Data Augmentationとは
AIの学習データに対して「変換」を施すことでデータを増やす手法をデータ拡張(Data Augmentation)といいます。
通常、画像処理分野では活発に使われていますけど、NLPでは単語一つだけ変わっても文章の意味が全く変わるため、データ拡張技法を活用するのは簡単ではないです。
例えば、下の図で猫の写真をグレースケールしたり裏返しても依然として猫の写真ですが、「This is good」という自然言語は順番や単語を一つ変えただけなのに、意味が完全に変わることが確認できます。

2019年EMNLPで発表されたEDA:Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks論文は、その難しい課題をやり遂げました。
主な内容は自然言語処理で簡単に思い浮かぶデータ拡張技術が実際に性能向上に有意義な影響があるということです。
EDA以前に提案されていた有名な自然言語処理のデータ拡張方法には代表的に
- 文章をフランス語に翻訳し、再び英語に翻訳して新しいデータを得る方法 : QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
- データにノイズを軽く追加する方法 : Data Noising as Smoothing in Neural Network Language Models
- 単語を類義語に置き換える言語モデル : Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations
がありました。
そして、このような方法は有効だったが、コストパフォーマンスが悪くて、あまり使いませんでした。そこで、この論文ではEDAと呼ぶ普遍的なデータ拡張方法を紹介し、本人たちはデータ拡張のためのテキスト編集技法を包括的に探求した最初の研究者だと紹介します。
EDAを5つのベンチマークデータセットを通じて評価し、どれだけ性能向上を成し遂げたか、特に少量のデータセットにどれだけ役立つかを提示します。
Easy Data Augmentation
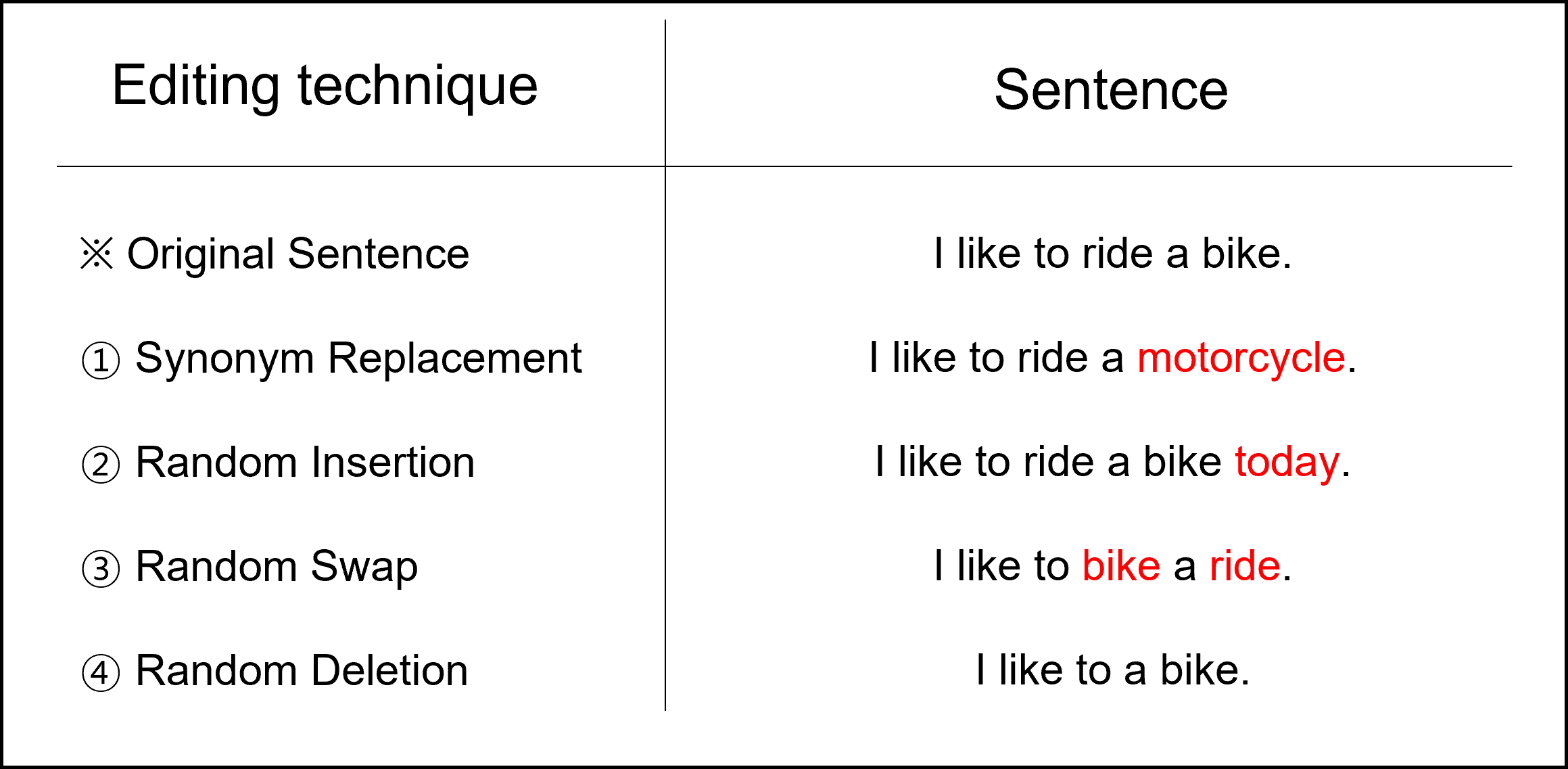
Easy Data Augmentation(EDA)の技法には以下の4つの方法があります。
- 類義語に交替(Synonym Replacement, SR):文章からランダムにstop wordsではなくn個の単語を選んで任意に選択した類義語の一つに変える方法。
- ランダム挿入(Random Insertion, RI):文章内でstop wordsではない単語からランダムに選択した単語の類義語を任意に定める。そして、類義語を文章内の任意の位置に入れることをn回繰り返す。
- ランダム交換(Random Swap, RS):ランダムに文章内で二つの単語を選択し、位置を変える。これをn回繰り返す。
- ランダム削除(Random Deletion, RD):確率pを通じて文章内にある各単語を無作為に削除する。
長い文章は短い文章より単語が多いため、元のラベルを維持しながらノイズに相対的に影響を受けません。代わりに公式$n = \alpha l$と共に文章の長さ$l$とを基準にSR、RI、RSに対して変わった単語の数$n$を変化します。公式$n = \alpha l$で$\alpha$は単語の百分率が変更されたことを示すパラメータを意味します。(RDの場合は$\alpha=p$です。)
そして、それぞれの元の文章に対して$n_{aug}$個の文章を作ります。下の表は、EDAを利用して作られた文章の例です。
Experimental Setup
- SST-2, CR, SUBJ, TREC, PCの5つのベンチマークデータセットを利用してテキスト分類を進める。
- EDAがより小さなデータセットに役立つと仮定し、全体データのランダム部分集合を選択して、$N_{train}$={500, 2,000, 5,000, all avalilable data}の4つの部分集合でテストを行う。
- 分類モデルにはLSTM-RNNとCNNを使用。
Result
EDAを5つのベンチマークデータからLSTM-RNN(RNN)とCNNを利用してテストし、5つのランダムシードから出た結果の平均を出しました。
データセットサイズによる性能変化
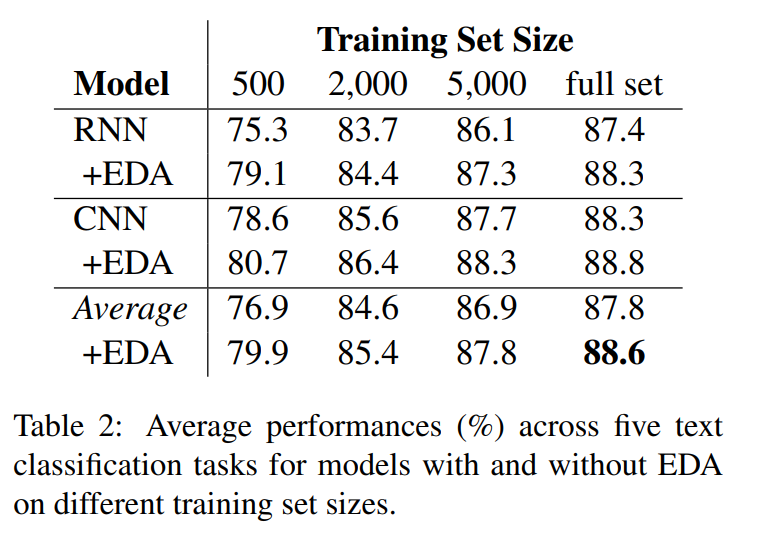
多様な学習データサイズに対して5つのデータセットにわたってEDA使用、未使用に分けてCNNとRNNモデルで検証しました。
性能の平均はTable2に作成されています。平均的にすべてのデータセットを使用する場合は0.8%の正解率(Accuracy)向上が、$N_{train} = 500$の場合は3.0%の正解率向上がありました。
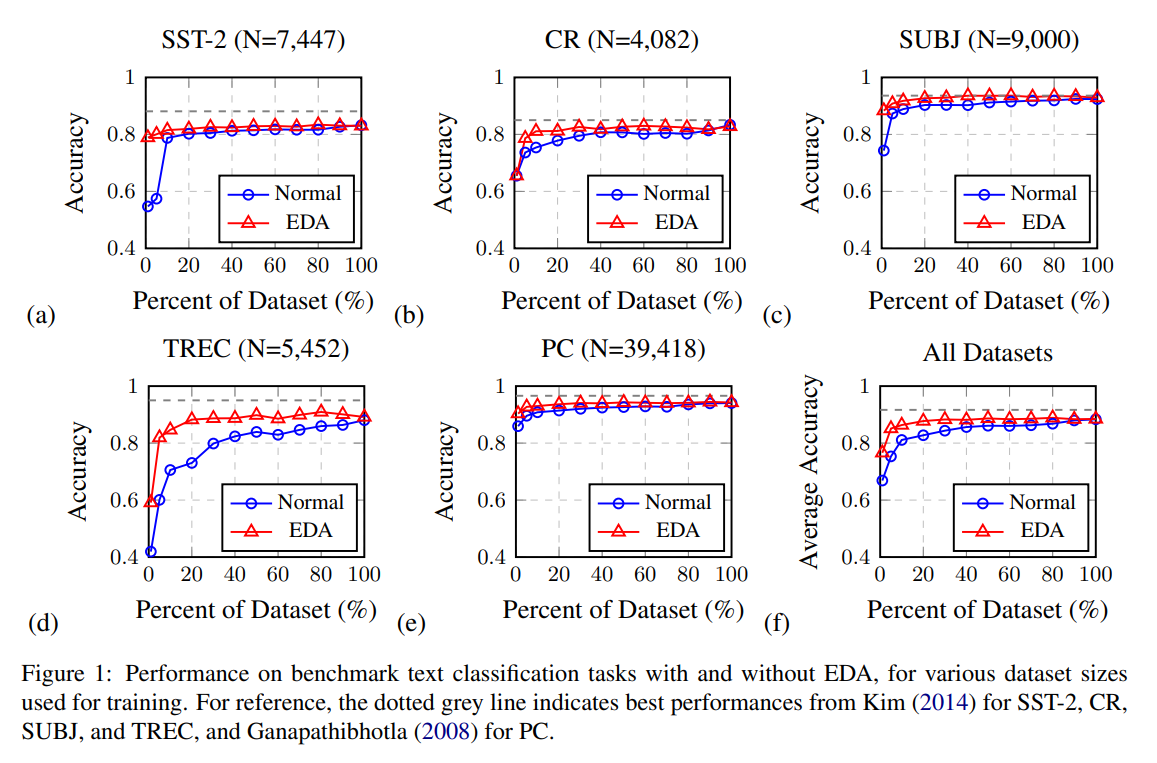
グラフを見れば分かりますが、主に0~10%の差が大きいです。
過学習は、小さなデータセットで学習するときにひどくなる傾向があります。それでデータセットを何パーセント使いながら、EDAを使用した時に正解率がどれだけ上昇するかをグラフで示しました。
予想通り、パーセントが低いほどEDAで増やしたデータセットとの正解率の差が大きくなり、パーセントが高いほどその差が少なくなります。
EDAは既存ラベルを保存しているのか?
データ拡張において最も重要な部分です。データセットを増やしたのにラベルが毀損されると(既存のラベルと値が異なる場合)、それは役に立たないデータセットだからです。
まず、データ拡張なしにPC分類データセット(Pro-Con dataset)をRNNで学習します。次に、EDAを利用して1つの文章当たり9つの新しい文章を作ります。このように作られた文章を元の文章とRNNで学習し、最後のレイヤーから結果値を出力します。この値にt-SNEを適用し、2Dグラフで示したものが下のFigure 2です。

EDAで拡張された文章がほとんど元の文章のラベルを保存している!
つまり、拡張された文章に対するその結果の潜在的な空間表現が元の文章空間表現を密接に取り囲んでいることが分かりました。
Ablation Study: EDA Decomposed
Ablation Study : 手法の中からある条件だけを抜くことで,その要素の重要さについて考察する実験
EDAの各効果を確認するためにAblation Studyを行いました。SRは以前からデータ拡張に使われる方法でしたが、他の3つのEDA技法はまだ探求されたことがありませんでした。そのため、各EDA技法を分離してテストを行い、表に示したものが下のFigure3です。

結果は、4つの方法すべてが性能向上に大きく貢献しました。
SRは$\alpha$が小さいと性能向上に大きく役立ったのですが、$\alpha$が大きいと性能がむしろ落ちました。単語を変えすぎると、文章の意味が変わるからです。
RIは$\alpha$の値が大きくなるほど性能が安定的に向上しました。文章内にある元の単語とその順序が維持されるからです。
RSは$\alpha \le 0.2$では高い性能向上がありましたが、$\alpha \ge 0.3$からは性能が落ちました。多くの位置交換を行うことは、文章全体の順序を変えたのと同じだからです。
RDは$\alpha$が小さいと高い性能向上がありましたが、たまに$\alpha$が高い時に性能低下がありました。文章内の単語が半分以上削除されると、文章の意味が変わるからです。
結果的にすべてのEDA方法は分類モデルの性能を確実に向上させ、$\alpha=0.1$の時が最も性能が良かったです。(sweet spot)
どれだけデータを拡張するか
では、一文章当たりどれくらい拡張すればいいでしょうか?下のFigure4は文章当たり{1, 2, 4, 8, 16, 32}個だけ拡張した時の結果を示しています。
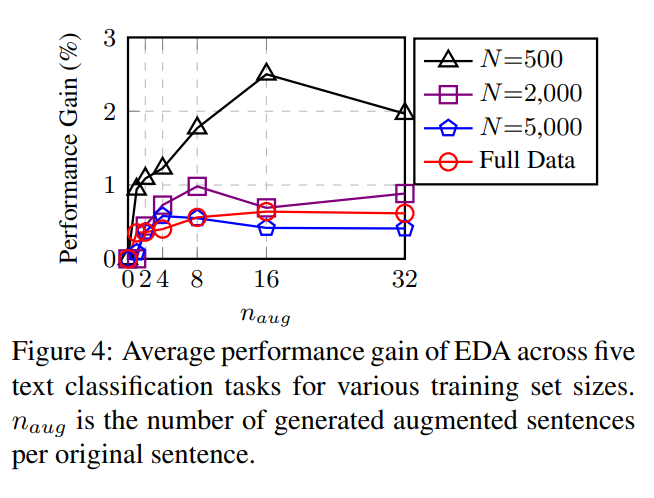
データセットのサイズが小さい場合は、過学習が発生する確率が高かったため、文章をたくさん生成するとより大きな性能向上がありました。
データセットのサイズが大きい場合は、データ拡張をしなくてもモデルが適切に一般化される傾向があるため、元の文章あたり4つ以上の拡張データを追加することは役に立ちませんでした。
すでにデータが十分だから···
この結果に基づいて、論文はパラメータを次のように推奨しました。

Discussion and Limitations
この論文は、今後の調査の基準となり得る一連の簡単な方法を導入することにより、自然言語処理の標準化されたデータ拡張手法の不足を解消することを目的としています。
ディープラーニングで自然言語処理研究の割合が最近大幅に増え、研究者たちがまもなく使いやすいより高い性能のデータ拡張技術が出てくると期待しています。最近、多くのNLP研究が複雑なニューラルネットワークモデルを作成することに集中していますが、この研究は正反対にアプローチしました。
論文の著者は、EDAが現在や未来にNLPのためのデータ拡張技法になるとは予想していませんが、代わりに普遍的または自然言語データ拡張に対する新しいアプローチにインスピレーションを与えることを希望していると言います。
限界について話してみると、データが十分なときに性能が制限される可能性があるということです。実験した5つのベンチマークデータセットですべてのデータを使用してEDAを適用した場合、正解率が1%上がったそうです。
そして小さなデータセットでより良い性能を得ることは確かですが、BERTのようなPre-trained Modelを使用する場合には改善効果がほとんどありませんでした。
Conclusion
簡単なデータ拡張方法は、テキスト分類に大いに役立ちます。もちろん「必ずうまくいく!」ではありませんが、小規模データセットに関する学習を行う際の性能を実質的に向上させ、オーバーフィッティングを減少させます。
EDA活用事例
EDAが簡単な方法であるだけに、英語以外の言語にも応用されています。