はじめに
最近では AWS S3をベースとしたデータレイクを構築してデータをまとめているケースも多くあると思います。そこで今回はS3上のログをSplunkに取り込むまでをやってみたいと思います。いろいろな取り込み方法があるのですが、今回はとにかくシンプルかつ早い設定をテーマにやってみます。
##設定の流れ
大きく分けると AWS上の設定とSplunk上の設定の2つが必要になります。
AWS上の準備・設定
- AWS S3 Bucket の作成
- S3 上にデータをアップロード
- IAMユーザー作成 & ポリシー作成しユーザーへの権限付与
Splunk上の設定
4. APPの追加 (Add-on for AWS)
5. Configuration (IAM User追加)
6. Input設定
AWS上の設定
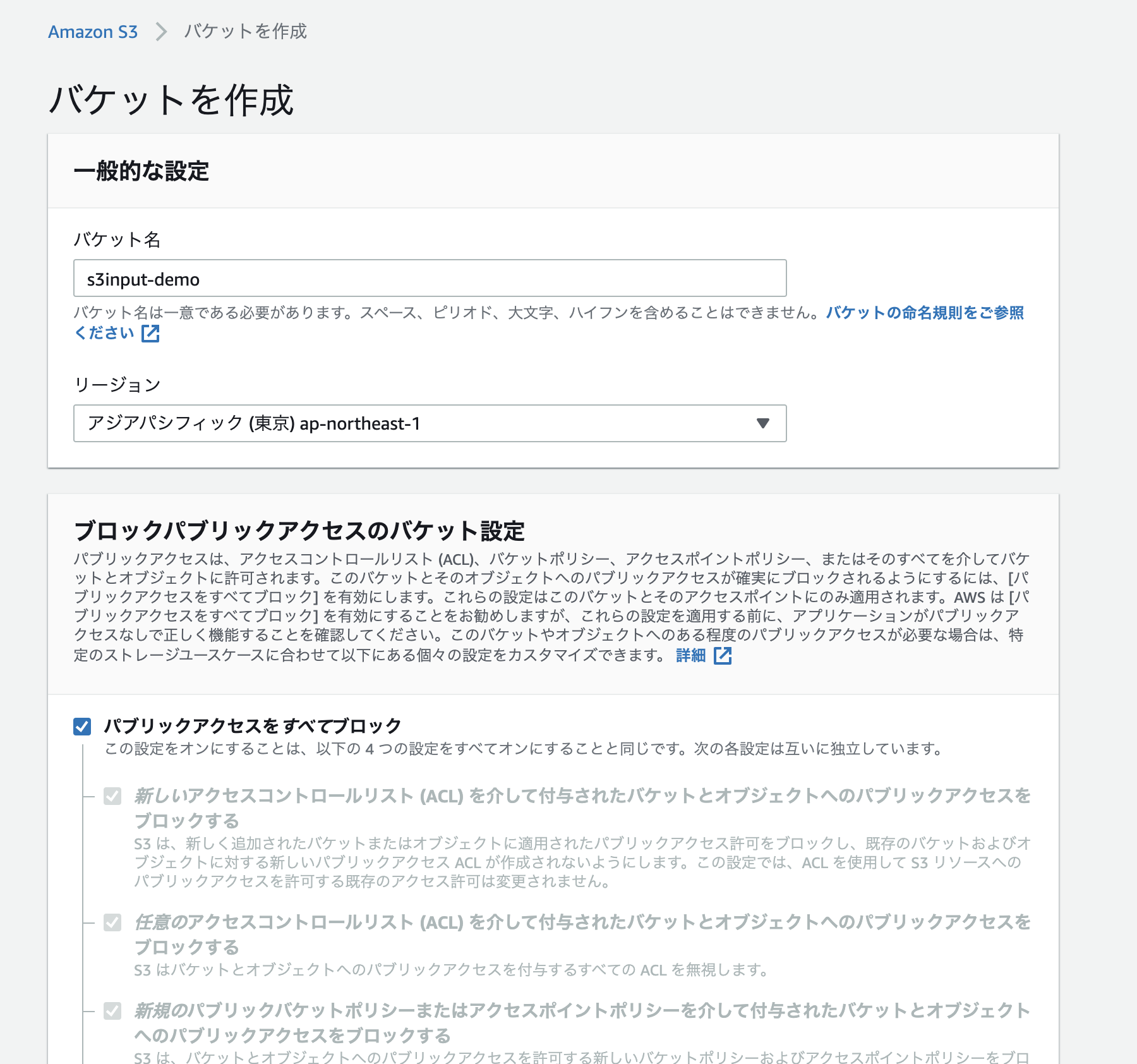
###1. AWS S3 Bucket の作成
まずは通常通り S3 Bucke を作成します。Publicアクセスはすべてブロックで大丈夫です。
###2.S3上にデータをアップロード
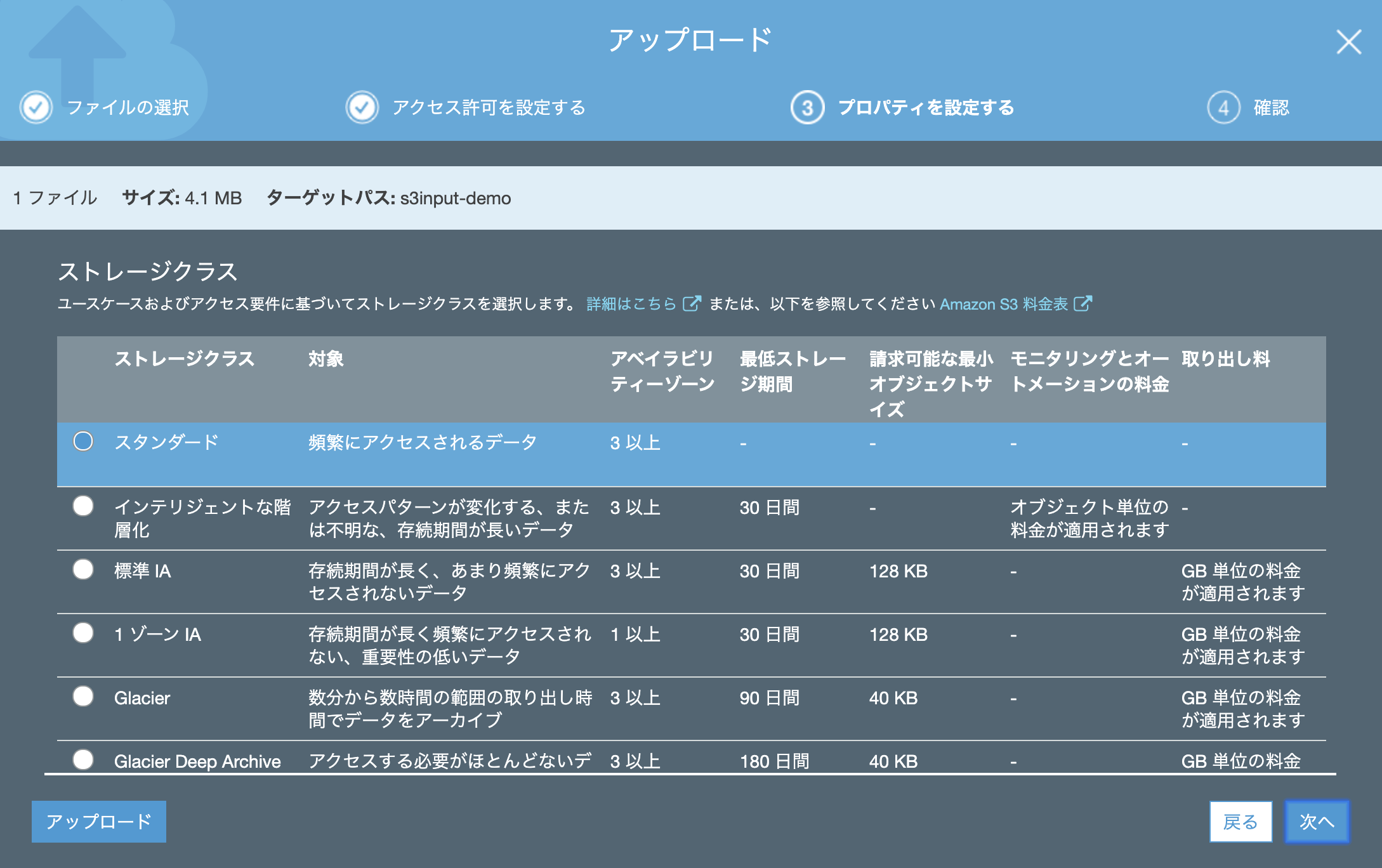
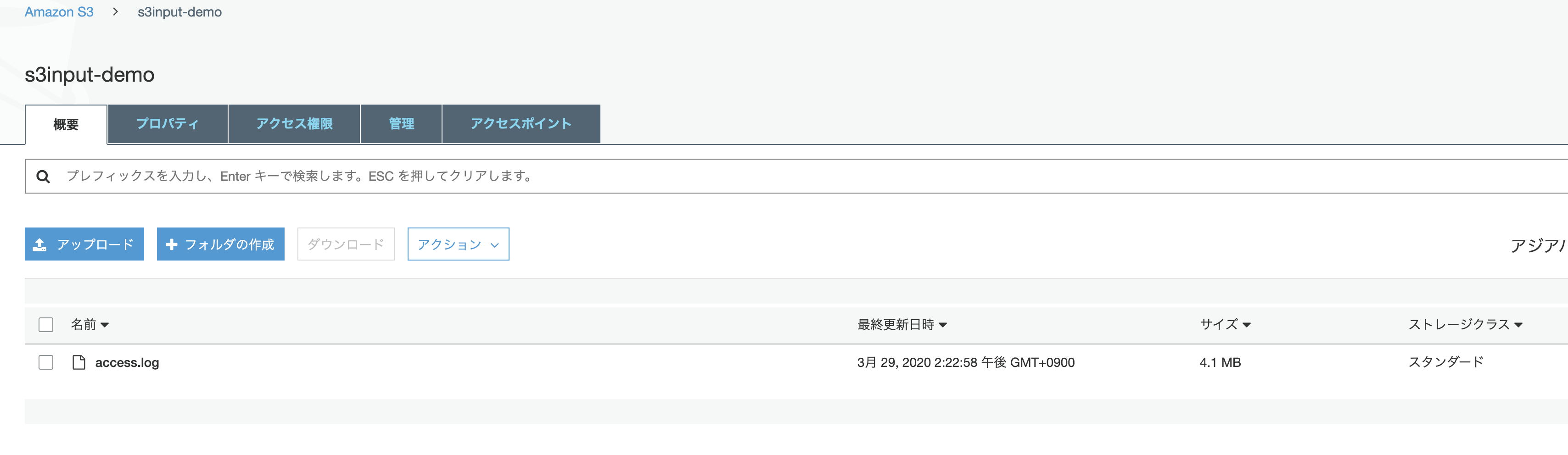
今回は Splunk tutorial data 内にある access.log をアップロードしてみます。
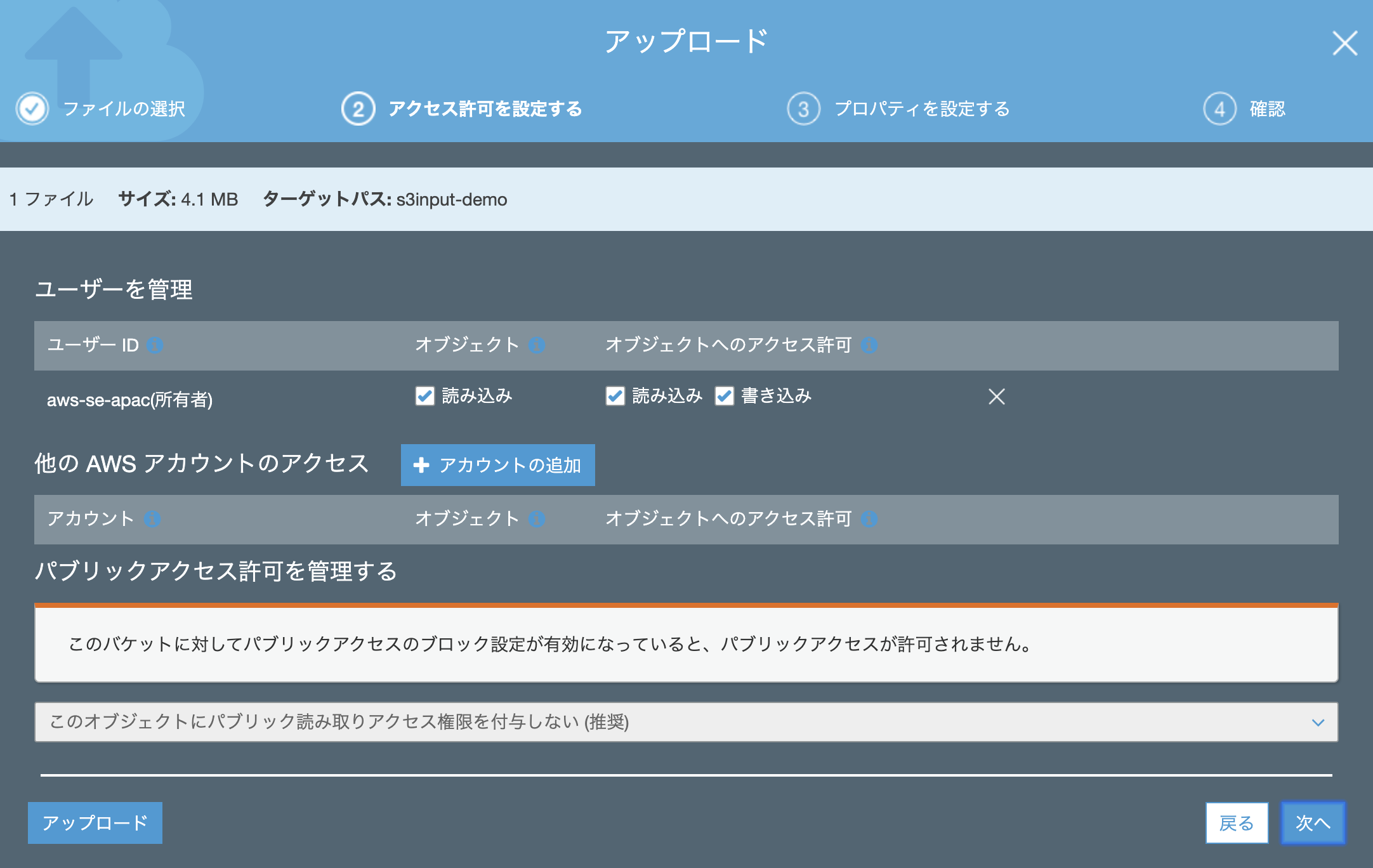
アクセス許可は特に追加する必要はありません。(デフォルトのままでOK)
プロパティも「スタンダード」でアップします。(他のクラスでも多分大丈夫かと)

###3. IAMユーザー作成
次に 外部からS3にアクセスできるようにユーザーと権限の設定をしていきます。まずはユーザー作成から。
[IAM]サービス -- [ユーザー」 -- [ユーザー追加]
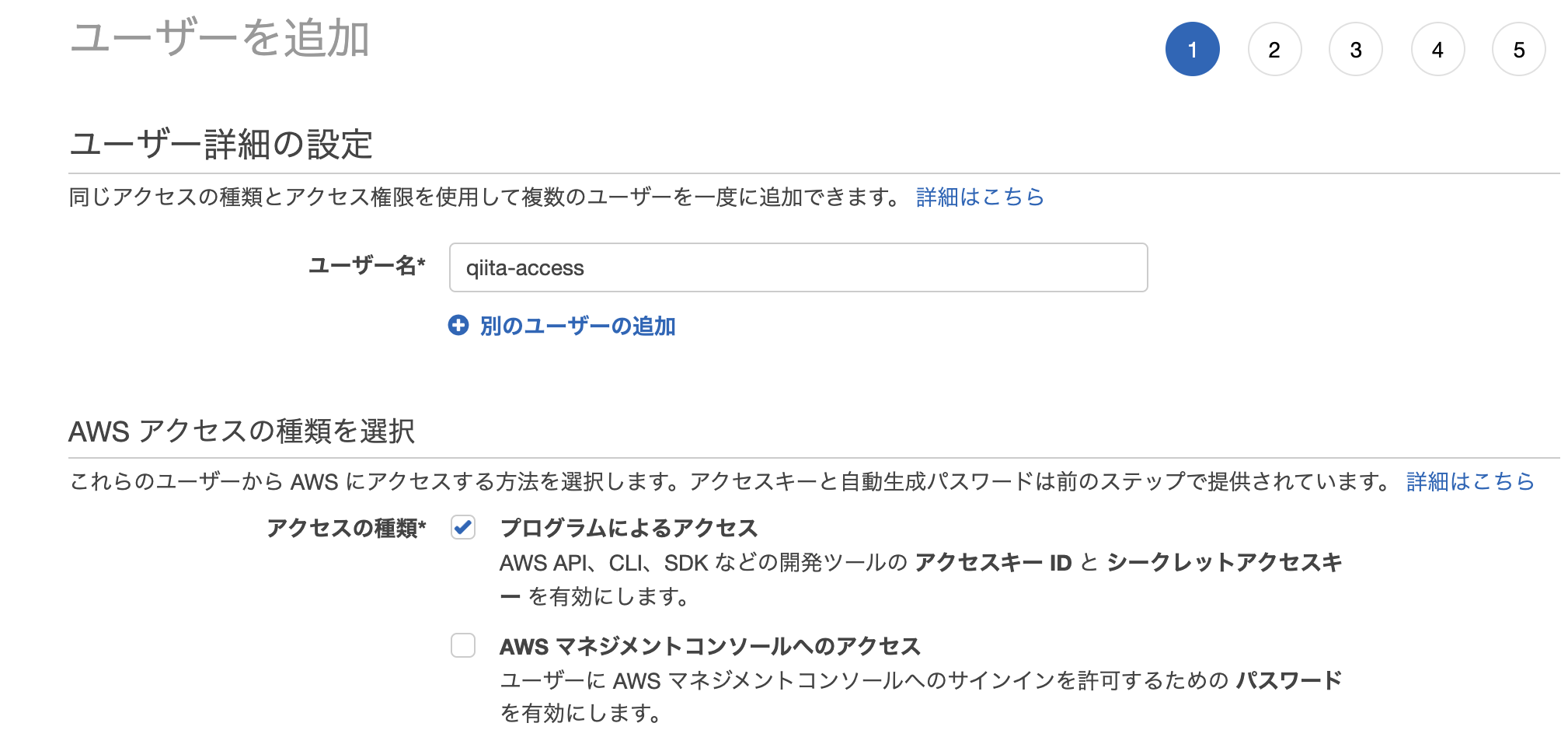
「プログラムによるアクセス」にチェックを入れるのを忘れずに!!
次にアクセス許可設定ですが、「既存のポリシーを直接アタッチ」をクリックして、「ポリシーの作成」をクリック
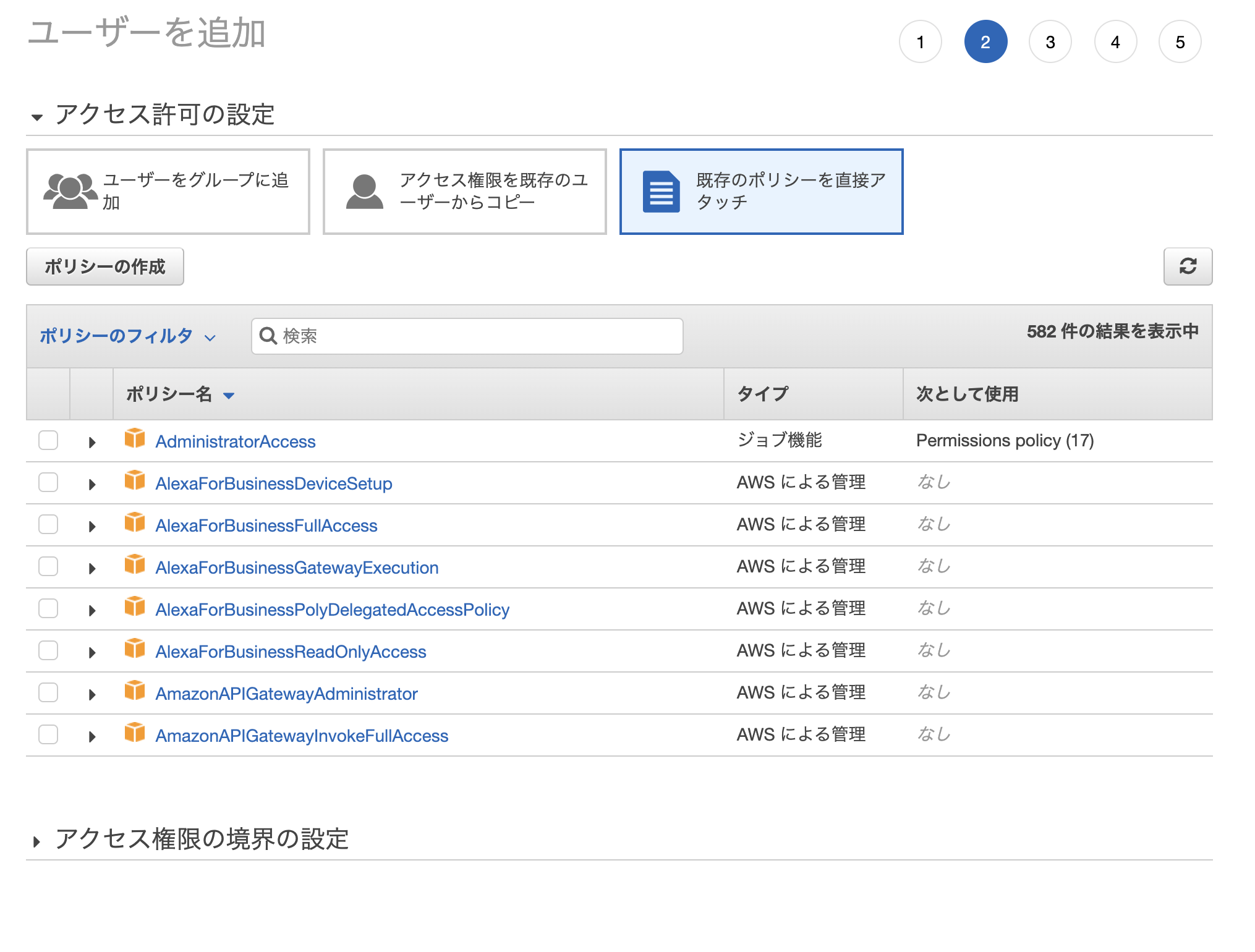
「ポリシー作成」 - [JSON] 設定画面にて以下のように上書き
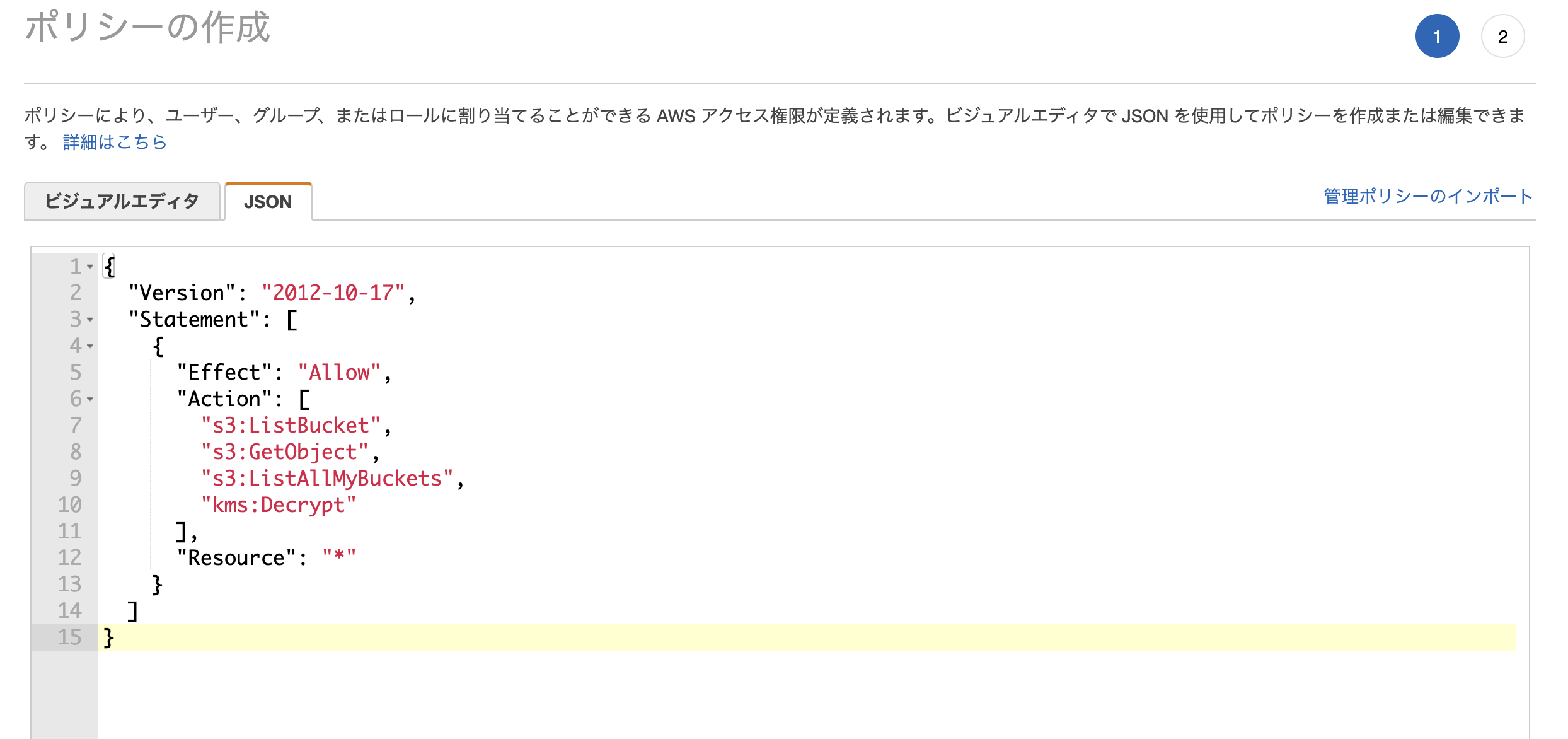
(下をコピペして使ってください)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:ListAllMyBuckets",
"kms:Decrypt"
],
"Resource": "*"
}
]
}
適当にポリシー名を作成して完成
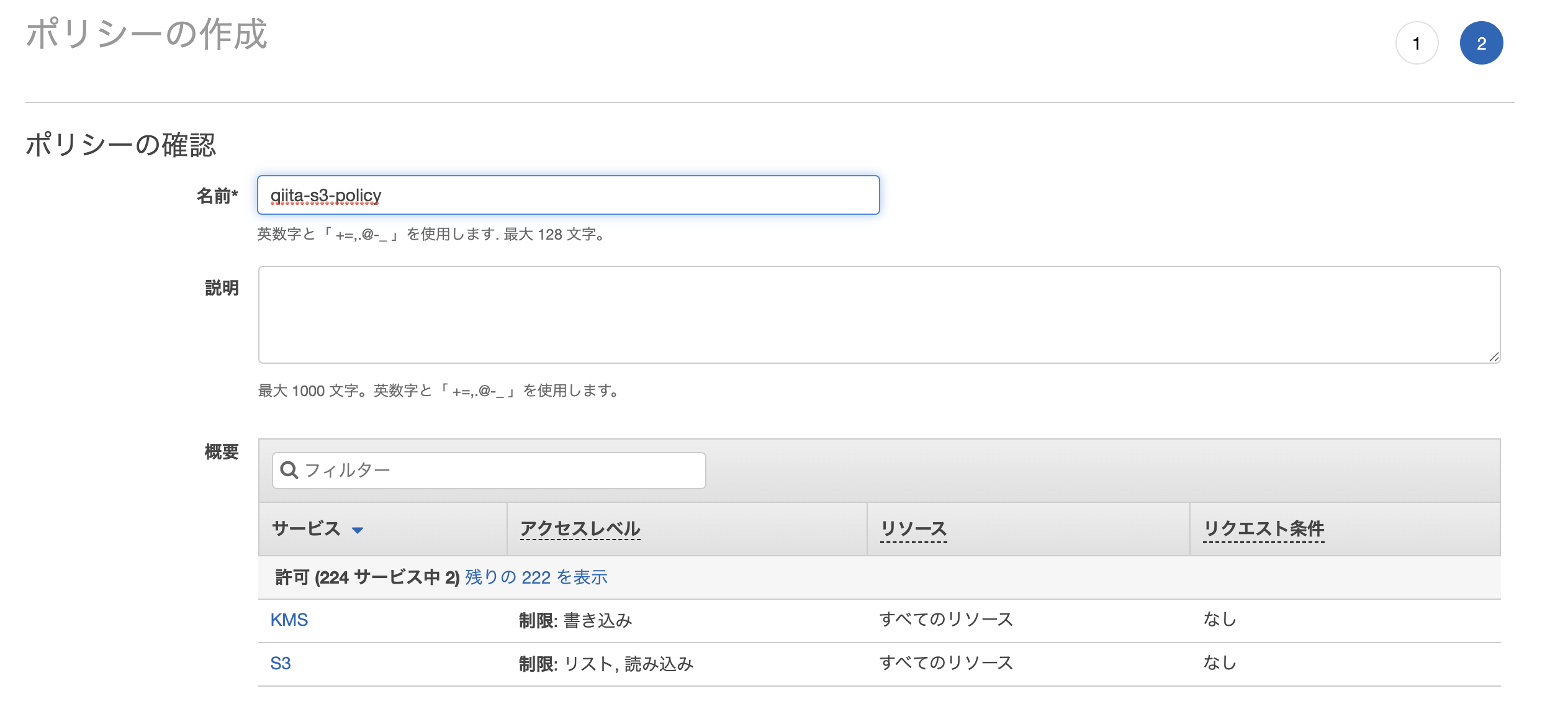
ポリシー追加画面に戻って、「更新」をしてから、作成したポリシーを追加する
タグは特に不要
ユーザー追加も不要
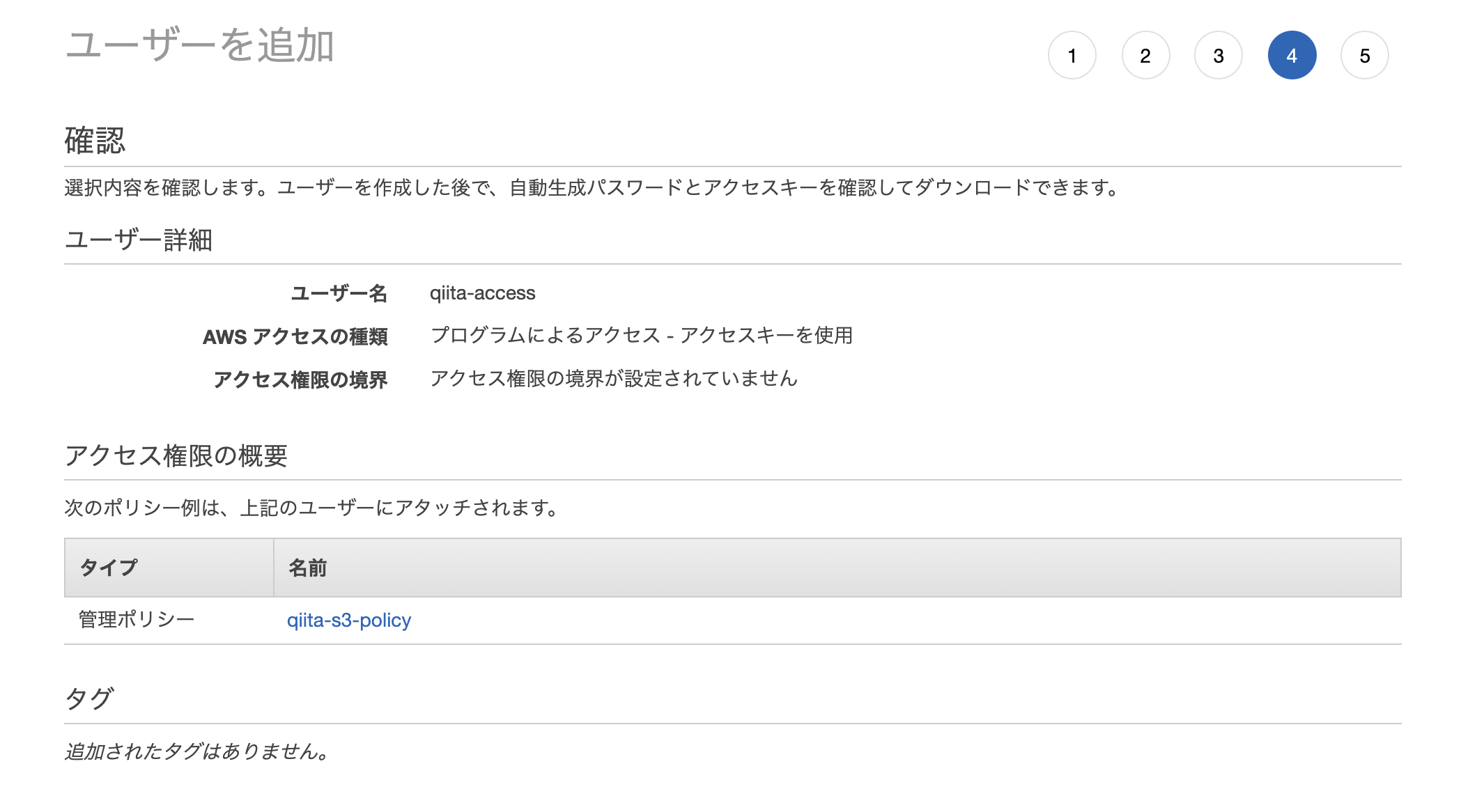
アクセスキーとシークレットアクセスキーは後で使うので大事に保存しておいてください。(csvをダウンロードしておく)
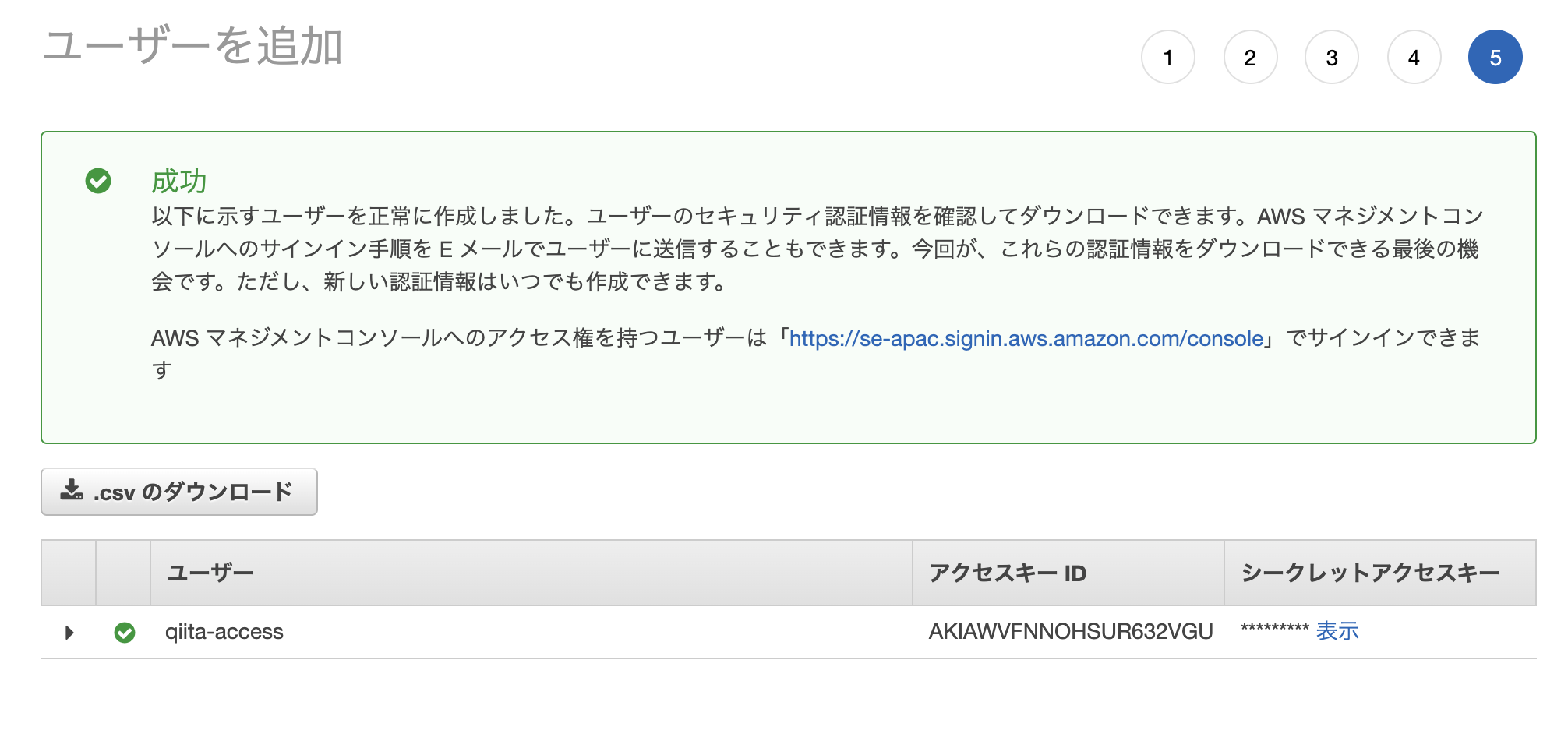
これで、AWS側の設定は終了です。
Splunk側の設定
4. APPの追加 (Add-on for AWS)
Splunk Add-On for AWS をSplunkにインストールします。
https://splunkbase.splunk.com/app/1876/
ここではインストール方法については割愛します。
5.Configuration (User追加)
Splunk Add-on for AWS アプリを開き、 [Configuration] - [Account] に移動し、追加ボタンをクリック
3.で作成した AWS のユーザー (qiita-access)のアクセスキーとシークレットアクセスキーを入力
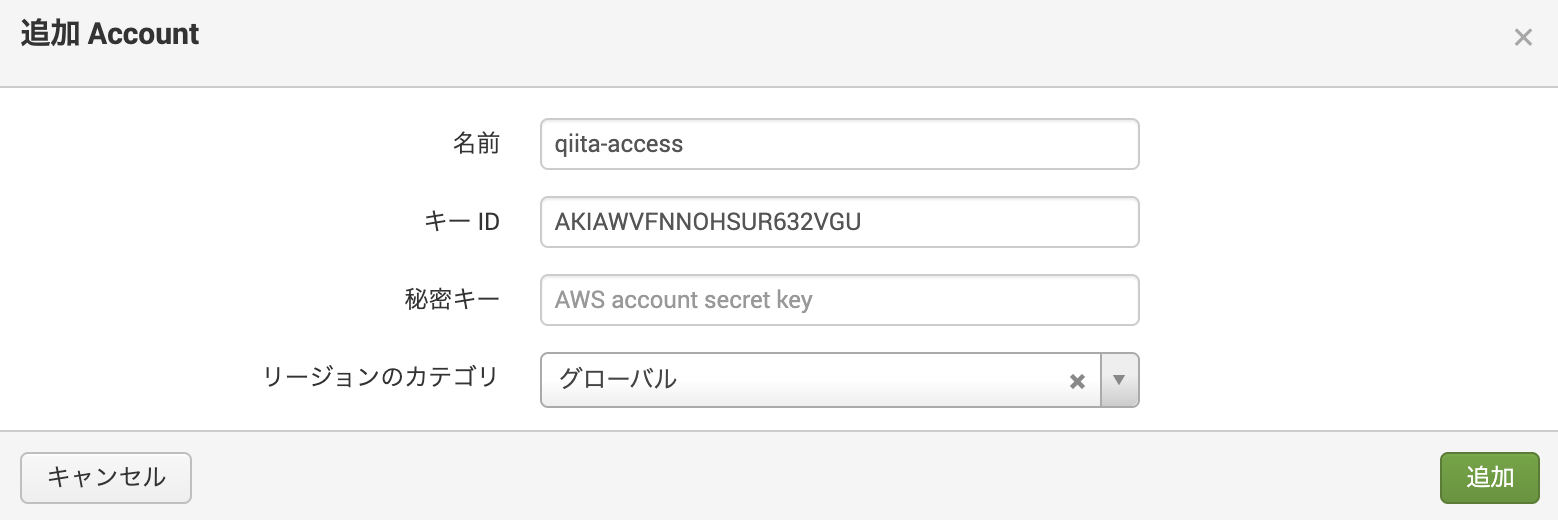
こんな感じでユーザーが追加されれば OK!

6. Input設定
それではおまたせしました。S3上のデータを取り込みましょう!! (イエーイ)
右上の「設定」ー「データ入力」 をクリック
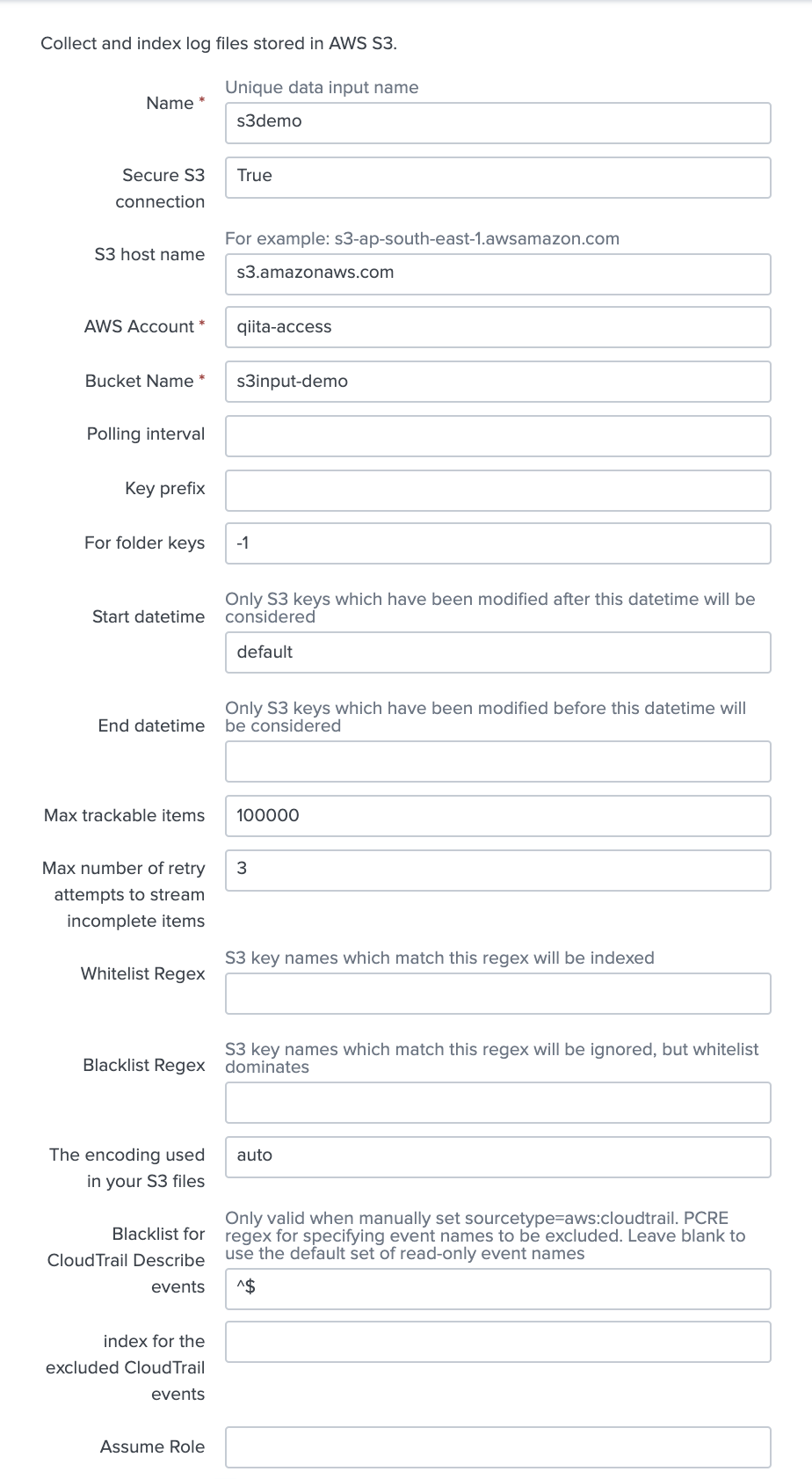
[AWS S3] という項目があるので、 [add new] で追加します。

必須記入項目である以下の3つを入力。 (必要に応じて他の項目を入力してください)
・ Name : s3demo
・ AWS Account : qiita-access (先ほど追加したユーザー)
・ Bucket Name : s3input-demo (先ほど作成した S3 Bucket Name)
一番下の「more settings」チェックを入れて追加入力項目を編集します。
- Interval : 30 (default) <-- データを取りに行く Polling time
- Set Sourcetype : From list <-- データのソースタイプに併せて選択してください。今回はTutorial DataでSourcetypeがわかっているため access_combined を指定します。
- Host: aws_s3 <-- データのメタ情報として追加するHost名。今回は適当に入力しておきます。
- Index : aws-s3 <-- 今回S3上のデータをSplunk内のどのIndex に取り込むか。 予め aws-s3 という Indexを作ってあるためそれを指定します。
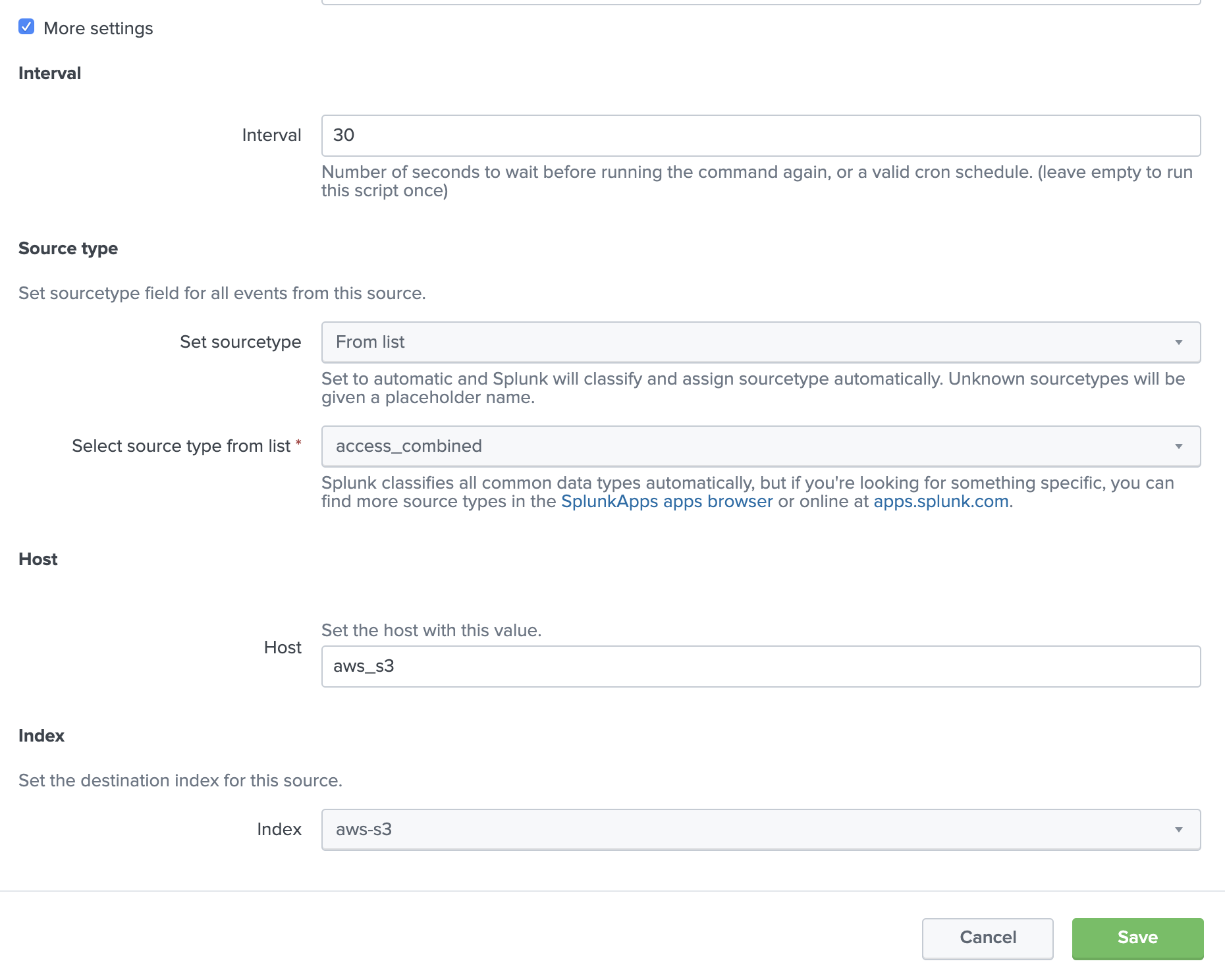
Splunk の設定も以上です。
データの確認
それでは、データが取り込めているか確認してみましょう!
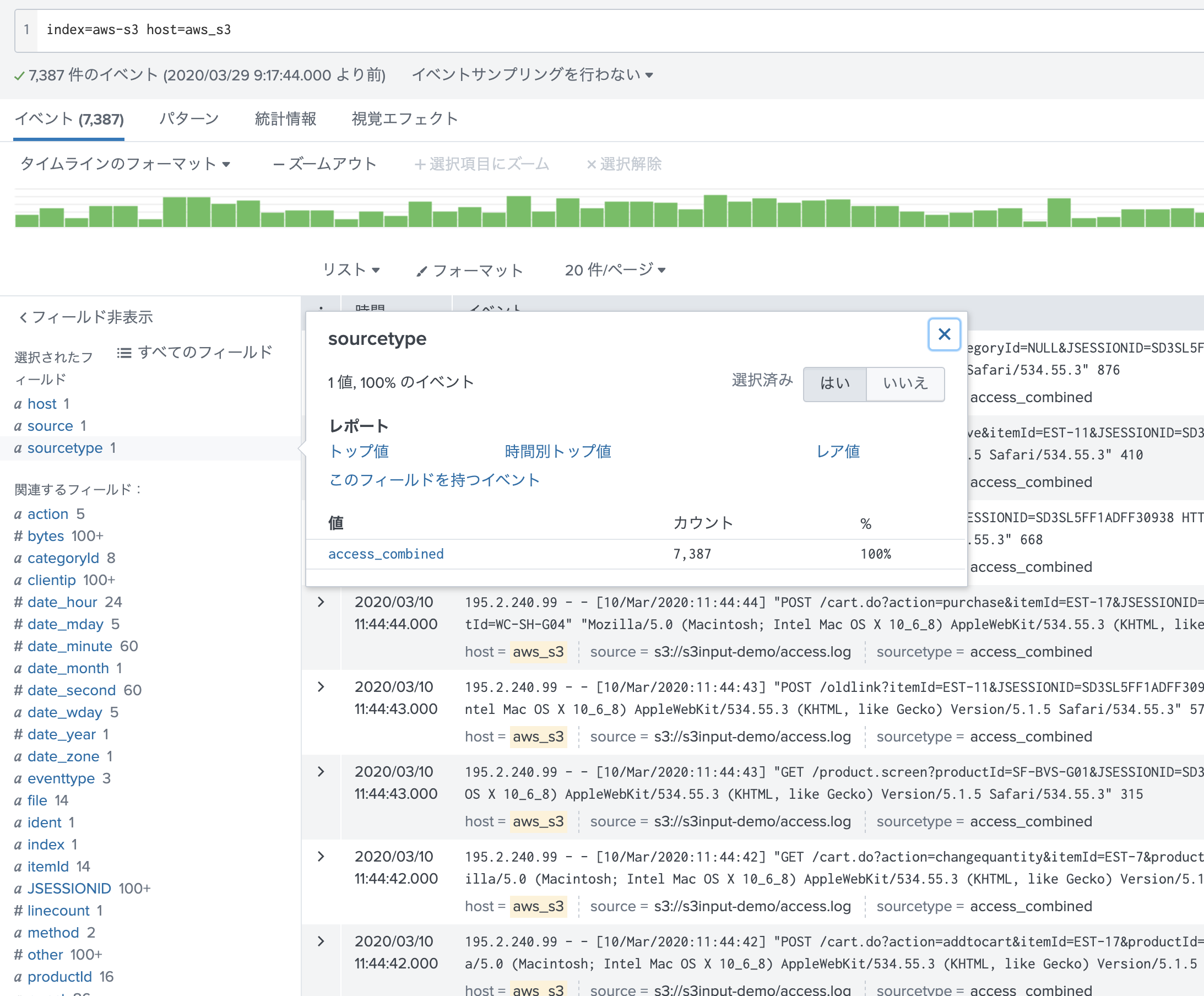
ちゃんと、ソースタイプを理解して Field抽出もできております。
もし、データ取り込みがうまくいかない場合は、 Add-Onアプリの「Health Check」 - [S3 Inputs Health Details]からエラーを確認してみてください。
こんな感じでエラー情報が確認できます。(メッセージ内容は今回の取り込みのものではありません)

##その他
ドキュメントに書かれていた利用時の追加情報です。
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web
S3内の特定のデータのみ抽出したい場合
S3 Bucket単位で設定可能ですが、同じS3 Bucket内に様々なデータがある場合、全部を取り込むのはコストがかかるのでやりたくないですよね。
そのような場合に、特定のファイルのみ取り込むような設定ができます。
Input設定の箇所で、オプション項目が沢山ありましたが、そこでファイル名の Prefix や 正規表現による White / Black List設定、Time Rangeによる設定などが可能です。詳細はこちらのマニュアルをご覧ください。
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web
圧縮ファイルの対応
データ入力では、以下の圧縮形式をサポートしています。
ZIP、GZIP、TAR、またはTAR.GZ形式の単一ファイル
ZIP、TAR、またはTAR.GZ形式のフォルダを含む、または含まない複数のファイル
https://docs.splunk.com/Documentation/AddOns/released/AWS/S3#Configure_a_Generic_S3_input_using_Splunk_Web
大量のデータ取り込みについて
S3 バケットに非常に多くのファイルが含まれている場合、1 つの S3 バケットに対して複数の S3 入力を設定することでパフォーマンスを向上させることができます。その際に同じファイルを重複して取り込まないように、各入力設定で取り込むファイルを分類しながら取り込む必要があります。また、1つの入力設定で1つのソースタイプしか指定できないため、データの種類が複数ある場合は、別の入力設定にした方が良さそうです。
Splunkでは、データ量が多いPull型取得の場合は SQSを使った取り込みを推奨しております。そうすることでQueueにデータを貯める事ができ、Add-On側を増やす事でスケールできるのと、再送してくれるためデータの信頼性が増します。また Kinesis Firehoseや Lamdaを使った Push型のデータ取り込みも推奨しております。
S3 上の古いデータについて
ベストプラクティスとして、S3バケットのコンテンツを積極的に収集する必要がなくなったらアーカイブしましょう。
AWSでは、入力がバケットをスキャンして新しいファイルや変更されたファイルを探すために使用するリストキーのAPIコールに課金されるため、古いS3キーを別のバケットやストレージタイプにアーカイブすることでコストを削減し、パフォーマンスを向上させることができます。
取り込みデータに関する注意点
S3 データ入力は、頻繁に変更されるファイルを読み込むことを目的としていません。ファイルがインデックス化された後に変更された場合、Splunk はそのファイルを再度インデックス化してしまい、データが重複してしまいます。
key/blacklist/whitelist オプションを使用して、後で変更されないことがわかっているファイルのみをインデックス化するよう設定してください。
最後に
今回はなるべくシンプルにということで、直接S3へPollingして取り込む方法をご紹介しました。一方で大量のデータを捌くためにはSplunkのInputを増やしても、データを重複せずに取れるようにするために、SQSを用いた構成が推奨されております。こちらの構成については次回チャレンジしたいと思います。
参考情報
Splunk Add-On for AWS Documents
https://docs.splunk.com/Documentation/AddOns/released/AWS/Description
取り込みに必要な IAM Policy Permission
https://docs.splunk.com/Documentation/AddOns/released/AWS/ConfigureAWSpermissions#Configure_S3_permissions
Sizing Information
https://docs.splunk.com/Documentation/AddOns/released/AWS/Sizingandcost