概要
Databricks で BigQuery のデータを取得する方法を整理します。主な方法としては代表的な方法が 2 種類あり、Databricks の環境によっていずれかの方法でデータを取得します。接続方法を理解し、接続方法に応じた権限を付与することで、BigQuery のデータを Databricks で活用できるようになります。
接続方法と Databricks の機能
接続方法
Databricks で BigQuery のデータを参照する場合、一般的には以下の 2 つの方法が採用されます。Spark コネクターによる接続方法では、 Google が開発している Apache Spark SQL connector for Google BigQuery(Spark-BQ コネクター)を利用し、 JDBC による方法では、 Simba 社の JDBC コネクターを利用します。Databricks ではいずれも Databricks Runtime に組み込まれています。テーブル参照では Spark コネクターを使う方が低コストかつ高速ですが、ビューを参照する際は必要となる権限が異なるなどの注意点があります。
- Spark コネクターによる接続方法
- JDBC による接続方法
それぞれの具体的な手順は以下の記事で紹介しています。
- Databricks にて BigQuery から JDBC により Spark データフレームを作成する方法 #Databricks - Qiita
- Databricks にて BigQuery から Spark コネクターにより Spark データフレームを作成する方法 #Databricks - Qiita
Databricks の機能
Databricks では以下の機能を使い、上記いずれかの接続方法で BigQuery のデータを取得します。Spark データフレームを作成するときはどちらの方法も選択できますが、Lakehouse Federation を利用する場合は実行環境によって接続方式が異なります。
- Spark データフレーム
- Lakehouse Federation
Serverless compute for notebooks では、JDBC による接続方法により Spark データフレームを作成する方法が制限されています。
The input query contains unsupported data source(s). Only csv, json, avro, delta, kafka, parquet, orc, text, unity_catalog, binaryFile, xml, simplescan, iceberg, mysql, postgresql, sqlserver, redshift, snowflake, sqldw, databricks, bigquery, oracle, salesforce, salesforce_data_cloud, teradata, workday_raas, mongodb data sources are supported on serverless compute, and only csv, json, avro, delta, kafka, parquet, orc, text, unity_catalog, binaryFile, xml, simplescan, iceberg data sources are allowed to run DML on serverless compute.

2025年5月1日時点では、Databricks Runtime 16.1 以降のクラスターで Lakehouse Federation を使う場合に Spark コネクターによる接続方法で実行され、それ以外の環境では JDBC による接続方法が実行されます。今後、他の環境でも Spark コネクターが利用される可能性が高いので、リリースノートを随時確認してください。接続方法の確認方法については以下の記事をご参照ください。
認証方法
Databricks から BigQuery に認証する方法
Databricks から BigQuery への認証は、Google Cloud のサービスアカウントを用いるケースが多いです。
- Google Cloud のサービスアカウントを利用した認証
Google Cloud のサービスアカウントを利用した認証については、以下の記事で紹介しています。
Google Cloud にて付与する権限
基本的な権限付与方針
2 つの接続方法どちらにも対応できるよう、以下の権限付与を想定することを検討してください。Spark Connector が 0.43.0 以降の場合、BigQuery Data Editor ではなく BigQuery Data Viewer で十分です。
- BigQuery Read Session User
- BigQuery Job User
- BigQuery Data Editor
- ただし、テーブルのみをソースにする場合は BigQuery Data Viewer でも可。
ケース別必要権限
状況に応じた権限付与を、以下の表にまとめました。使用するケースが限定的であれば必要権限を調整してください。
| # | ケース | 必要権限 |
|---|---|---|
| 1 | Spark コネクター テーブル参照 | - Read Session User - Data Viewer |
| 2 | Spark コネクター ビュー参照 (0.42.x 以前) |
- Read Session User - Job User - Data Editor |
| 3 | Spark コネクター ビュー参照 (0.42.1 以降) |
- Read Session User - Job User - Data Viewer |
| 4 | JDBC テーブル/ビュー参照 (4 万行以上) |
- Job User - Data Viewer - Read Session User |
| 5 | JDBC テーブル/ビュー参照 (4 万行未満) |
- Job User - Data Viewer |
検証結果は以下の記事で整理しています。
-
Spark コネクターによりテーブルのみから取得するケース
-
0.42.0 バージョン以前の Spark コネクターによりビューを取得するケース
-
0.43.0 バージョン以降の Spark コネクターによりビューを取得するケース
-
JDBC により取得するケース
ビューを扱う際の注意点
参照権限のないテーブルをベースにしたビューを取得する際の注意事項
BigQuery でテーブルとビューが別のデータセットにあり、ビュー(またはそのデータセット)のみ権限を付与してテーブル側のデータセットには権限を付与しない場合は、以下のいずれかの対応が必要です。
- Authorize Datasets を設定する方法
- Authorize View を設定する方法
詳細は以下の記事で整理しています。
その他のテクニック
多数の BigQuery を効率的に連携する方法
多数の BigQuery をソースにする場合には BigQuery を統合してからデータ連携を行うことで、効率的に実施できる場合があります。Spark コネクターによるデータ連携時の BigQuery のコストを最適化するために、テーブル参照権限の付与も検討してください。
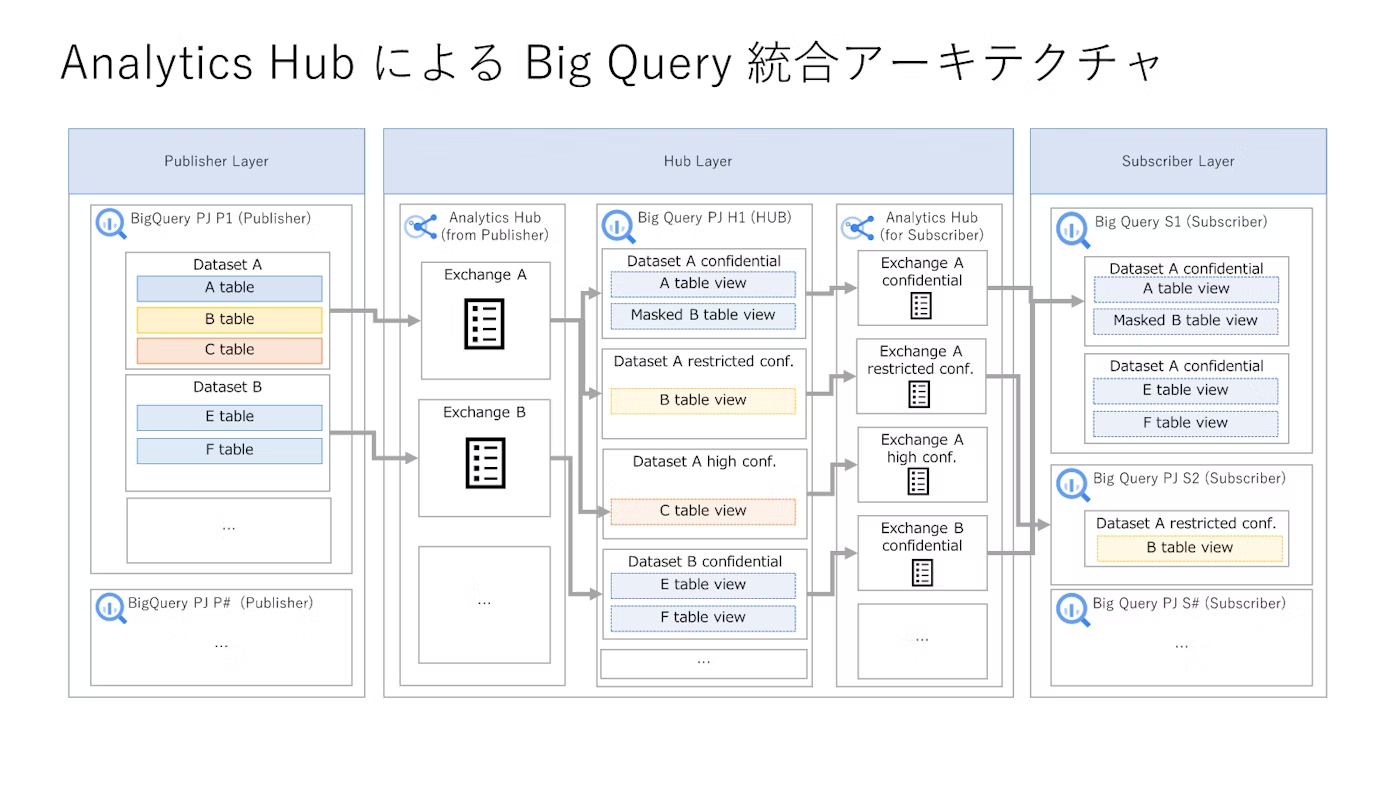
下記の記事にて詳細を記述しています。
- サイロ化したBigQueryをAnalyticsHubにより統合するアーキテクチャの検討時のメモ #GoogleCloud - Qiita
- サイロ化されたBigQueryデータセット統合におけるDataplexと関連サービスの活用方法 #GoogleCloud - Qiita
まとめ
- テーブルが主体で大規模な処理の場合は Spark-BigQuery コネクターが高速かつ低コスト。
- ビューを扱う場合は Spark コネクターのバージョンと必要権限に注意。0.43.0 以降なら Data Viewer + Job User + Read Session User で簡潔化。
- 実行環境の Runtime バージョンによって接続方法が異なり、Lakehouse Federation でも Spark コネクターが利用される場合があるので要確認。