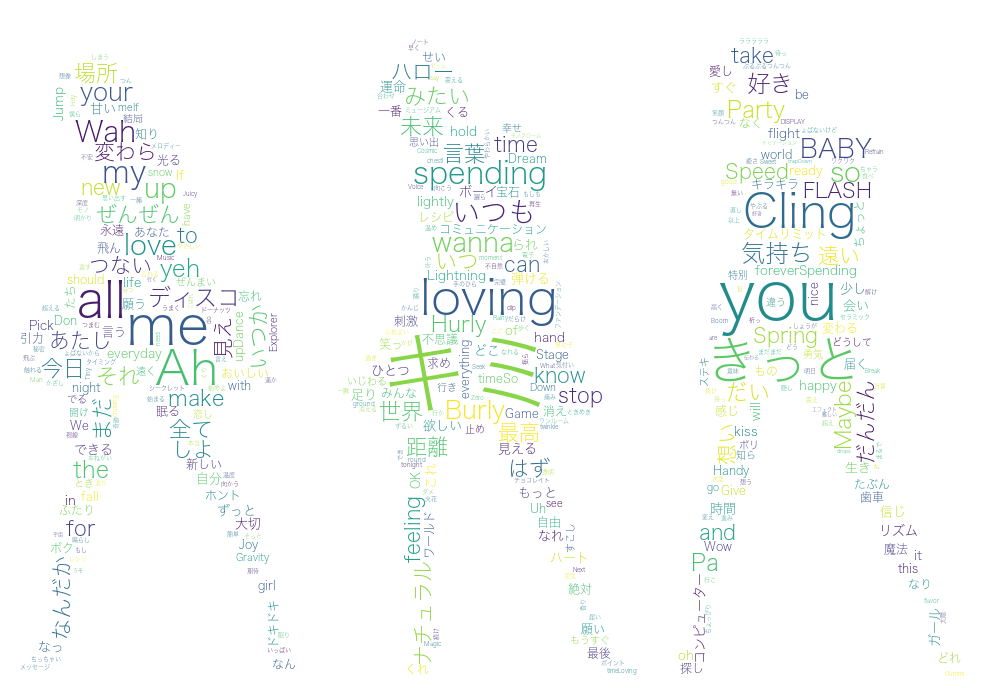
この記事はestie Advent Calendar 2019の6日目の記事となります。
不動産ベンチャーestie.incでエンジニアやっています、まるしょうです。
はじめに
最近、こちらの記事が話題になっていましたね!
【Python】嵐の歌詞をWordCloudで可視化して、結成20年でファンに伝えたかったことを紐解いてみた
自分の好きなアイドルやアーティストが長年活躍して愛されていると、本当に嬉しい気持ちになりますよね。
ファンとして改めて彼らの言葉や、伝えたかったことを確かめたくなる気持ちがめっちゃわかります。
ところで、偶然にも同じく結成20周年を迎えたアーティストがいるんですよ
そうですみんな大好きPerfumeです。
ご存知の通りPerfumeはテクノロジーとの親和性が高く、Googleの機械学習を使ったライブ演出や5Gでのライブ配信してたりと、最先端の表現を発信し続けています。
Rhizomatiksさまさまですね。
ということで、自分も10年ほどPerfumeのライブに通っているファンの一人として
Perfumeの歌詞を形態素解析+WordCloud可視化をやってみようと思います。
環境
- MacOS Mojave
- Python3.8
やり方
先人達と同じく
歌詞の取得→形態素解析→WordCloud
でやっていきます。
詳しくは参考サイトをご覧ください
形態素解析ツール
あまりテキストマイニングをやったことがないので、形態素解析といったらMeCabと思っていたのですが、
調べてみるといろいろな形態素解析ツールがあるみたいです。
今回はその中から
こちらの3人組を試してみたいと思います。
MeCab
現Google日本語入力開発者の方が開発した定番の形態素解析ツールです。
環境を選ばず動作しますが、解析には別途辞書が必要です。
今回は公式に推奨されているIPA辞書+新語辞書を使いました
import MeCab
# 歌詞ファイルの読み込み
text_data = open("perfume.txt", "rb").read()
text = text_data.decode('utf-8')
# 形態素解析
mecab = MeCab.Tagger("-ochasen")
node = mecab.parseToNode(text)
perfume_list = []
tags = ["名詞","動詞", "副詞", "形容詞", "形容動詞"]
while node:
#単語の抽出
word = node.surface
#品詞の抽出
word_class = node.feature.split(",")[0]
#特定の品詞のみ抽出
if word_class in tags:
perfume_list.append(word)
node = node.next
print(perfume_list)
Janome
こちらもMeCabに次いでよく使われる解析ツールです。
MeCabより実行速度が劣りますが、辞書内包・依存ライブラリが少なく
pip install janome
のみでインストールが終わる手軽さが魅力です。
MeCabの前段の検証で用いられることが多いようです。
from janome.tokenizer import Tokenizer
# 歌詞ファイルの読み込み
text_data = open("perfume.txt", "rb").read()
text = text_data.decode('utf-8')
# 形態素解析
t = Tokenizer()
seps = t.tokenize(text)
perfume_list = []
tags = ["名詞","動詞", "副詞", "形容詞", "形容動詞"]
for _ in seps:
#単語の抽出
if _.base_form == '*':
word = _.surface
else:
word = _.base_form
#品詞の抽出
ps = _.part_of_speech
word_class = ps.split(',')[0]
#特定の品詞のみ抽出
if word_class in tags:
perfume_list.append(word)
print(perfume_list)
Nagisa
こちらは比較的新しいツールです。Janomeと同様に環境構築が手軽で
pip install nagisa
でインストール完了です。
今回は歌詞なので活かせませんが、顔文字やURLに対して頑健な解析ができるようです。
品詞による出力単語のフィルタリングメソッドがあるので簡単に抽出できます。
import nagisa
# 歌詞ファイルの読み込み
text_data = open("perfume.txt", "rb").read()
text = text_data.decode('utf-8')
# 形態素解析・品詞を指定して単語抽出
tags = ["名詞","動詞", "副詞", "形容詞", "形容動詞"]
perfume_list = nagisa.extract(text, extract_postags=tags).words
print(perfume_list)
結果
-
Mecab

-
Janome

-
Nagisa

同じ辞書を使っているMecabとJanomeは似たような結果になりましたね
おわりに
Pa Pa きっと今日もキミをloving youな気持ち ディスコディスコってところでしょうか
曲名を繰り返す楽曲も多数あるので、その影響も反映されてますね!
テキストマイニングのツールも豊富で手軽なものが増え、気軽にこのような視覚化ができるのは嬉しいです
みなさんもお好きなアーティストで試してみてはいかがでしょうか
ところで、現在私がジョインしているestieではオフィスデータを可視化することで
さまざまな不動産xテクノロジーのサービスを提供しています。
オフィス移転をお考えの方は、ぜひestieをご利用ください!
ほかにも不動産データ基盤estie proも提供してます
またestieではWebエンジニアを募集しています
Wantedly
お気軽にオフィスに遊びに来てくださいね!