はじめに
Splunk DLTKのサンプルコードを実行しながら、仕組みを理解してみたいと思います。
今回は、NVIDIA社が提供しているRapidsというライブラリにある UMAP という次元削減法を使い、大量のデータを次元削減後に可視化してみたいと思います。
(注意) 今回のサンプルコード実行には、GPU環境が必須になります。
UMAPとは?
最新の次元削減法とのことです。他のPCA,t-SNEなどの手法と比べ高速に処理ができるというのもポイントらしいです。
こちらを参考にさせていただきました。
https://qiita.com/cheerfularge/items/27a55ebde4a671880666
Rapidsとは?
NVIDIAが提供しているオープンソースなGPUアクセラレーションプラットフォーム。以前CUDAを使ったサンプルコードを紹介しましたが、このRapidsはそのCUDA上で動作して、様々なライブラリー群やAPIが利用できます。
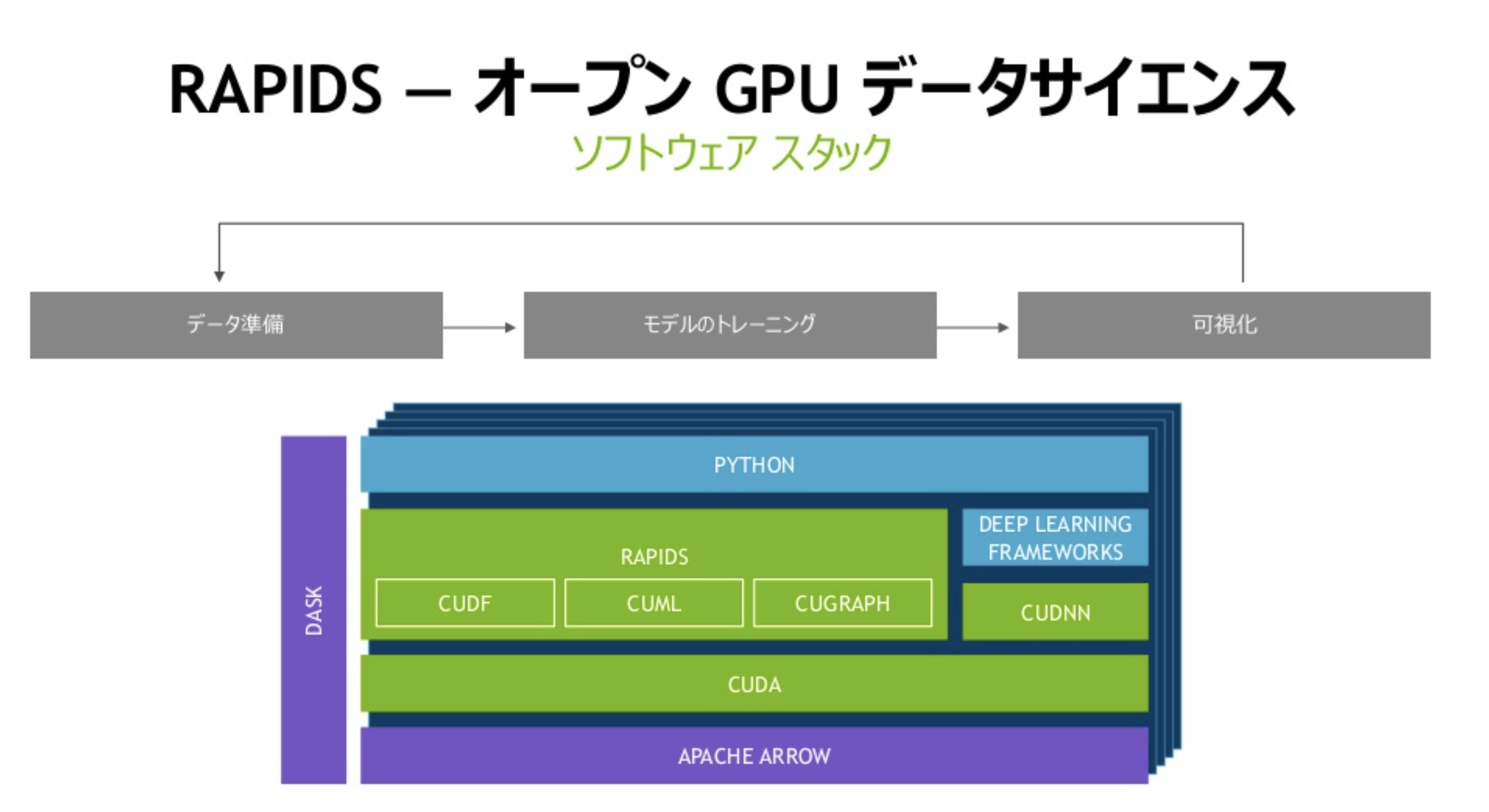
図:https://www.slideshare.net/NVIDIAJapan/rapids-120510206
事前準備
Rapidsは、デフォルトのGoldenイメージには入っていないので、新規に Rapidsのコンテナを立ち上げる必要があります。
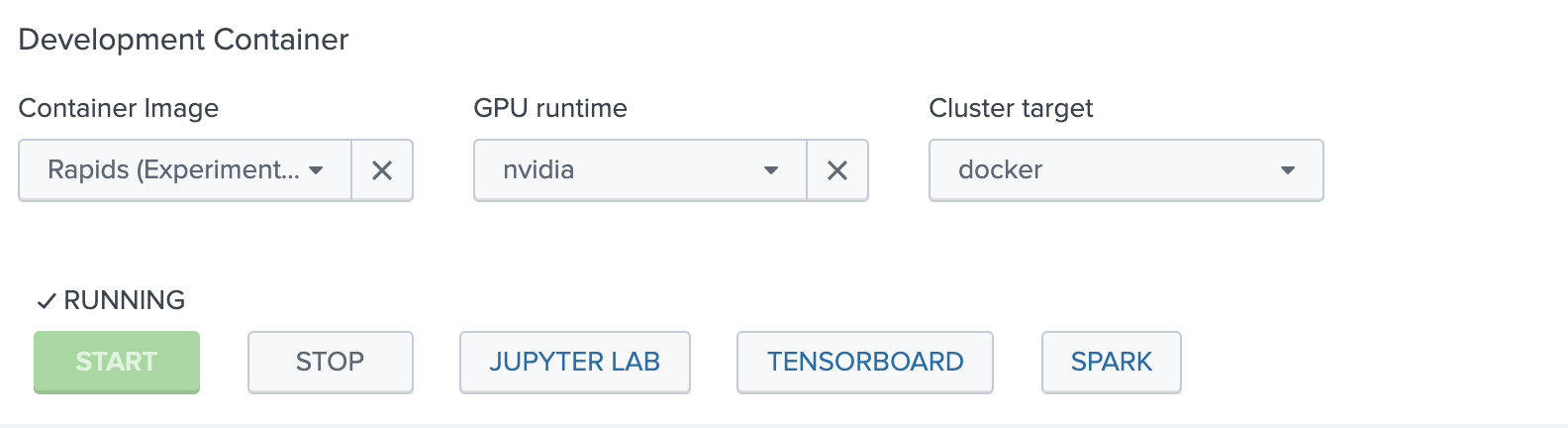
またRAPIDSを使う上で GPUは必須になります。GPU環境のセットアップについてはこちらのBlogをご覧ください。
https://www.splunk.com/en_us/blog/tips-and-tricks/splunk-with-the-power-of-deep-learning-analytics-and-gpu-acceleration.html
また今回は、サンプルデータとして、DGA Appに含まれるデータを利用しますので、こちらのAppも事前にインストールしておいてください。
https://splunkbase.splunk.com/app/3559/
DLTKのセットアップや使い方についてはこちらをご覧ください。
https://qiita.com/maroon/items/5a8b027631a674d6d8be
サンプルコードを確認
それでは DLTKに含まれる rapids_umap_dga.ipynb をみていきたいと思います。
最初はライブラリーのインポートです。cudfと UMAPが読み込まれてますね。
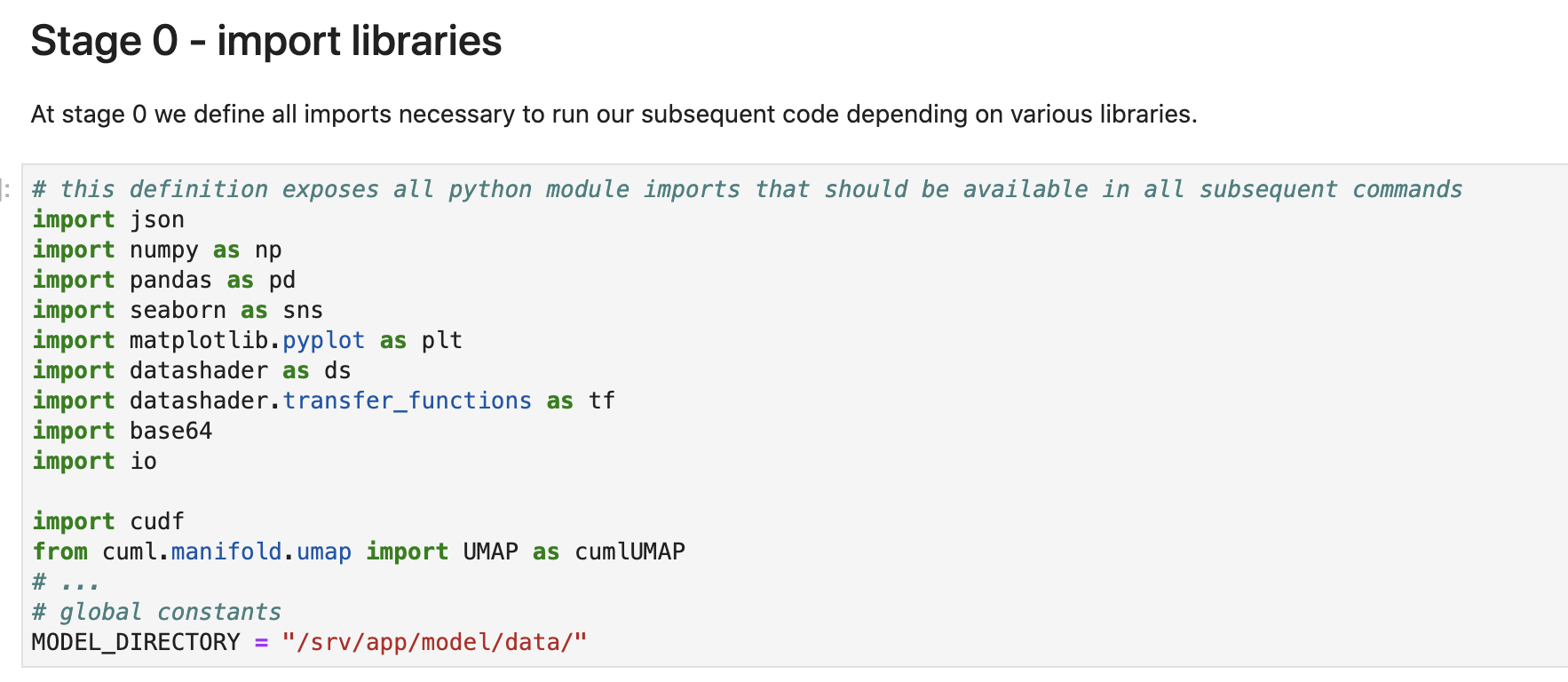
Stage1: データ取得
次にデータ取得です。Splunkからデータを加工して保存したものを読み込みます。
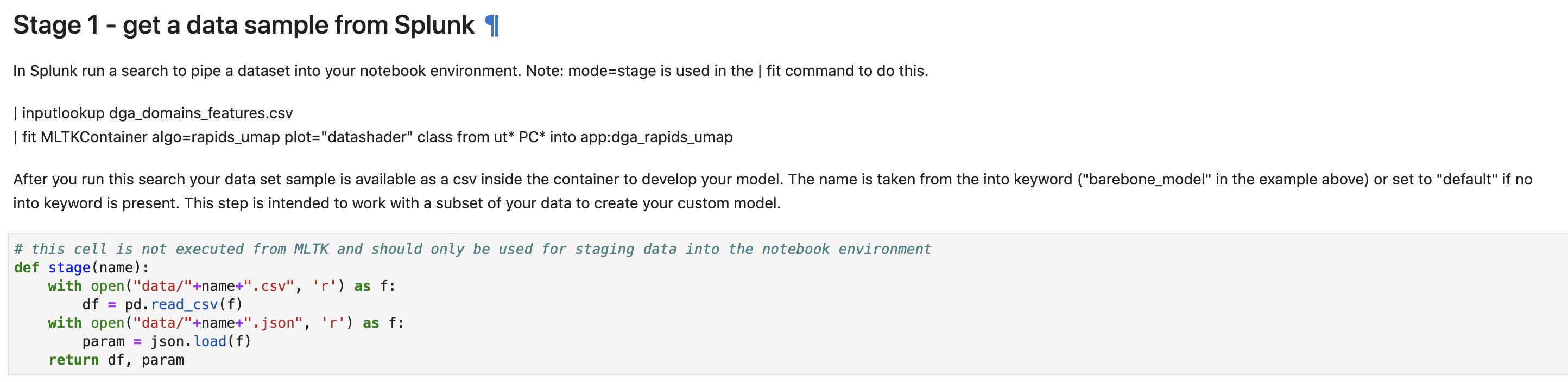
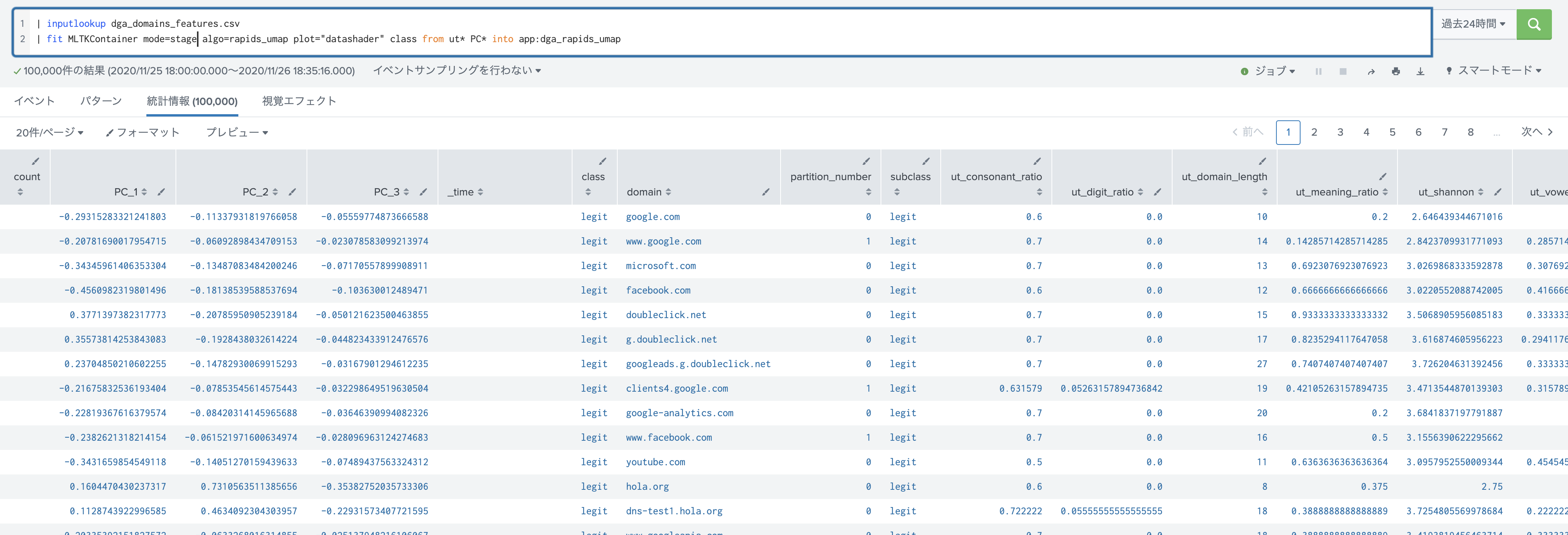
Splunk側での実行は以下の通りです。(サンプルコードにはmode=stageが抜けているので注意)
こちらのデータセットを利用するために、予め DGA Appを追加しておく必要があります。今回は10万件のデータを利用しております。
| inputlookup dga_domains_features.csv
| fit MLTKContainer mode=stage algo=rapids_umap plot="datashader" class from ut* PC* into app:dga_rapids_umap
Stage2 & Stage3: 初期化 & 学習
Stage2,3 の関数では、特に何もしていないため、紹介はスキップします。
Stage4: 適用(apply)
今回の目玉の箇所です。少し長いので前半のplotしている箇所と、後半のapply箇所で分けたいと思います。
最初に3つほどある関数定義は、matplotlibやseabornによるグラフ作成とpngとして保存する関数定義になります。
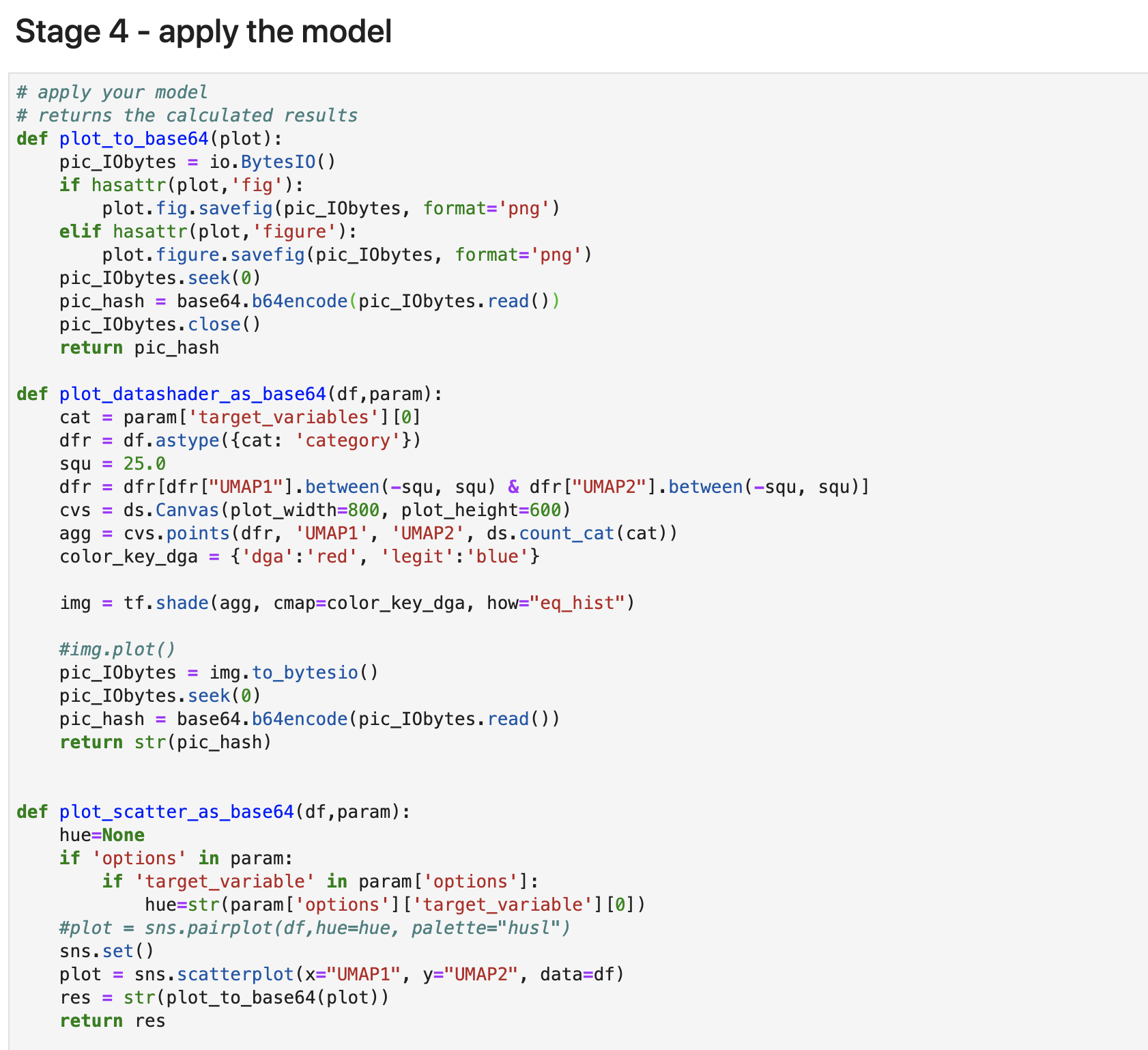
次の関数定義は、applyになります。GPUで扱うため、Rapidsのライブラリーを使ってデータをGPU上に呼び込み、umapを使って計算し、DataFrameに変換してからリターンします。

サンプルダッシュボード
上記を一通り実行したら、DLTKのサンプルダッシュボードを見てましょう。
「Sample」-[Data Mining] - [Rapids UMAP on DGA]
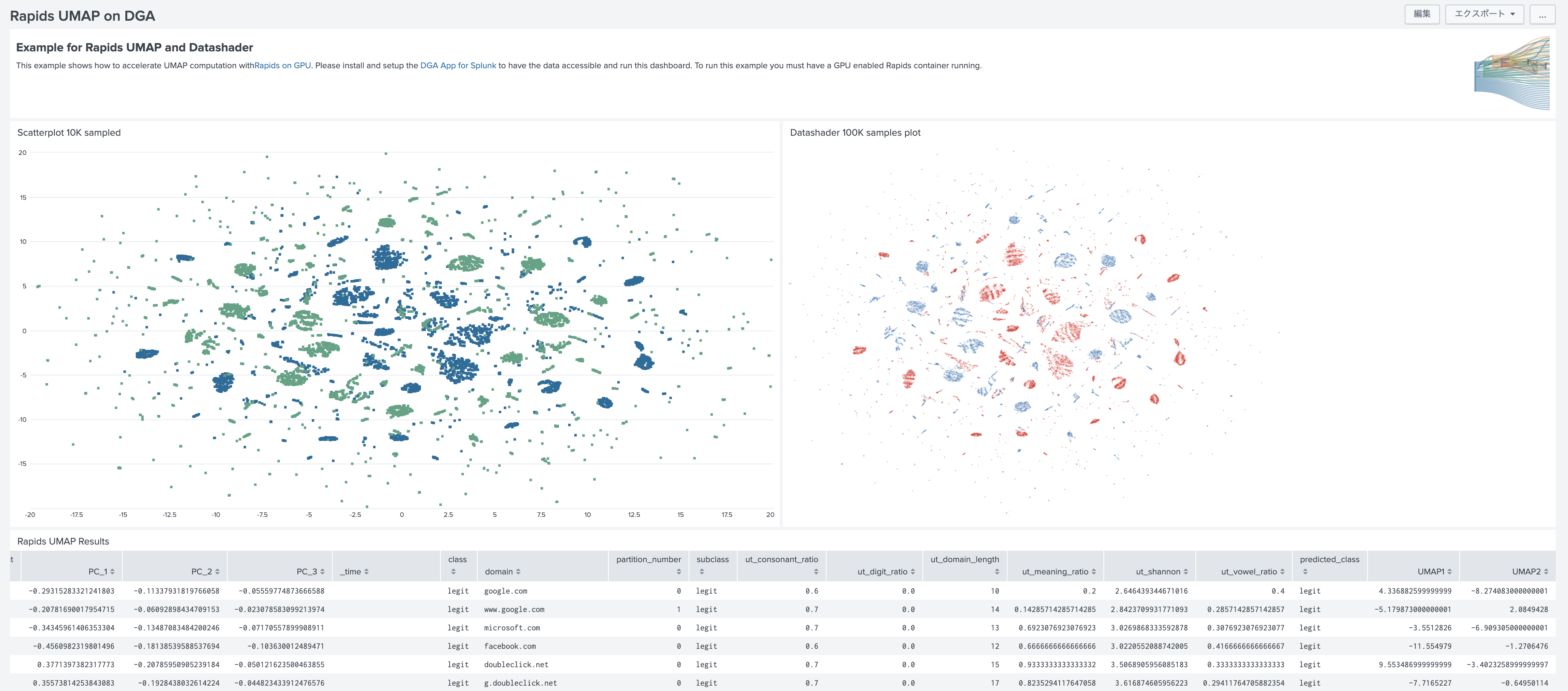
左側のグラフが scatterplot で右側のグラフが datashader になります。Jupyter Notebook側で作成されたグラフが、Splunkのダッシュボードで表示されております。
最後に
MLTKには、UMAPを使った次元削減は用意されておりませんが、DLTKを使ってこのようにUMAPを利用できるようになりました。しかもGPUとの組み合わせにより100,000件のデータ分析も瞬時に出すことが可能になります。是非お試しください。