概要
Treasure Data CDP (TD) と Databricks を相互にデータ連携する方法を整理します。
Customer Data Platform (CDP) 業界では、クラウド DWH サービスとのシームレスなデータ連携機能が注目されています。以前、その背景について投稿しました。このような背景から、Zero Copy だけでなく、CDP With DWH を実現するための方法論を整理しようと考えました。
引用元:Zero-Copy による CDP With DWH
本記事では Treasure Data CDP と Databricks における CDP With DWH を実現するための方法論を整理します。Databricks から Treasure Data CDP への連携だけでなく、Treasure Data CDP から Databricks への連携方法も整理します。ただし、現時点では Treasure Data CDP 環境がないため、実装方法のみを整理します。
採用すべきデータ連携方法
本記事で提示する方法論の中から、最も適した方法を採用してください。場合によっては、1つの方法だけでなく、ユースケースに応じて2つ以上の方法を採用することもあります。
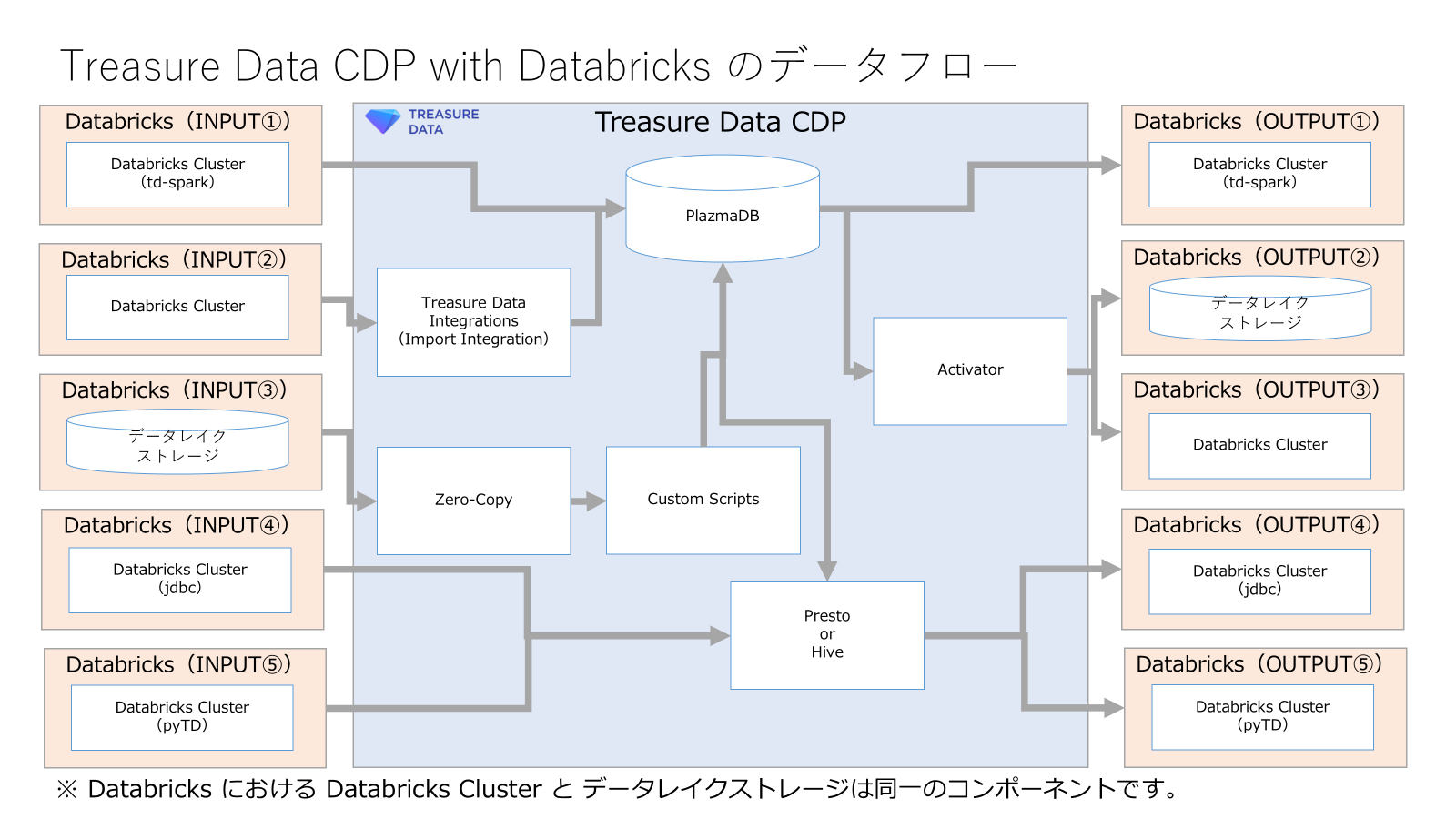
下記の図にて Databricks と Treasure Data CDP のデータフローを示しています。この図で重要なのは、どの機能を利用してデータ連携が行われているのかを把握することです。これにより、コストやパフォーマンスへの影響を理解できます。データ統合機能(Treasure Data CDP における Presto や Hive、Databricks における Spark クラスター)が直接ストレージサービス(Treasure Data CDP における PlazmaDB、Databricks におけるデータレイクストレージ)を参照して処理を行うことが、性能面やコスト面で理想的であることが多いです。
Treasure Data CDP のコストを考慮する際には、キャパシティ上限を考える必要があります。キャパシティ上限の影響が最小限となる方法論が、理想的な方法になる可能性が高いです。キャパシティ上限については、下記の記事で整理しています。

引用元:Treasure Data CDPの全体像を理解する:機能とコンポーネントの詳細ガイド #TreasureData - Qiita
Databricks -> Treasure Data CDP のデータ連携方法
| # | 方法論 | 実行主体 | 備考 |
|---|---|---|---|
| 1 | Databricks Cluster にて td-spark 経由で Plazma にデータを連携する方法 | Databricks | |
| 2 | Treasure Data Integrations にて Databricks Cluster 経由でデータを連携する方法 | TD | |
| 3 | Zero-Copy にてクラウドストレージ経由でデータを連携する方法 | TD | |
| 4 | Databricks Cluster にて JDBC 経由でデータを連携する方法 | Databricks | 書き込みが可能か不明 |
| 5 | Databricks Cluster にて pyTD 経由でデータを連携する方法 | Databricks | |
| 6 | Treasure Data Integrations にて Delta Sharing 経由でデータを連携する方法 | TD | 現時点ではベータ版 |
| 7 | Treasure Data Integrations にてクラウドストレージ経由でデータを連携する方法 | TD | ファイルフォーマットに制限あり |
参考リンク
- Databricks Cluster にて td-spark 経由で Plazma にデータを連携する方法
- Treasure Data Integrations にて Databricks Cluster 経由でデータを連携する方法
- Zero-Copy にてクラウドストレージ経由でデータを連携する方法
- Databricks Cluster にて JDBC 経由でデータを連携する方法
- Databricks Cluster にて pyTD 経由でデータを連携する方法
- Treasure Data Integrations にて Delta Sharing 経由でデータを連携する方法
- Treasure Data Integrations にてクラウドストレージ経由でデータを連携する方法
Treasure Data CDP -> Databricks のデータ連携方法
| # | 方法論 | 実行主体 | 備考 |
|---|---|---|---|
| 1 | Databricks Cluster にて td-spark 経由で Plazma からデータを連携する方法 | Databricks | |
| 2 | Activator にてデータレイクストレージ経由でデータを連携する方法 | TD | |
| 3 | Activator にて Databricks 経由でデータを連携する方法 | TD | |
| 4 | Databricks Cluster にて JDBC 経由でデータを連携する方法 | Databricks | |
| 5 | Databricks Cluster にて pyTD 経由でデータを連携する方法 | Databricks |
参考リンク
- Databricks Cluster にて td-spark 経由で Plazma からデータを連携する方法
- Activator にてデータレイクストレージ経由でデータを連携する方法
- Activator にて Databricks 経由でデータを連携する方法
- Databricks Cluster にて JDBC 経由でデータを連携する方法
- Databricks Cluster にて pyTD 経由でデータを連携する方法
関連情報
1. Live Connect Zero-Copy with Databricks について
ドキュメントの下記図によると、Live Connect Zero-Copy with Databricks は Databricks の Delta Sharing Protocol を通じてデータ連携を行うようです。私は Presto から直接 Delta Lake 形式のストレージにクエリが発行されると想定していましたが、そのような動作の記述はドキュメントで確認できませんでした。

引用元:Live Connect Zero-Copy with Databricks
2. TD Workflow における Databricks Connect の利用について
Databricks Connect という外部環境から Databricks クラスターのコードを実行する機能があり、 Custom Scripts in Workflows にて実行することで Treasure Data 側のワークフロー機能により Databricks の操作を実施できる可能性があります。ワークフローを Treasure Data 側で管理したい場合には有益な利用方法となります。他の方法として Databricks 上にコードを配置してAPIで実行することも可能であるため、ユースケースに応じて使い分けることができます。

引用元:Databricks Connect とは - Azure Databricks | Microsoft Learn