はじめに
Splunk DLTKのサンプルコードを実行してみるシリーズです。
今回は Pytorch + CUDAのサンプルコードを実行しながら使い方について勉強してみたいと思います。
ただし、私の環境ではGPUは利用できないのでコードを眺めながらも実際はCPUで実行しております(いつの日かGPU環境を使って試してみたいなー)
Pytorchとは?
Facebookが開発を主導した機械学習ライブラリで、他のライブラリと比べて以下のような特徴があります。
- 直感的にコードを書ける
- 参照リソースが豊富
- define by run (動的フレームワーク。データを流しながら計算グラフを構築してくれる)
- device(CPU/GPU) の切替えが簡単にできる
4番の特徴のおかげで、今回のコードも簡単にCPU / GPUで実行&切替が可能になります。
CUDAとは?
NVIDIAが提供しているGPU向けのプログラミングモデルで、コンパイラーやライブラリを提供してます。
https://ja.wikipedia.org/wiki/CUDA
これらのライブラリーを使うことでデータをGPU上に送って計算することができるようになります。PytorchからこのCUDAのライブラリーを呼び出すことで、GPU上で機械学習ができるようになります。
サンプルコードを見てみる
それでは、早速DLTKのサンプルコードを見てみたいと思います。ノートブックには以下の2つが用意されてます。
- pytorch_logistic_regression.ipynb
- pytorch_nn.ipynb
今回は2つ目の pytorch_nn.ipynb をチェックしてみたいと思います。
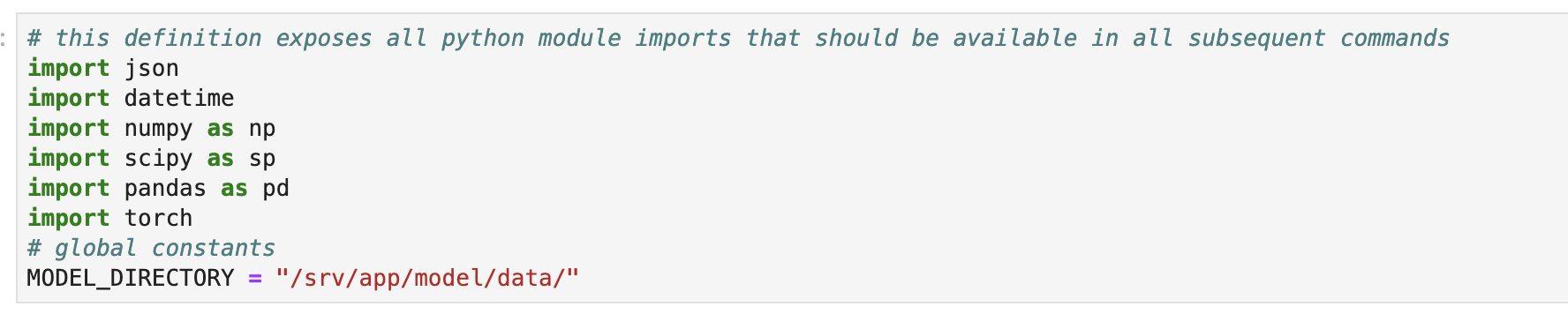
最初はライブラリーのインポートです。まだ CUDAに関してはtorchに含まれております。
Stage1: データ取り込み
Splunk DLTKではデータ取り込みは Splunkから行います。そのためSplunk側でSPLを実行して取り込むデータをコンテナに送ってあげます。
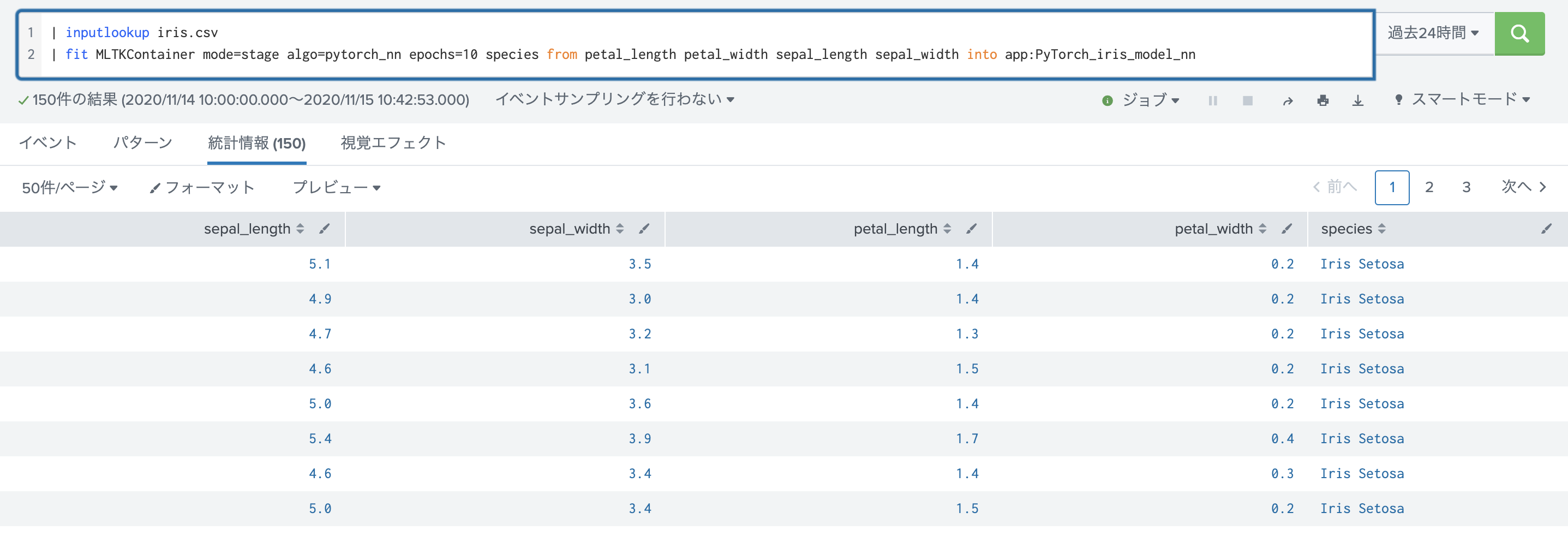
下の図はSplunk側での実行画面です。今回は irisのデータセットを使ってますね。ちなみに irisのデータセットはSplunkのMLTKに最初から入っているので、このまま利用できます。
Stage2: 初期化
次に学習前の初期化を行います。少し量が多いので少しずつ解説していきます。

最初に先ほど取り込んだデータから目的変数(Y)と説明変数(X)を代入します。またデータサイズとクラスの数を同じくデータから計算して代入します。NNで利用する学習率を指定して、YのSpeciesの種類を数字に変換するためにマッピングを作ります。
次にNNモデルのパラメータをここでセットします。
次にGPUが利用できる場合、device変数に "cuda"をセットします。なければ "cpu" になります。コードを書き直さなくても利用できるようになってますね。

先ほどの続きです。Splunk側でオプションが指定されているかチェックします。指定できるオプションは "epochs", "batch_size", "hidden_layers" の3つのようです。必要に応じてこちらを編集すればオプションを追加できます。
次にメインである、NNモデルを作成して、インスタンスを立ち上げます。nn.Linearは全結合層になります。nn.ReLUは活性化関数になります。最後に to(model['device']) で学習するデバイスを指定しているのがポイントです。
最後に損失関数(loss)や 最適化(Optimizer)を指定します。この辺りはNNの範囲です。
これで初期化は終了です。
Stage2: 学習(Fit)
学習ステージも少し長いのですが、前半は先ほどの初期化と同じ内容です。(両方に記載する理由はわかってません・・・)
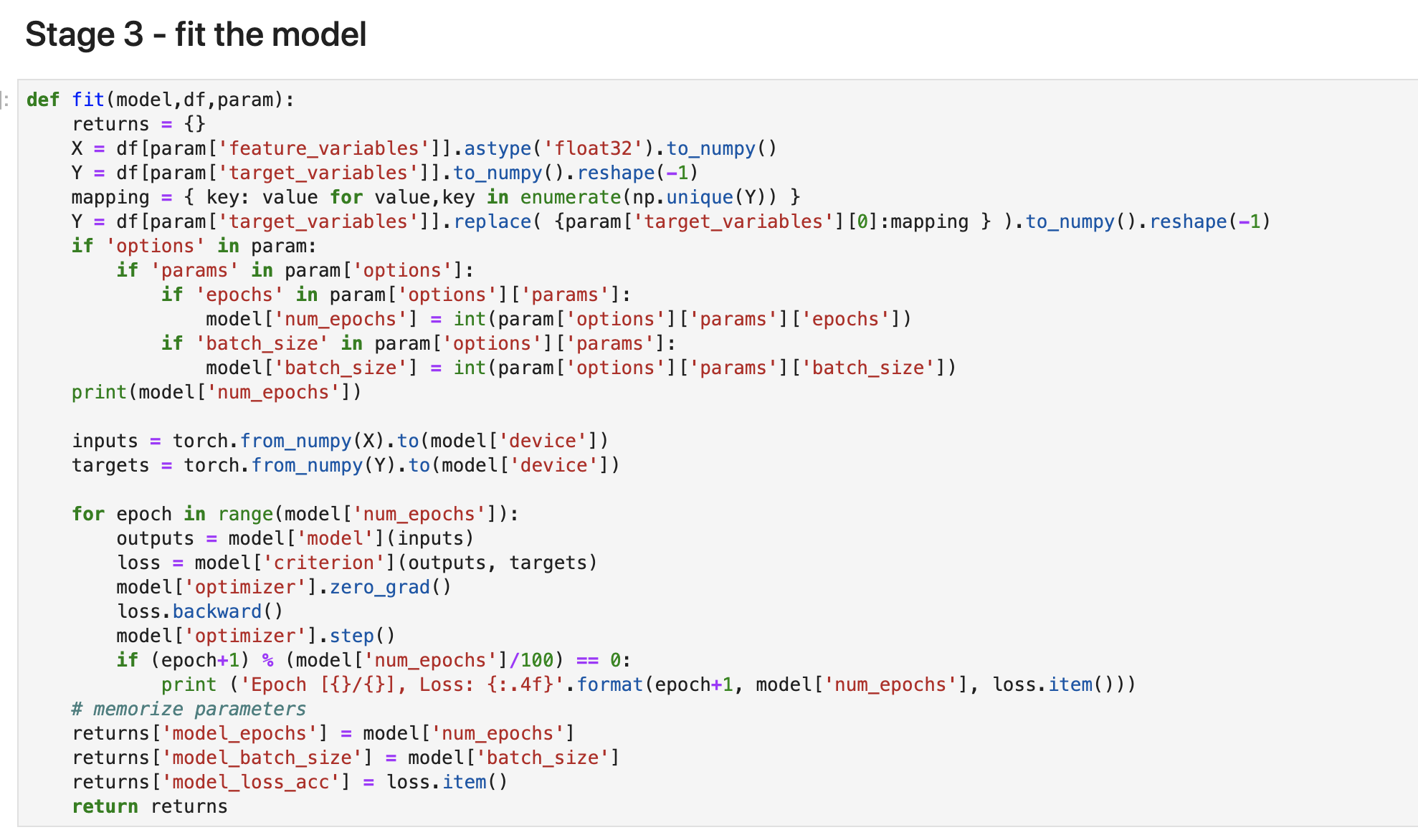
真ん中あたりに、inputs, targets にデータを代入しておりますが、その際にデバイス指定しております。この辺もCUDA連携のポイントです。
後半の for文の中で NNを実行します。model.step()の箇所ですね。
最後に epochs, batch_size, loss値 をリターンします。
Stage3: 適用(Apply)
次に適用ステージ設定です。

取得したデータをXに代入して、学習時に作ったモデルから目的変数の種類と番号をclassesに代入します。
inputを設定されたデバイス(CPU or GPU)に入れて、学習済みのモデルに適用します。softmax法と同じく一番予想が高いクラスをpredicted に代入します。 .cpu()というのは CPUで計算すると指定しております。
最後に予測値が数字で表現されているので、マッピングされるspeciesの値に変換してリターンします。
その他ステージ
残りはこんな感じです。
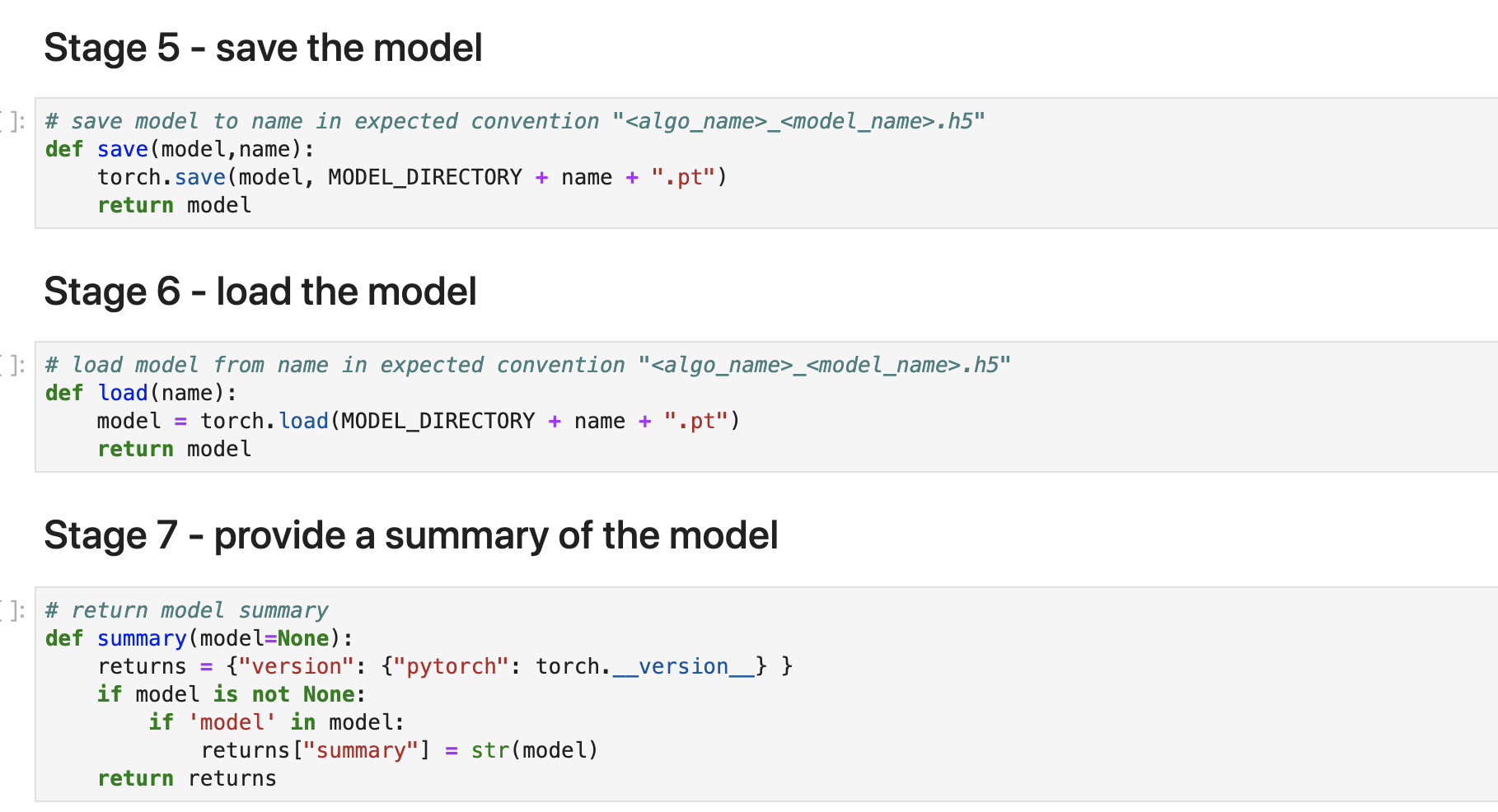
Splunkから実行してみる
fitで学習モデルを作ります。リターンはApplyの結果が返ってきますね。
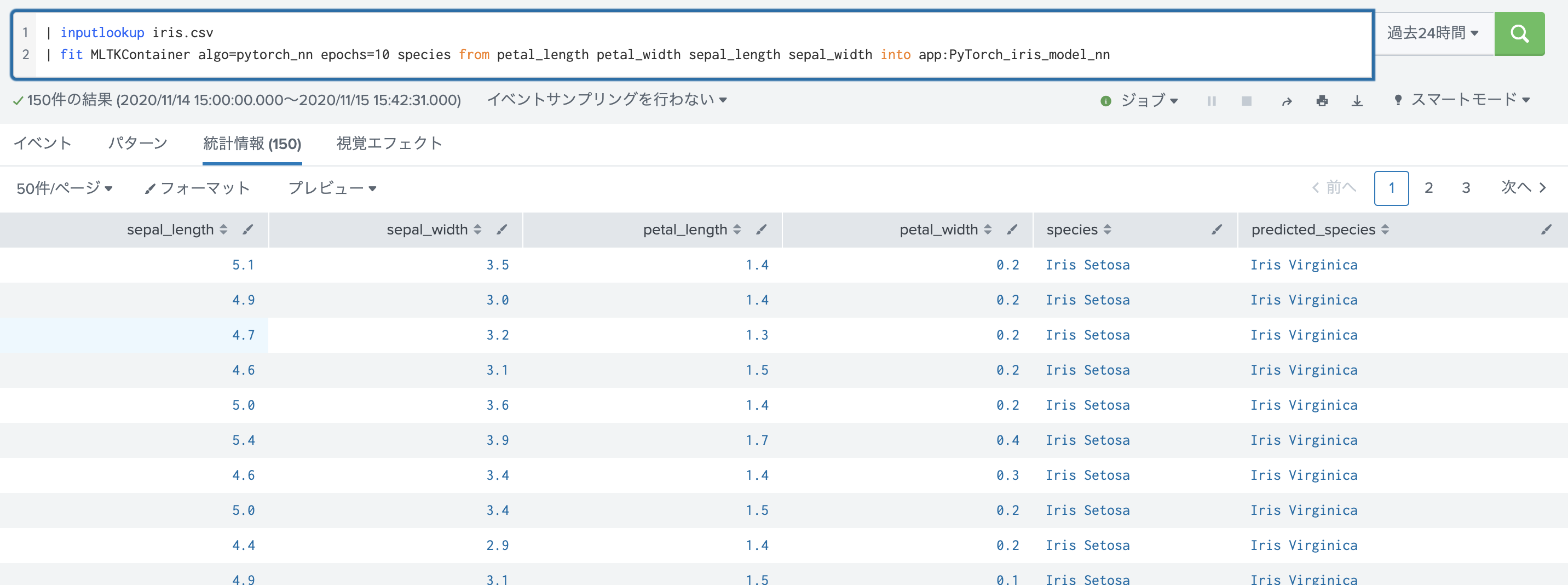
applyも同じ結果です。(同じデータを使っているため)
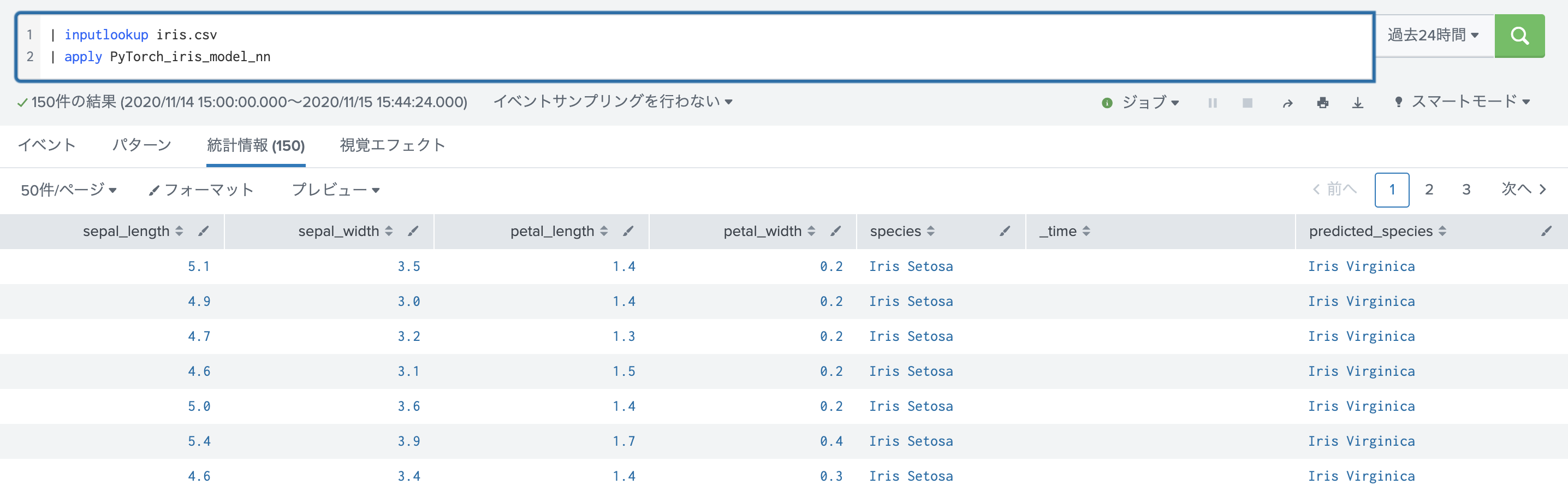
サンプルダッシュボード
Splunk DLTKにはサンプルダッシュボードが用意されております。
Epoch数をあげると精度が上がっていきます。今回はGPUがないため100回で実行した結果のため低くなっておりました。
最後に
本来ならGPUを使って、学習時間の比較をしたかったですが、これは今度にしたいと思います。
コードがそのまま再利用できるのはうれしいです😊