概要
Splunkが DeepLearningに対応しました(驚き)。昨年(2018年)の .conf で発表があり beta 版としてアングラで動いてたらしいですが、今回正式に Deep Learning Toolkit もリリースされて追加できるようになりました。 もちろんGPUなどにも対応しており、Tensorflow /Keras / PyTorch そして 複数の NLP ライブラリが利用可能です。
今回はどんな感じで実装できるのか、まずはセットアップしてみたいと思います。
ちなみに Youtubeで概要とセットアップなどが紹介されてますので、こちらも合わせてチェックしてください。
https://www.youtube.com/watch?v=IYCvwABLyh4
マニュアルはなさそうでして、DL Toolkit アプリをインストールすると簡単なセットアップガイドが載ってるため、そこを参照しながら作成しました。
Deep Learning Toolkit for Splunkとは?
以下のイメージのように、Splunk環境とは別に Container 環境を用意して、そこで学習や本番データへの適用を実行します。そのためコンテナ環境ではGPUなども利用し学習時間を短縮させることも可能です。
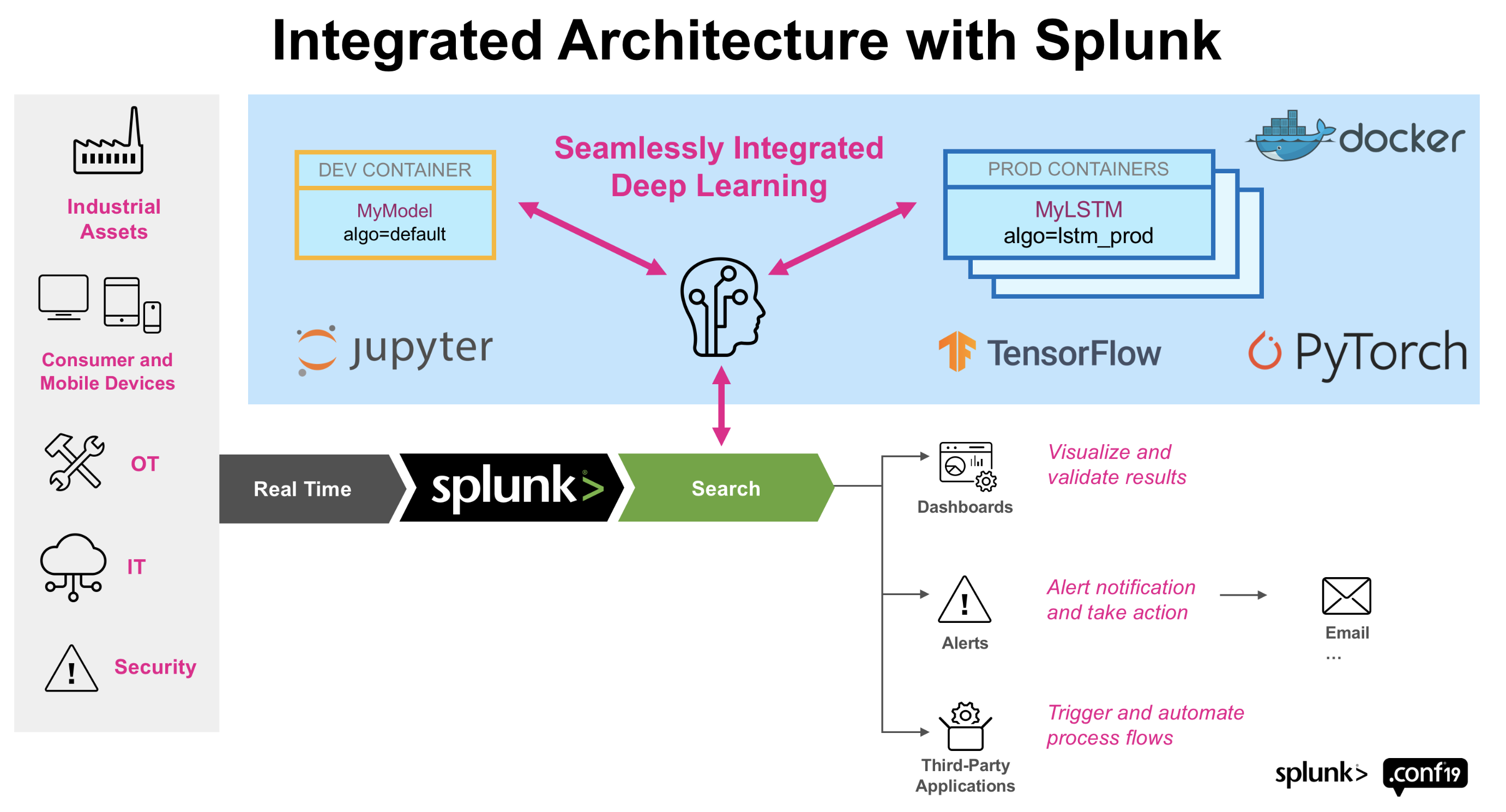
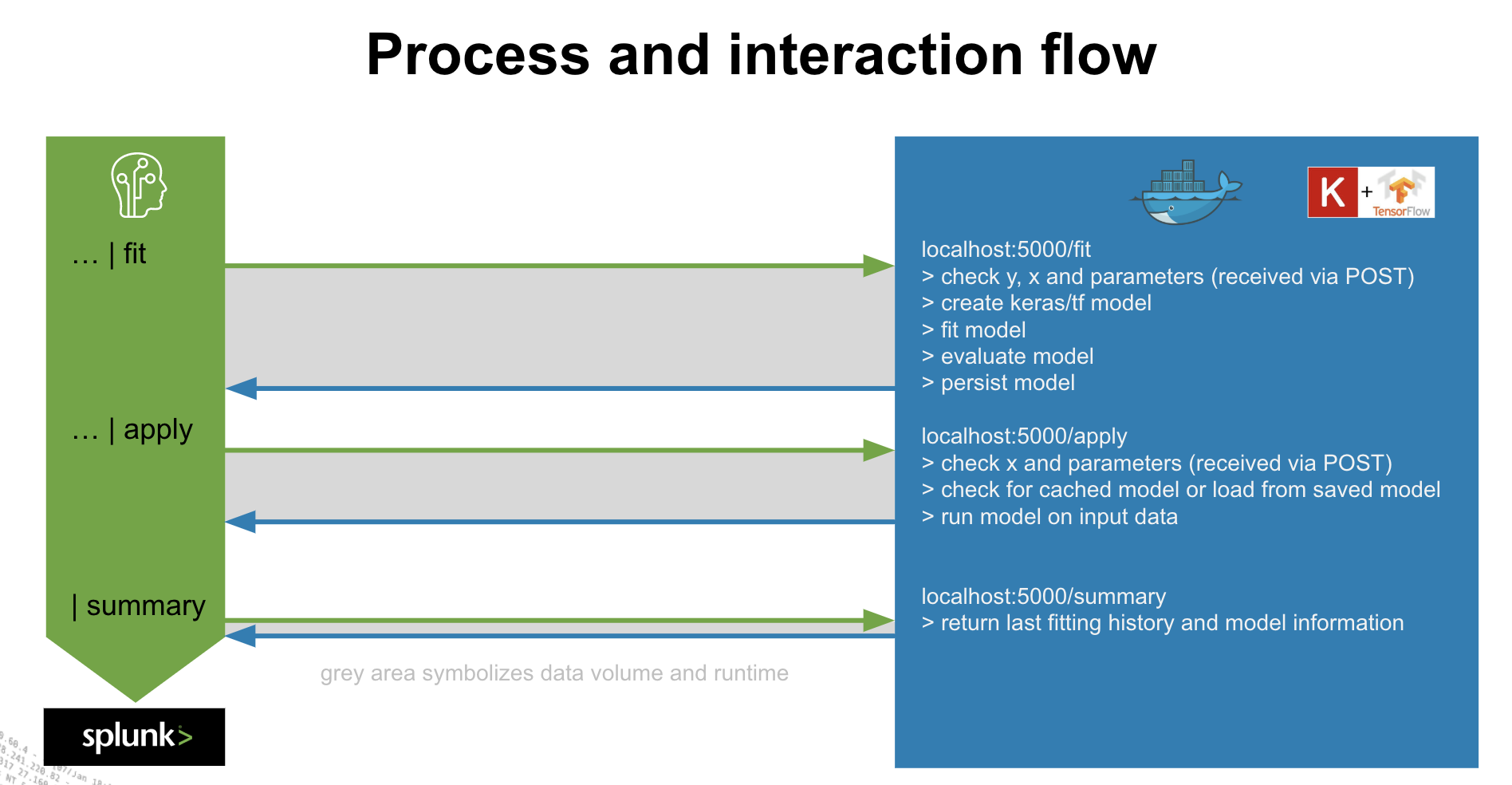
以下のように、Splunk側から fit / apply などのコマンドと一緒にモデルを指定すると、コンテナ環境上にデータをロードし指定したモデルに従い結果をリプライします。そのため Splunk側からは従来の機械学習用のアルゴリズムと同様にモデルのスケジュール実行やアラートなど運用に取り込むことが可能となります。簡単にいうとDLに関わる部分だけを外出ししてデータの取得や前処理、結果の実装などは従来通りSplunkという Win-Win の関係なのです。
あと splunkbase をみると、現在のところこのToolkitはサポート対象外のようなので、利用の際は注意してご利用ください。
構成について
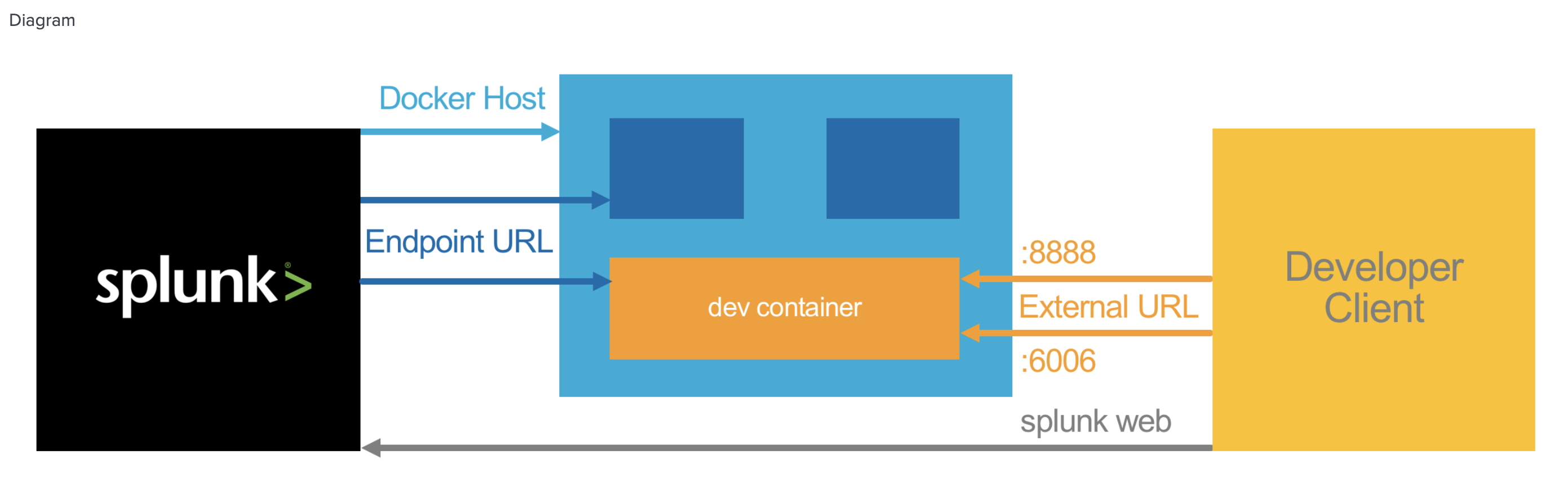
シングル構成と、 Splunk 環境と Docker 環境を分離した構成の2パターンが構成できます。
以下のように、Client(ユーザーPC)からも Dockerにアクセスするため、分離する場合は、External IPが必要になります。
事前準備
・Splunk環境は、現在(2019/10/28時点)では Splunk 7.3 のみです。 version 3.0で8にも対応しました!
・Splunk Machine Learning Toolkit 4.4
・Python for Scientific Computing 1.4
・Deep Learning Toolkit for Splunk 2.3 (*) Splunk8の場合は 3.0が必要
https://splunkbase.splunk.com/app/4607/
<コンテナ環境>
・ Docker
セットアップ
今回は、最初ということもありシンプルにシングルノード構成でセットアップします。分離する場合はおそらくリモートから Dockerhostに対して命令できるような追加の設定が必要になると思われます。
1. 各種アプリのインストール
まずは、Splunk 7.3 の環境に対して、以下のアプリをインストールします。やり方は通常のアプリと同じです。
・Splunk Machine Learning Toolkit 4.4
・Python for Scientific Computing 1.4
・Deep Learning Toolkit for Splunk 2.3
2. Docker 環境の準備
今回はシングルノード構成なので、同じホスト上に Docker をインストールします。
## docker のインストール
$ sudo yum install docker
## docker サービスの立ち上げ
$ sudo service docker start
基本的にはこれだけで利用できます。あとはboot時に dockerサービスが立ち上がるように設定するとかくらいでOKです。
sudo chkconfig docker on
3. セットアップ
DL Toolkit のセットアップ画面に行くと、以下のようにあります。
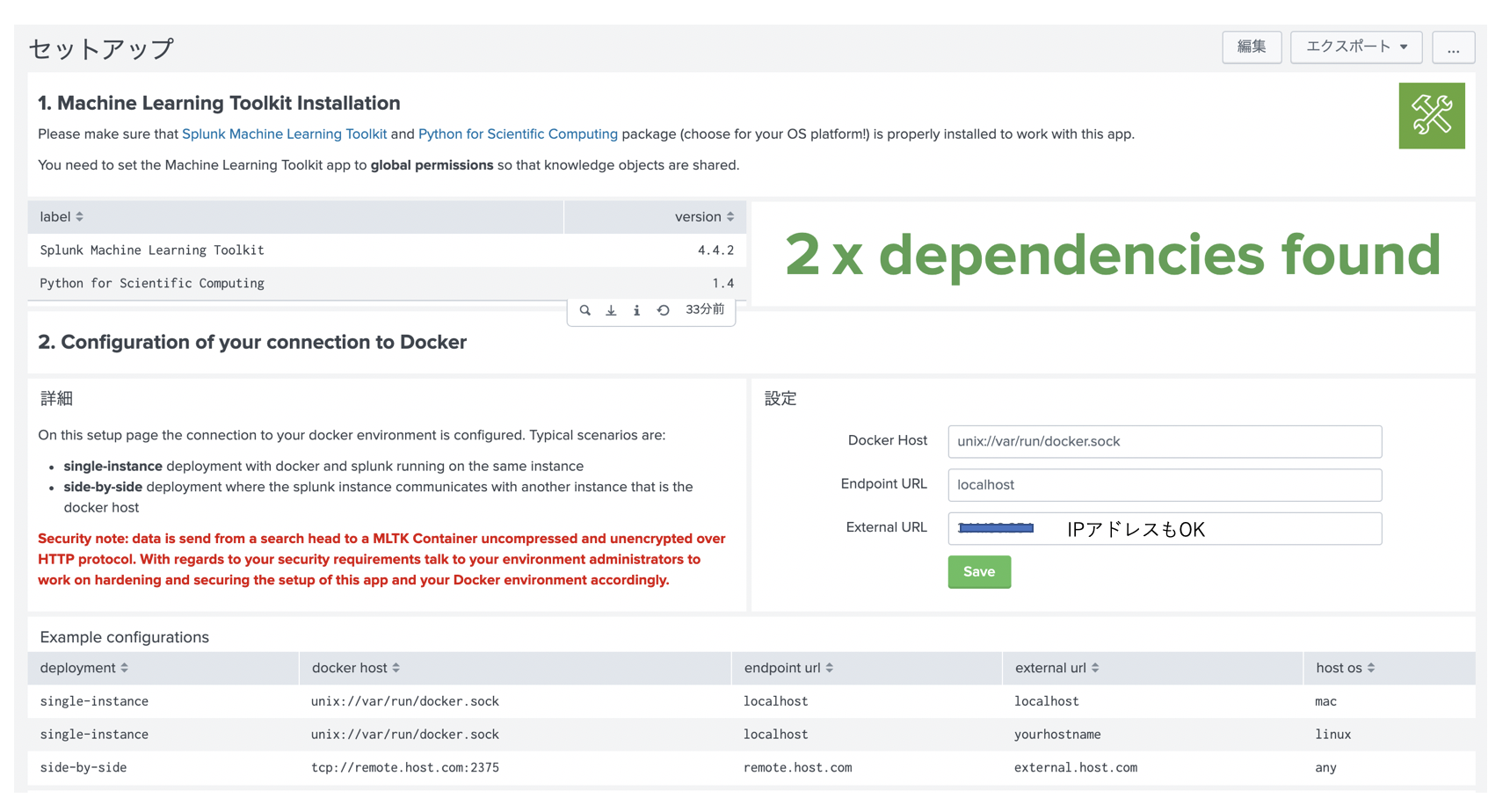
最初に、MLTK/PSCがインストールされているかチェックされます。
ここで、MLTKは、Global permissionが必要とあるので、アプリ設定画面で permissionを変更しましょう。
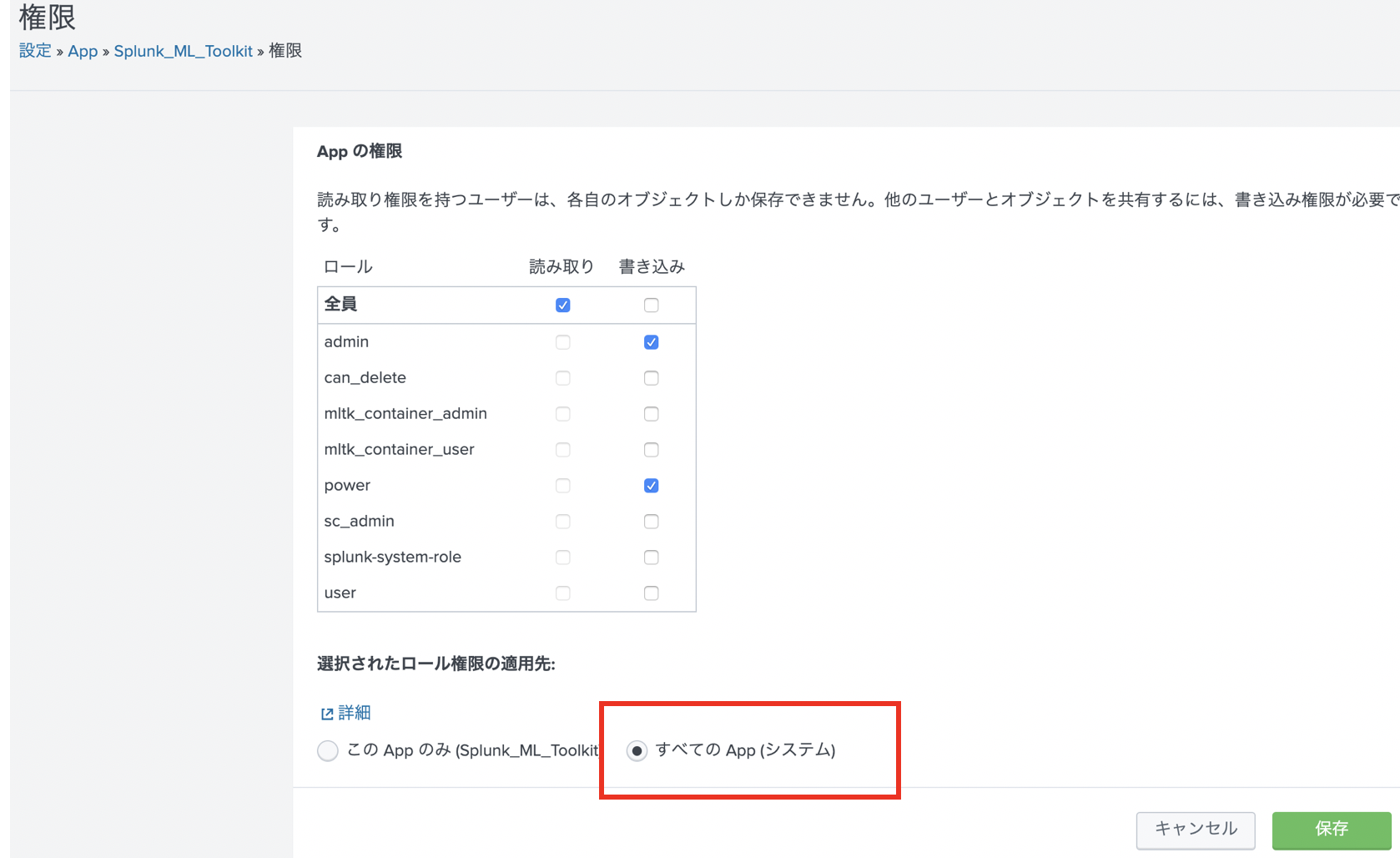
そして2番目の設定項目で、私の環境は Linux の single node 構成なので、下にある Exampleを参考に以下のように入力しました。
DockerHost : unix://var/run/docker.sock
Endpoint URL: localhost
External URL:
External URL は、自分のPCからアクセスできるような IPアドレスまたはホスト名を入力します。また FW設定などある場合は、8888 / 6006 に対してアクセスできるように変更してください。
あとは、Save ボタンを押すと、以下のようなメッセージが現れたら完了です。
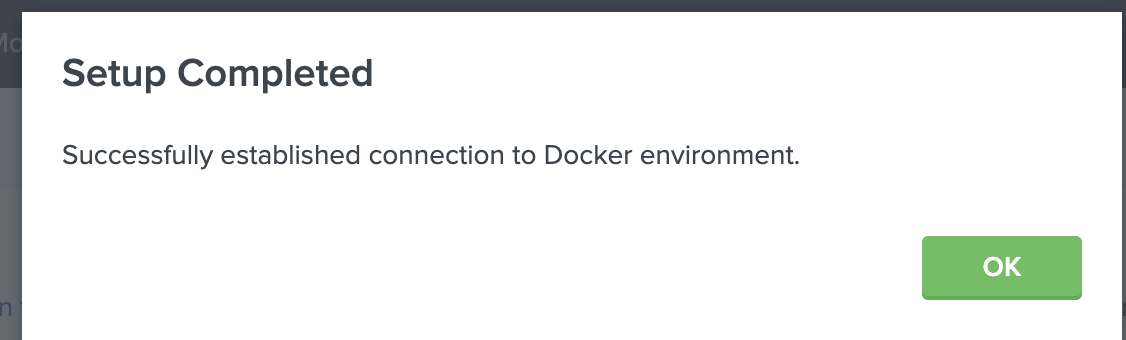
もし、うまく現れない場合は、Dockerhostにうまくアクセスできていないので、サービスが上がっているか、もしくはリモートアクセス権なども確認してみてください。
開発の流れ
さて、ここまで来たら基本的なセットアップは終了です。次にアプリ内にある 以下のモデル作成ガイドにしたがって進めたいと思います。

0 から 8までのステップが書いてあります。
0: コンテナ準備とセットアップ (開発用のコンテナ環境のロードと起動)
- モデル作成の準備 ( jupyter labで、 pythonコードがモデル名になるため、サンプルコードを参考にコピーして新規モデルを保存します)
- コードを書くために、サンプルデータをコンテナ上にロードします。
- モデルの中身作成 ( jupyter labで、モデルの中身のコードを書きます。cnn / lstm など自由にモデルを作成することが出来ます)
- 実データを使ってモデルの学習をする。 ( fit コマンドを使って、splunk上で作成したモデルを呼び出して学習させる)
- 学習状況を確認 (tensorboardを使って、学習状況を確認します)
- 実モデルのテスト&評価 (apply コマンドで 学習済みのモデルを使って、今まで利用していなかったデータに対して適用し評価する)
- モデルの反復、改良、再トレーニング (モデルをさらにいいものにするため、上記を繰り返します)
- 本番データへの適用 (完成したモデルを使って実運用をする。 apply コマンドで適用)
Step 0: 最初に開発用のコンテナ環境を作成します。
すでに4つのコンテナが DockerHub上に用意されており、利用したいライブラリや環境(GPUなど)により、選択してロードします。今回はGPUがないので、Tensorflow CPUを選択しました。
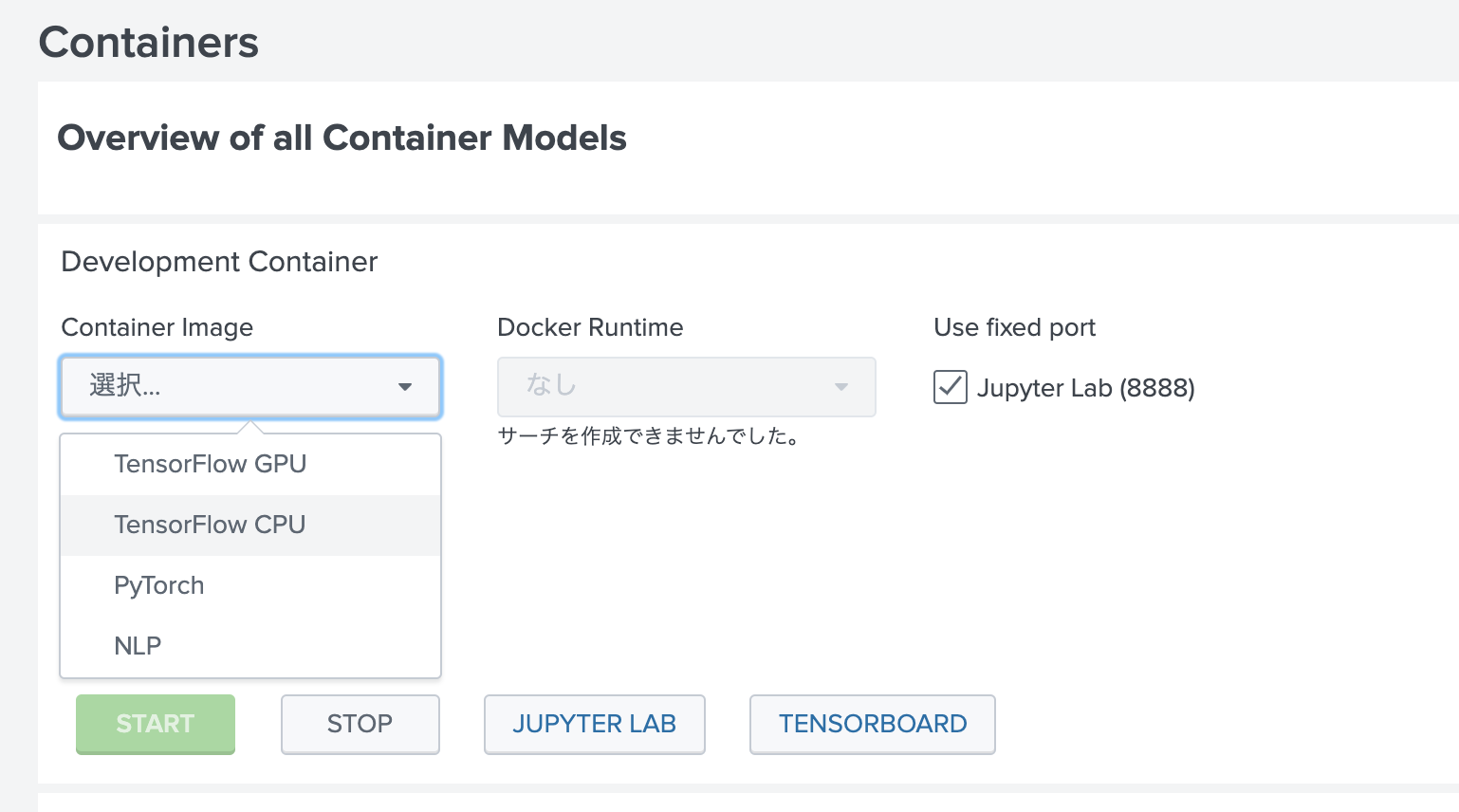
Startすると、Jupyter NotebookやTensorboard環境にもアクセスできるようになります。
ちなみにRebuildしたりローカルのリポジトリに登録したい場合は、こちらからダウンロードして変更できます。
https://github.com/splunk/splunk-mltk-container-docker
Step 1. JupyterLabを用いたモデル作成の準備
"JUPYTER LAB" ボタンをクリックして、jupyter lab にアクセスします。(pass: Splunk4DeepLearning)
/notebook に移動すると、サンプルでいくつもの pythonコードが用意されております。 (my_ と頭文字にあるのは私がコピーしたものです)
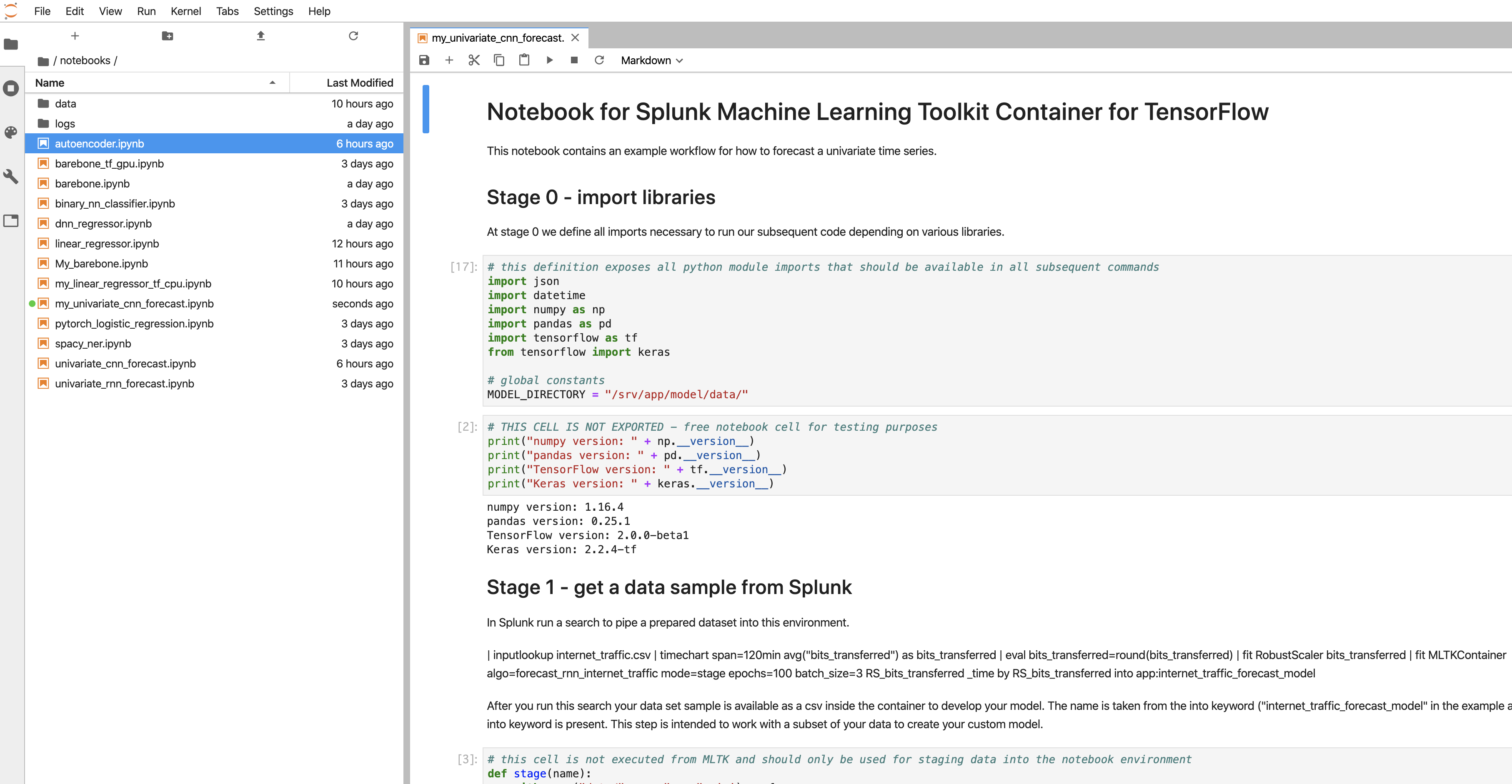
サンプルコードをコピーして、my_univariate_cnn_forecast.ipynb として保存します。
ちなみに、今回は CNNの Conv1Dを使った時系列予測のサンプルアルゴリズムを使用します。
Step 2. Splunk上のデータをコンテナ環境上にロードする
Splunkのサーチで以下のコマンドを実行し、コンテナ環境にデータセットをロードします。
この後 juniper notebook を使って、モデルを作成する際に利用するためなので、サンプルデータとしていくつか取り込めれば十分です。
今回はデータの正規化のため RobustScaler を使っておりますが、必須ではありません。前処理としてお好きなように加工してください。
mode=stage と指定することで、実際には fitせずにデータをコンテナ環境にロードするようになります。
(データはコンテナ内の /srv/notebook/data に保存されます)
| inputlookup internet_traffic.csv
| timechart span=120min avg("bits_transferred") as bits_transferred
| eval bits_transferred=round(bits_transferred)
| fit RobustScaler bits_transferred
| fit MLTKContainer mode=stage algo=my_univariate_cnn_forecast RS_bits_transferred _time by RS_bits_transferred into app:internet_traffic_forecast_model
今回は時系列予測で1次元の特徴量でいいのですが、順番も関係あるため _timeも指定しておりますが、実際に利用するのは RS_bits_transferred のため、byで対象のフィールドを指定しております。
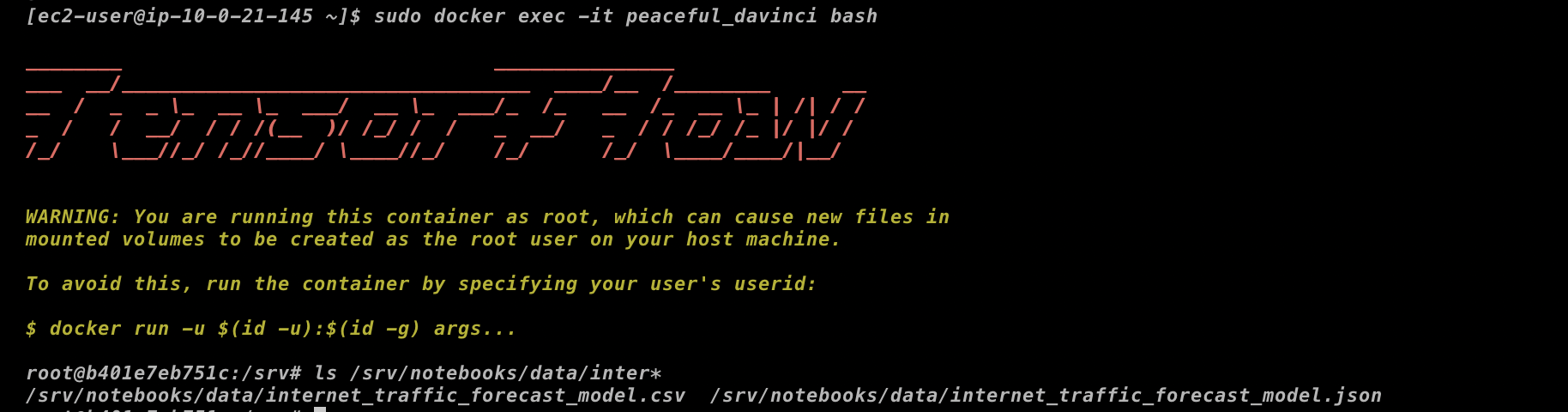
ちなみに、コンテナ内のディレクトリを確認すると、確かにデータが読み込まれているのが確認できます。
Step 3. モデルの中身の作成
それでは、保存した my_univariate_cnn_forecast.ipynb の中身を見ていきます。
Stage0: ライブラリーインポート
こちらは、このまま実行します。

Stage1: Splunkからのデータロードの確認
先ほどコンテナ上にロードしたデータが読み込めるか確認します。
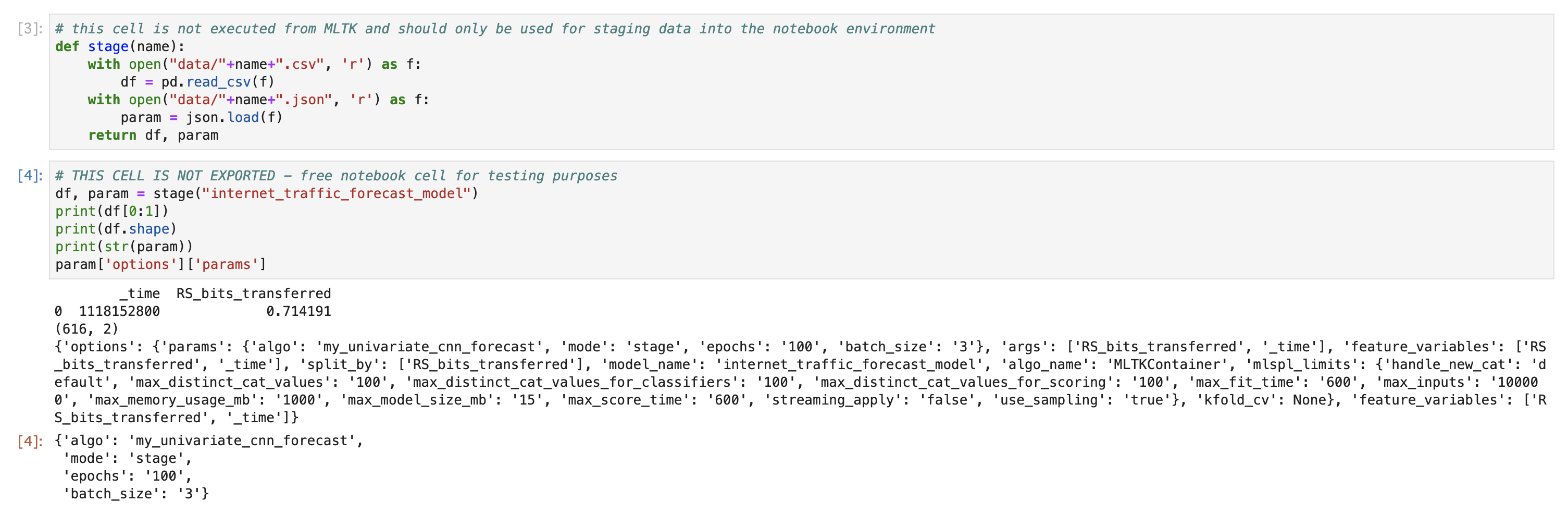
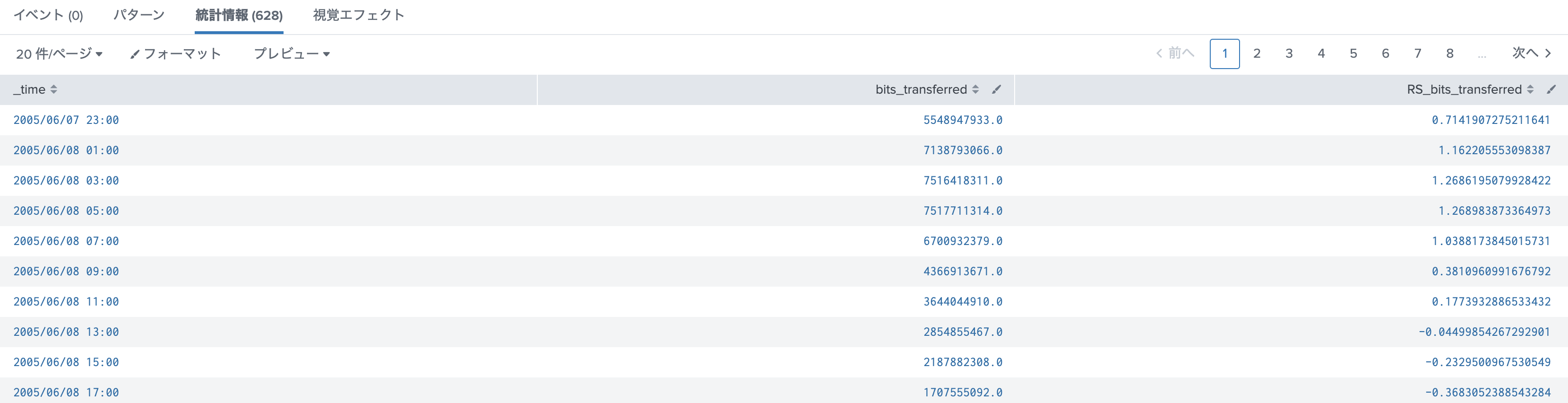
ちゃんと、データセットと epoch などのオプションが読み込めてますね。
Stage2. モデルの作成と初期化
ここでロードしたデータセットを使って、モデルの作成と初期化を行います。
詳細は省きますが、今回はCNNのモデルを定義しております。お好みでレイヤーを追加してもOKです。
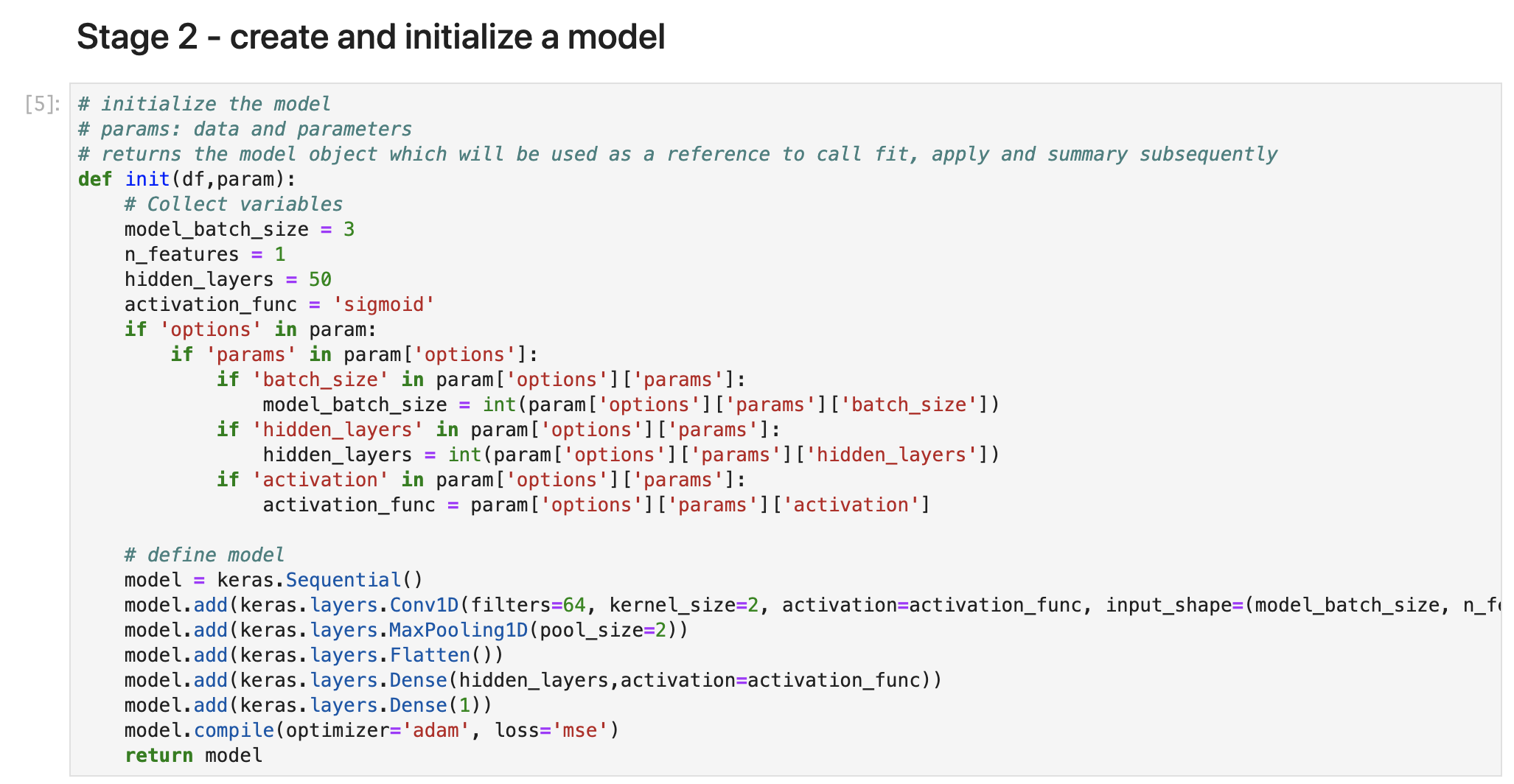
summary関数で、定義したモデルの中身をみてみます。
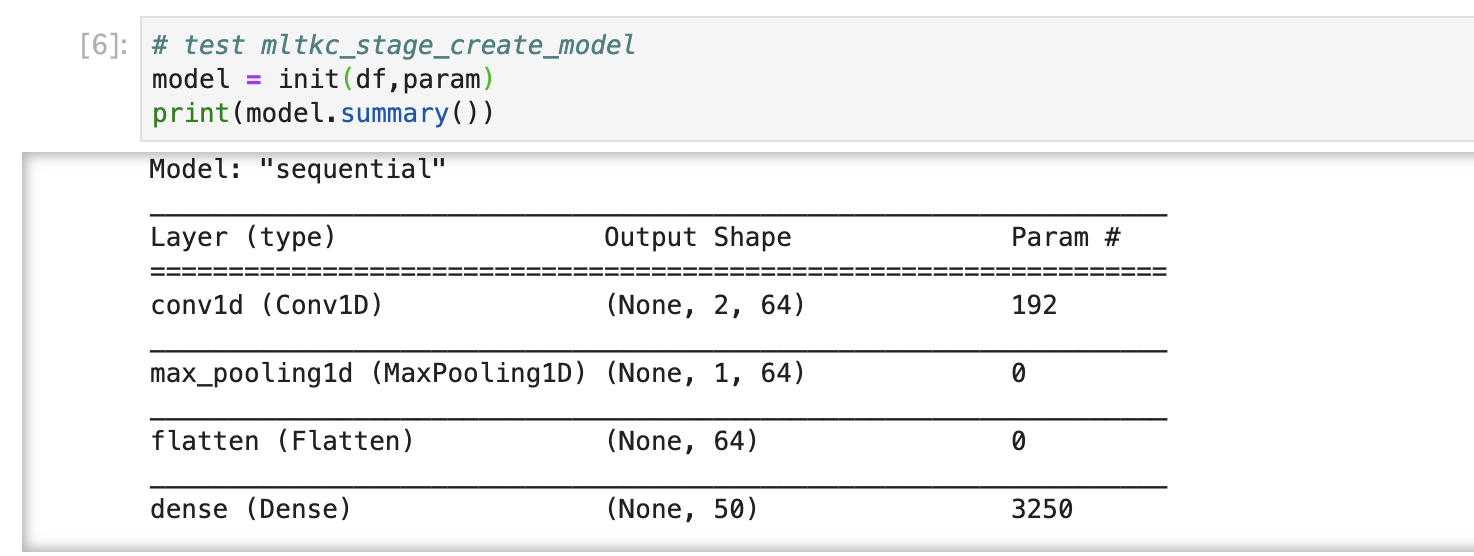
Stage3. fit モデルの定義
ここでは、fit コマンドの中身を定義していきます。
後ほど Splunkから fitコマンドでアルゴリズムが呼び出された際にこちらの関数が実行されます。

ステージング用のデータセットを使って fitさせた結果を確認。結果によってはモデルを作り直したり、パラメータを変更したりします。

Stage4. Apply の定義
ここでは、Splunkから applyコマンドを呼び出された際に実行する関数を定義します。
model_batch_size などのパラメータのデフォルト値はこちらで変更するか、apply実行時に引数で指定できます。

Stage5. モデルの保存
モデルの保存先などを定義してます。

その他 ( load model / summary model)
他の学習済みモデルを読み込んだり、モデルのサマリーを確認する関数を定義。

最後まで実行が出来たら、作成したjupyter notebookを保存してください。
Step 4. 実際の訓練データを使った学習 (fitコマンド)
さてアルゴリズムは作成しましたので、実際にSplunkからモデルの学習用の訓練データを使って学習させたいと思います。
(今回はstageと同じデータセットを使わせて頂きます)
mode=stage というオプションが外れ、最後に model名を指定して保存しております。
また epochs などオプションを指定しておりますが、指定しない場合はデフォルト値が利用されます。(今回はデフォルト値と同じですが)
| inputlookup internet_traffic.csv
| timechart span=120min avg("bits_transferred") as bits_transferred
| eval bits_transferred=round(bits_transferred)
| fit RobustScaler bits_transferred
| fit MLTKContainer algo=my_univariate_cnn_forecast epochs=100 batch_size=3 RS_bits_transferred _time by RS_bits_transferred into app:MyFirstModel
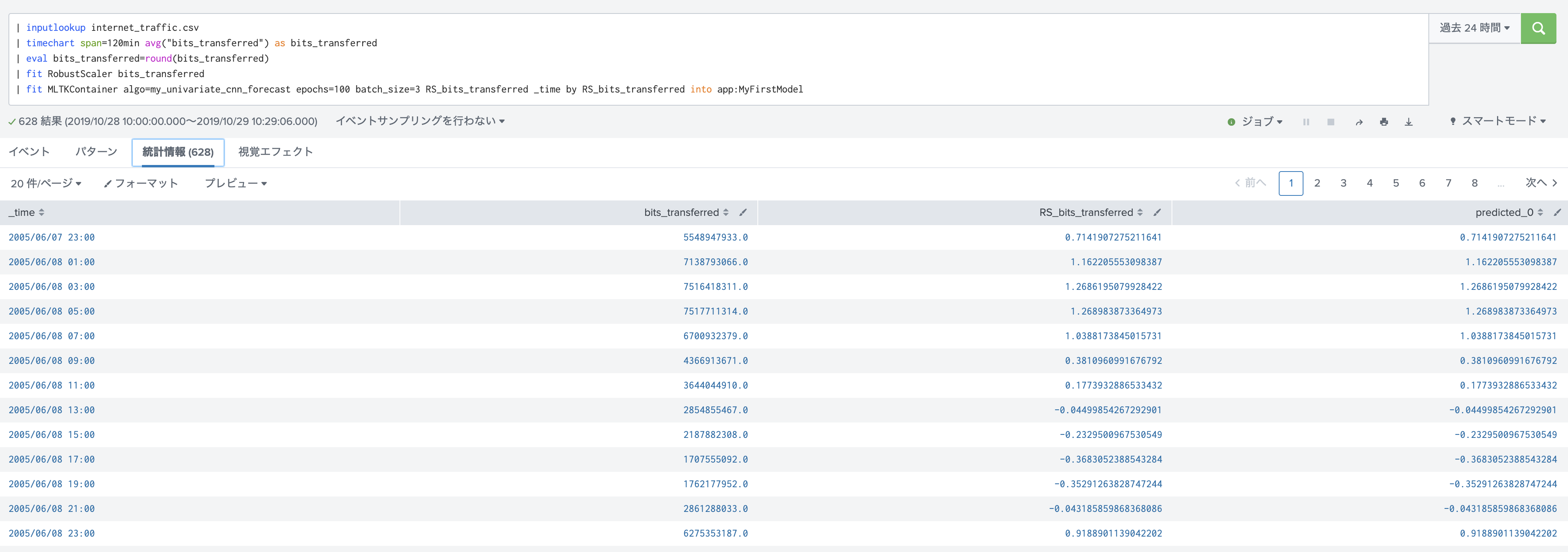
"predicted_0" というフィールドが出来てますね。こちらが予測値になります。
今回は Conv1D を使用しており、inputがbatch_sizeになっているので、3つのデータを使って、次の一つを予測するようなモデルになっております。
Step 5. Tensorboard を用いた学習状況の確認
学習したモデルについては、学習中の経過や精度などを Tensorboardを使って確認できます。
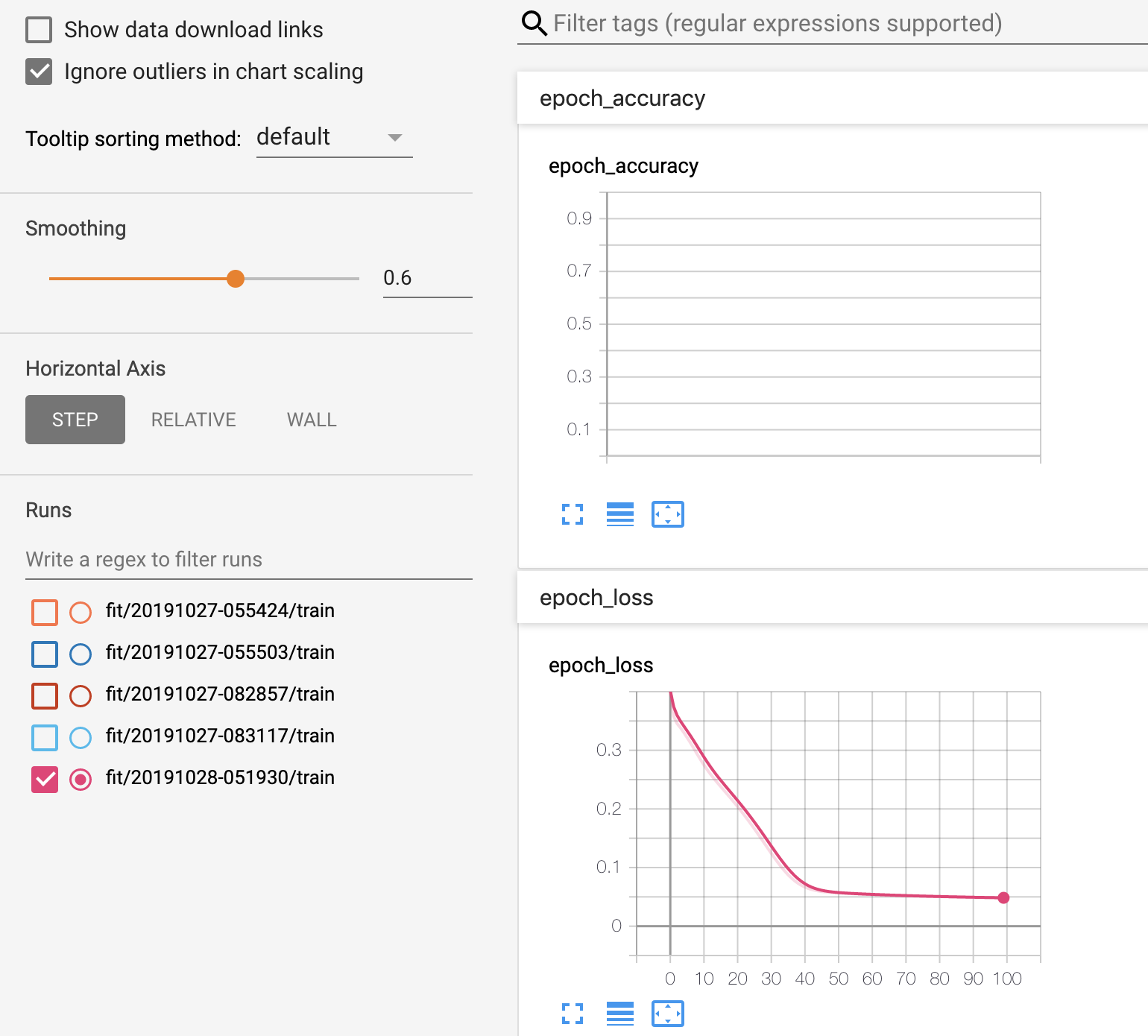
Tensorboard の見方はよく分からないため、イメージ図だけ貼り付けておきます。(勉強せねば。。。)
・ モデルの中身を図示
・ epoch ごとのロス率
・(Distributions)

・(Histgrams)
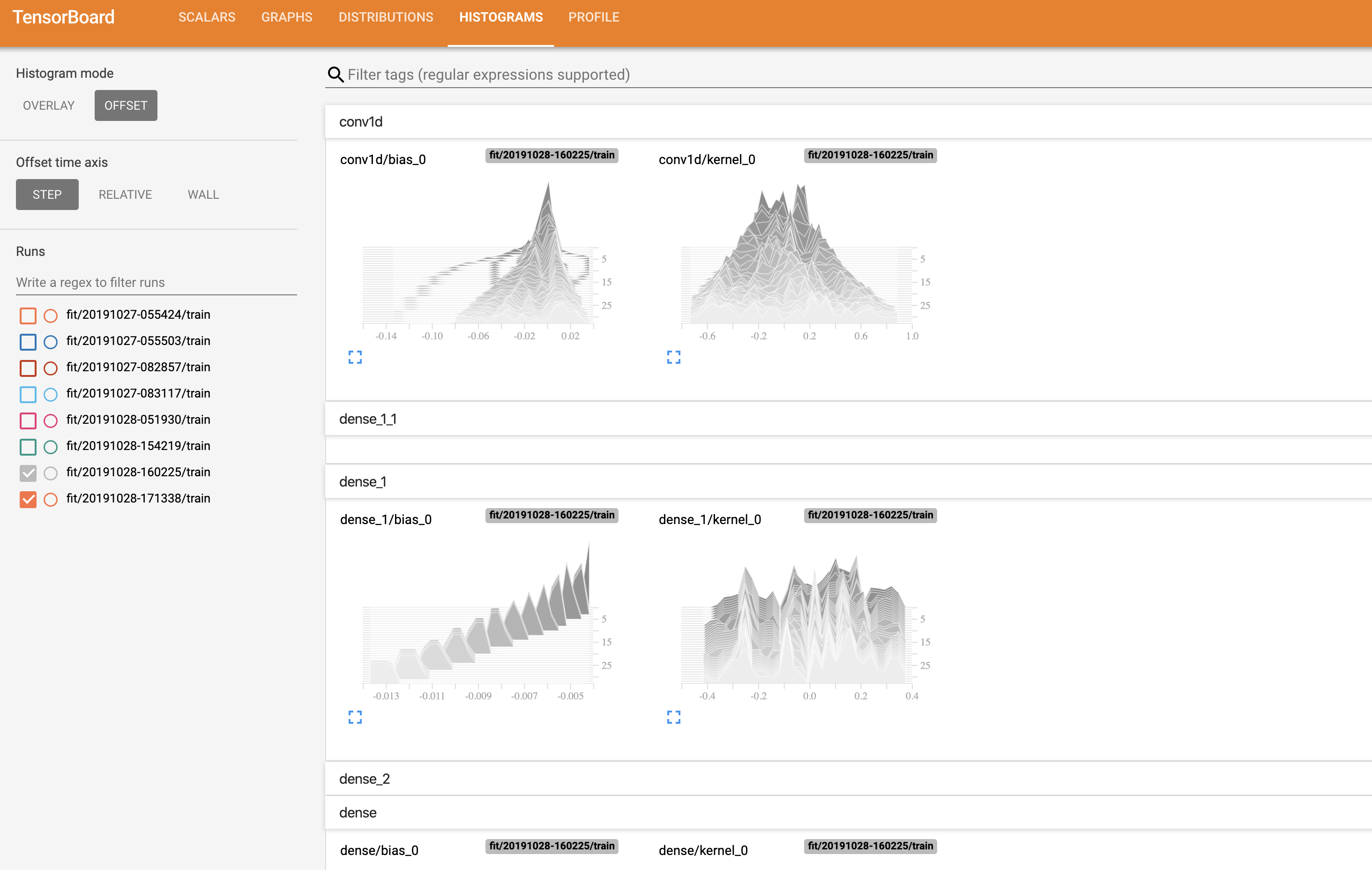
Step 6. 検証データへの適用・評価
Tensorboardを見ながら学習がうまく行ってそうだったら、検証データへ適用して評価します。
今回はToolの使い方がメインなので、訓練データと同じデータを利用させて頂きます。(本来は別のデータに適用し評価する必要があります)
| inputlookup internet_traffic.csv
| timechart span=120min avg("bits_transferred") as bits_transferred
| eval bits_transferred=round(bits_transferred)
| fit RobustScaler bits_transferred
| apply MyFirstModel
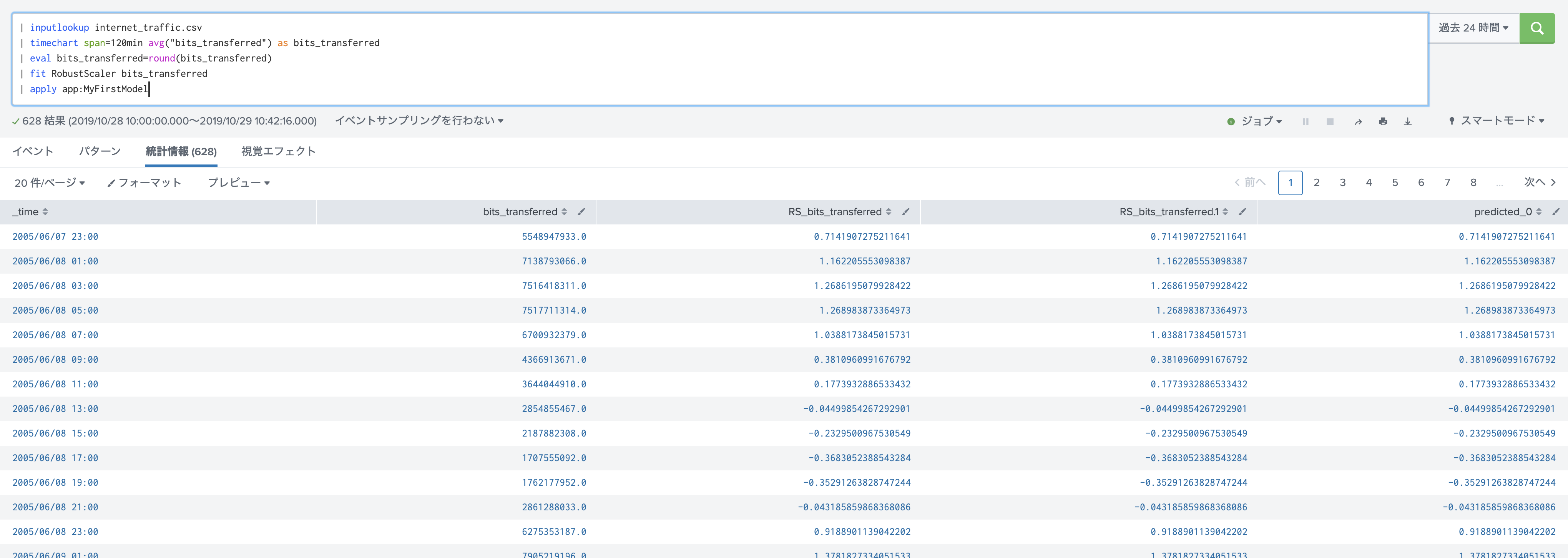
見やすいように予測した最後の30箇所にズームするとこちらのようになりました。(holdback=30 のため)
予測値と実測値が同じように推移しているのがわかります。
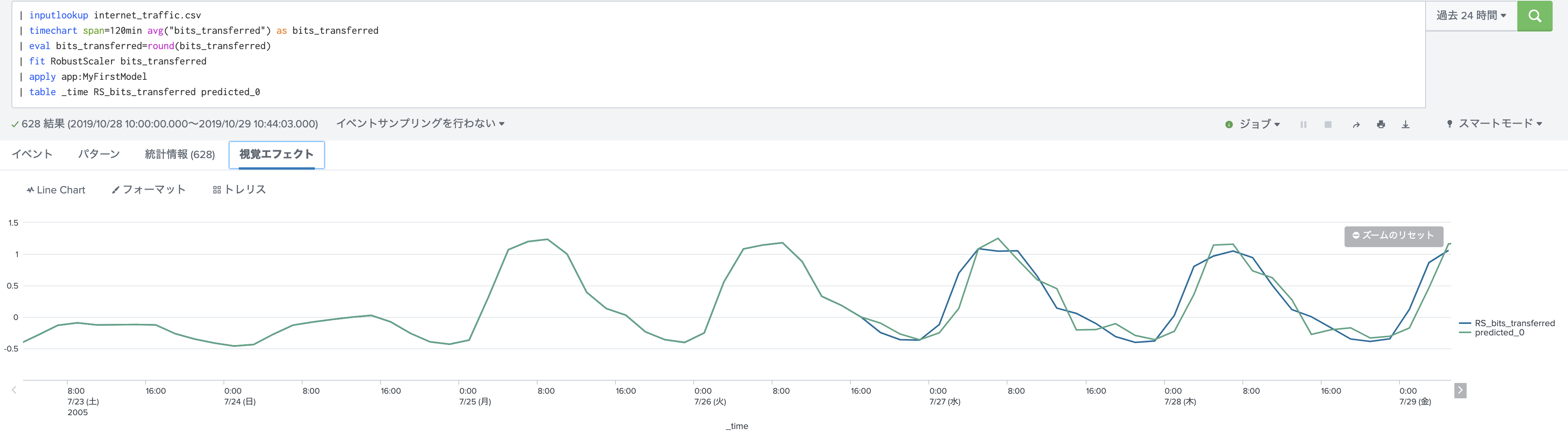
一応評価もしてみます。
| inputlookup internet_traffic.csv
| timechart span=120min avg("bits_transferred") as bits_transferred
| eval bits_transferred=round(bits_transferred)
| fit RobustScaler bits_transferred
| apply MyFirstModel
| table _time RS_bits_transferred predicted_0
| where isnotnull(RS_bits_transferred)
| tail 30
| score r2_score "RS_bits_transferred" against "predicted_0"

流石に訓練データと同じなので精度も高いですね。
Step 7. モデルの反復、改良、再学習
Step6 の結果を見ながら、Stage3のモデルを作り直したり、パラメーターを変更したりして納得のいくモデルを作り上げます。
ちなみに、summary コマンドの結果です。
| summary MyFirstModel
| spath input=summary
| fields - summary
| transpose
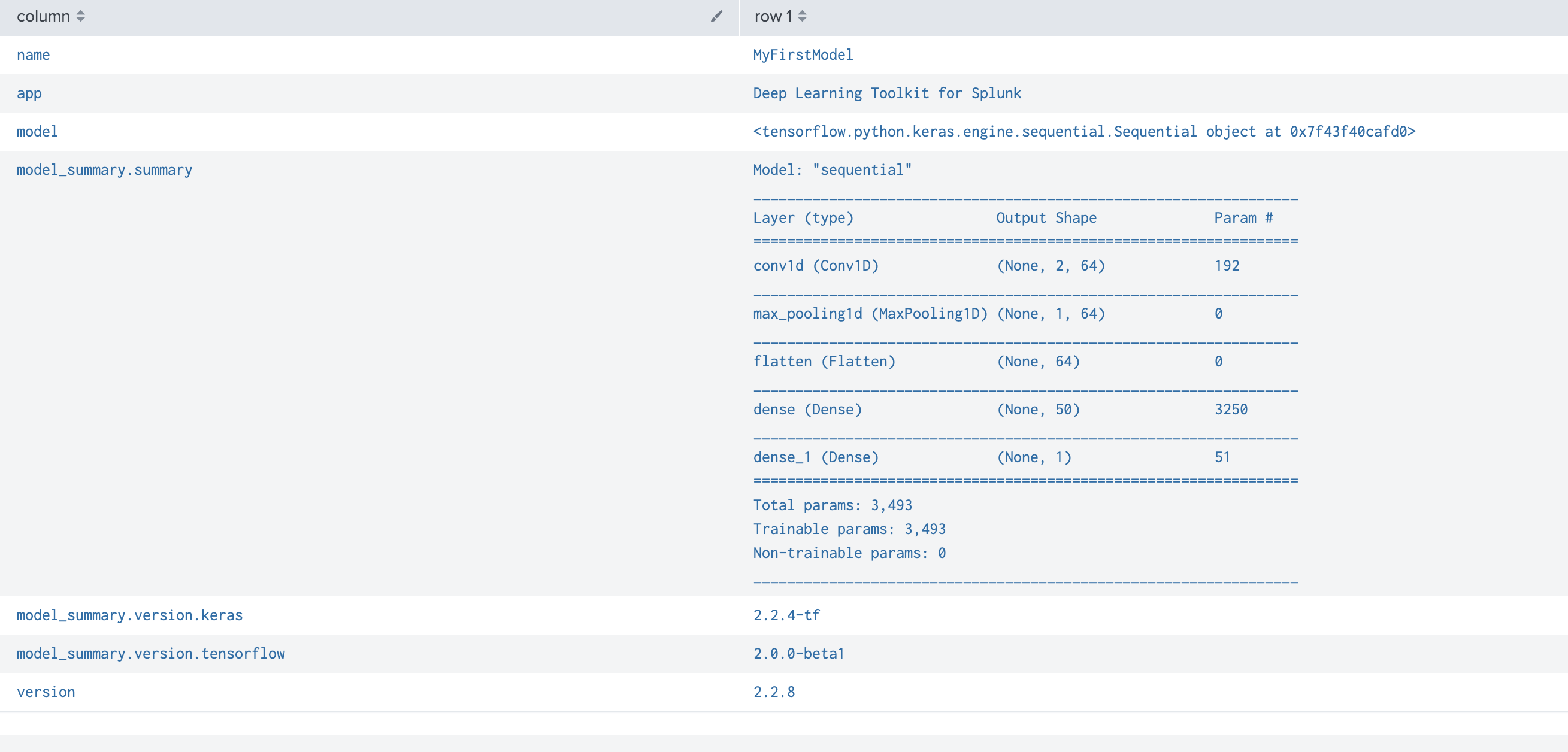
Step 8. 運用への実装
Step6 で実行した apply コマンドを使って、本番環境に実装を行います。学習済みのモデルを適用するだけなので負荷はそれほど高くないです。
コンテナ環境は開発用のコンテナのままなので、本番運用向けのコンテナ環境を deployして実装するのが推奨です。
コンテナ管理の画面からモデルを選択してコンテナイメージを適用するだけです。
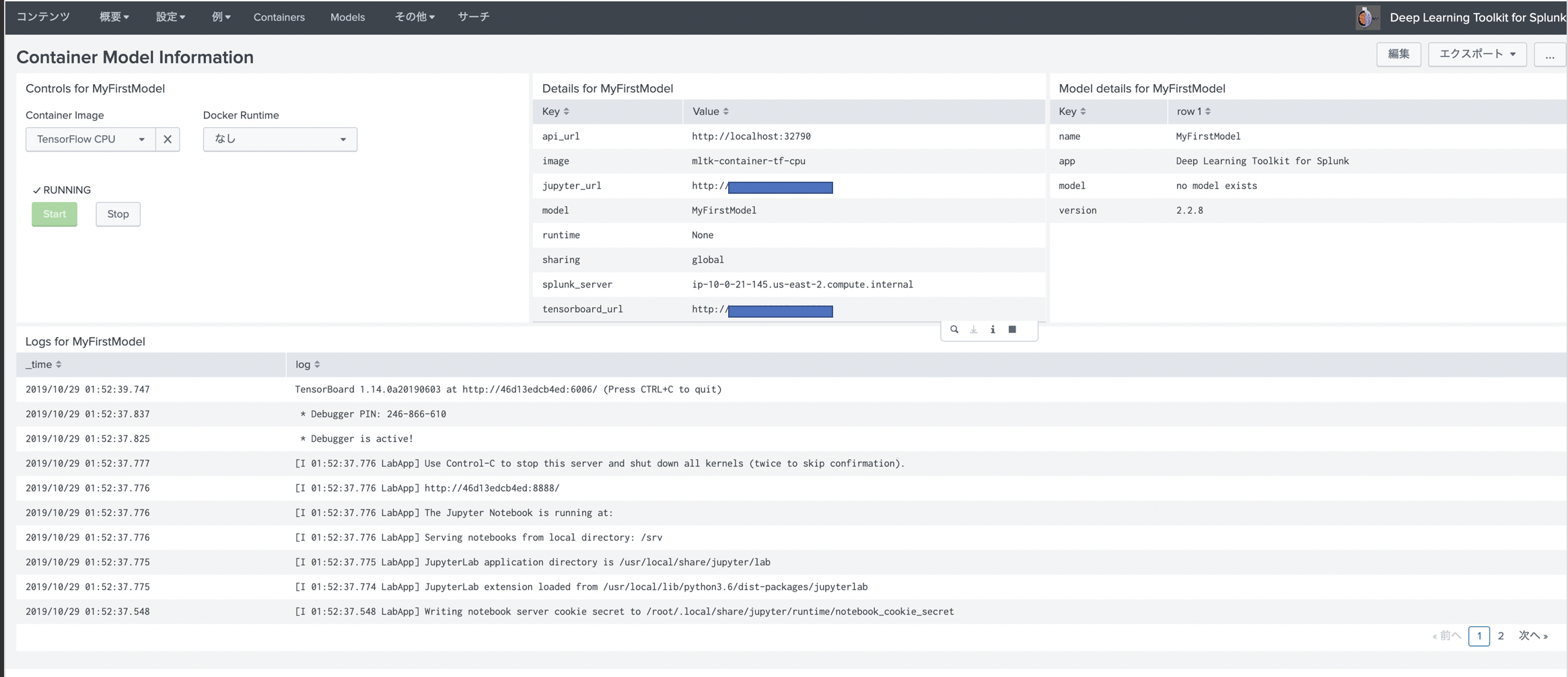
もちろん通常のSPLコマンドから実行できるので、今までどおりレポートやダッシュボード、アラートへの組み込みが可能になります。
最後に
非常にざっくりとでしたが DeepLearning Toolkit for Splunk を触ってみたのをまとめてみました。
モデル作成などに DLの知識が必要になるためハードルは高いですが、DLをかじったことがある方はpythonコードのまま理解できるので逆に扱いやすいのではないでしょうか?
またいいモデルができてしまえば、後は通常の Splunkの知識さえあれば実装ができます。データサイエンティストが苦労するデータ収集や前処理、そして最後の実装部分をSplunkに任せて、実際のモデル作成を jupyter notebookを使ってコーディング出来るため、いいところどりな気がします。
今後は、GPU環境を利用したり、NLPや Pytorch といった他のライブラリを活用したモデル・ユースケースをいつか触ってみたいと思います。