概要
Databricks ベースにしたデータ分析基盤から Azure SQL Database へのデータ連携(書き込みと読み込み)方法を検討内容を共有します。
サービスを検討する際には次の観点で検討することをおすすめします。機能の比較を行う際には、機能比較表を作成することがありますが、クラウドサービスはどんどん機能が追加されるため、機能比較表の機能数で判断する方法は避けるべきです。本記事では、この観点では整理しきれておりません。
- 機能
- 性能
- 使い勝手
- コスト
Databricks ベースにしたデータ分析基盤としては、次のようなサービスで構成していることを前提としてます。
| # | サービス | 主な利用目的 |
|---|---|---|
| 1 | Azure Databricks | メダリオンアーキテクチャをベースにしてデータを管理する |
| 2 | Azure Data factory | ワークフロー管理機能、GUI 型ETL機能を利用する |
| 3 | Azure Storage | データを保持する |
| 4 | Azure SQL Database | OLTP のような機能が必要となるデータ処理を実施する |
検討メモ
Azure SQL Database の前提
Azure SQL Database では、次のような購入モデルがあります。3 については大量データを書き込むようなケースでは不向きであり、1 か 2 のどちらかを選択することが多いです。エラスティックプール機能についてはリソースの最適な割当が実施されないことがあるため、 私は利用を避けることが多いです。
- プロビジョニング済み仮想コアベースの購入モデル
- サーバーレス仮想コアベースの購入モデル
- DTU ベースの購入モデル
Azure SQL Database では、SQL Server で利用できた括インポート操作の最小ログ記録が実施できないため、データ書き込み性能が高くならない場合があることに留意してください。
Azure Database へのデータ連携方法の検討
- Databricks から Spark コネクター によりデータ連携する方法
- Databricks から jdbc によりデータ連携する方法
- Azure SQL Database の にて Azure Blob Storage内のデータへの一括アクセスによりデータ連携する方法
- Azure Data factory のデータフローによりデータ連携する方法
- Azure Data factory のコピーアクティビティによりデータ連携する方法
1. Databricks から Spark コネクター によりデータ連携する方法
製品サポートと Spark バージョンのサポートに懸念があったため、Spark コネクターによりデータ連携する方法を採用しませんでした。
Microsoft 社のサポートを受けられず、コミュニティでのサポートとなる旨がドキュメントに記載されています。

引用元:Apache Spark コネクタを使用した SQL Database - Azure Databricks | Microsoft Learn
サポートされている Spark のバージョンが次のように記載されており、 Spark の新バージョンがどんどんリリースされる Databricksで利用する際の懸念事項となります。
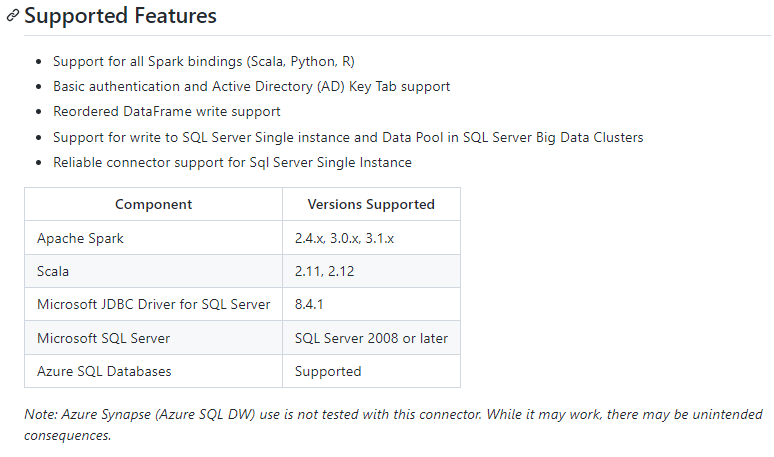
引用元:microsoft/sql-spark-connector: Apache Spark Connector for SQL Server and Azure SQL (github.com)
以上のサポートに懸念があるため今回は採用しませんでしたが、jdbc によりデータ連携する方法より性能が高くなるようなので、上記のリスクを許容できる場合には選択してください。

引用元:SQL Server 用の Apache Spark コネクタ - Spark connector for SQL Server | Microsoft Learn
Spark コネクターを利用する際には、下記の記事も参考になりそうです。
2. Databricks から jdbc によりデータ連携する方法
今回は、jdbc によりデータ連携する方法を採用しました。jdbc での書き込みの性能検証を実施したところ、比較的満足のいく結果を得られました。
並列で処理できるようで、 Spark のコア数分を並列で処理するようにしました。
spark_core = spark.sparkContext.defaultParallelism
print(spark_core)
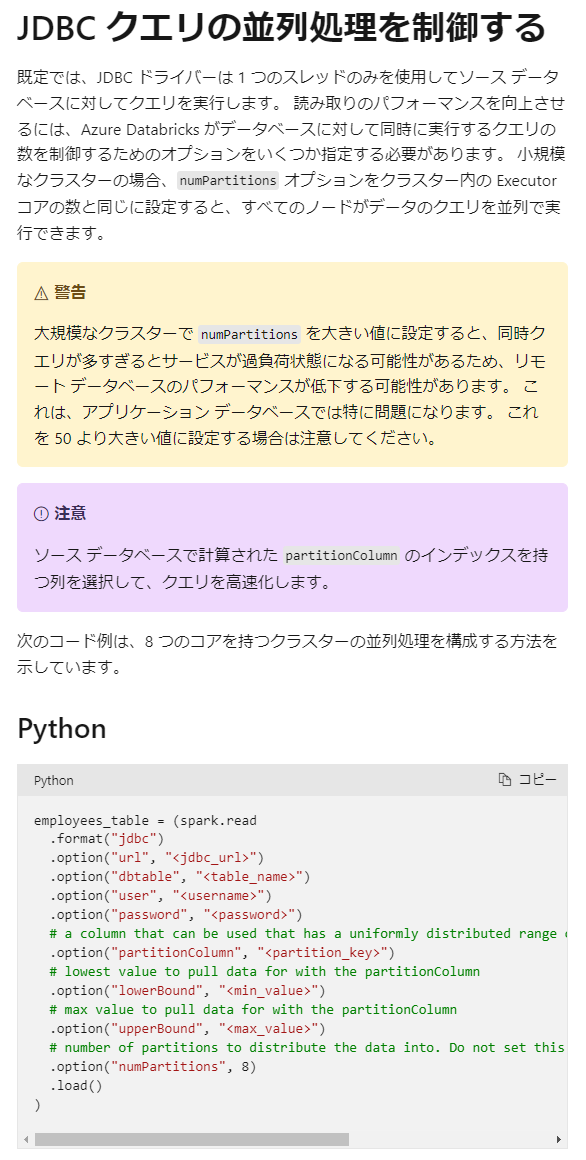
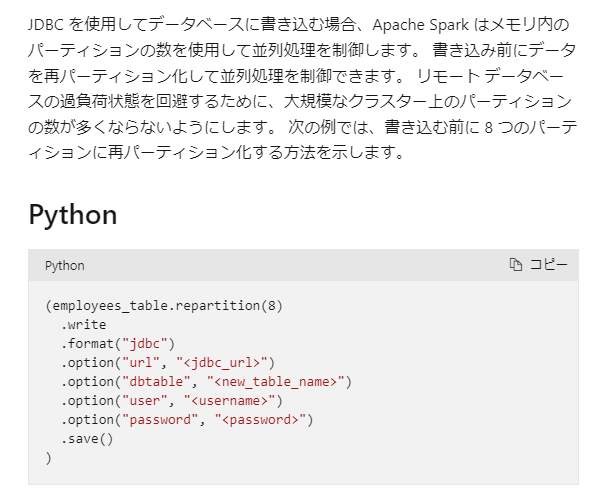
引用元:JDBC を使用したデータベースのクエリ - Azure Databricks | Microsoft Learn
データ書き込みの性能を向上させるために、batchsize オプションの調整が有効でした。

引用元:JDBC To Other Databases - Spark 3.3.1 Documentation (apache.org)
懸念事項としては、Azure AD(サービスプリンシパル等)による認証する方法が標準で利用する方法を確認できず、SQL ユーザー認証になることです。
3. Azure SQL Database の にて Azure SQL Database にて Azure Blob Storage内のデータへの一括アクセスによりデータ連携する方法
Databricks にて Azure Storage に対してファイルを取り込み後、Azure SQL Database の にて zure Blob Storage内のデータへの一括アクセスする機能によりデータ連携する方法も検討しましたが、 Parquet ファイル形式に対応していなかっため採用しませんでした。Azure SQL Database では、Azure Blob Storage からのインポートのみが実施でき、エクスポートはできないようです。
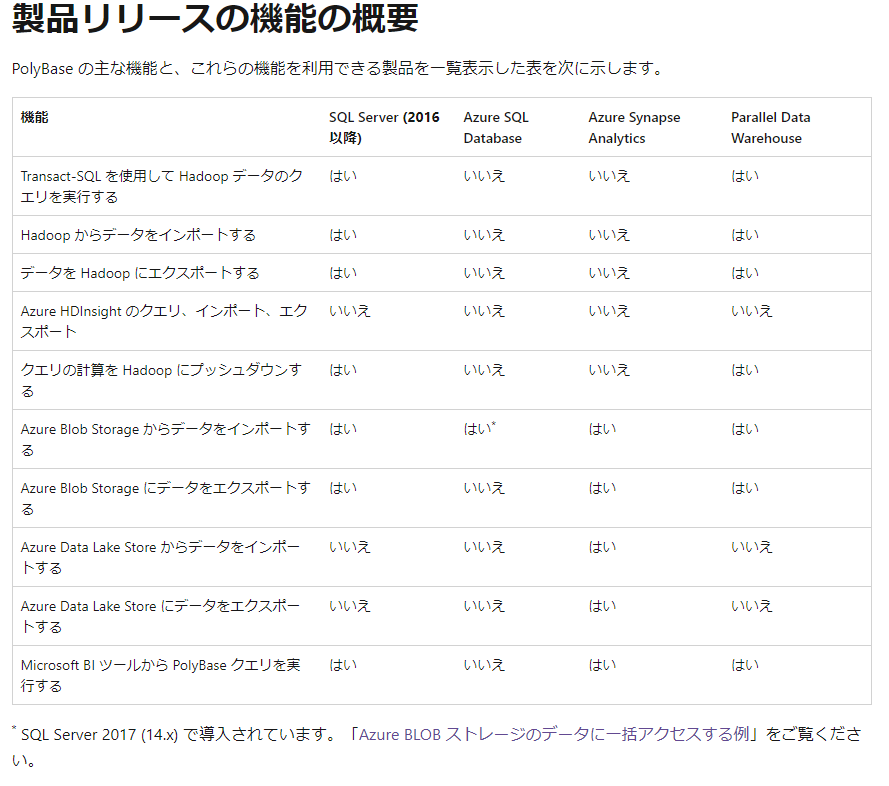
引用元: PolyBase の機能と制限事項 - SQL Server | Microsoft Learn
Azure SQL Database にデータ仮想化機能が実装され、parquet 形式でのインポート/エクスポートが実施できるようになった場合には、有力な選択肢となりそうです。
- PolyBase によるデータ仮想化の概要 - SQL Server | Microsoft Learn
- データの仮想化 - Azure SQL Managed Instance | Microsoft Learn
Azure SQL Database <-> Azure Storage の認証に、マネージドIDを利用できそうです。
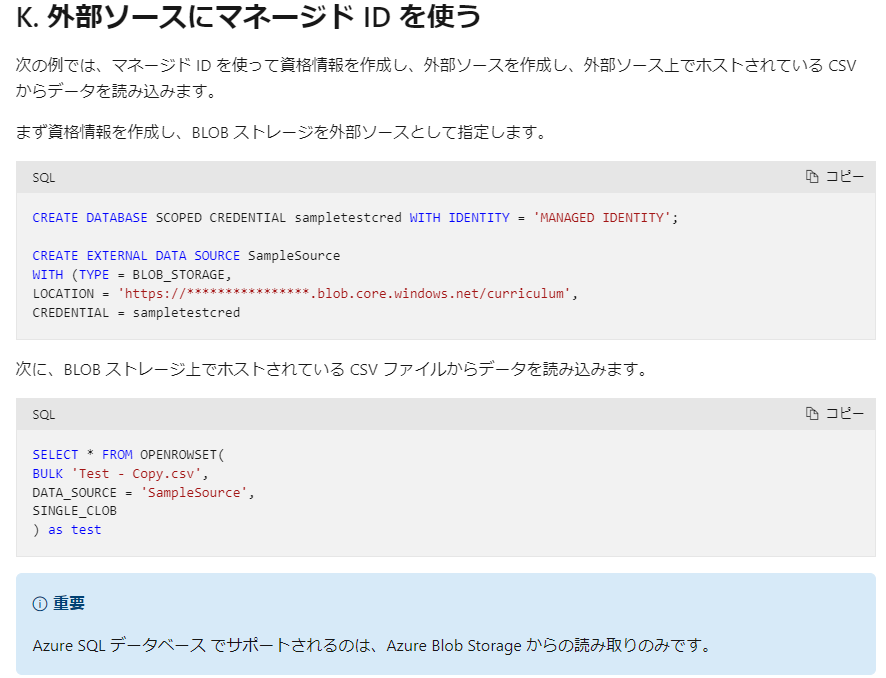
引用元:OPENROWSET (Transact-SQL) - SQL Server | Microsoft Learn
4. Azure Data factory のデータフローによりデータ連携する方法
下記の理由で、採用しませんでした。GUI での開発を行いたい場合には、有力な選択肢です。
- Azreu Data factory 側でロジックをあまり保持させたくないこと
5. Azure Data factory のコピーアクティビティによりデータ連携する方法
下記の理由で、採用しませんでした。
- Azreu Data factory 側でロジックをあまり保持させたくないこと
- 大量データ時の性能に対して懸念があること、