概要
Databricks から Python にて Azure SQL Database へ下記表の方法により実行する方法を共有します。Spark dataframe (jdbc) 経由で操作する方法にて、prepareQueryオプションにて DDL 等の実行できましたが、継続的に実行可能であることが保証できないため、本番環境での利用をおすすめしません。
| # | 操作方法 | 事前準備 |
|---|---|---|
| 1 | Spark dataframe (jdbc) 経由で操作 | 特になし |
| 2 | pyodbc にて操作 | ODBC を事前にインストール |
| 3 | pymsql にて操作 | pymsql を事前にインストール |
Azure SQL Database に対して Spark コネクターにより接続することも可能ですが、サポートの観点で検証対象外としました。詳細については、次の記事に記載しています。
Azure SQL Database から参照(SELECT 操作)だけを実施する場合には、Lakehouse フェデレーション機能の利用を検討してください。

引用元:Lakehouse フェデレーションを使用してクエリを実行する - Azure Databricks | Microsoft Learn

引用元:Lakehouse フェデレーションを使用してクエリを実行する - Azure Databricks | Microsoft Learn
基本的な情報の整理
Spark dataframe (jdbc) に関する情報
Spark Dataframe 操作時にformatをsqlserverと指定することで、読み込みと書き込みが実施できます。

引用元:Azure Databricks を使用して SQL Server にクエリを実行する - Azure Databricks | Microsoft Learn
従来の jdbc URL で接続する方法はレガシー扱いとなってしまったようです。

引用元:Azure Databricks を使用して SQL Server にクエリを実行する - Azure Databricks | Microsoft Learn
prepareQueryオプションにて SQL を実行できるようですが、スキーマ作成などのいくつかの SQL ではエラーとなりました。
sql = """
CREATE SCHEMA abc;
"""
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("prepareQuery", sql)
.option("dbTable", "(select 1 as test) src")
.load()
)

com.microsoft.sqlserver.jdbc.SQLServerException: Incorrect syntax near the keyword 'SELECT'.
pyodbc と pymsql に関する情報
Python から Azure SQL Database を操作するドライバーとして次のように紹介されており、 pyodbc を利用することが推奨されているようです。

引用元:SQL Server 用 Python ドライバー - Python driver for SQL Server | Microsoft Learn
pyodbc については、Databricks Runtime 11.3 LTS 以降であれば、Runtime にデフォルトでインストールされております。

引用元:Databricks Runtime 11.3 LTS - Azure Databricks | Microsoft Learn
実行コードと実行結果
Spark dataframe (jdbc) 経由で操作
Azure SQL Database に対する接続情報に関する値を変更にセット。
server = "ads-01" ## サーバー名
database = "ads-01" ## データベース名
username = "user" ## Azure SQL DB のユーザー名
password = "password" ## Azure SQL DB のパスワード

テーブル作成とデータ挿入を実施する SQL 文を実行。
# CREATE TABLE の実行
sql = """
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[create_tble_01]') AND type in (N'U'))
DROP TABLE [dbo].[create_tble_01]
;
CREATE TABLE dbo.create_tble_01
(
str_col varchar(100) COLLATE Japanese_CI_AS
)
;
INSERT INTO dbo.create_tble_01
SELECT 'abc' as str_col
UNION ALL
SELECT N'あいう' as str_col
UNION ALL
SELECT NULL as str_col
;
"""
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("prepareQuery", sql)
.option("dbTable", "(select 1 as test) src")
.load()
)

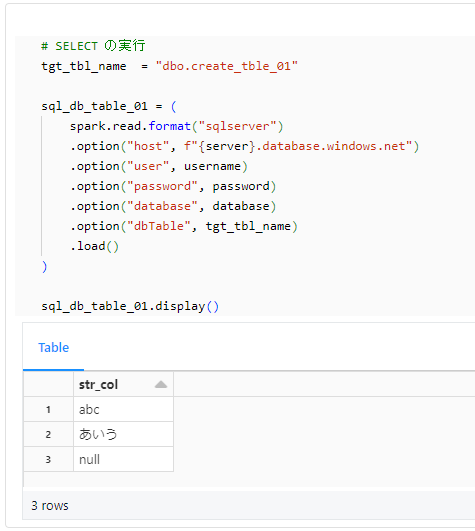
テーブルにデータが書き込まれたことを確認。
# SELECT の実行
tgt_tbl_name = "dbo.create_tble_01"
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_01.display()
次のコードを実行することで、書き込みの実施も可能。
src_schema = "str_col string"
src_data = [
{
"str_col": "abc",
},
{
"str_col": "あいう",
},
{
"str_col": None,
},
]
df = spark.createDataFrame(src_data,src_schema)
tgt_tbl_name = "dbo.create_tble_01"
(
df.write.format("sqlserver")
.mode("overwrite")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("truncate", True)
.option("dbTable", tgt_tbl_name)
.save()
)

pyodbc にて操作
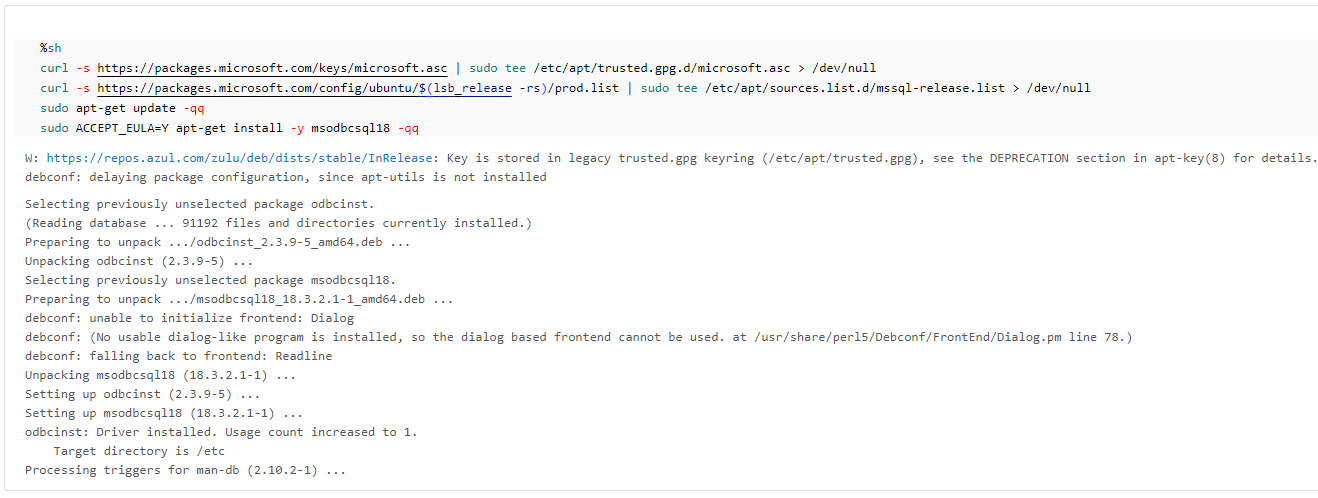
Azure SQL Database (SQL Server)の ODBC をインストール。
%sh
curl -s https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.asc > /dev/null
curl -s https://packages.microsoft.com/config/ubuntu/$(lsb_release -rs)/prod.list | sudo tee /etc/apt/sources.list.d/mssql-release.list > /dev/null
sudo apt-get update -qq
sudo ACCEPT_EULA=Y apt-get install -y msodbcsql18 -qq
Azure SQL Database に対する接続情報に関する値を変更にセット。
server = "ads-01" ## サーバー名
database = "ads-01" ## データベース名
username = "user" ## Azure SQL DB のユーザー名
password = "password" ## Azure SQL DB のパスワード

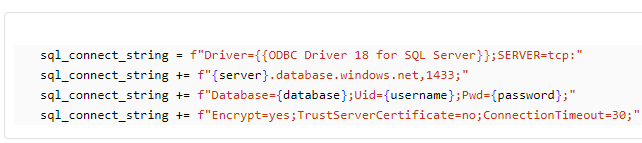
pyodbc にて利用する接続文字列を変数にセット。
sql_connect_string = f"Driver={{ODBC Driver 18 for SQL Server}};SERVER=tcp:"
sql_connect_string += f"{server}.database.windows.net,1433;"
sql_connect_string += f"Database={database};Uid={username};Pwd={password};"
sql_connect_string += f"Encrypt=yes;TrustServerCertificate=no;ConnectionTimeout=30;"
テーブル作成とデータ挿入を実施する SQL 文を実行。
import pyodbc
sql = """
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[create_tble_02]') AND type in (N'U'))
DROP TABLE [dbo].[create_tble_02]
;
CREATE TABLE dbo.create_tble_02
(
str_col varchar(100) COLLATE Japanese_CI_AS
)
;
INSERT INTO dbo.create_tble_02
SELECT 'abc' as str_col
UNION ALL
SELECT N'あいう' as str_col
UNION ALL
SELECT NULL as str_col
;
"""
try:
with pyodbc.connect(sql_connect_string, timeout=300) as conn:
with conn.cursor() as cursor:
cursor.execute(sql)
conn.commit()
except pyodbc.Error as e:
print("An error occurred while connecting to the database.")
print(e)

テーブルにデータが書き込まれたことを確認。
# SELECT の実行
tgt_tbl_name = "dbo.create_tble_02"
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_01.display()
pymsql にて操作
%pip install pymssql -q
dbutils.library.restartPython()

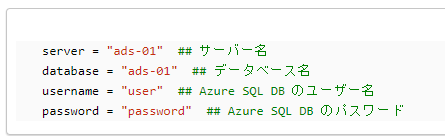
Azure SQL Database に対する接続情報に関する値を変更にセット。
server = "ads-01" ## サーバー名
database = "ads-01" ## データベース名
username = "user" ## Azure SQL DB のユーザー名
password = "password" ## Azure SQL DB のパスワード
テーブル作成とデータ挿入を実施する SQL 文を実行。
import pymssql
server_for_pymssql = f"{server}.database.windows.net"
sql = """
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[create_tble_03]') AND type in (N'U'))
DROP TABLE [dbo].[create_tble_03]
;
CREATE TABLE dbo.create_tble_03
(
str_col varchar(100) COLLATE Japanese_CI_AS
)
;
INSERT INTO dbo.create_tble_03
SELECT 'abc' as str_col
UNION ALL
SELECT N'あいう' as str_col
UNION ALL
SELECT NULL as str_col
;
"""
# Connect to the database
with pymssql.connect(server_for_pymssql, username, password, database) as conn:
# Create a cursor object
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()

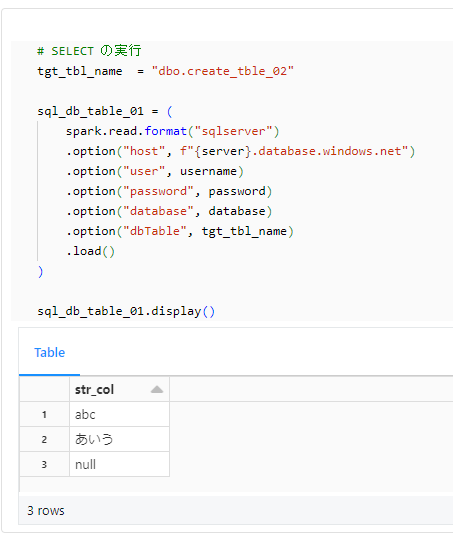
テーブルにデータが書き込まれたことを確認。
# SELECT の実行
tgt_tbl_name = "dbo.create_tble_03"
sql_db_table_01 = (
spark.read.format("sqlserver")
.option("host", f"{server}.database.windows.net")
.option("user", username)
.option("password", password)
.option("database", database)
.option("dbTable", tgt_tbl_name)
.load()
)
sql_db_table_01.display()

事後処理
Azure SQL Database に対して 次の SQL を実行してテーブルを削除。
DROP TABLE dbo.create_tble_01
GO
DROP TABLE dbo.create_tble_02
GO
DROP TABLE dbo.create_tble_03
GO
