概要
Fivetran は、さまざまなソースシステムからのデータ取得をフルマネージドで実行し、初回の全量コピーから増分アップデート、スキーマ変更への対応まで自動化するデータ統合サービスです。本記事では、 700 種類以上のコネクタ や Monthly Active Rows(MAR) を基準とした課金モデル、SCD Type 1/2 に対応可能なデータ同期モード(Soft Delete Mode / History mode)、多彩な CDC(Change Data Capture)手法、Transformations 機能による変換ワークフローなど、Fivetran が提供する主要機能と特長を整理しています。また、ネットワーク要件に合わせて選択できる SaaS・Hybrid・Self-Hosted といった複数のデプロイメントモデルや、 Data Lakes への書き込みを可能にする Managed Data Lakes Service 、独自コネクタを開発できる Connector SDK など、高度な活用方法についても解説し、導入時の検討事項を包括的にまとめています。
1. Fivetran について
Fivetran は、データ同期の構築・管理を自動化するフルマネージドのデータ統合サービスです。わずかな設定で多様なソースシステムとのデータ連携が可能で、最初にソースの全データをコピーし、以降は増分アップデート(更新分のみの抽出・ロード)を実行します。スキーマ変更への追従も自動的に行われます。さらに課金モデルは CPU コア数ではなく レコード数 が基準のため、高頻度な同期や高負荷が想定される場合でも予測しやすいコストで運用できます。また、 Transformations(データ変換処理) 機能により、必要な変換・整形処理を一元管理できる点も大きな特徴です。

出所: What is Fivetran? | Blog | Fivetran
Fivetran の製品戦略は、ユーザーに価値ある体験を提供するための指針として、以下 5 つのプリンシパル(基本原則)に基づいています。これらの原則は、製品開発や意思決定の場面で一貫性をもたらし、ユーザーのデータ連携に関する課題解決を目指して設計されています。
- The core of Fivetran is and will always be connectors
- One default, simple, predictable choice
- Connectors just work
- Your data is secure
- Fast data movement

引用元: Product Principles
- コアは常にコネクタ
- デフォルトはシンプルで予測可能な一択
- コネクタは「ただ動く」
- データは安全である
- 迅速なデータ移動
上記の翻訳
2. Fivetran のユニーク性
Fivetran の主なユニークポイントは、以下のとおりです。
-
700 以上のコネクタとシンプルな設定
多数のデータソースを、極めてシンプルな設定で連携できます。これにより、開発・運用コストを削減しつつ、実運用開始までの期間を短縮できます。 -
整理されたデータ連携手順とデータモデル
ソースシステムごとにデータ連携手順やデータモデルが明確化されているため、分析や可視化などのデータ活用を効率的に進められます。 -
MAR(Monthly Active Rows)ベースの料金体系
コストを予測しやすく、高頻度かつ安定したデータ同期を実現します。高負荷時でもリソース不足を心配する必要がなく、必要に応じたタイミングで柔軟に同期を設定できます。
3. Fivetran 基礎
3-1. 全体像
Fivetran のアーキテクチャ全体像を、下記の図に示します。一般的には「データの取得・同期機能」に注目されがちですが、実際には スキーマ(メタデータ)の自動反映 や データ変換機能 なども含まれており、データ統合を継続的・効率的に運用するための仕組みを幅広くカバーしています。コネクタによるソースシステムからのデータ取得だけでなく、ソース側のスキーマ変更を Destination に自動で反映したり、dbt Core や外部サービスを利用してデータ変換処理を行ったりと、複数工程が一貫して管理できる点が特長です。
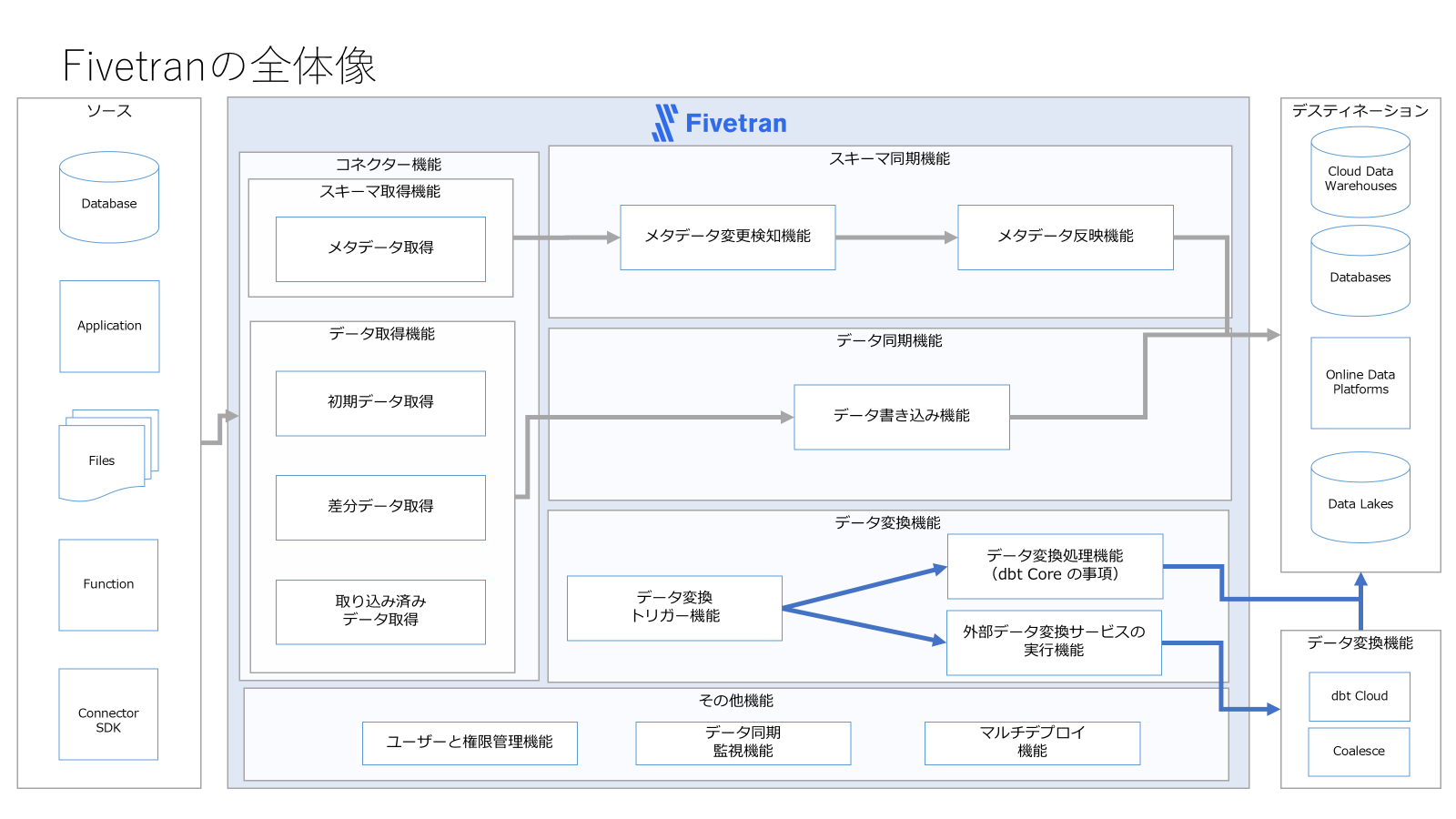
| カテゴリー | 機能 | 説明 |
|---|---|---|
| コネクタ機能 | メタデータ取得機能 | ソースシステムに存在するテーブル、スキーマ、カラムなどのメタデータを抽出する機能。 |
| コネクタ機能 | データ取得機能 | ソースシステムからデータを取得する機能。 |
| スキーマ同期機能 | メタデータ変更検知機能 | ソースのスキーマ変更(カラムの追加・削除、データ型の変更など)を検知する機能。 |
| スキーマ同期機能 | メタデータ反映機能 | 検知されたスキーマ変更を基に、転送先(Destination)のメタデータを更新する機能。 |
| データ同期機能 | データ書き込み機能 | ユーザー設定の同期モードに従い、抽出データを転送先に効率的に書き込む機能。必要に応じてハッシュ化等の変換処理も実施。 |
| データ変換機能 | データ変換トリガー機能 | 事前定義された条件やスケジュールに基づき、データ変換プロセスの開始を自動的にトリガーする機能。 |
| データ変換機能 | データ事前変換機能 | Fivetran が提供する dbt core 環境から変換処理を実行する機能。 |
| データ変換機能 | 外部データ変換サービスの実行機能 | Fivetran から外部のデータ変換サービスと連携し、必要な変換処理を実行できる機能。 |
| その他機能 | データ同期監視機能 | データ連携の進捗、エラー、遅延等をリアルタイムで監視し、異常時にアラートを送信することでシステムの健全性を維持する機能。 |
| その他機能 | ユーザーと権限管理機能 | ユーザーの認証・認可、アクセス管理および権限設定を実施する機能。 |
| その他機能 | マルチデプロイ機能 | クラウド(SaaS)環境、オンプレミス、またはハイブリッド環境など、さまざまな運用形態に柔軟に対応したデプロイメントを実現する機能。 |
3-2. MAR について
MAR は Fivetran の使用量ベースの料金体系における重要指標で、特定の暦月にソースシステムから Destination に同期された一意のプライマリキーの数を指します。月の間に同じ行が何度更新されても、1 回しか課金対象になりません。Fivetran は増分更新により同期を行うため、処理対象は毎回変更のあった行のみです。
MAR is the number of distinct primary keys synced from the source system to your destination in a given calendar month.
出所: Usage-Based Pricing | Monthly Active Rows
MAR は、特定の暦月にソース システムから Destination に同期された個別のプライマリキーの数です。
上記翻訳
CPU やメモリを基準とした従来の課金モデルに慣れていると違和感があるかもしれませんが、MAR による価格体系には以下のメリットがあります。
-
コストの予測可能性
初回同期(Initial sync)以降は更新分のみが課金対象です。多くの場合、データ増分の規則性があるため TCO(Total Cost of Ownership)を予測しやすくなります。 -
同期頻度の柔軟化
同期を頻繁に行っても課金対象はアクティブ行なので、大きくコストが変動しません。ビジネス要件やログの蓄積要件に合わせ、最適なタイミング・頻度で同期を実行できます。 -
運用の安定化
CPU やメモリなどのリソース制限を考慮する必要がないため、データ量が急増しても処理遅延や同期失敗を最小化しやすくなります。
MAR の使用量を最適化するには、ソースシステムがどのように更新され、MAR に影響を与えるかを把握することが重要です。コネクタごとの MAR 計算方法や課金ルールは下記のドキュメントにまとまっています。

たとえば、Google Sheets の場合は参照範囲の全行が対象となるなど、コネクタ固有の取り扱いが詳しく記載されています。
Upon each subsequent incremental sync, the entire named range is scanned and any changes are reflected in the destination

出所:MAR Management for Google Sheets
後続の増分同期のたびに、名前付き範囲全体がスキャンされ、変更が宛先に反映されます
上記翻訳
また、以下の処理は MAR に含まれず、初回同期(Initial sync)も無料となっています。
- Initial syncs
- Connection trials
- Private preview connectors (excluding destinations)
- Fivetran system tables
- Fivetran Platform connector
- Re-syncs
- HVR Troubleshooting Window
- Accounts with a legacy pricing plan
- Free plan
- Promotions
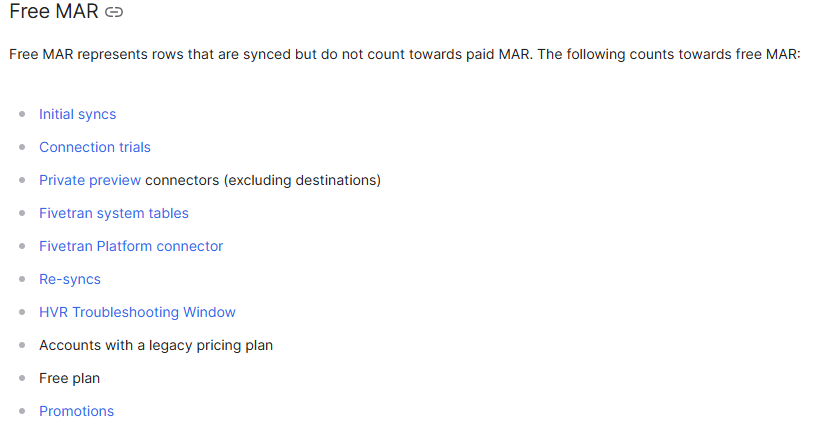
出所: Usage-Based Pricing | Monthly Active Rows
3-3. Connector と Destination
Fivetran では、データ取得元を Connector(コネクター)と呼び、データ書き込み先を Destination(デスティネーション)と呼びます。
コネクターは下記のように分類され、それぞれに詳細なドキュメントが用意されています。また、Connector SDK により独自のコネクターを開発・追加することも可能です。
| # | コネクター分類 | 概要 |
|---|---|---|
| 1 | Database | リレーショナルや NoSQL などのデータベースからデータを抽出・同期するためのコネクタ。 例: MySQL、PostgreSQL、SQL Server、Oracle など |
| 2 | Application | SaaS アプリケーションやクラウドサービスなど外部アプリケーションのデータ取得用コネクタ。 例: Salesforce、HubSpot、Google Analytics など |
| 3 | Event | イベントソースやストリーミングデータからリアルタイムに情報を取得し、パイプラインに取り込むためのコネクタ |
| 4 | Files | ファイルストレージやファイル系アプリケーションからデータを抽出するコネクタ |
| 5 | Function | AWS Lambda、Azure Functions、Google Cloud Functions などサーバーレス環境でカスタムパイプラインを構築するためのコネクタ |
| 6 | Connector SDK | Python ベースのカスタムコネクタを作成可能 |
Destination には主に下記の分類があります。Fivetran はクラウドデータウェアハウスのみならず、広範囲のデータストアをサポートします。Managed Data Lakes Service ではクラウドストレージ上に OTF(Open Table Format)で書き込みが可能です(詳細は後述)。
- Cloud Data Warehouses
- Databases
- Online Data Platforms
- Data Lakes
- Managed Data Lakes Service
3-4. 差分データの検出
Fivetran では、ソースデータの変更を検知し、更新差分のみを別のシステムに反映させる CDC(Change Data Capture)を用いてレプリケーションします。代表的な手法は下記のとおりです。
| No. | CDC 手法 | 概要 |
|---|---|---|
| 1 | Log-based CDC | データベースのトランザクションログを直接読み取り、変更をリアルタイムに検出。整合性が高くシステム負荷が小さい手法 |
| 2 | Timestamp-based CDC (Query-based CDC) |
タイムスタンプや更新日時に基づいて定期的にクエリを実行し、変更レコードを抽出。実装は単純だが、タイムスタンプ精度やクエリ性能に依存 |
| 3 | Log-free CDC (TeleportSync) |
ログに依存せず、定期的なスナップショットと差分比較で変更を検出。ログベースが使えない環境でも完全同期が可能 |
| 4 | Trigger-based CDC | DB のトリガー機能を用いて変更を検知。即時性は高いが、トリガーの実行がシステムパフォーマンスに影響を与え得る |
リレーショナル DB をソースとする際は、運用形態やパフォーマンス要件に応じた CDC 手法の選定が重要です。たとえば、Log-based CDC はリアルタイム性・効率性に優れますが、DB のログ設定を変更する必要が生じる場合があります。Timestamp-based CDC はシンプルな反面、削除レコードの検出が難しくなるなどのデメリットがあります。
Fivetran の TeleportSync(Log-free CDC)は、定期的にスナップショットを取得し差分を計算する手法で、READ 権限のみで削除レコードも把握できます。大規模テーブルの場合は別途検討が必要ですが、ログを設定しにくい環境で有効です。
3-5. Sync
Fivetran の同期(Sync)には以下の種類があります。通常は Initial sync(初回に全データ取得)を行い、以後は Incremental sync(差分のみ)で更新を取り込みます。
| 同期方法 | 説明 |
|---|---|
| Initial sync | コネクタ作成時に最初に実行する履歴データの同期(Historical sync) |
| Priority-first sync | 初回およびその後の同期で「より最近のデータ」を優先的に取得。まず最新データをロードし、次いで古いデータをバックグラウンドで取得 |
| Incremental sync | 新規または変更されたデータのみを取り込む同期 |
| Rollback sync | 1 日 1 回自動実行される仕組みで、一定期間(Rollback window)遡ってソースを再確認し、更新漏れを防ぐ同期 |
| Re-import | 毎回テーブル全体を再取り込み(全件上書き)する必要がある場合に用いる同期 |
| Re-sync | Destination とソースで不整合が発生した場合に、全件または部分的にテーブルを再同期して修正 |
| Full re-sync | すべてのテーブルを再同期し、 Destination を完全に上書きする方式 |
| Table re-sync | 特定テーブルだけを再同期する方式 |
| Historical sync | 初回および任意でトリガー可能な再同期。ソース全体を丸ごと取得 |
3-6. Sync Modes
Fivetran での書き込みモードには、主に以下の 2 つがあります。Soft Delete Mode では削除レコードが論理削除されたデータとして保持され、History Mode ではレコードのバージョンを管理したデータが保持されます。
| No. | モード | 説明 |
|---|---|---|
| 1 | Soft Delete Mode | SCD Type 1 相当の書き込み |
| 2 | History Mode | SCD Type 2 相当の書き込み |
History Mode のテーブルに対するクエリ方法が下記の記事で紹介されています。
3-7. Sync 時のデータ変換
Sync 時には、以下のようなデータ変換が可能です。
| No. | 機能 | 説明 | メリット / 目的 |
|---|---|---|---|
| 1 | Row Filtering | 指定条件に合致する行のみを同期 | 不要データを除外することで転送量の削減やパフォーマンス向上に寄与 |
| 2 | Data Blocking | 機密データや不要データを同期から完全除外 | コンプライアンス対応やプライバシー保護に有効 |
| 3 | Column Hashing | 特定列をハッシュ化 | 元データを隠しつつ比較・分析が可能。セキュリティ向上につながる |
詳細は下記ドキュメントを参照してください。
3-8. Schema Migration
Fivetran はソースで行われるスキーマ変更を自動検知し、 Destination に反映します。たとえば、新たにカラムが追加された場合でも自動で Destination に追加されます。
下記ドキュメントに、どのような変更を検知し、どのように対応するかが記載されています。
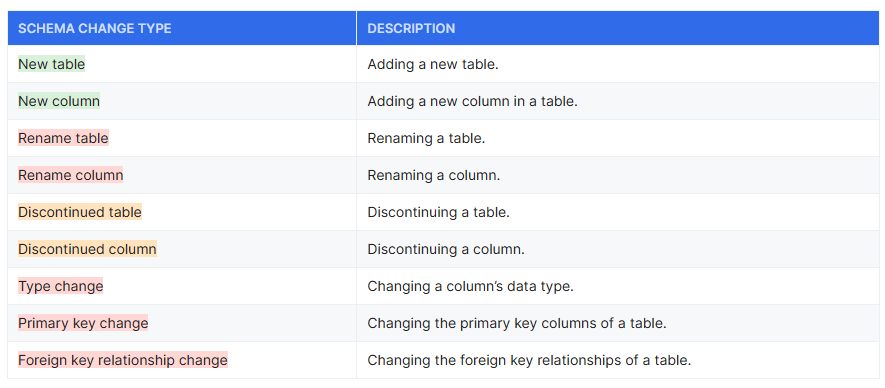
出所: How schema migrations work | Fivetran connector strategy
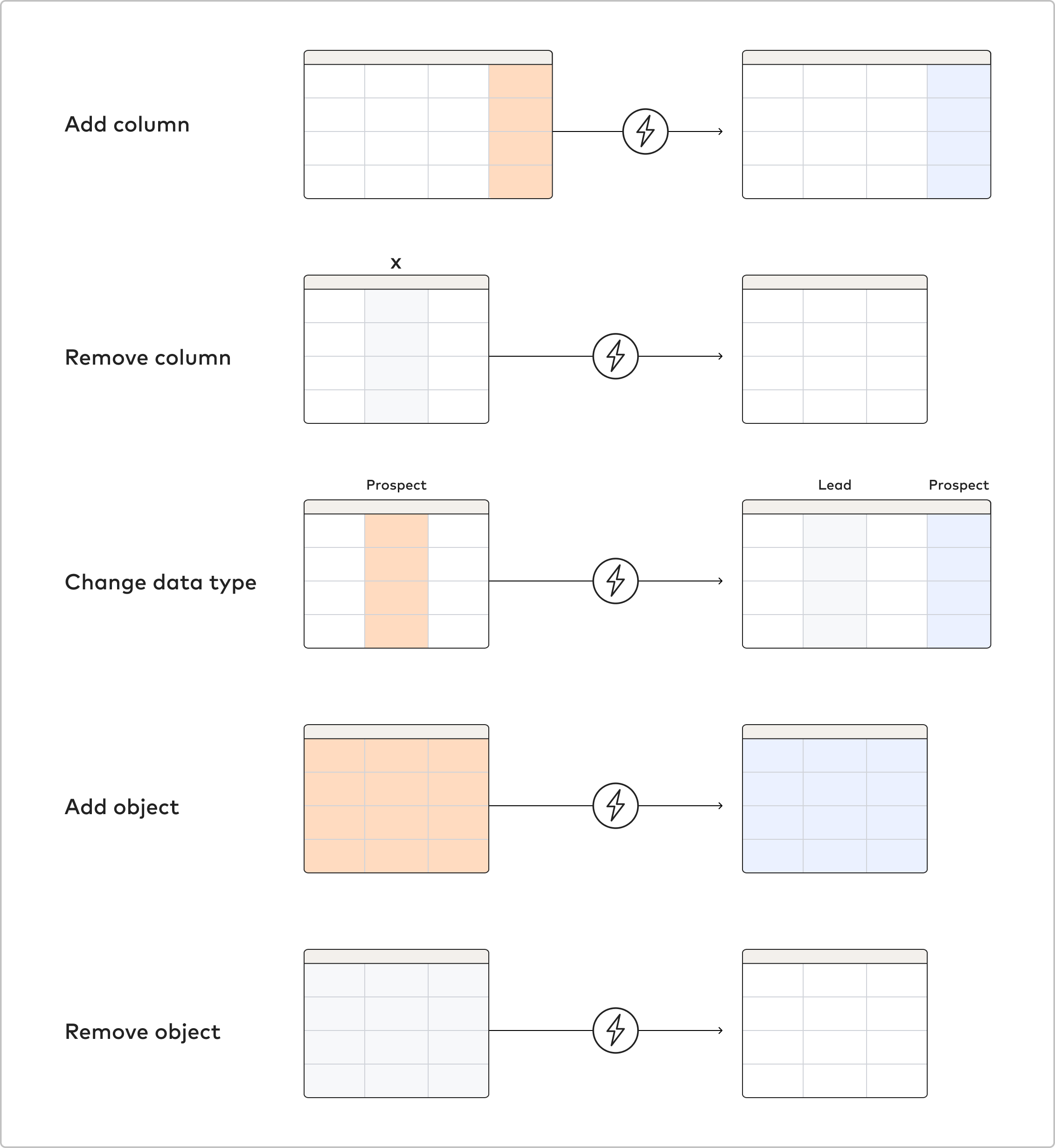
出所: Supported Destinations | Fivetran destination documentation and setup
3-9. Fivetran におけるデータ変換処理
Fivetran でのデータ変換(Transformations)は、組み込みデータモデル(Pre-built Data Models) か 外部ツールとの連携(Integrations) のいずれかで実行します。Transformations そのものは DWH や外部システムで実行されるため、コンピューティングリソースは Fivetran 自体ではなく Destination や連携先が担う形となります。
-
組み込みデータモデル(Pre-built Data Models)
Fivetran があらかじめ用意した dbt モデルを活用できます。-
Quickstart Data Models
ダッシュボード上から直接追加可能で、ユーザーが dbt プロジェクトを自前で用意する必要がありません。 -
Fivetran Data Models
ユーザーの dbt プロジェクトにインポートして利用します。既存プロジェクトと統合しやすく、柔軟なカスタマイズが可能です。
-
Quickstart Data Models
-
外部ツールとの連携(Integrations)
dbt Core や dbt Cloud、Coalesce などのツールと連携できます。ユーザーが定義した SQL 変換を一元管理し、スケジューリングできます。-
Fivetran-hosted dbt Core Integration
Fivetran がホストする dbt Core 上で変換を実行。Fivetran ダッシュボードからジョブ管理が可能です。 -
dbt Cloud Orchestration
dbt Cloud と連携し、より高度な変換やスケジューリングを行います。 -
Coalesce Orchestration
Coalesce と連携して、複雑な変換やワークフロー管理が可能です。
-
Fivetran-hosted dbt Core Integration
なお、Transformations のコストは MAR とは別の料金体系で、Quickstart Data Models と Fivetran-hosted dbt Core Integration の場合に課金対象となります。詳しくは公式ドキュメントを参照してください。
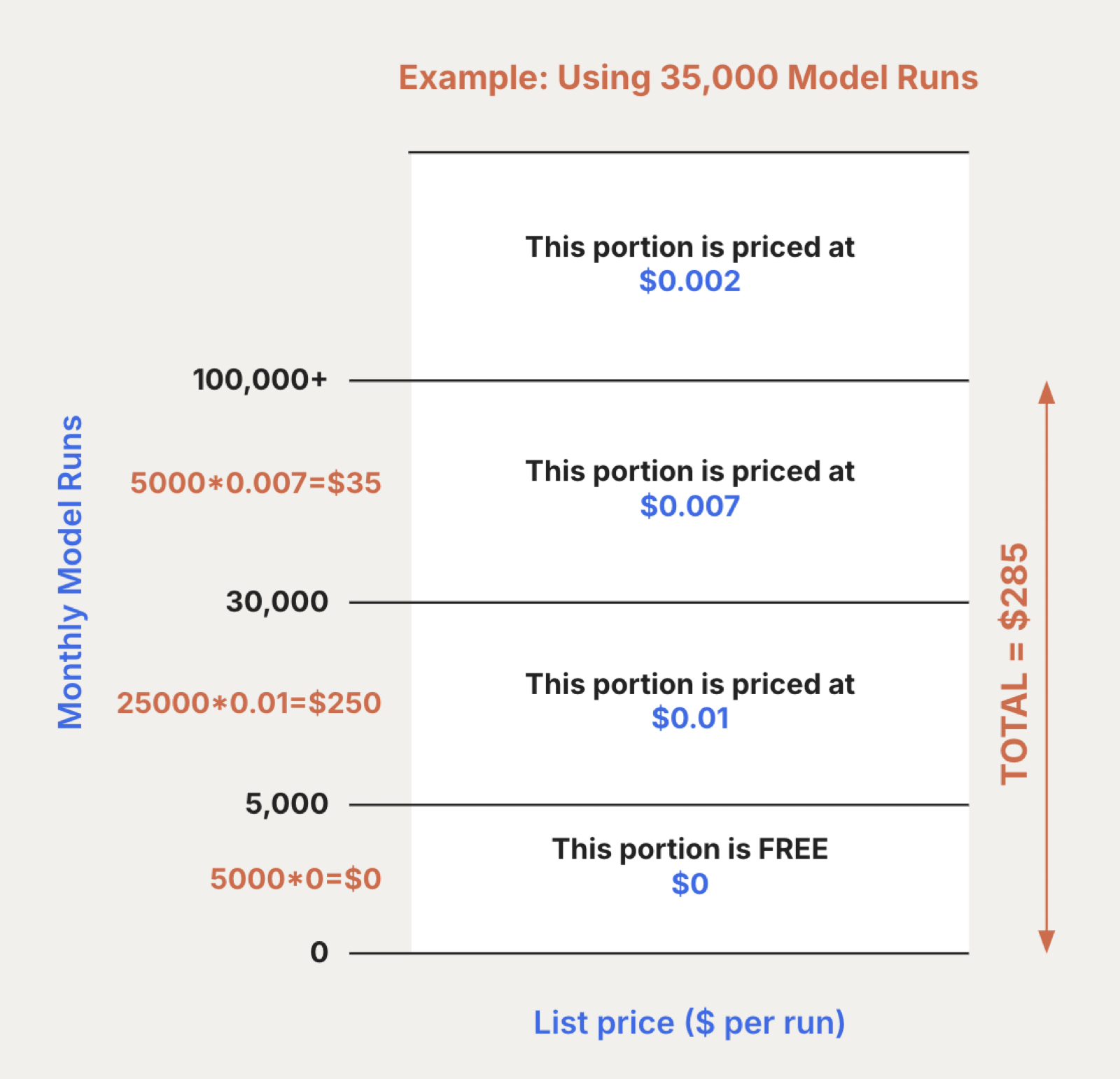
出所: Transformations Pricing | Monthly Model Runs
3-10. エラーのリカバリー
Fivetran はエラー検知とリカバリーが自動化されており、ネットワーク障害やソース API のレート制限超過、接続不良などの一般的なエラーは Fivetran 側が自動検知しリトライ・一時待機を行います。ダッシュボード上のアラート機能により、エラー発生時には通知と対処方法が提示されるため、ダウンタイムを最小化できます。
- Cost-effective ELT: Four factors to consider | Blog | Fivetran
- Fivetran Alerts
- Fivetran Notifications
3-11. Fivetran における Plan
Fivetran には複数のプランが存在し、機能差やネットワーク関連オプションの可否(例: PrivateLink など)が異なります。必要に応じて上位プランの導入を検討してください。また、大量データを扱う場合は、High-Volume Agent Connectors(HVA)が利用可能か確認しましょう。専用エージェントを介して効率的な大量データ取り込みを実現します。
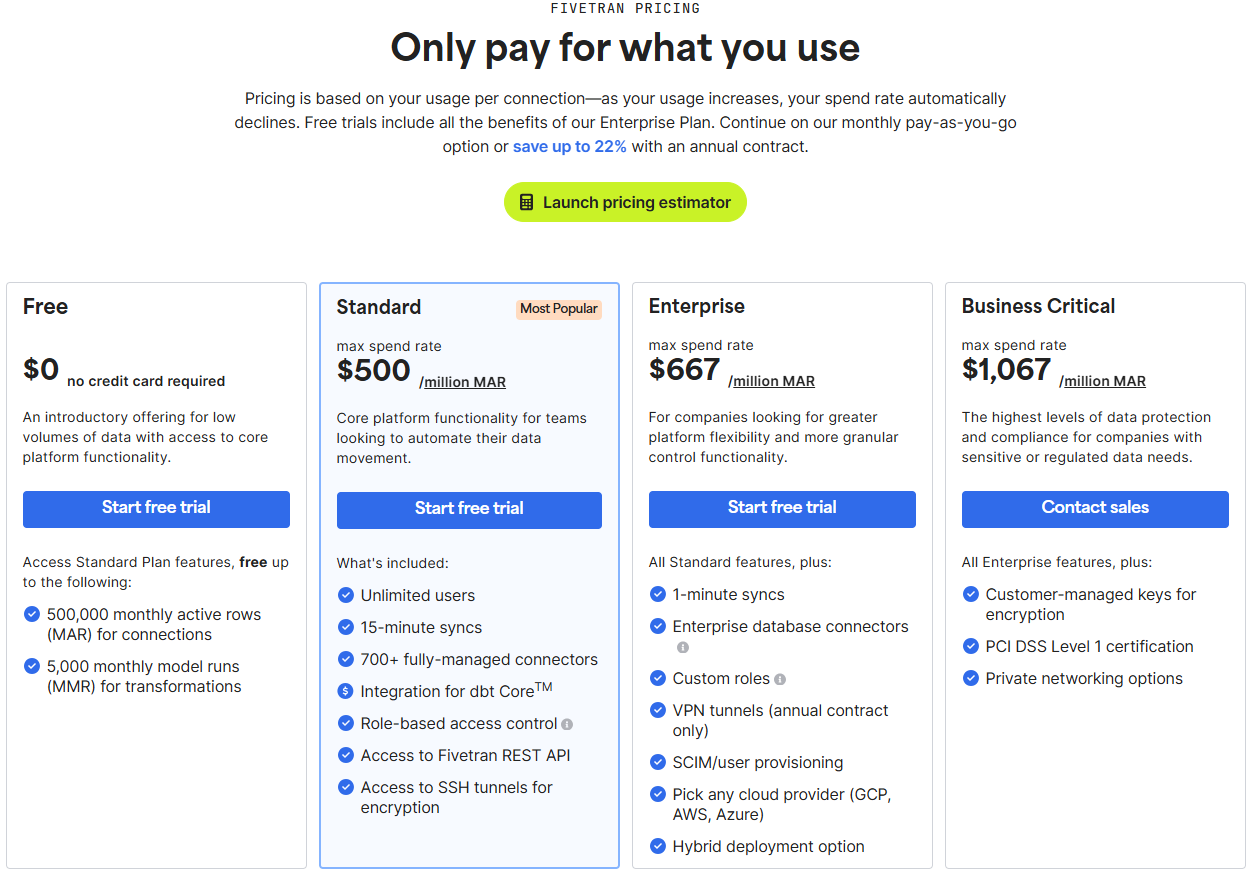
引用元: Pricing | Fivetran
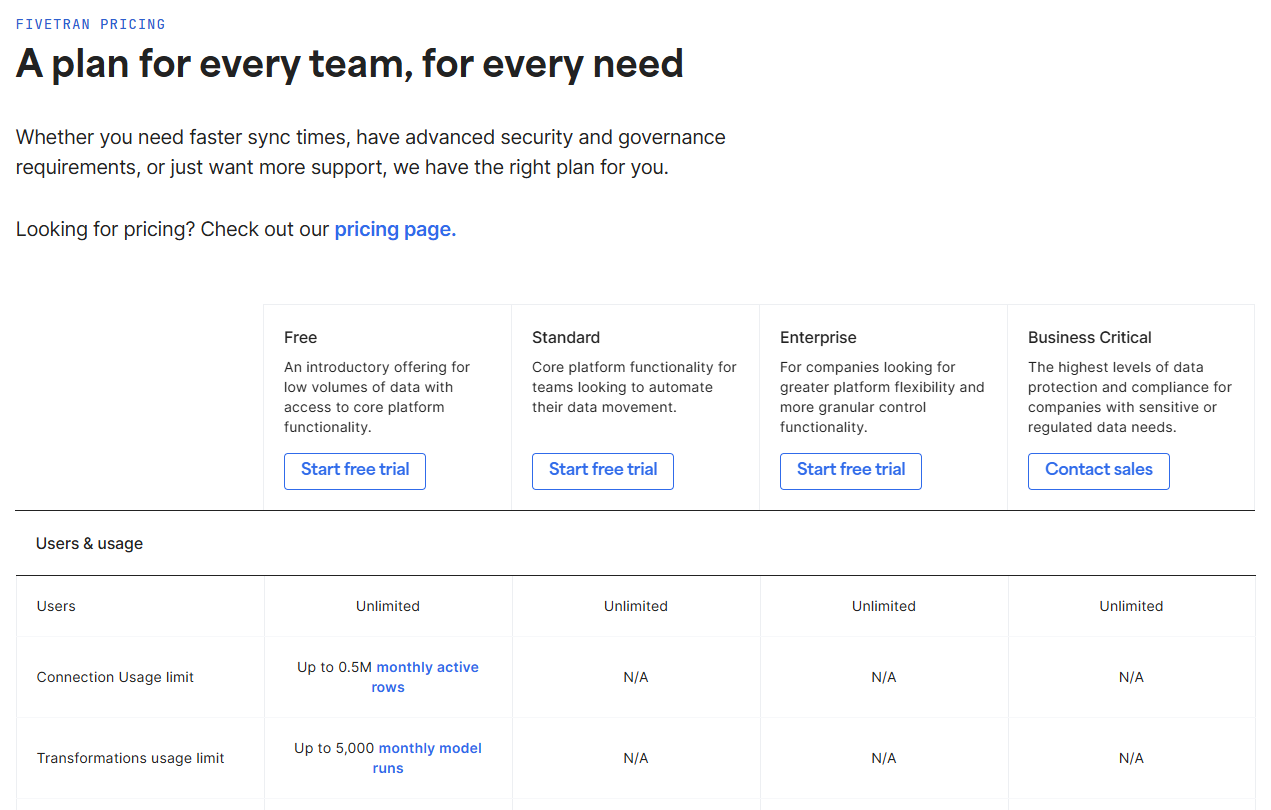
出所: Plans & features | Pricing | Fivetran
プラン検討の際には、ネットワーク要件や以下の機能が必要かどうかが重要です。
- Hybrid deployment の利用可否
- 運用リージョンの指定可否(例: AWS us-east-1 など)
- Private networking(AWS PrivateLink、Azure Private Link、Google Private Service Connect など)の利用可否
3-12. Deployment Model
Fivetran には以下 3 種類のデプロイメントモデルがあり、要件に合わせて選択します。Hybrid や Self-Hosted を利用する場合、自社内での環境構築が必要になります。
| # | デプロイメントモデル | 特徴 |
|---|---|---|
| 1 | SaaS Deployment | クラウド上で Fivetran のワークロードを実行し、フルマネージドで利用 |
| 2 | Hybrid Deployment | クラウド上での Fivetran でオーケストレーションや設定を行い、データ処理を自社ネットワークで実施 |
| 3 | Self-Hosted Deployment | 自社環境上で Fivetran 本体もホストして利用 |
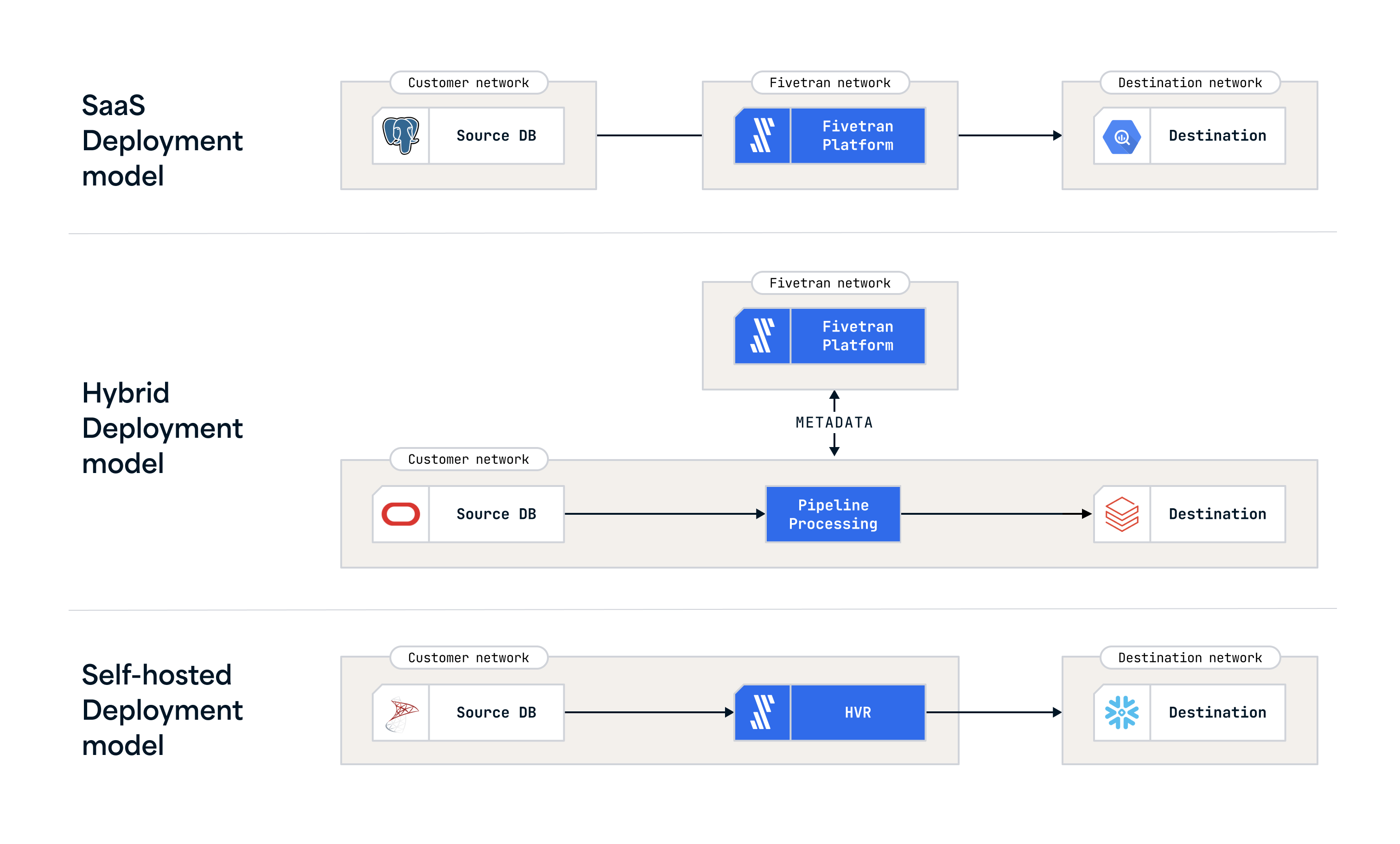
出所: Fivetran deployment models | A guide to Fivetran deployment models and their architecture
4. Fivetran によるデータ同期までのステップ
4-1. Destination の検討
Destination とするデータストアを検討します。
Destination と Fivetran の接続方法に関しては下記のドキュメントが参考になります。
クラウド DWH が選択されるケースが多いと考えられますが、複数のクエリエンジンからアクセスする要件がある場合は、Managed Data Lakes Service の利用も検討してください。
4-2. ソースにおけるコネクターとデータモデルの調査
Connector Explorer で、対象ソースシステムを検索し、対応するコネクターの必要要件や設定方法を確認します。
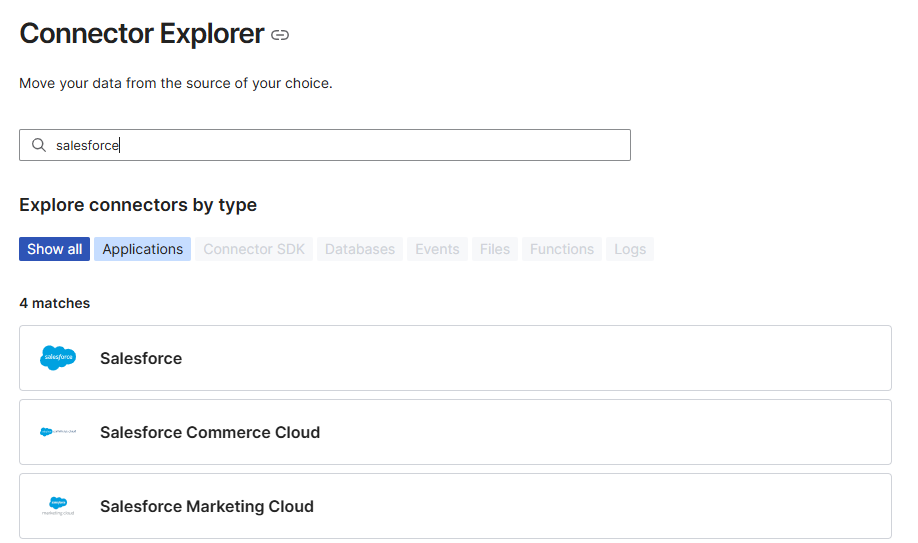
出所: Connector Explorer | Fivetran connector documentation and setup
コネクターごとのドキュメントページには、サポート機能や設定手順が詳細に記載されています。
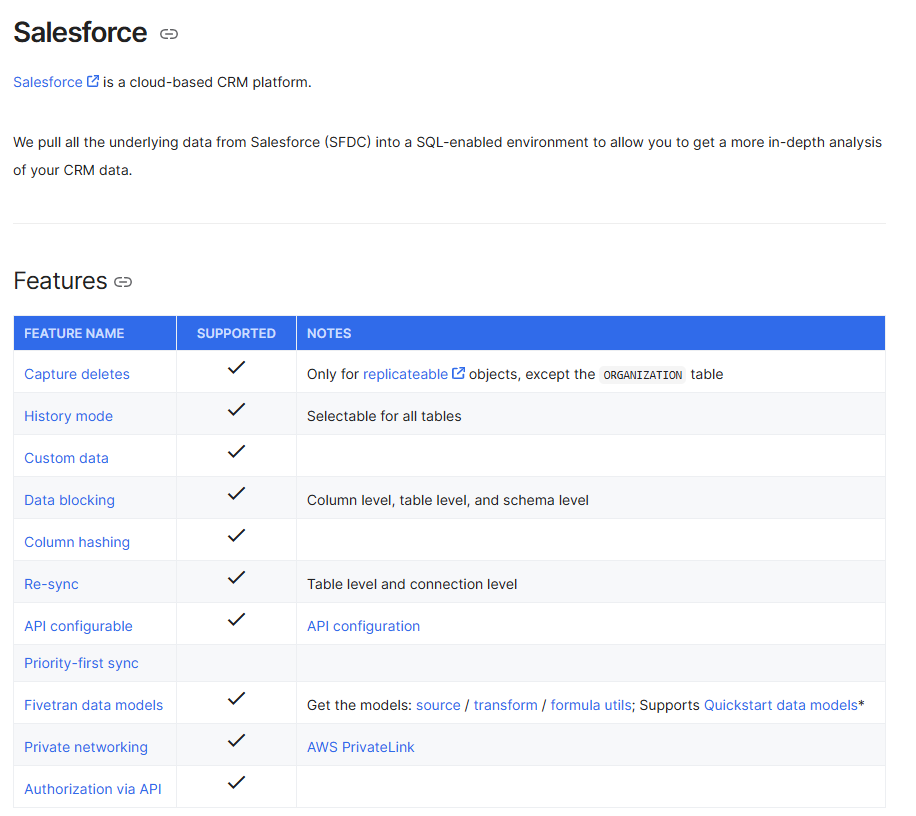
出所: Salesforce schema for destination | Fivetran data pipeline
さらに、データモデル(スキーマ)についても細かく整理されています。ソースシステムを理解する上で有益な情報ですので、参照をおすすめします。
- Google Slide で公開されているもの
- ERD のページとして公開されているもの
- オブジェクトが網羅されていないもの
- 公開されていないもの
コネクターの Features に Fivetran data models と記載があれば、Fivetran 提供の dbt モデルが利用できます。コードは Github で公開されており、分析設計の参考になります。
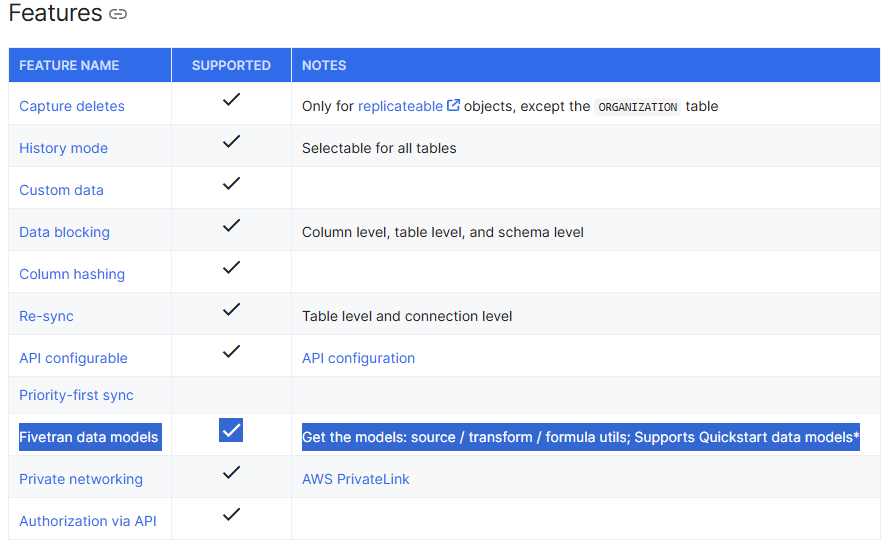
出所: Salesforce schema for destination | Fivetran data pipeline
出所: https://hub.getdbt.com/fivetran/
4-3. ソースシステムの接続方法の検討
ソースシステム、Deployment Model、ネットワーク経路、CDC 手法などを総合的に検討します。CDC 手法の選択によってはソースの設定変更が必要になる場合があります。
-
Deployment Model
- SaaS / Hybrid / Self-Hosted
-
ネットワーク経路
- PrivateLink, 自己管理の IP, Fivetran IP, Public など
-
Log ベース CDC を利用する場合
- ソース DB のログ設定が必要(例: Oracle の LogMiner、SQL Server の Change Data Capture、PostgreSQL の Logical Replication、MySQL の Binary Log)
High-Volume Agent Connectors をサポートしているコネクターの場合には、優先的に検討します。利用時の制限事項等についてはドキュメントにてご確認ください

出所:Fivetran High-Volume Agent Connectors
同期する際の命名規則を検討する必要もあります。命名規則により、 Destination における宛先のスキーマ、テーブル、および列の名称が標準化されます。
4-4. データの書き込み方法の検討
データの書き込みモードとして、Soft Delete Modeと History mode のどちらを利用するかを検討します。
| No. | モード | 使用されるカラム・フラグ |
|---|---|---|
| 1 | Soft Delete Mode |
_fivetran_deleted フラグを使う論理削除方式 |
| 2 | History mode |
_fivetran_active、_fivetran_start、_fivetran_end などの列を用いて履歴管理 |
併せて、Sync 時のデータ変換の方針を定めます。
- Row Filtering
- Data Blocking
- Column Hashing
4-5. Transformations の実施方針の検討
データの変換処理をどこまで Fivetran の Transformations 機能に委ねるか、あるいは DWH 側や別ツール(dbt Cloud、Coalesce など)で実施するかを検討します。
- 対象コネクターが Fivetran Data Models を提供している場合は、それをそのまま活用したり部分的に拡張したりできます。
- 既存の dbt プロジェクトや別ツール(Coalesce など)と連携する場合は、Fivetran-hosted dbt Core や dbt Cloud 連携を通じて統合的に管理することが可能です。
Transformations を利用する場合には、スケジュールの検討が必要となります。下記のドキュメントを確認して、スケジュールの実施方針を検討してください。
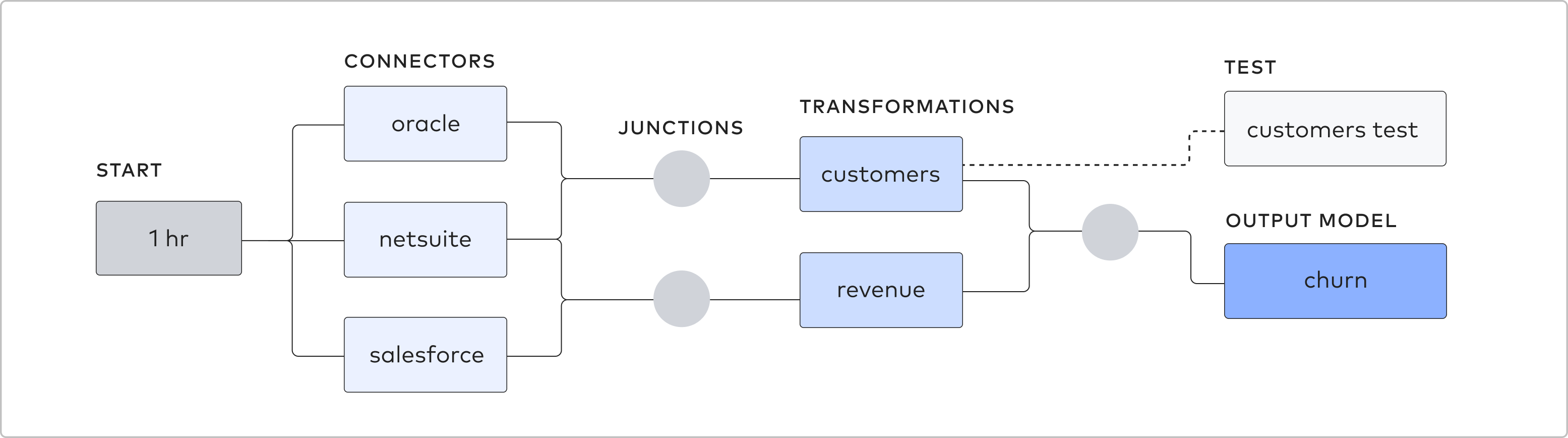
出所: Transformation Scheduling | Scheduling
4-6. データ統合と Transformation の開始
上記ステップを踏まえ、コネクターの作成・設定後に、 データ統合を開始します。併せて、Transformations ジョブを構成し、分析・可視化に適した形でデータを整えます。
5. さらなる活用に必要な知識
5-1. Fivetran により追加されるシステム列
Fivetran は Destination のテーブルにシステム列を自動で追加します(モードによって若干異なります)。

出所: Fivetran audit tables and system columns | Warehouse documentation
Soft Delete Mode では、以下の列がデフォルト追加されます。
| 列名 | データ型 | 説明 |
|---|---|---|
_fivetran_synced |
UTC タイムスタンプ | Fivetran がその行を最後に同期(抽出)した日時 |
_fivetran_deleted |
BOOLEAN (真偽値) | ソースで削除された行もしくは更新により無効化された行に TRUE がセットされる |
_fivetran_id |
TEXT / STRING 型 | Fivetran が生成する一意のサロゲートキー |
_fivetran_index |
INTEGER (整数) | 行更新の順序(インデックス) |
History Mode では、以下の列が追加されます。
| 列名 | データ型 | 説明 |
|---|---|---|
_fivetran_active |
BOOLEAN (真偽値) | 現在アクティブ(有効)なレコードかどうかを示す |
_fivetran_start |
UTC 日時 | レコードが有効になった開始時刻(ソースで新規・更新された日時を表す) |
_fivetran_end |
UTC 日時 | レコードが無効化された日時 |
5-2. Managed Data Lakes Service
Managed Data Lakes Service は、Fivetran がクラウドストレージ(AWS S3 や Azure Data Lake Storage など)に Apache Parquet 形式でデータを書き込み、テーブルのメタデータを Delta Lake と Apache Iceberg の両方で管理する機能です。Apache Iceberg のカタログとして Fivetran Iceberg REST Catalog を利用できるため外部にカタログを用意する必要がありません。
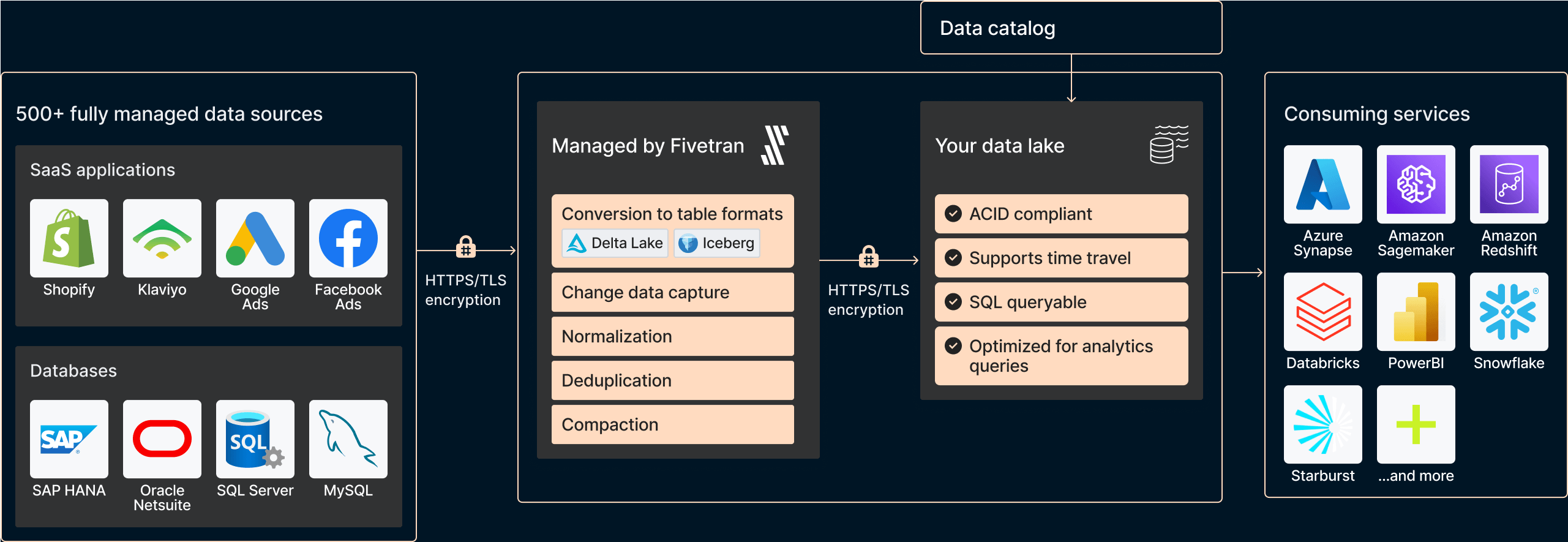
Apache Iceberg カタログの標準に準拠しているため、 Snowflake Open Catalog などの外部のカタログと統合できます。下記のドキュメントにて手順が紹介されています。
-
Fivetran Iceberg REST Catalog | Integration and documentation
ただし、制限事項があることに注意が必要です。Delta Lake では、データ統合時に有益な Change Data Feed 機能ができないなど機能制限があります。
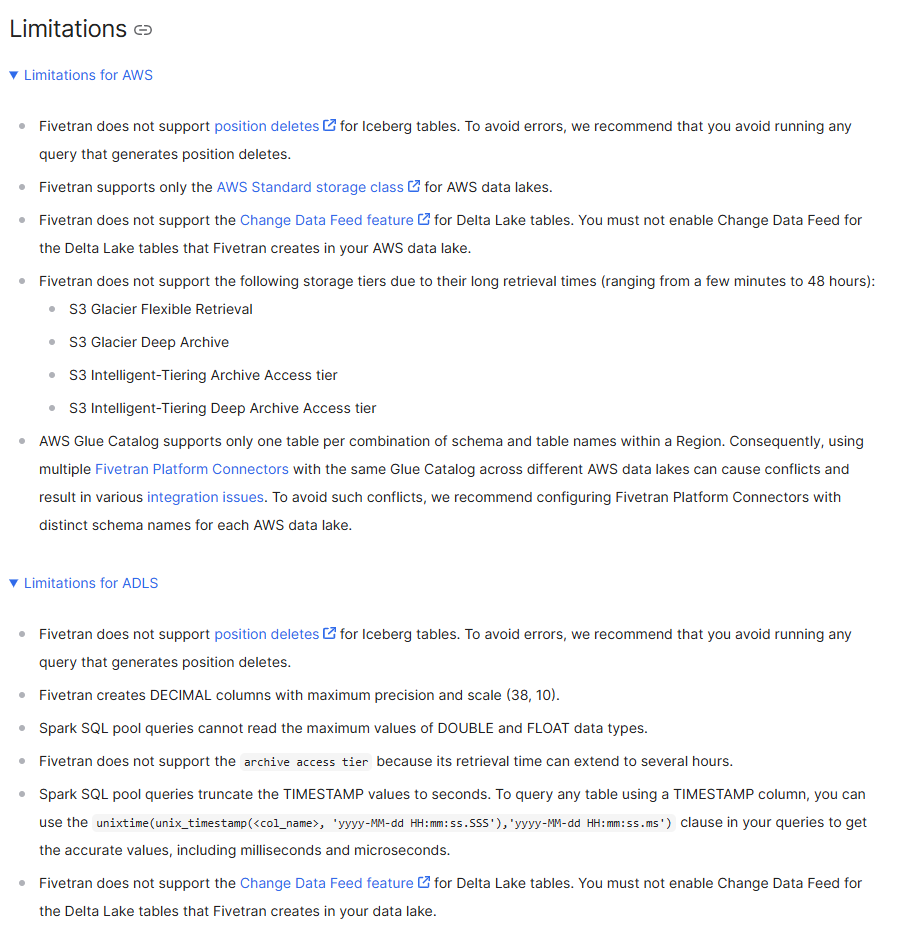
出所: Fivetran for Managed Data Lake | Configuration and documentation
サポートされるクエリエンジンは下記を参照してください。
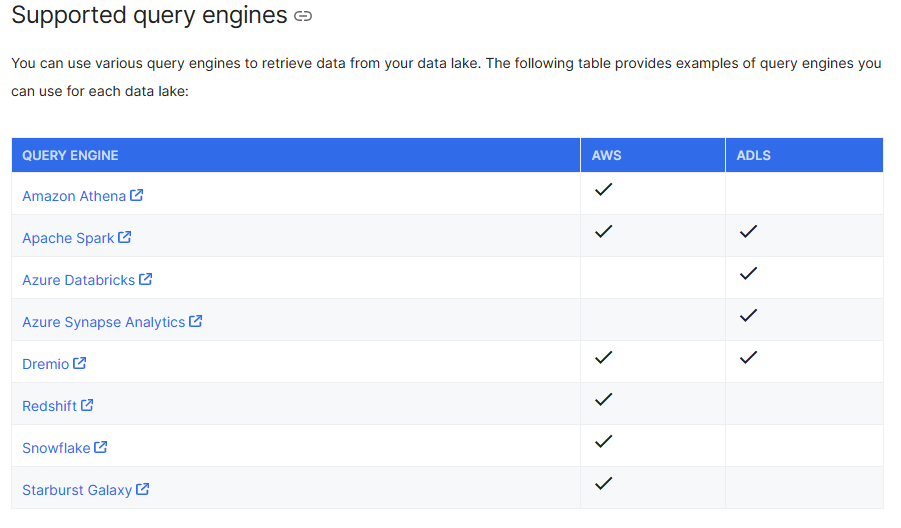
出所: Fivetran for Managed Data Lake | Configuration and documentation
Snowflake や BigQuery からテーブルにアクセスする際は、Iceberg だけでなく Delta Lake でも参照可能です。2つのサービスで Delta Lake を参照する方法について下記の記事で紹介しています。
- Snowflake Apache Iceberg™ table を Delta Lake 形式のディレクトリから作成する機能を試してみた #iceberg - Qiita
- Google Colab で操作した Delta Lake のデータから Delta Lake 用の BigLake 外部テーブルを作成する方法 #BigQuery - Qiita
Fivetran はテーブルのメンテナンス(コンパクションなど)を自動で行います。

出所: Fivetran for Managed Data Lake | Configuration and documentation
6. 技術検証結果
6-1. Fivetran にて Databricks (クラウド DWH)に書き込む際のステージングストレージに関する注意事項
Fivetran の SaaS Deployment で Databricks を Destination として使用する場合、Fivetran 管理下のストレージにデータが配置される点に注意が必要です。セキュリティポリシーに照らし合わせ、この動作を事前に許容できるかどうか確認してください。詳細については下記の記事を確認してください。
6-2. スキーマ・テーブル・カラムの名称変換
Fivetran における名称変換(Naming conventions)に関して下記の記事で整理しています。異なるソースがそれぞれ持つ命名スタイルを統一し、ターゲットシステムの規約や仕様に合わせるためにスキーマやカラムに対して名称変換を行います。ソースのカラムに日本語がある場合には、アルファベットに変換されるため注意が必要です。
6-3. Fivetran の Hybrid Deployment によりデータを連携方法に関する基本的な手順
下記記事にて、Fivetran の Hybrid Deployment を利用したデータ連携手法の検証結果を紹介しています。
6-4. Fivetran の Managed Data Lakes Service を Azure Data Lake Storage Gen2 で構築する手順
Fivetran の Managed Data Lakes Service を Azure Data Lake Storage Gen2 で構築する手順を紹介しています。
6-5. Fivetran の Managed Data Lakes Service の Apache Iceberg テーブルに Google Colab の Spark からアクセスする方法
下記の記事に手順を紹介しています。
6-6. Fivetran の Managed Data Lakes Service の Apache Iceberg テーブルを Snowflake に登録する手順
下記の記事に手順を紹介しています。
6-7. Fivetran から Microsoft Fabric にデータを同期する手順
下記の記事にて紹介しています。
7. 参考リンク
7-1. Fivetran 公式ページ
- 公式ドキュメント
- 公式ブログ
- サービスステータス
- 用語集と機能紹介
7-2. ベストプラクティス
7-3. Fivetran におけるデータ統合に関するガイド
- 10 data pipeline challenges your engineers will have to solve
- Fivetran | Ultimate guide to data integration