はじめに
KMeans自体は MLTKにあるのですが、データサイズが大きくなるとサーチヘッドのメモリ不足でエラーになることがあります(まずは設定をチェックしてね)。
DLTKを使うとサーチヘッドとは別のコンテナ環境で計算してくれるのである程度は問題解決できますが、さらにDaskを使うことでデータセットを分割して計算してくれるためもっと大量のデータでも取り扱えるようになります。
##Daskとは
こちらの記事を参考にさせていただきました。
https://qiita.com/simonritchie/items/e174f243bc03fb25462e
・ Pythonで並列処理・分散処理などを簡単に扱ってくれる。
・ データを部分的なかたまり単位(chunk/npartition)で処理してくれる
・ 既存のpandasなどを置き換えるものというよりも、拡張してくれるライブラリー
メモリ制限に引っ掛かったけど、Sparkを利用するまでではない、中間的なケースに当てはまりそう。
DLTKについて
今回はDLTKの使い方については解説しません。DLTKのセットアップや使い方についてはこちらの記事をご覧ください。
https://qiita.com/maroon/items/5a8b027631a674d6d8be
サンプルコード確認
それでは早速サンプルコードをみていきましょう。
最初はライブラリーのインポート. dask関連のライブラリーをインポートしております。
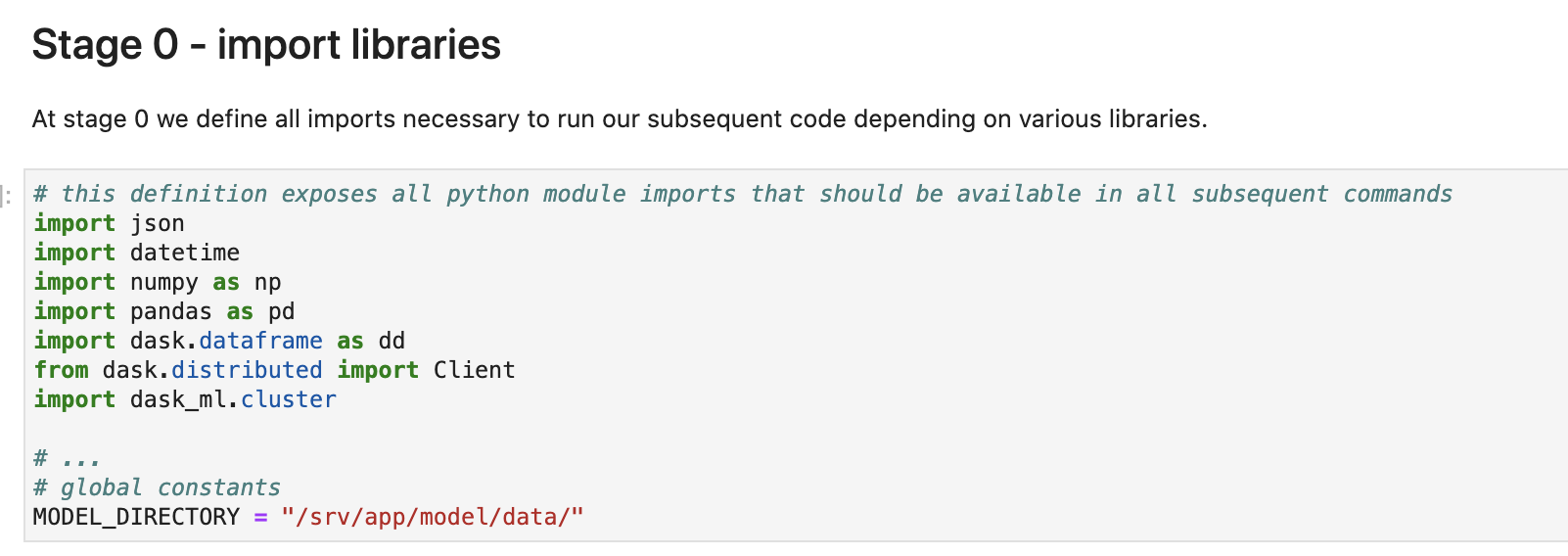
Stage1: データ取り込み
次にデータの取り込みです。Splunkで整形したデータを保存して取り込みます。
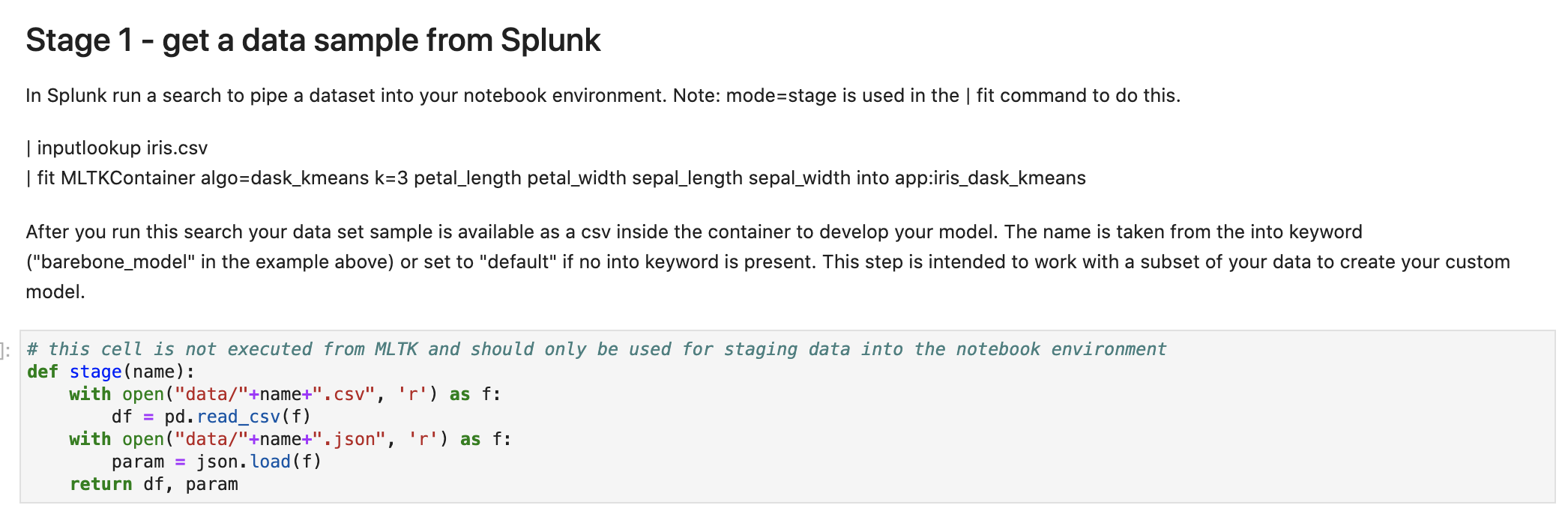
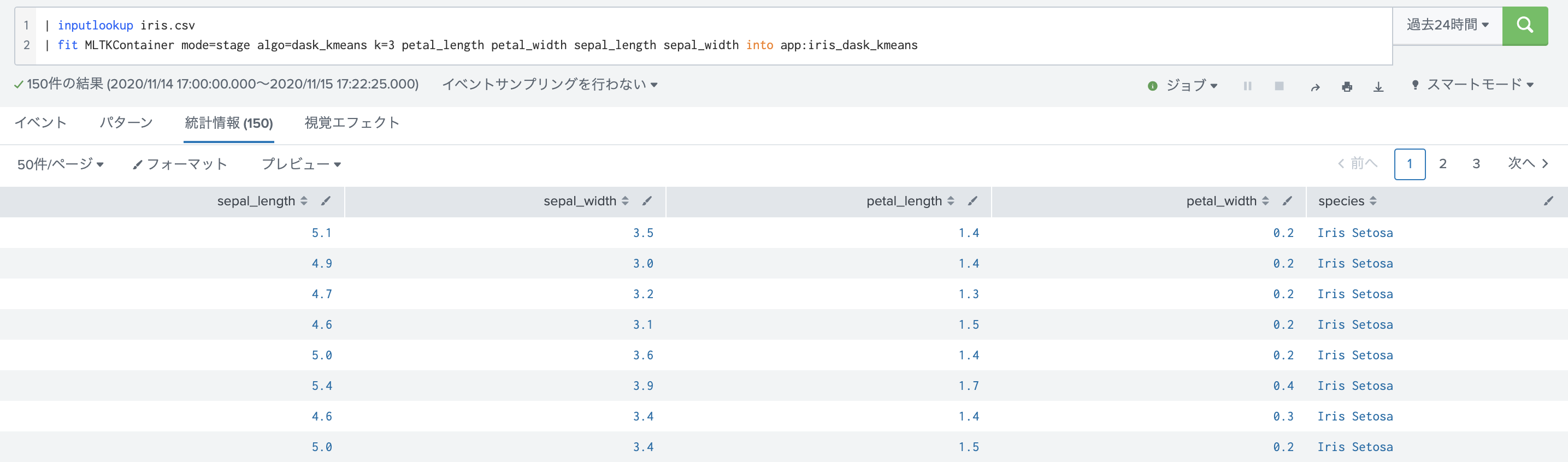
下の図はSplunk側で実行した結果です。
サンプルデータは、isisのデータセットを利用してます。
Stage2: 初期化
Daskのインスタンスを作成します。ここで複数のサーバ上に分散して実行する場合はClientを指定しますが、今回はローカルサーバ上で実行します。

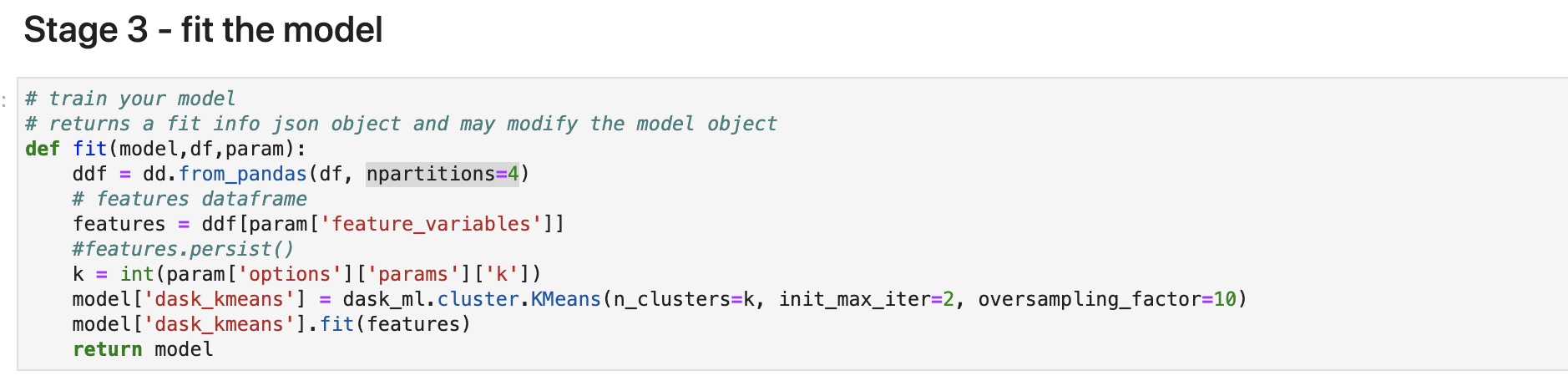
Stage3: 学習(fit)
学習を始めます。今回はデータセットを4つのpartition(chunk)に分割して、Splunkからの引数で KMeansの kの数を読みこみ、dask_ml のKMeansを使って計算します。
Stage4: 適用(apply)
学習済みのデータラベル計算して、DataFrameに変換して返します。

その他ステージ
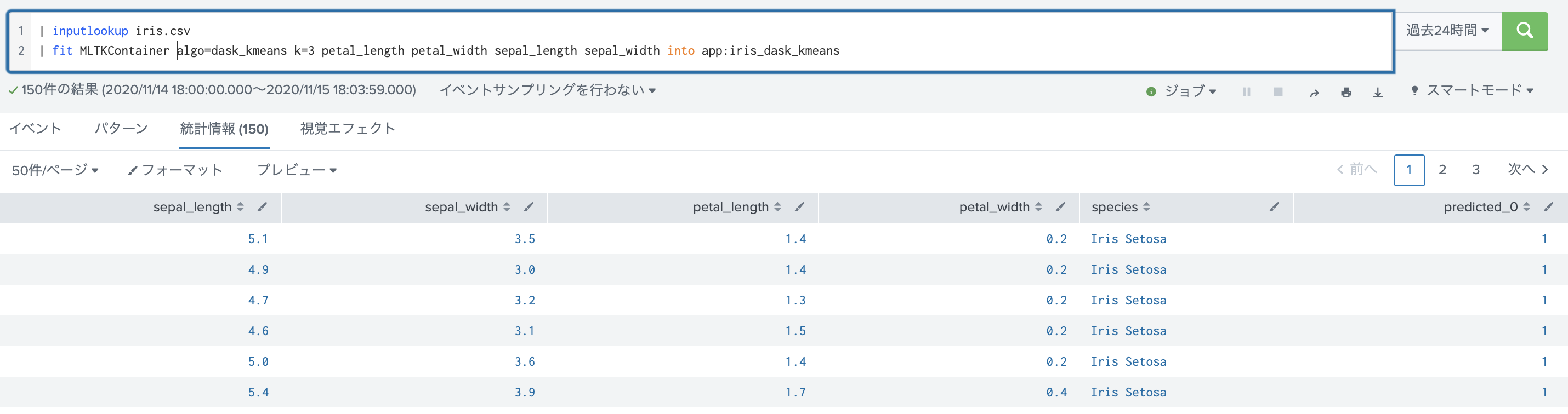
Splunkから呼び出してみる
クラスター番号が追加されているのがわかります。データセットのサイズを大きくして試してみたいです。。
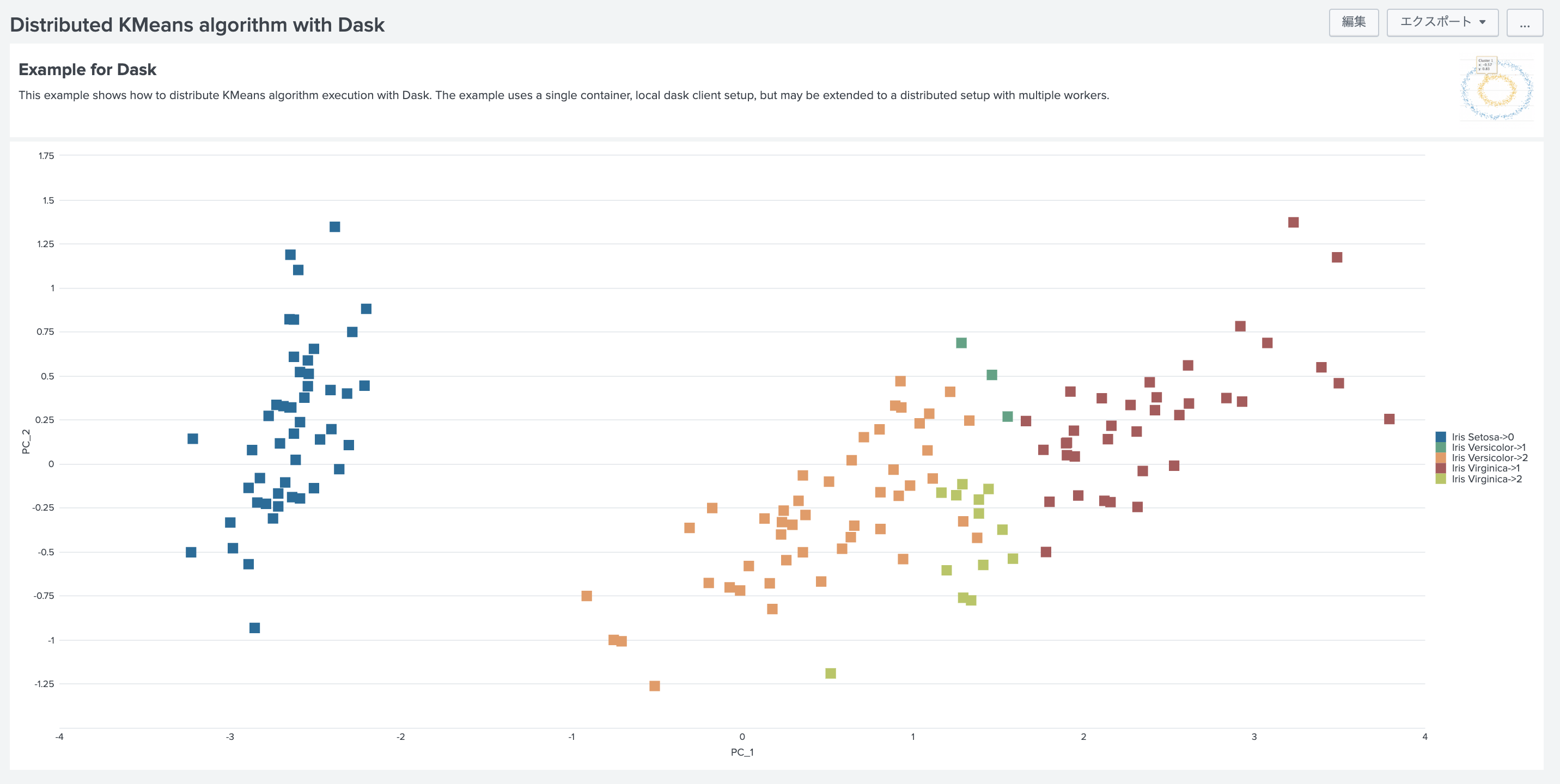
サンプルダッシュボードを確認
Splunk DLTKにはサンプルダッシュボードも用意されております。
特徴量をPCAで次元削減して 先ほどのクラスター結果をScatterplotで表示したものです。
まとめ
Dask MLでは、KMeans以外にも 回帰分析が使えたり、XGBoostや PyTorchなどとも連携できるようです。
https://ml.dask.org/
MLTKだとメモリ不足に陥るケースがあるので、このような機能が簡単に利用できるのはありがたいです。