概要
Fivetran の Managed Data Lakes Service の Apache Iceberg テーブルに Google Colab の Spark からアクセスする方法を共有します。

本記事は下記記事の一部です。

出所:フルマネージドなデータ連携:データ統合の自動化を実現する Fivetran の全貌 #fivetran - Qiita
事前準備
下記の記事を参考に Fivetran の Managed Data Lakes Service によりデータ同期を実施します。
手順
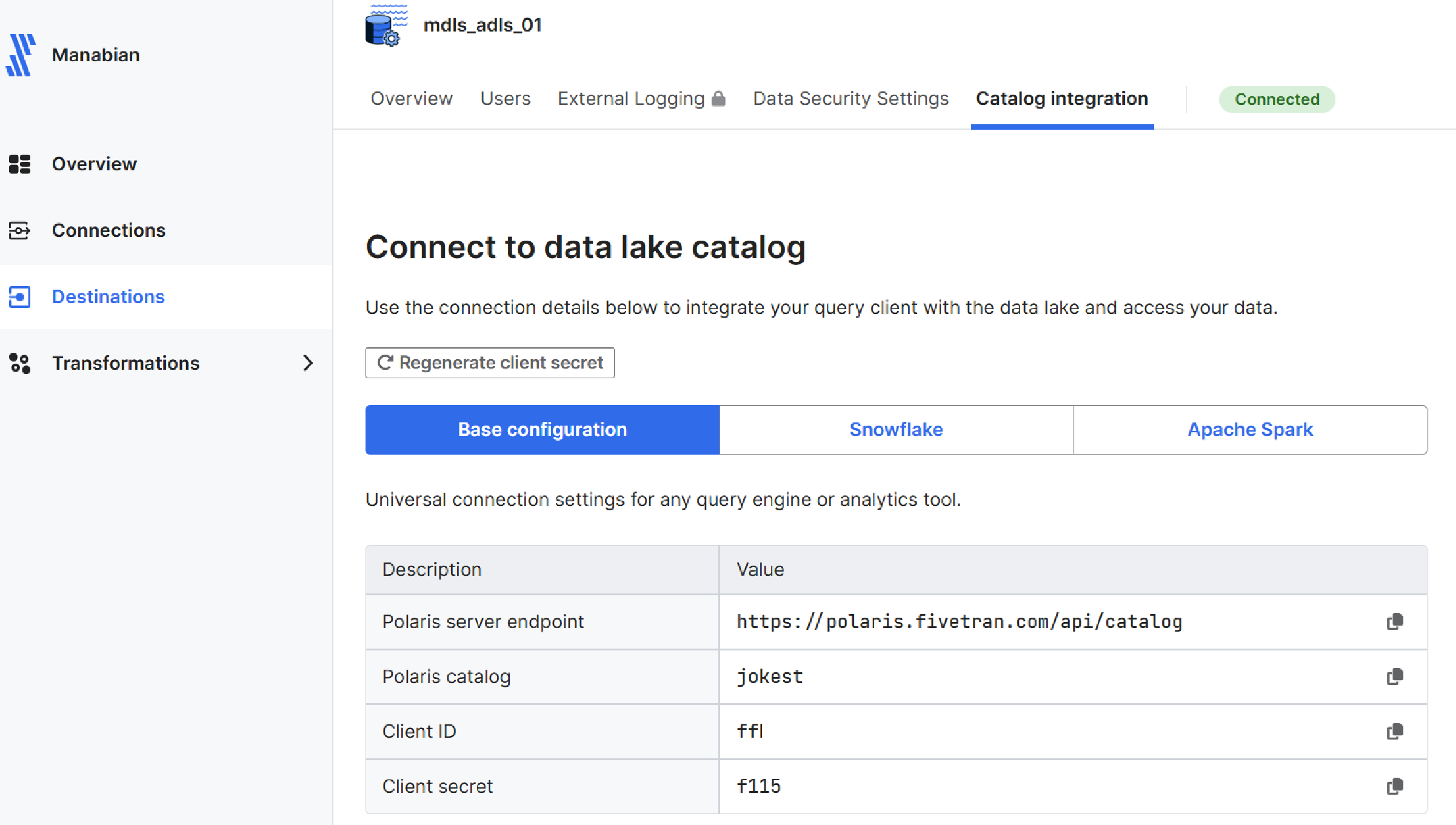
Fivetran にて Destinations -> 構築済み Destination -> Catalog integration -> Base configuraionに記載されている情報を取得
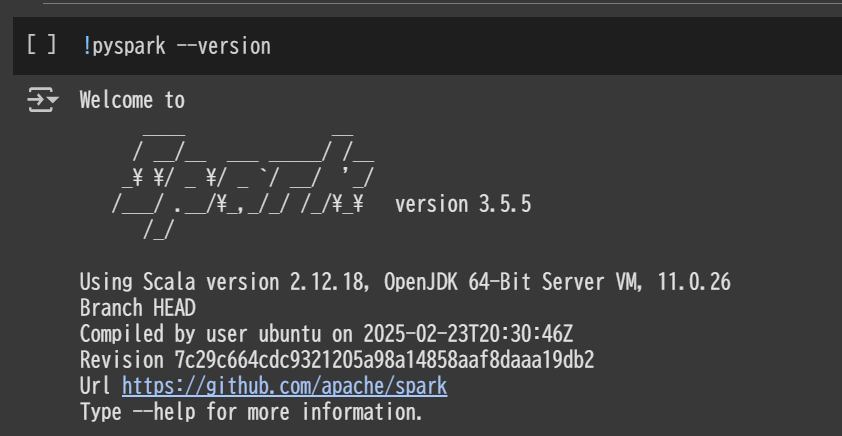
Google Colab にてノートブックを作成し、 Spark のバージョンを確認
!pyspark --version
Fivetran Iceberg REST Catalog に関する情報をセット
# 機密値は Colab の「▶︎」→「環境変数」で設定するか、os.environ 経由で渡すべき
polaris_server_endpoint = "https://polaris.fivetran.com/api/catalog"
catalog_name = "jokester_waterfall"
client_id = "ffb13f98be9c2bc3"
client_secret = "f11590941611ac94d50e936af4a30693"
region = ""

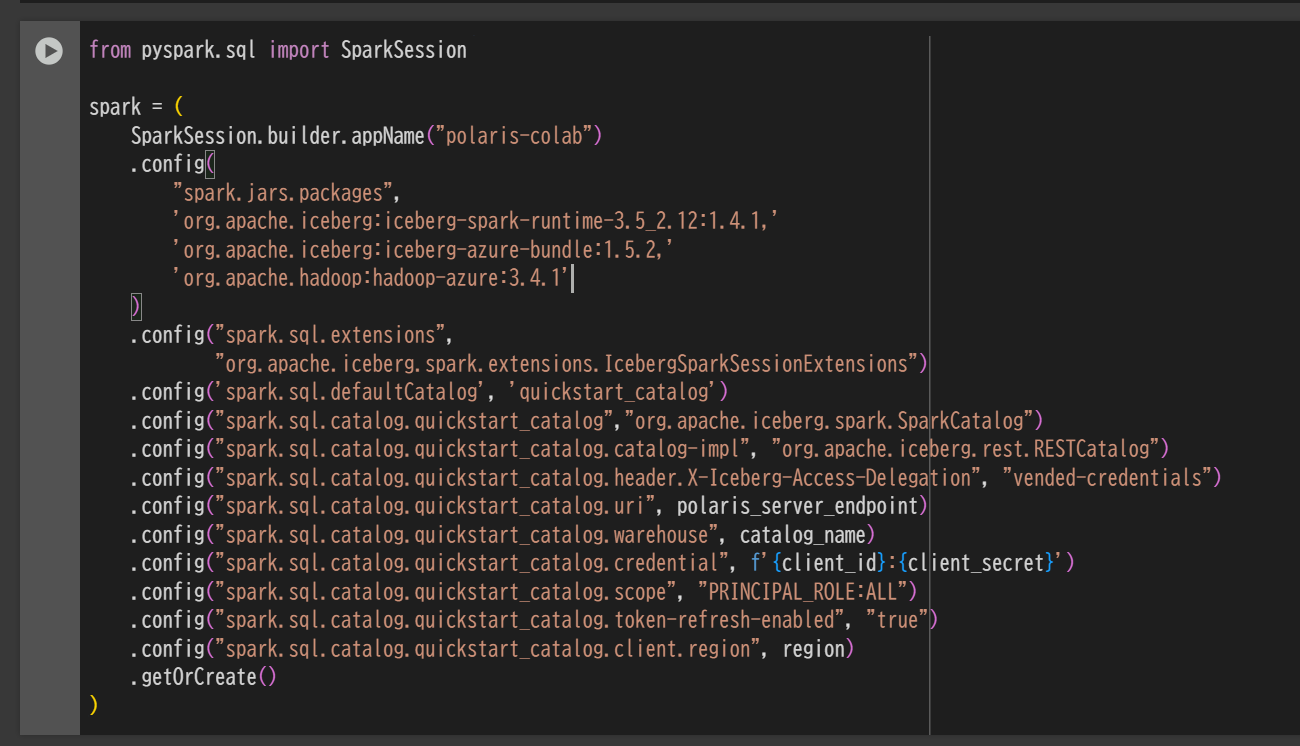
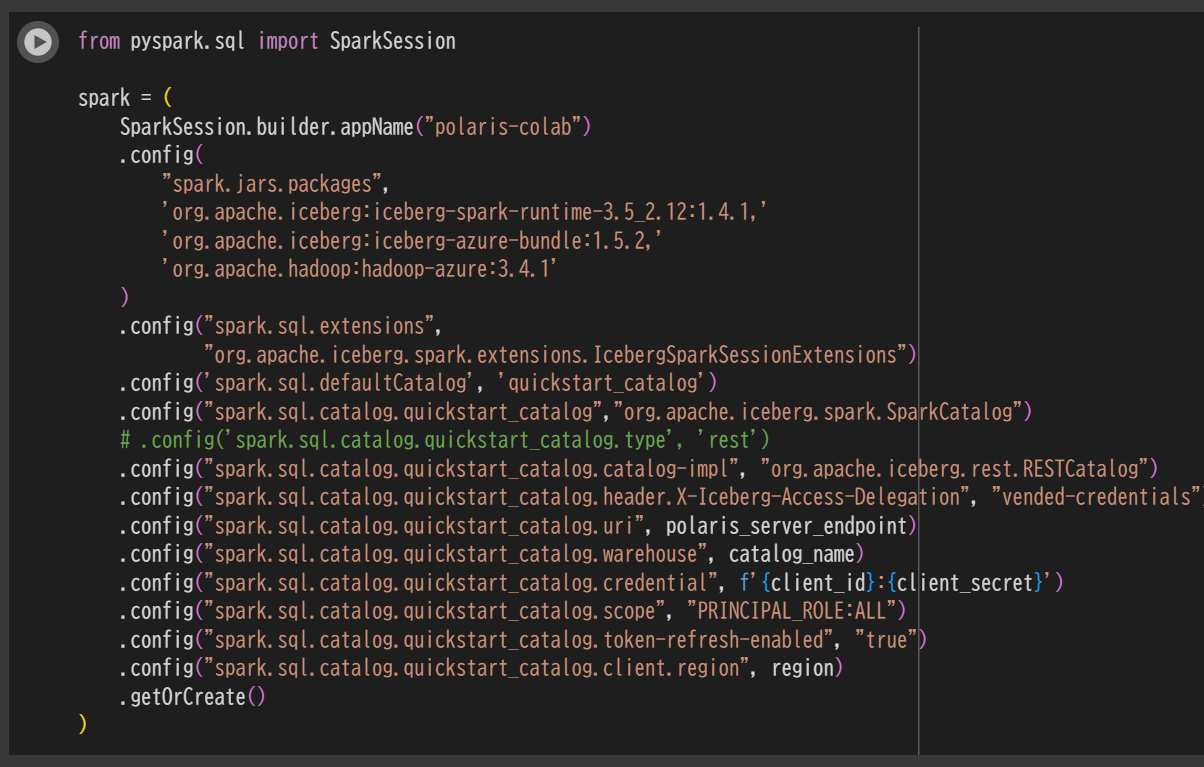
SparkSession を定義
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("polaris-colab")
.config(
"spark.jars.packages",
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,'
'org.apache.iceberg:iceberg-azure-bundle:1.5.2,'
'org.apache.hadoop:hadoop-azure:3.4.1'
)
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config('spark.sql.defaultCatalog', 'quickstart_catalog')
.config("spark.sql.catalog.quickstart_catalog","org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.quickstart_catalog.catalog-impl", "org.apache.iceberg.rest.RESTCatalog")
.config("spark.sql.catalog.quickstart_catalog.header.X-Iceberg-Access-Delegation", "vended-credentials")
.config("spark.sql.catalog.quickstart_catalog.uri", polaris_server_endpoint)
.config("spark.sql.catalog.quickstart_catalog.warehouse", catalog_name)
.config("spark.sql.catalog.quickstart_catalog.credential", f'{client_id}:{client_secret}')
.config("spark.sql.catalog.quickstart_catalog.scope", "PRINCIPAL_ROLE:ALL")
.config("spark.sql.catalog.quickstart_catalog.token-refresh-enabled", "true")
.config("spark.sql.catalog.quickstart_catalog.client.region", region)
.getOrCreate()
)
スキーマの一覧を表示
# スキーマの一覧を表示
spark.sql("SHOW SCHEMAS").show(truncate=False)

###テーブルの一覧を表示
# スキーマを指定
schema_name = "fivetran_metadata_jokester_waterfall"
spark.sql(f"USE {schame_name}")
# テーブルの一覧を表示
spark.sql("SHOW TABLES").show(truncate=False)

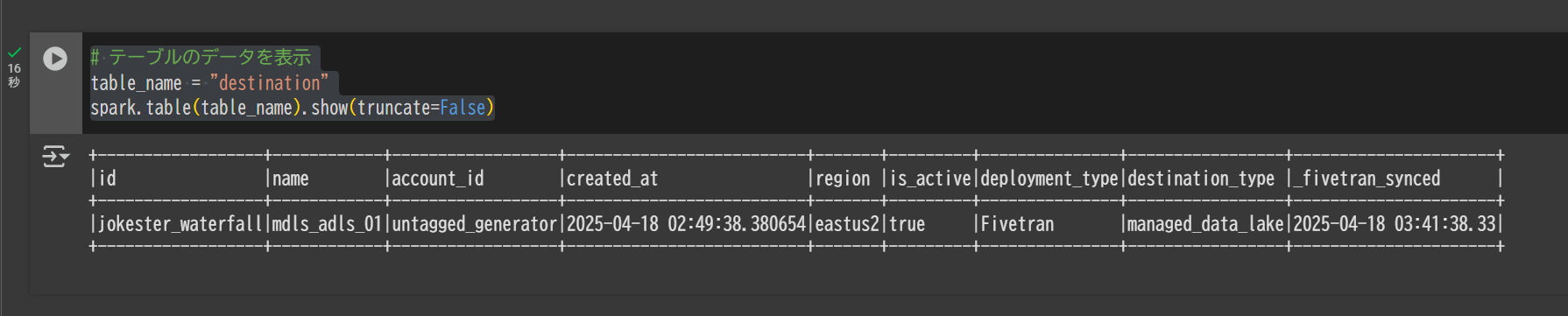
テーブルのデータを表示
# テーブルのデータを表示
table_name = "destination"
spark.table(table_name).show(truncate=False)