Easy Data Augmentationとは
こちらの論文で提案されている、文章のかさ増し手法です。
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
似たようなデータを生成してデータをかさ増しすることでモデルの精度向上を図るAugmentationは画像認識などではお馴染みですが、その自然言語版となります。
具体的には、下記の4つの手法を用いて文章を変換することで類似する文章を生成します。
| 手法 | 概要|
|:---------|:-------|:-------:|
| Synonym replacement| ランダムに単語を同義語でn個置き換える(ストップワードは除く)|
| Random deletion| ランダムに単語を同義語で確率pで削除する |
| Random swap| ランダムに単語の場所をn回入れ替える|
| Random insertion| 文中に出現する単語の同義語をランダムにn個挿入|
このEasy Data Augmentationをgitで公開されている英語版の実装コードをベースに、日本語版を実装してみました。
【参考コード】
github eda_nlp
【参考記事】
日本語自然言語処理のData Augmentation
自然言語処理のData Augmentation手法 (Easy Data Augmentation)
日本語版の実装
環境:Google Colaboratory
下準備
同義語検索用関数の定義
同義語の検索が必要となる手法があるため、日本語WordNetをDLして同義語検索用関数を定義します。関数の内容詳細については過去の記事を参照ください。
日本語WordNetを使用した類義語検索 / リスト化
import gzip
import shutil
import sqlite3
import pandas as pd
import random
from math import ceil
# 日本語wordnetをDLして解凍
! wget "http://compling.hss.ntu.edu.sg/wnja/data/1.1/wnjpn.db.gz" # 1~2分
with gzip.open('wnjpn.db.gz', 'rb') as f_in:
with open('wnjpn.db', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
# synset(概念ID)とlemma(単語)の組み合わせDataFrameの作成
conn = sqlite3.connect("wnjpn.db")
q = 'SELECT synset,lemma FROM sense,word USING (wordid) WHERE sense.lang="jpn"'
sense_word = pd.read_sql(q, conn)
# 類義語をリストにして返す関数
def get_synonyms(word):
synsets = sense_word.loc[sense_word.lemma == word, "synset"]
synset_words = set(sense_word.loc[sense_word.synset.isin(synsets), "lemma"])
if word in synset_words:
synset_words.remove(word)
return list(synset_words)
get_synonyms("データ")
# >['情報', '智見', '見聞', '知識', '知見', '資料']
ストップワード
SlothLibのテキストページを取得してストップワードとします。
# DLしてリスト化
! wget "http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt"
stop_words = pd.read_csv("Japanese.txt",header=None)[0].to_list()
分かち書き関数の定義
各手法を用いる前に、まずは元の文章の分かち書きをする必要があるため関数化します。また、WordNetからの同義語検索に備えて、単語の原型もリスト化しておきます(WordNetには単語は原型で登録されているため)。このとき、指定の品詞以外は空文字にしておきます。
# MeCabをインストール
!pip install mecab-python3
!pip install ipadic
import MeCab
import ipadic
def wakati_text(text, hinshi=['名詞', '動詞']):
m = MeCab.Tagger(ipadic.MECAB_ARGS)
p = m.parse(text)
p_split = [i.split("\t") for i in p.split("\n")][:-2]
# 原文の分かち書き
raw_words = [x[0] for x in p_split]
# 同義語検索用の単語の原型リスト(品詞を絞る)
second_half = [x[1].split(",") for x in p_split]
original_words = [x[6] if x[0] in hinshi else "" for x in second_half]
original_words = ["" if word in stop_words else word for word in original_words]
return raw_words, original_words
text = "類似するデータを生成する記事を書いてます。"
raw_words, original_words= wakati_text(text)
print(raw_words)
# > ['類似', 'する', 'データ', 'を', '生成', 'する', '記事', 'を', '書い', 'て', 'ます', '。']
print(original_words)
# > ['類似', 'する', 'データ', '', '生成', 'する', '記事', '', '書く', '', '', '']
Easy Data Augmentation 各手法の実装
ここからが各手法の実装となります。
Synonym replacementとRandom insertionは日本語の類似語を抽出する必要があるため、英語版gitコードから修正を加えています。Random deletionとRandom swapはgitコードほぼそのままです。
それぞれ関数化し、どのような変換が行われるかを見ていきます。
Synonym replacement(ランダムに単語を同義語でn個置き換える)
def synonym_replacement(raw_words, original_words, n):
new_words = raw_words.copy()
# 同義語に置き換える単語をランダムに決める
original_words_idx = [i for i, x in enumerate(original_words) if x != ""]
random.shuffle(original_words_idx)
# 指定の件数になるまで置き換え
num_replaced = 0
for idx in original_words_idx:
raw_word = raw_words[idx]
random_word = original_words[idx]
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(synonyms)
new_words = [synonym if word == raw_word else word for word in new_words]
print(random_word, " → ", synonym)
num_replaced += 1
if num_replaced >= n:
break
print(f"原文:{(''.join(raw_words))}")
print(f"変換後:{(''.join(new_words))}")
print("-"*50)
return new_words
synonym_replacement(raw_words, original_words, 2)
# >データ → 見聞
# >生成 → 創り出す
# >原文:類似のデータを生成する記事を書いてます。
# >変換後:類似の見聞を創り出すする記事を書いてます。
Random insertion(ランダムに単語をn個挿入)
def random_insertion(raw_words, original_words, n):
new_words = raw_words.copy()
for _ in range(n):
add_word(new_words, original_words)
print(f"原文:{(''.join(raw_words))}")
print(f"変換後:{(''.join(new_words))}")
print("-"*50)
return new_words
def add_word(new_words, original_words):
synonyms = []
counter = 0
insert_word_original = [x for x in original_words if x]
while len(synonyms) < 1:
random_word = insert_word_original[random.randint(0, len(insert_word_original)-1)]
synonyms = get_synonyms(random_word)
counter += 1
if counter >= 10:
return
random_synonym = synonyms[0]
random_idx = random.randint(0, len(new_words)-1)
print(f"挿入する単語:{random_synonym}")
new_words.insert(random_idx, random_synonym)
random_insertion(raw_words,original_words, 2)
# >挿入する単語:執筆
# >挿入する単語:類似性
# >原文:類似のデータを生成する記事を書いてます。
# >変換後:類似性類似するデータを生成する記事執筆を書いてます。
Random deletion(ランダムに単語をn個削除する)
def random_deletion(words, p):
# 1文字しかなければ削除しない
if len(words) == 1:
return words
# 確率pでランダムに削除
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
else:
print(f"削除:{word}")
# 全て削除してしまったら、ランダムに1つ単語を返す
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
print(f"原文:{(''.join(words))}")
print(f"変換後:{(''.join(new_words))}")
print("-"*50)
return new_words
random_deletion(raw_words, 0.05)
# >削除:データ
# >削除:ます
# >原文:類似のデータを生成する記事を書いてます。
# >変換後:類似のを生成する記事を書いて。
Random swap(ランダムに単語の場所をn回入れ替える)
def random_swap(words, n):
new_words = words.copy()
for _ in range(n):
nwords = swap_word(new_words)
print(f"原文:{(''.join(words))}")
print(f"変換後:{(''.join(new_words))}")
print("-"*50)
return new_words
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
print(new_words[random_idx_1], "⇔", new_words[random_idx_2])
return new_words
random_swap(raw_words, 2)
# >の ⇔ を
# >を ⇔ 類似
# >原文:類似のデータを生成する記事を書いてます。
# >変換後:を類似データを生成する記事の書いてます。
実行用関数
今まで作ってきた関数を一気に実行します。
パラメータは各手法のα(alpha_xx)、生成する類似文章数(num_aug)です。
突然αが出てきましたが、「単語を同義語でn個置き換え」「単語の場所をn回入れ替え」「文中に出現する単語の同義語をn個挿入」に登場するnは「α×文章の単語数」で決定します。これは文章の長さに応じて変換する数を増減させることを目的としています(長い文はたくさん変換、短い文は少しだけ変換)。Random deletion(ランダムに単語を確率pで削除する)に登場するpにはαがそのまま採用されます(p=α)。
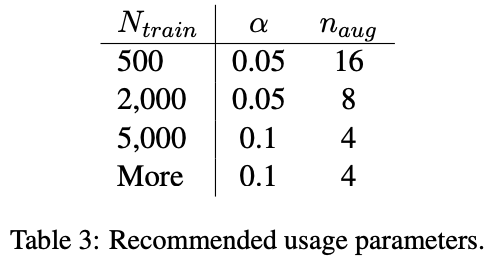
論文では既存のデータセットに存在する原文の件数に応じて、下記のパラメータに設定することを推奨しているようです。
※下記は論文より抜粋
def eda(sentence, alpha_sr=0.1, alpha_ri=0.1, alpha_rs=0.1, p_rd=0.1, num_aug=9):
# 分かち書き
raw_words, original_words = wakati_text(sentence)
num_words = len(raw_words)
augmented_sentences = []
techniques = ceil(alpha_sr) + ceil(alpha_ri) + ceil(alpha_rs) + ceil(p_rd)
if techniques == 0:
return
num_new_per_technique = int(num_aug/techniques)+1
#ランダムに単語を同義語でn個置き換える
if (alpha_sr > 0):
n_sr = max(1, int(alpha_sr*num_words))
for _ in range(num_new_per_technique):
a_words = synonym_replacement(raw_words,original_words ,n_sr)
augmented_sentences.append(''.join(a_words))
#ランダムに文中に出現する単語の同義語をn個挿入
if (alpha_ri > 0):
n_ri = max(1, int(alpha_ri*num_words))
for _ in range(num_new_per_technique):
a_words = random_insertion(raw_words,original_words, n_ri)
augmented_sentences.append(''.join(a_words))
#ランダムに単語の場所をn回入れ替える
if (alpha_rs > 0):
n_rs = max(1, int(alpha_rs*num_words))
for _ in range(num_new_per_technique):
a_words = random_swap(raw_words, n_rs)
augmented_sentences.append(''.join(a_words))
#ランダムに単語を確率pで削除する
if (p_rd > 0):
for _ in range(num_new_per_technique):
a_words = random_deletion(raw_words, p_rd)
augmented_sentences.append(''.join(a_words))
#必要な文章の数だけランダムに抽出
random.shuffle(augmented_sentences)
augmented_sentences = augmented_sentences[:num_aug]
#原文もリストに加える
augmented_sentences.append(sentence)
return augmented_sentences
# 原文から5つの文章を生成
eda(text, alpha_sr=0.05, alpha_ri=0.05, alpha_rs=0.05, p_rd=0.05, num_aug=5)
# >['類似するを生成する記事を書いてます。',
# '類似するデータを生成類似性する記事を書いてます。',
# '類似するデータを生成する記事を起草てます。',
# '類似するデータをますする記事を書いて生成。',
# '類似する書いを生成する記事をデータてます。',
# '類似するデータを生成する記事を書いてます。']
実装としては以上となります。
今後やりたいこと
例を見ても分かる通り、結構意味が変わってしまっている文もあり、本当にモデルの精度は向上するのかちょっと怪しいです。近いうちに、Easy Data Augmentationによってモデルの精度が向上するかを検証したいと思います。
(2/11追記)livedoorのニュースセットを用いて効果検証を行いました。よろしければこちらもご覧になってください
日本語版Easy Data Augmentation の効果検証(実装コードあり)
更新事項
(2021/1/23)mecab-python3をpip installするところでエラーが出てしまう不備を修正しました。
(2021/1/23)不要コードの削除、print文の追加を行いました。
(2021/1/24)コメントで指摘頂いた点を反映し、併せて不備も修正しました。(@polm23さん、ありがとうございました)
(2021/2/11)効果検証のリンクを追加、誤字修正