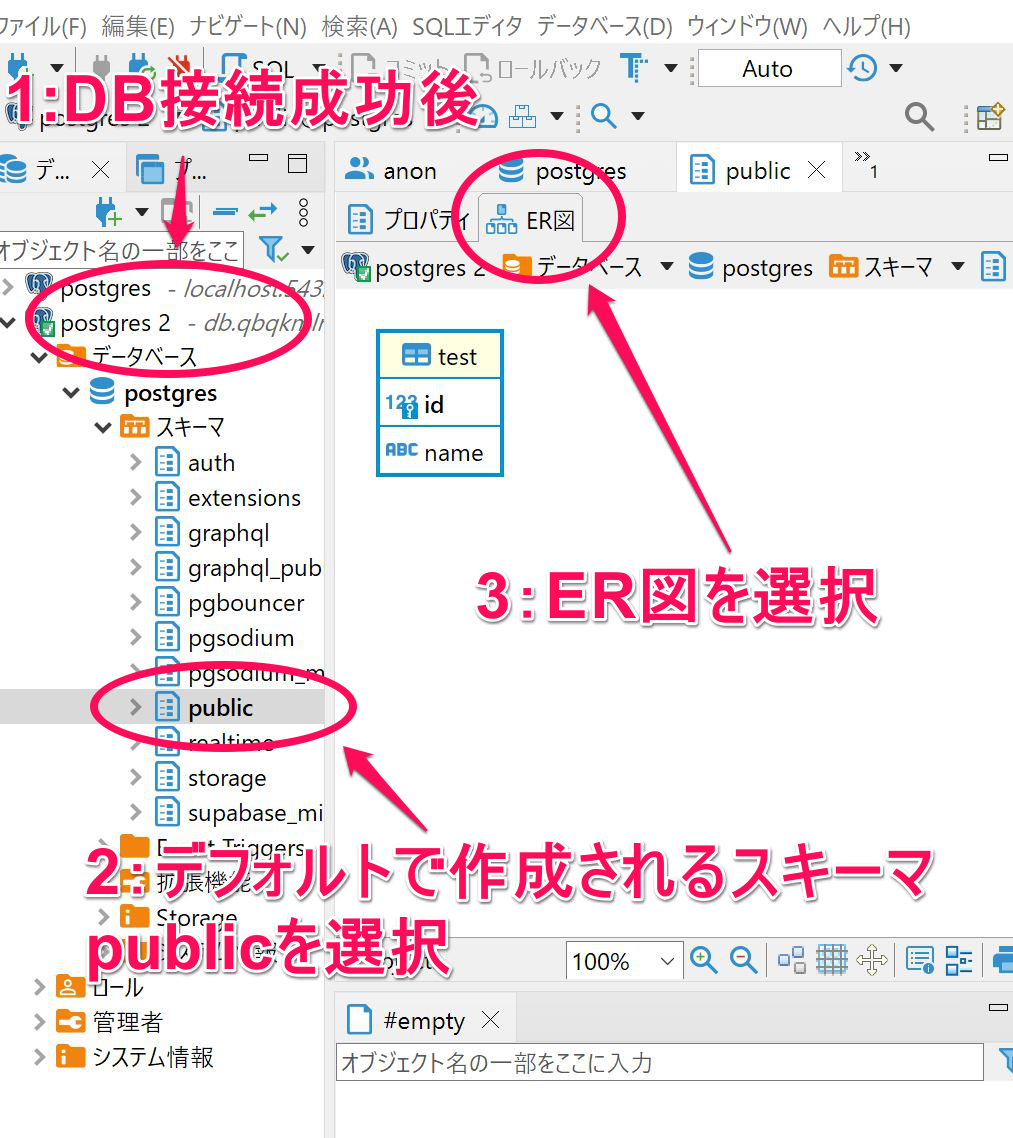
スキーマはデータベースに作成されるテーブルや関数といったオブジェクトをグループ化するものです。
postgresqlではデータベースを作成すると自動的にpublicと呼ばれる特別なスキーマが作成されます。
バグ
Getting error "relation "pgsodium.key_key_id_seq" does not exist (SQLSTATE 42P01)" when using "db remote commit" · Issue #8616 · supabase/supabase
https://github.com/supabase/supabase/issues/8616
Docker で Supabase を「初めて」立ち上げた後、
supabase init
supabase start
supabase link --project ...
# supabase db remote commit (<<非推奨になりました。)
supabase db pull
supabase db reset
をするとエラーが出て立ち上がらなくなります。
↓このコマンドは非推奨になりました。
supabase db remote commit
↓このコマンドを利用してください。
supabase db pull
マイグレーションファイルを削除するとエラーは解消されます。
supabase/migrations の下に、
202208260*****1_remote_commit.sql
マイグレーションファイルが出来ているので、このファイルを削除します。
注意点
現時点でローカルで開発してリモートにシンクロさせようとすると色々とエラーがでる
supabaseコマンドでPUSHする時
素直にリモートサーバー側だけで開発するか、
リモートサーバーとローカル開発環境をシンクロさせるのはそれぞれ手動で設定するのが良いようだ。
具体的には、リモートサーバー or ローカル開発環境でマイグレーションファイルを作成して、
そのマイグレーションファイルの中身は単なる SQL 文なので、
反対側の Supabase ダッシュボード上の SQL Editor に貼り付ければいい。
現状:ローカル開発環境上での開発は諦めて、リモートサーバーのみで練習、調査、開発中
用語
リモートサーバー
オンライン上の Supabase を指す
具体的には
https://app.supabase.com/
から入る Supabase の事。
ローカル
自分の PC の事。
ローカル開発環境で自分の PC 内で立ち上げた Docker の Supabase を指す。
ローカル開発環境
Docker でつくるローカル開発環境
具体的には自 PC 内に立ち上げた Docker 上で動作する Supabase の事を指す。
Studio URL: http://localhost:54323
で色々と設定していく。
クライアント
DB 用語でクライアントというとその DB の出入り口に該当するプログラムの事、クライアントを使用して DB にアクセスしてデータの入力、出力、更新、削除等を行う。
DB接続のためのクライアントなのでDBクライアントと呼ぶことも。
DB
データベースの頭文字
pgAdmin 4
ながーい歴史を持つ安定した DBクライアント
DBeaver
モダン(現代的)な DB 接続用クライアント
現代的な GUI 操作ができるようになっている。
GUI
マウスなどで操作可能な方法
直感的操作が可能
CLI もしくは CUI
コマンドを直接打って、命令をおくる方法。
直截的操作が可能
GraphQL
REST の欠点を改良するために作られた通信規格
REST は入力更新削除などの入出力をそれぞれ作る必要があったが
GraphQL では入出力は1箇所で済むようになった
REST は入出力をそれぞれ作るので通信ごとに独自の入出力ができ複雑になったが
GraphQL は Query、Mutation ごとに設計できるようになった。
プロジェクト ID
プロジェクトにアクセスする時に使うユニークな文字列
https://app.supabase.com/project/[project-id]
キーの種類
基本的に2つだけ。
anon key と service_role key
ドキュメントには色々な KEY 用語があるが、表記が揺れているだけでです。
key は supabase status で表示される
anon key
anon key
SUPABASE_KEY
SUPABASE_ANON_KEY
SUPABASE_CLIENT_API_KEY
NEXT_PUBLIC_SUPABASE_ANON_KEY
NEXT_PUBLIC_SUPABASE_API_KEY
これらはすべてanon keyの事だと思っていい。
service_role key
service_role key
SERVICE_KEY
SUPABASE_SERVICE_KEY
これらはすべて service_role key の事だと思っていい。
Vercel github
githubにリポジトリを作り
Vercelでgithubのリポジトリを登録
Vercelで.envに記入するべきデータを登録
環境変数
リモートサーバーのURLとkeyの登録
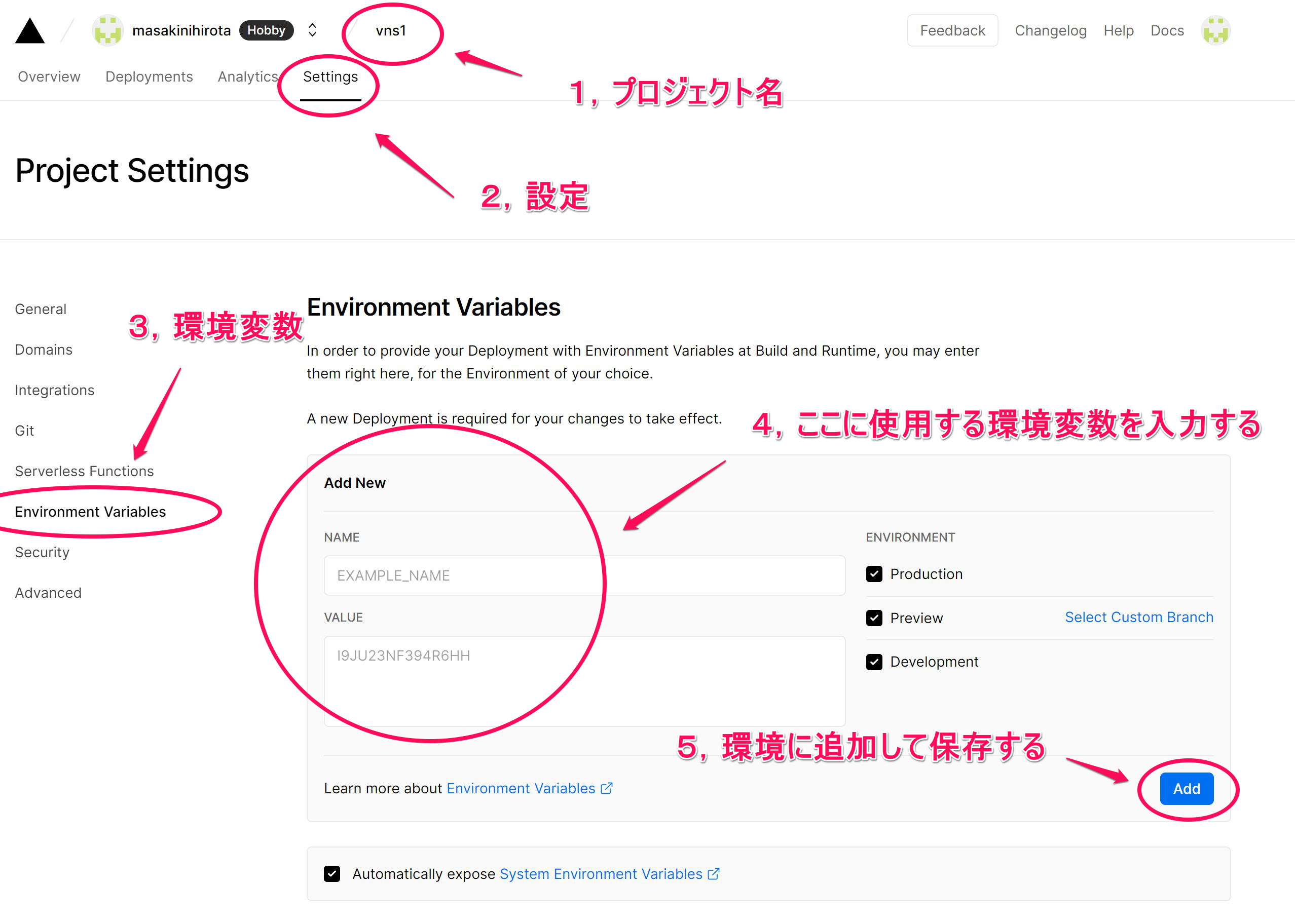
# リモートサーバー利用時のDB用の環境変数
# NEXT_PUBLIC_SUPABASE_URL=https://[project-ref].supabase.co
# NEXT_PUBLIC_SUPABASE_API_KEY=eyJh*****************************************************************************nMw
| NAME | VALUE |
|---|---|
| NEXT_PUBLIC_SUPABASE_URL | https://[project-ref].supabase.co |
| NEXT_PUBLIC_SUPABASE_API_KEY | eyJh*****************************************************************************nMw |
4番のAdd Newの箇所に入力する。
Vercel | Supabase
https://www.supabase.jp/docs/guides/integrations/vercel
VercelとSupabaseの統合
Vercelの環境変数をローカルにコピーする
npx vercel login
npx vercel link
npx vercel env pull
以下、TODO
Next.js
Storybook
TEST
書いている途中でもどんどん新しい技術がでてくるのでとても追いつけません。
Web開発は楽しいですが、その分野は広範囲にわたります。 特に独学では効率が悪く、限界があることが多いです。 もう個人でできる範囲を超えているため、グループ開発を行うための環境を整えたいですね。