概要
本記事では、 BigQuery サンドボックス環境から、 Apache Spark SQL Connector for Google BigQuery (以下「 Spark コネクター for BQ 」)を用いて Databricks Community edition にてデータを取得する方法を紹介します。 Spark コネクター for BQ は、 BigQuery Storage API を介してデータにアクセスするため、データフレーム操作などを行う際、低コストかつ高パフォーマンスな利用が可能な場合があります。
本記事は下記シリーズの一部です。

出所:Databricks で BigQuery のデータを取得する方法の徹底ガイド - Qiita
検証コードと実行結果
BigQuery の事前設定
1. IAM と管理 -> サービス アカウントタブにて、+ サービス アカウントを作成を千九田ふぁ
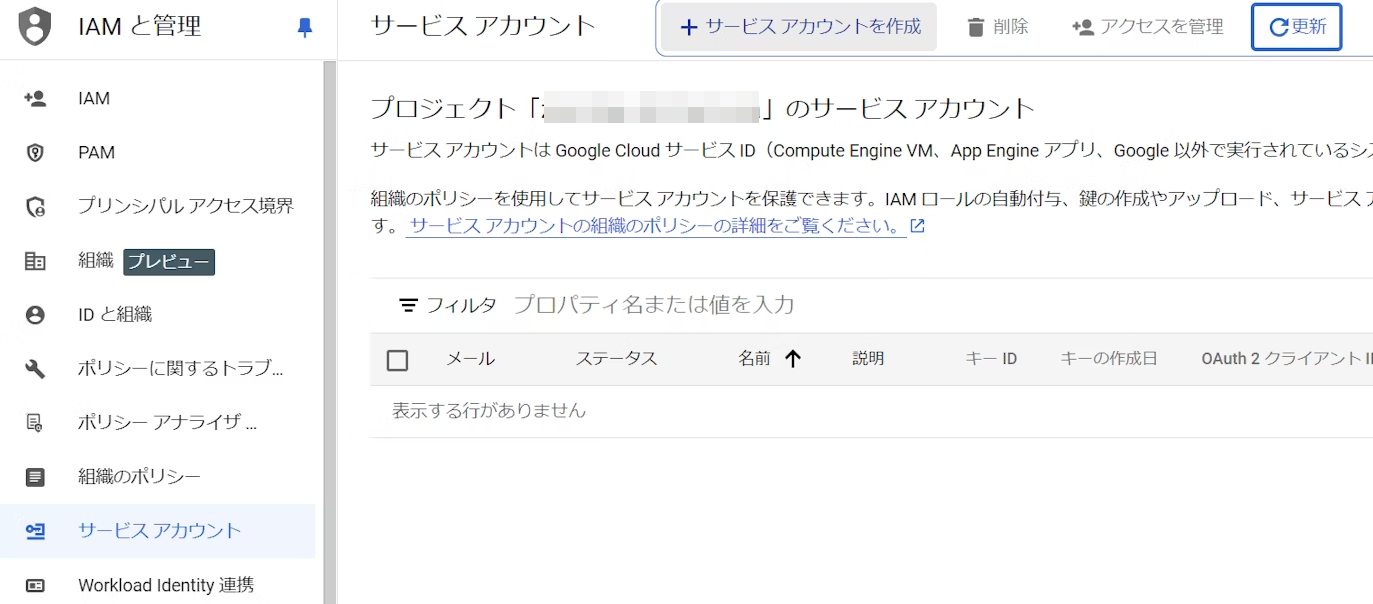
2. 任意の名称と ID を入力して作成して続行を選択
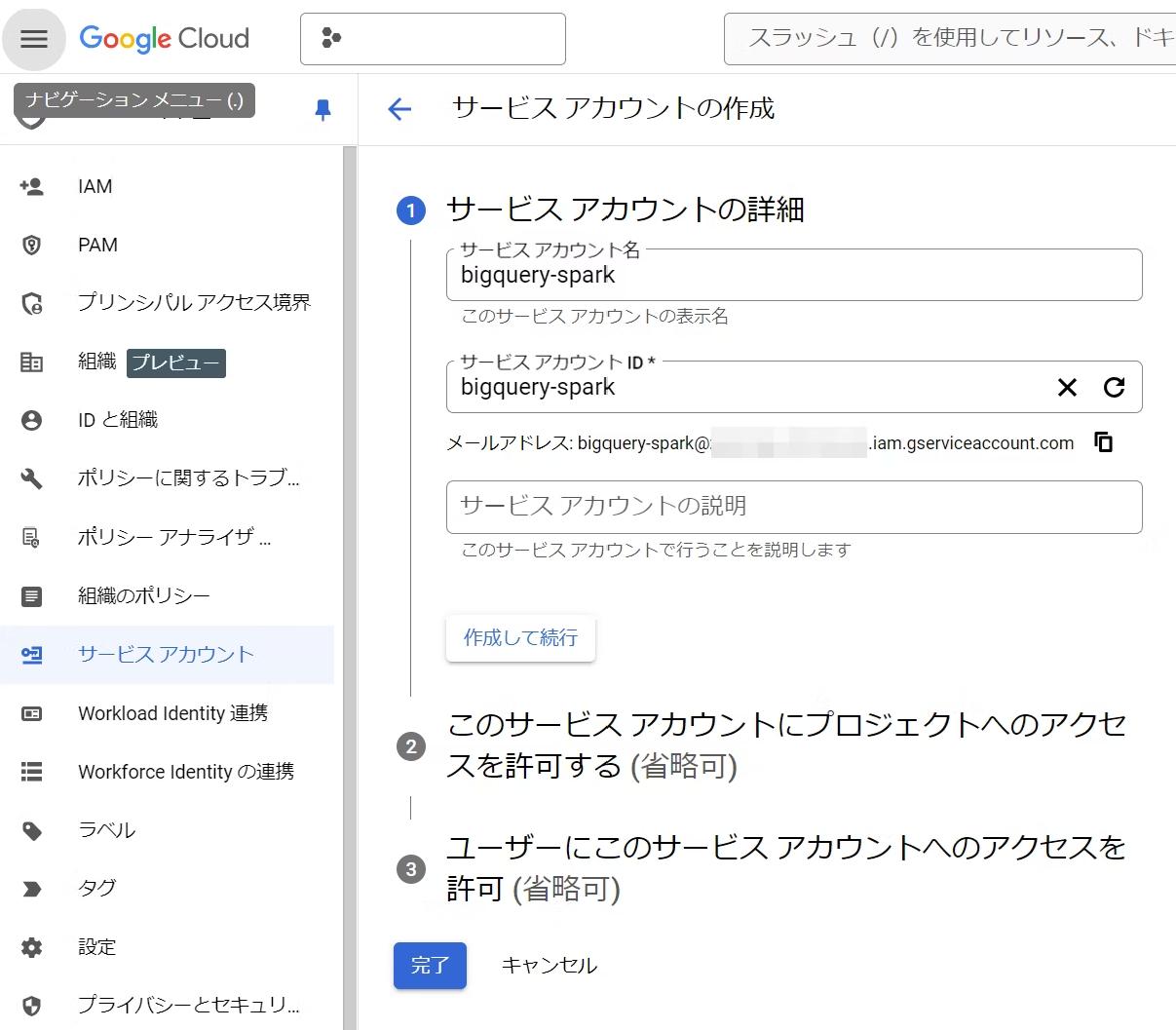
3. BigQuery user(BigQuery ユーザー)とBigQuery Data Editor(BigQuery データ編集者)のロールをついかして完了を選択
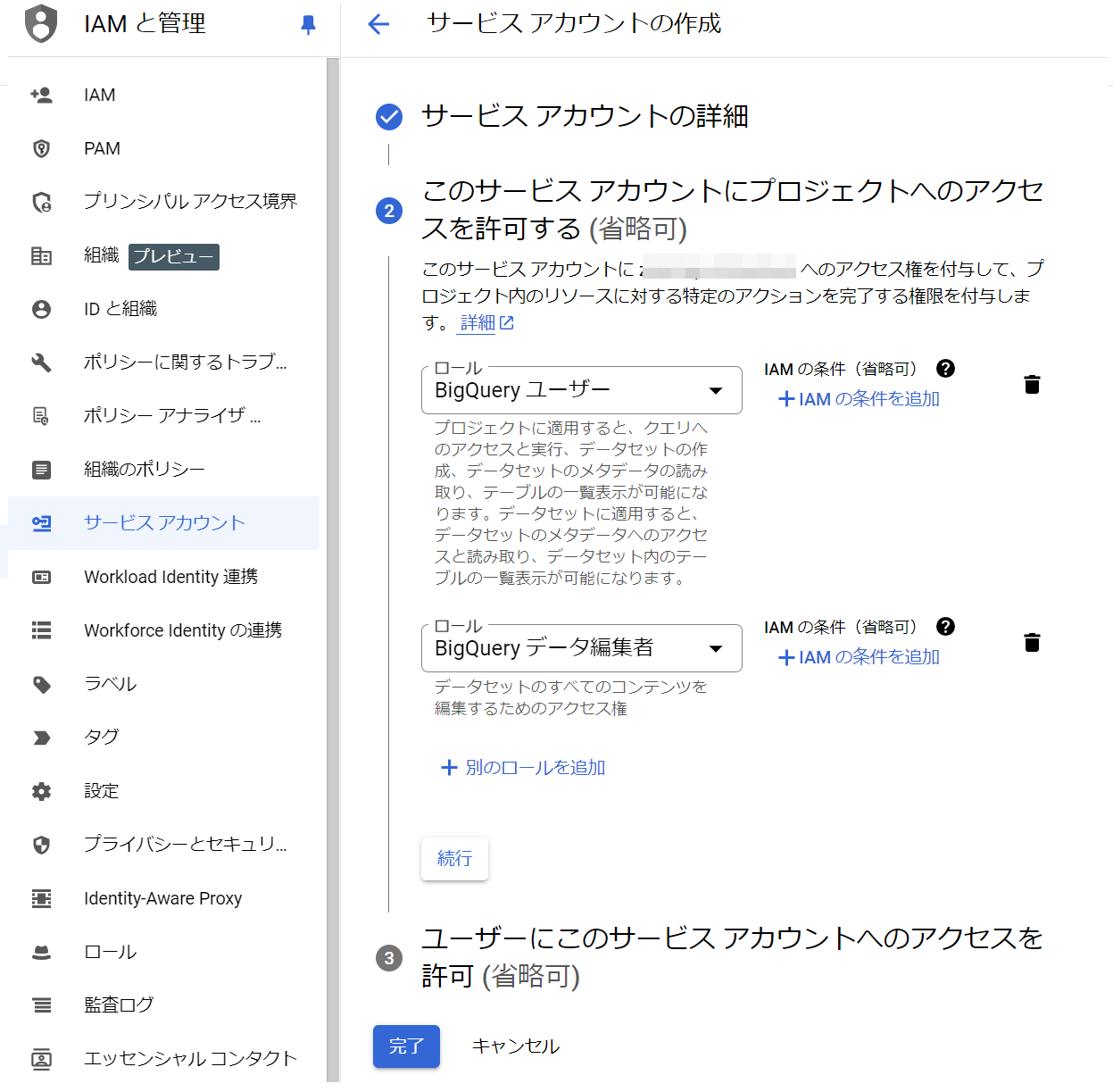
4. 作成したサービスアカウント -> キーを追記にある新しい鍵を作成を選択
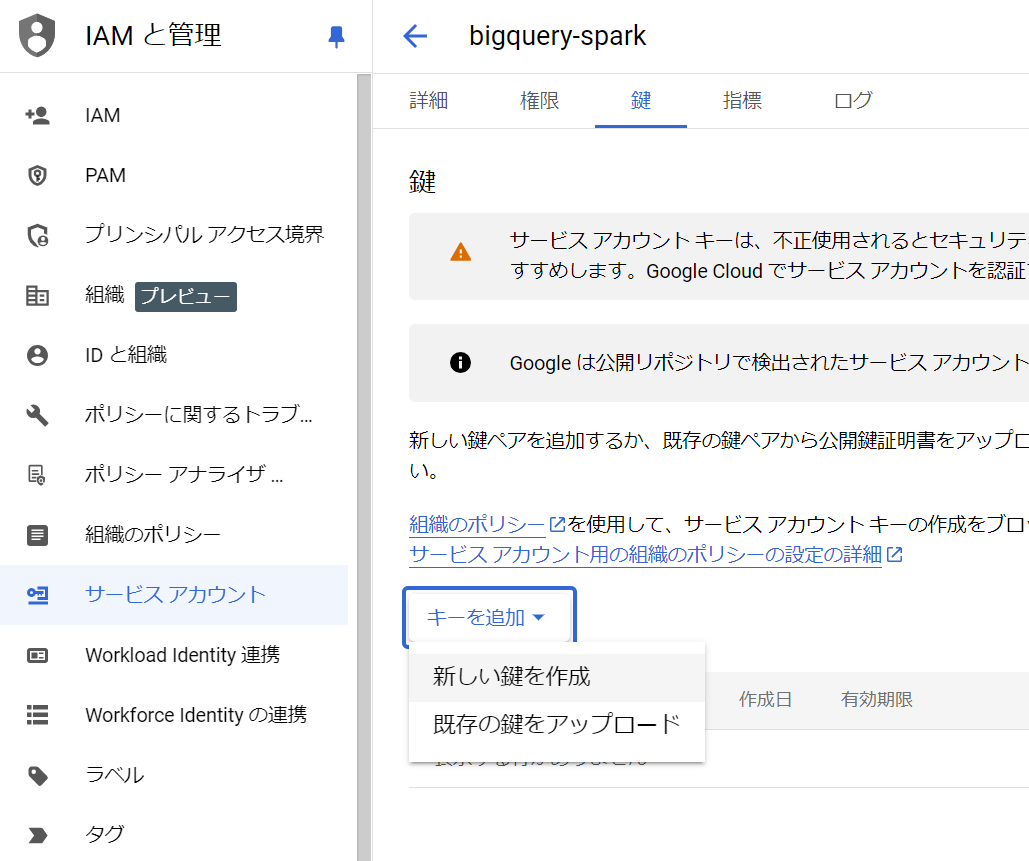
5. JSONを選択して作成を選択

6. JSON ファイルがダウンロードされたことを確認
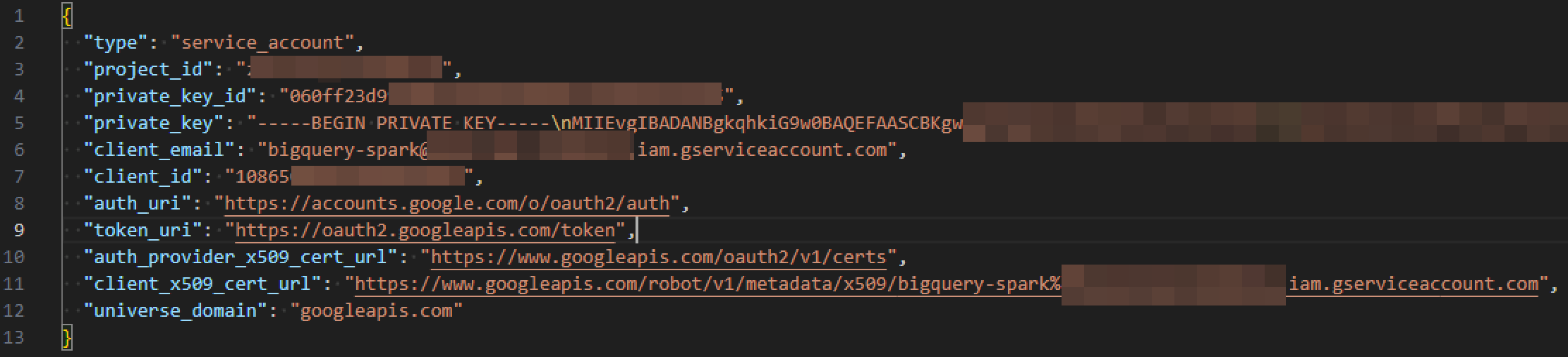
Databricks Community edition での実行例
1. リンク先にてDatabricks Community edition の申し込み
引用元:Signup - Community Edition - Databricks
2. Databricks にログイン後にCompute -> Create computを選択
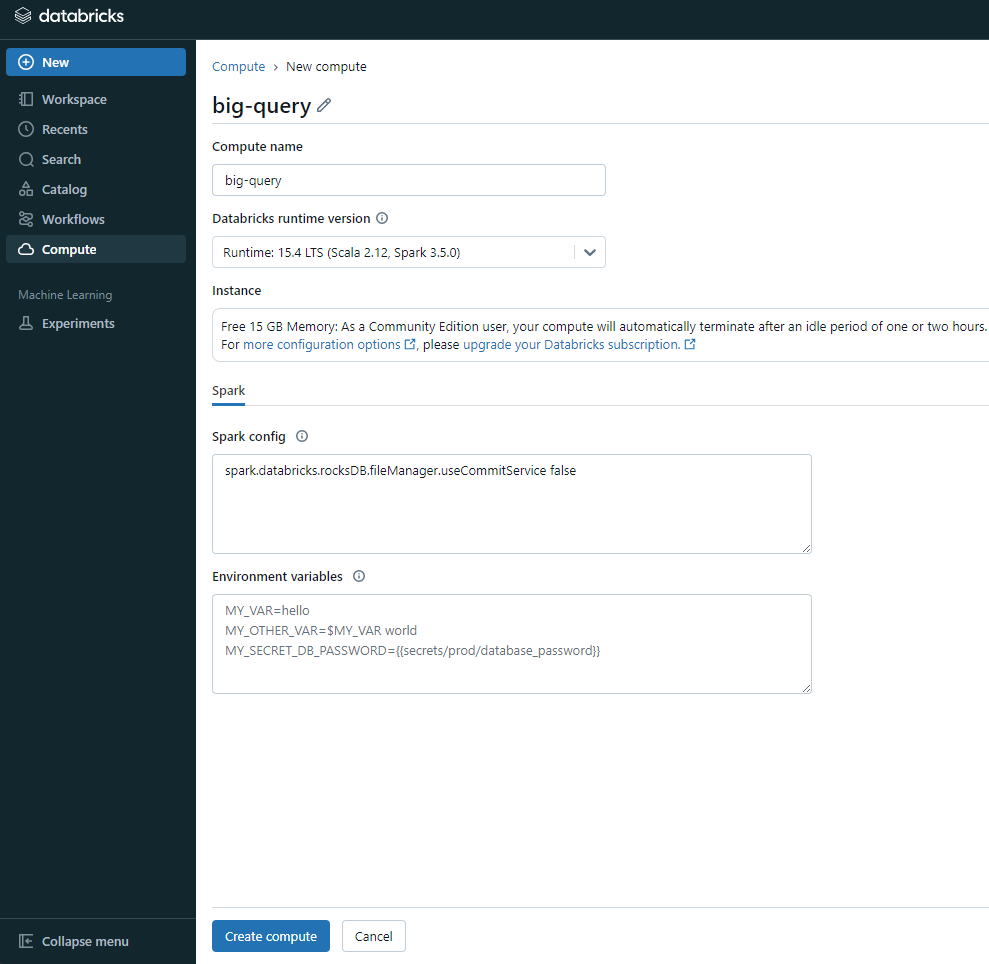
3. Databricks runtime versionにて最も新しいバージョンのクラスター選択しCreate computeを選択
4. 左上のNew -> Notebookを選択
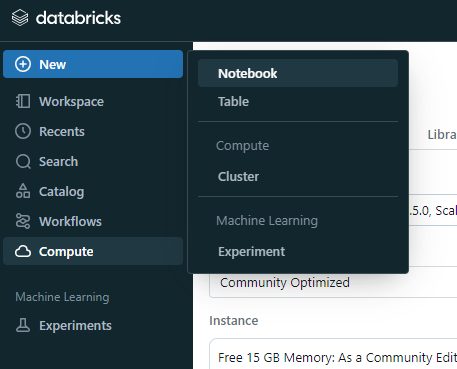
5. 作成されたノートブックの右側にあるConnectを選択し作成したクラスターを選択
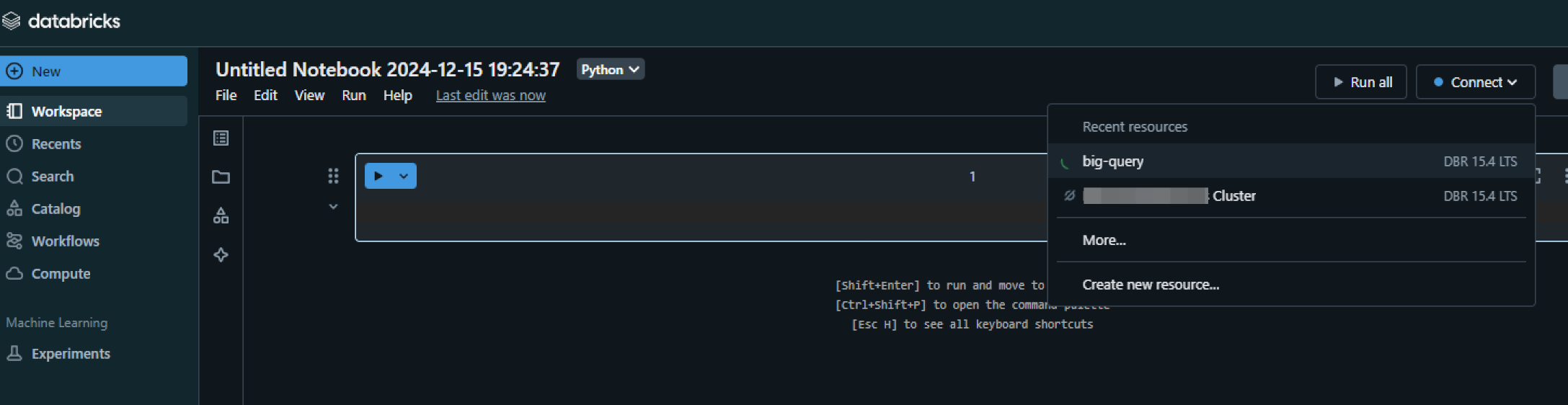
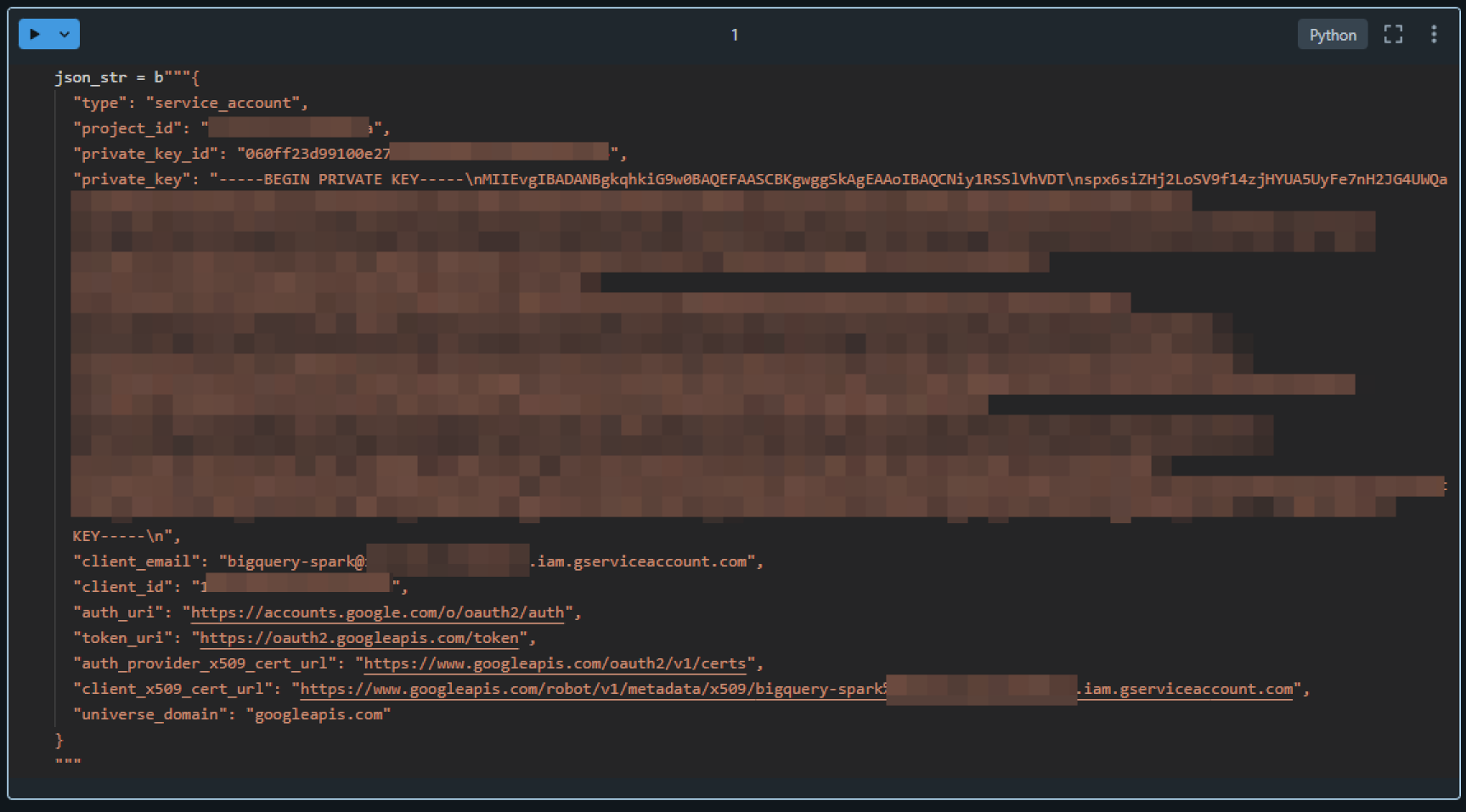
6. Databricks ノードブック上で BigQuery の認証キーの内容を貼り付けて実行
json_str = b"""{json_key}"""
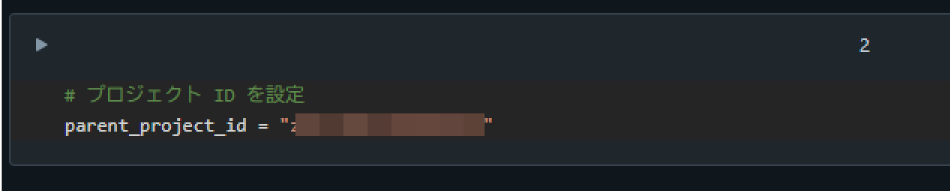
7. Google Cloud の Project ID を貼り付けて実行
# プロジェクト ID を設定
parent_project_id = "{project_id}"
Project ID は Google Cloud のコンソールにてプロジェクトを切り替えるウィンドウにて確認できます。

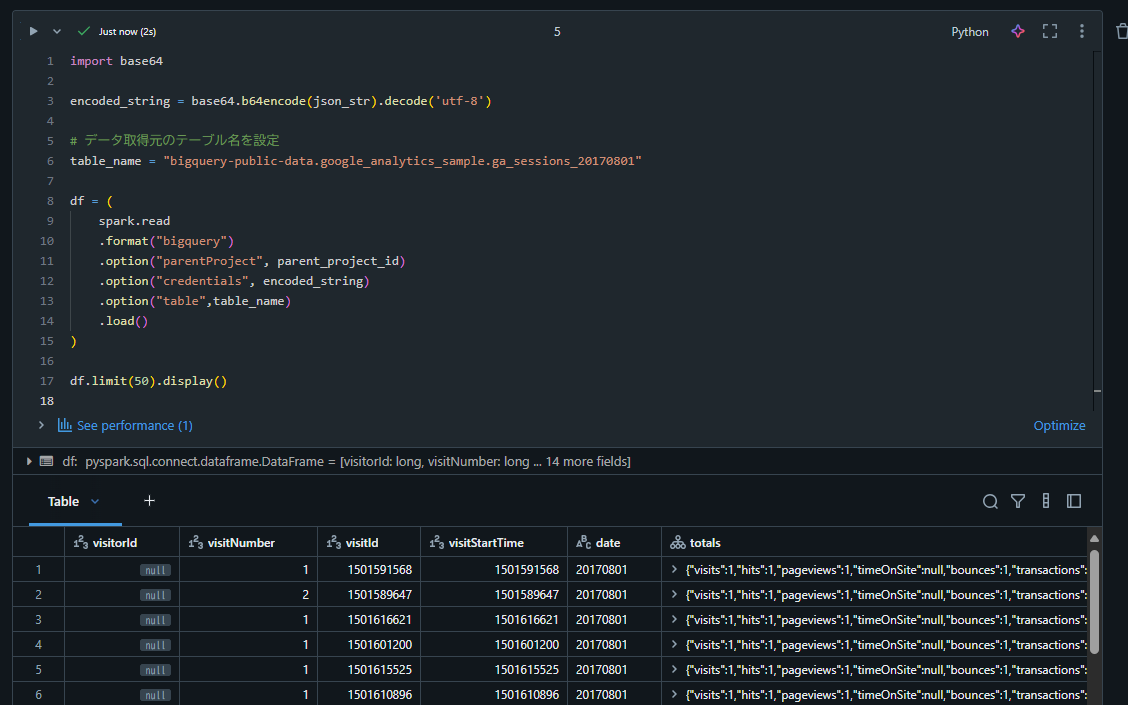
8. BigQuery からデータを取得するコードを実行
import base64
encoded_string = base64.b64encode(json_str).decode('utf-8')
# データ取得元のテーブル名を設定
table_name = "bigquery-public-data.google_analytics_sample.ga_sessions_20170801"
df = (
spark.read
.format("bigquery")
.option("parentProject", parent_project_id)
.option("credentials", encoded_string)
.option("table",table_name)
.load()
)
df.limit(50).display()
まとめ
本記事では、Apache Spark SQL Connector for Google BigQuery(Spark コネクター for BQ) を利用しDatabricks Community Edition 上で BigQuery のデータを取得する手順を紹介しました。 Spark コネクター for BQ は、大規模データ分析やデータフレーム操作において有用なツールであり、ぜひ活用してみてください。