概要
0.43.0 バージョン以降の Spark-BQ コネクター(Apache Spark SQL connector for Google BigQuery)におけるビューの実体化仕様に関する検証結果を共有します。0.43.0 バージョンは2025年5月1日時点では未リリースですが、 0.42.1 バージョンから動作が変更されていることを確認できました。README にて 0.43.0 バージョン以降ではビュー参照時の仕様が変更された旨が記載されています。その仕様変更により、従来では BigQeury Data Editor 権限が必要でしたが、 BigQuery Data Viewer 権限で十分となったようです。

事前準備
BigQuery 上でビューを作成
-- データセットを作成
CREATE SCHEMA IF NOT EXISTS `jdbc_test_01`;
-- テーブルを作成
CREATE OR REPLACE TABLE `jdbc_test_01.table_01` AS
SELECT *
FROM UNNEST([
STRUCT(1 AS id, 'Alice' AS name, 100 AS score),
STRUCT(2 AS id, 'Bob' AS name, 95 AS score),
STRUCT(3 AS id, 'Carol' AS name, 98 AS score)
]);
-- ビューを作成
CREATE OR REPLACE VIEW `jdbc_test_01.view_01` AS
SELECT * FROM `jdbc_test_01.table_01`;
SELECT * FROM `jdbc_test_01.view_01`;

Google Cloud 上でサービスアカウントを作成
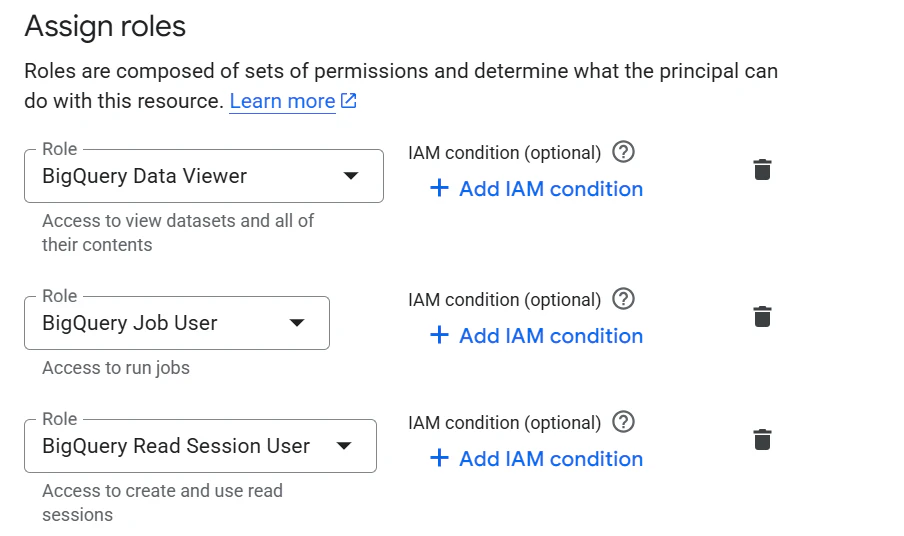
下記の権限を付与したサービスアカウントを作成し、キーを取得します。
- BigQuery Data Viewer
- BigQuery Job User
- BigQuery Read Session User
Google Colab にてノートブックを作成し Spark のバージョンを確
!pyspark --version

検証結果
0.41.0 バージョンでの検証
まず、ランタイムを接続解除して削除を選択して、ランタイムを初期化します。

サービスアカウントのキーを変数にセットします。
json_str = """{json_key}"""

SparkSession を定義します。
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName('bq_connector')
.config('spark.jars.packages', 'com.google.cloud.spark:spark-3.5-bigquery:0.42.0') \
.getOrCreate()
)

権限不足によりエラーとなることを確認します。
# プロジェクト ID を設定
parent_project_id = "axial-triode-XXXXX"
import base64
encoded_string = base64.b64encode(json_str).decode('utf-8')
# データ取得元のテーブル名を設定
table_name = "jdbc_test_01.view_01"
df = (
spark.read
.format("bigquery")
.option("parentProject", parent_project_id)
.option("credentials", encoded_string)
.option("viewsEnabled", True)
.option("table",table_name)
.load()
)
df.limit(50).show(truncate=False)
Caused by: com.google.cloud.spark.bigquery.repackaged.com.google.common.util.concurrent.UncheckedExecutionException: com.google.cloud.spark.bigquery.repackaged.com.google.cloud.bigquery.BigQueryException: Access Denied: Dataset axial-triode-368703:jdbc_test_01: Permission bigquery.tables.create denied on dataset axial-triode-XXXX:jdbc_test_01 (or it may not exist).

0.41.1 バージョンでの検証
まず、ランタイムを接続解除して削除を選択して、ランタイムを初期化します。
サービスアカウントのキーを変数にセットします。
json_str = """{json_key}"""
SparkSession を定義します。
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName('bq_connector')
.config('spark.jars.packages', 'com.google.cloud.spark:spark-3.5-bigquery:0.42.1') \
.getOrCreate()
)
データを取得できることを確認します。
import base64
encoded_string = base64.b64encode(json_str).decode('utf-8')
# データ取得元のテーブル名を設定
table_name = "shared_dataset_01.view_01"
df = (
spark.read
.format("bigquery")
.option("parentProject", parent_project_id)
.option("credentials", encoded_string)
.option("viewsEnabled", True)
.option("table",table_name)
.load()
)
df.limit(50).show(truncate=False)

BigQuery のログ
0.42.0 バージョンのログ概要
0.42.1 バージョンのログ概要
| # | methodName |
タイミング・役割 | 主な権限チェック (authorizationInfo) |
|---|---|---|---|
| 1 | jobservice.insert |
★ ジョブ作成リクエストクライアント → BigQuery |
bigquery.jobs.create``bigquery.tables.getData(view_01 / table_01) |
| 2 | google.cloud.bigquery.v2.JobService.InsertJob |
BigQuery がリクエストを受理しジョブ ID を確定(operation.first=true) | bigquery.jobs.create |
| 3 |
google.cloud.bigquery.v2.JobService.InsertJob(tableDataRead) |
基表 table_01 のデータ読み取り記録 |
bigquery.tables.getData |
| 4 | jobservice.jobcompleted |
★ クエリ完了通知(operation.last=true)実行統計・課金量などを記録 | ―(完了時は権限検証なし) |
| 5 |
google.cloud.bigquery.v2.JobService.InsertJob(jobInsertion) |
BigQuery 側から見た「ジョブ状態遷移」ログ | ― |
| 6 | jobservice.getqueryresults |
クライアントがクエリ結果(一時テーブル)を取得 |
bigquery.jobs.create(ジョブ所有者確認) |
0.42.0バージョンのログ概要
| # | methodName |
代表的に検証された権限 (authorizationInfo) |
|---|---|---|
| 1 | jobservice.insert |
bigquery.jobs.create``bigquery.tables.getData (view_01 / table_01)bigquery.tables.create & tables.updateData(一時テーブル用) |
| 2 |
google.cloud.bigquery.v2.JobService.InsertJob(operation.first) |
bigquery.jobs.create |
| 3 |
google.cloud.bigquery.v2.JobService.InsertJob(tableCreation) |
bigquery.tables.create |
| 4 |
google.cloud.bigquery.v2.JobService.InsertJob(tableDataChange) |
bigquery.tables.updateData |
| 5 |
google.cloud.bigquery.v2.JobService.InsertJob(tableDataRead) |
bigquery.tables.getData |
| 6 | jobservice.jobcompleted |
― |
| 7 |
google.cloud.bigquery.v2.JobService.InsertJob(jobChange) |
― |
| 8 | jobservice.getqueryresults |
bigquery.jobs.create``bigquery.tables.getData(一時テーブル) |
| 9 |
google.cloud.bigquery.v2.JobService.GetQueryResults(tableDataRead) |
bigquery.tables.getData |
| 10 | tableservice.update |
bigquery.tables.update``bigquery.tables.delete |
| 11 | google.cloud.bigquery.v2.TableService.PatchTable |
bigquery.tables.update |
| 12 | google.cloud.bigquery.storage.v1.BigQueryRead.CreateReadSession |
bigquery.readsessions.create``bigquery.tables.getData |
| 13 | google.cloud.bigquery.storage.v1.BigQueryRead.ReadRows |
bigquery.tables.getData |
BigQuery Data Editor権限を付与して正常実行後のログを取得しています。

