概要
Snowflakeで、Apache Iceberg™テーブルをDelta Lake形式のディレクトリから作成できる機能を検証したため、その結果と検証コードを共有します。ここで注意すべき点は、Apache Iceberg形式のディレクトリ構成に変更されるわけではなく、Snowflakeが内部でスキームの解釈をおこなっているようです。本記事では、 Google Colab の Spark から Delta Lake 形式のデータを用意しています。
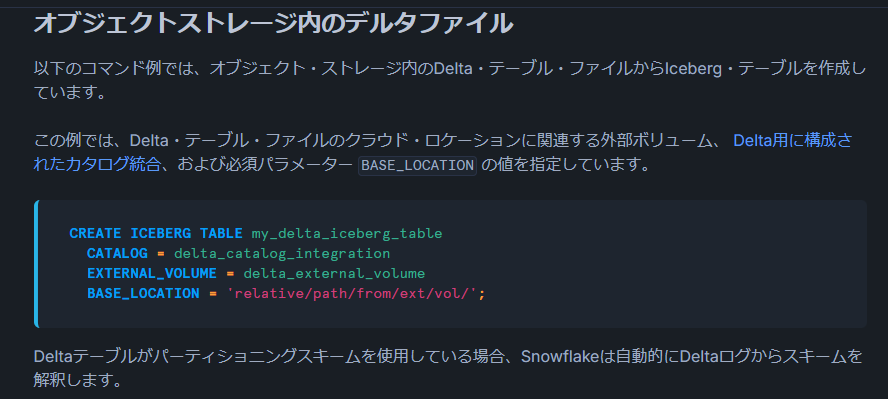
出所:Snowflakeで Apache Iceberg™ テーブルを作成する | Snowflake Documentation
Delta LakeはAuto Refreshに対応しています。2025年3月9日時点では、日本語ドキュメントにこの点の記載はありませんが、英語ドキュメントにはDelta Lakeがサポート対象であると明記されています。

出所:Apache Iceberg™ テーブルの自動リフレッシュ | Snowflake Documentation
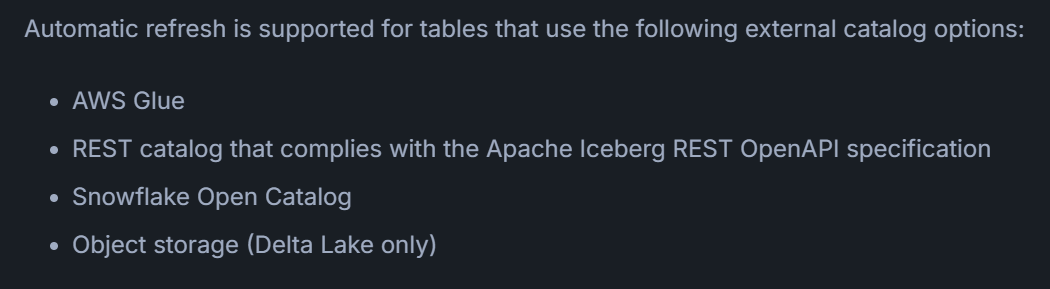
出所:Automatically refresh Apache Iceberg™ tables | Snowflake Documentation
本記事は「SnowflakeにおけるApache Iceberg機能の完全ガイド」シリーズの一部です。
Apache Iceberg機能の全体像やSnowflake上での活用方法について詳しく知りたい方は、以下の記事をご覧ください。
環境準備
Snowflake Catalog環境の準備
以下の記事で紹介している環境構築手順をあらかじめ実施してください。
出所:Snowflake Catalog における Iceberg テーブルの基本的な操作手順 #Spark - Qiita
Delta LakeからIcebergテーブルを作成
Google Colab(Spark)でDelta Lake形式のデータを準備
まず、Azureストレージのアカウント名とキーを変数にセットします。
# Azure Storage に関する情報をセット
azure_storage_account_name = "snowflakeicebergqiita"
azure_storage_account_key = "kKRn6nruDHEhUF0AQzM1PFlXtXs9V0BJQSrn6Z8GvJOsb0JHflV9Fn=="

SparkSessionを定義します。Delta Lakeを利用できるようにパッケージを追加しています。
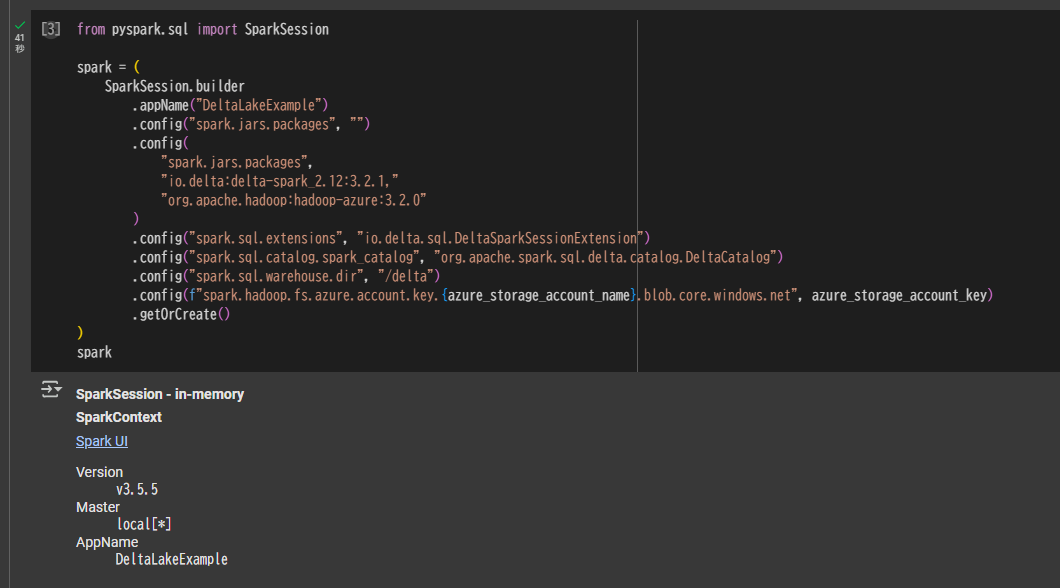
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("DeltaLakeExample")
.config("spark.jars.packages", "")
.config(
"spark.jars.packages",
"io.delta:delta-spark_2.12:3.2.1,"
"org.apache.hadoop:hadoop-azure:3.2.0"
)
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.config("spark.sql.warehouse.dir", "/delta")
.config(f"spark.hadoop.fs.azure.account.key.{azure_storage_account_name}.blob.core.windows.net", azure_storage_account_key)
.getOrCreate()
)
spark
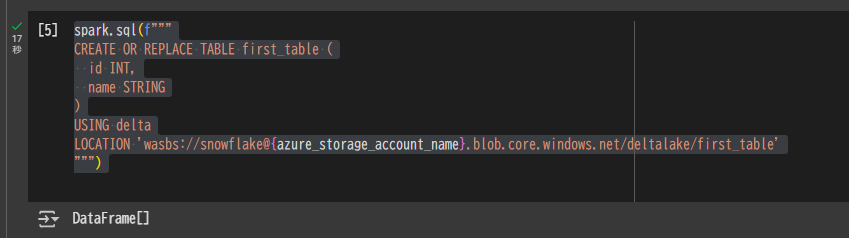
次に、Delta Lakeの外部テーブルをAzure Storage上に作成します。
spark.sql(f"""
CREATE OR REPLACE TABLE first_table (
id INT,
name STRING
)
USING delta
LOCATION 'wasbs://snowflake@{azure_storage_account_name}.blob.core.windows.net/deltalake/first_table'
""")
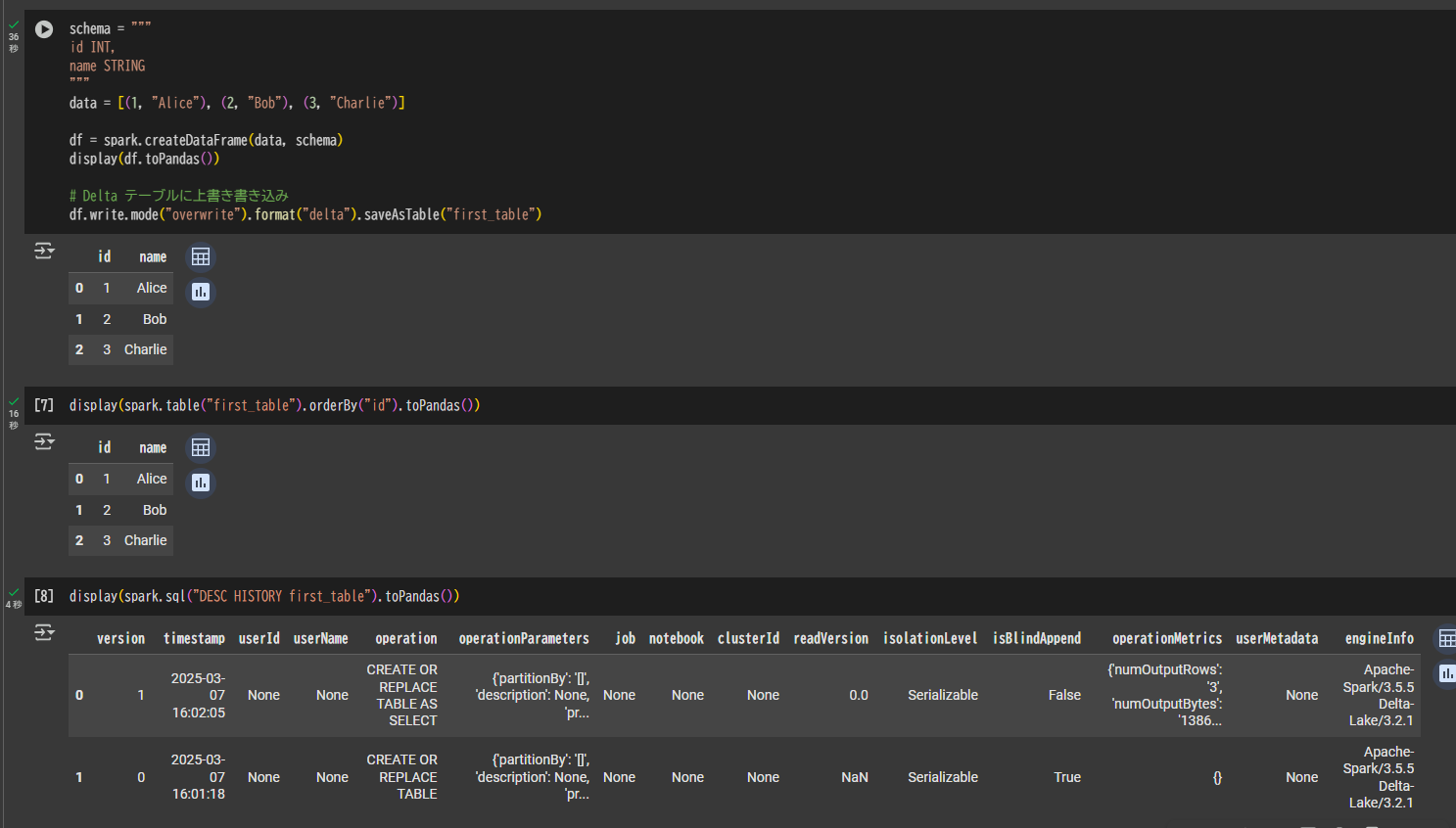
続いてテーブルにデータを上書き書き込みします。
schema = """
id INT,
name STRING
"""
data = [(1, "Alice"), (2, "Bob"), (3, "Charlie")]
df = spark.createDataFrame(data, schema)
display(df.toPandas())
# Delta テーブルに上書き書き込み
df.write.mode("overwrite").format("delta").saveAsTable("first_table")
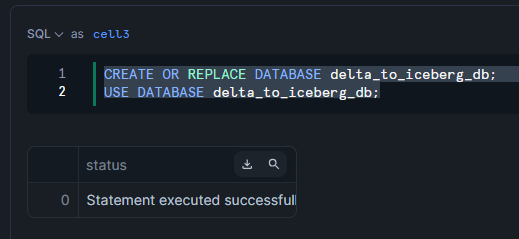
Snowflakeでオブジェクトを作成
データベースを作成します。
CREATE OR REPLACE DATABASE delta_to_iceberg_db;
USE DATABASE delta_to_iceberg_db;
オブジェクトストレージ(Delta Lake形式)のカタログ統合を作成します。
CREATE OR REPLACE CATALOG INTEGRATION delta_catalog_integration
CATALOG_SOURCE = OBJECT_STORE
TABLE_FORMAT = DELTA
ENABLED = TRUE;
DESCRIBE CATALOG INTEGRATION delta_catalog_integration;
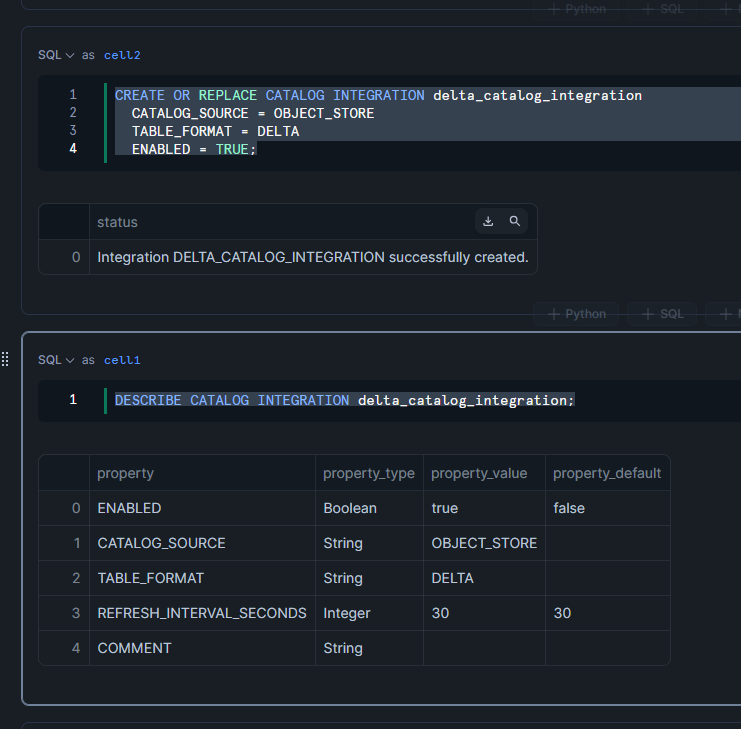
続いて、外部Volumeを作成し、その認証設定を行います。
-- 各値を変数としてセット
SET azure_tenant_id = '095ca098-c723-478f-xxxx-xxxxx';
SET azure_storage_account_name = 'snowflakeicebergqiita';
SET storage_provider = 'AZURE';
-- 連結した URL は変数に事前に設定
SET full_storage_uri = 'azure://' || $azure_storage_account_name || '.blob.core.windows.net/snowflake/deltalake/';
SELECT
$storage_provider AS STORAGE_PROVIDER
,$full_storage_uri AS STORAGE_BASE_URL
,$azure_tenant_id AS AZURE_TENANT_ID;
-- 外部 Volume を作成
CREATE OR REPLACE EXTERNAL VOLUME delta_to_iceberg_volume
STORAGE_LOCATIONS = (
(
NAME = 'delta-to-iceberg-volume'
STORAGE_PROVIDER = 'AZURE'
STORAGE_BASE_URL = 'azure://snowflakeicebergqiita.blob.core.windows.net/snowflake/deltalake/'
AZURE_TENANT_ID = '095ca098-c723-478f-xxxx-xxxxx'
)
)
ALLOW_WRITES = true;
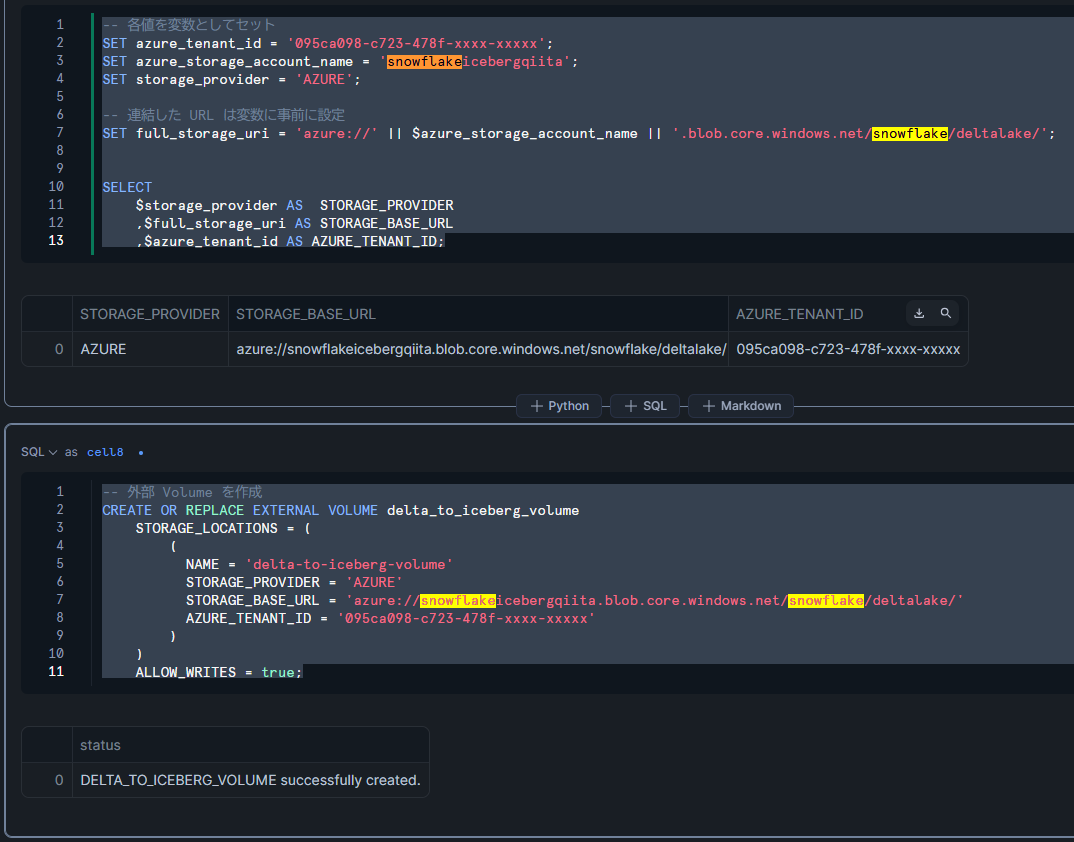
DESC EXTERNAL VOLUME delta_to_iceberg_volume;
DESC EXTERNAL VOLUME delta_to_iceberg_volume;
SELECT
PARSE_JSON($4):AZURE_MULTI_TENANT_APP_NAME::string AS AZURE_MULTI_TENANT_APP_NAME,
PARSE_JSON($4):AZURE_CONSENT_URL::string AS AZURE_CONSENT_URL
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE $2 = 'STORAGE_LOCATION_1';
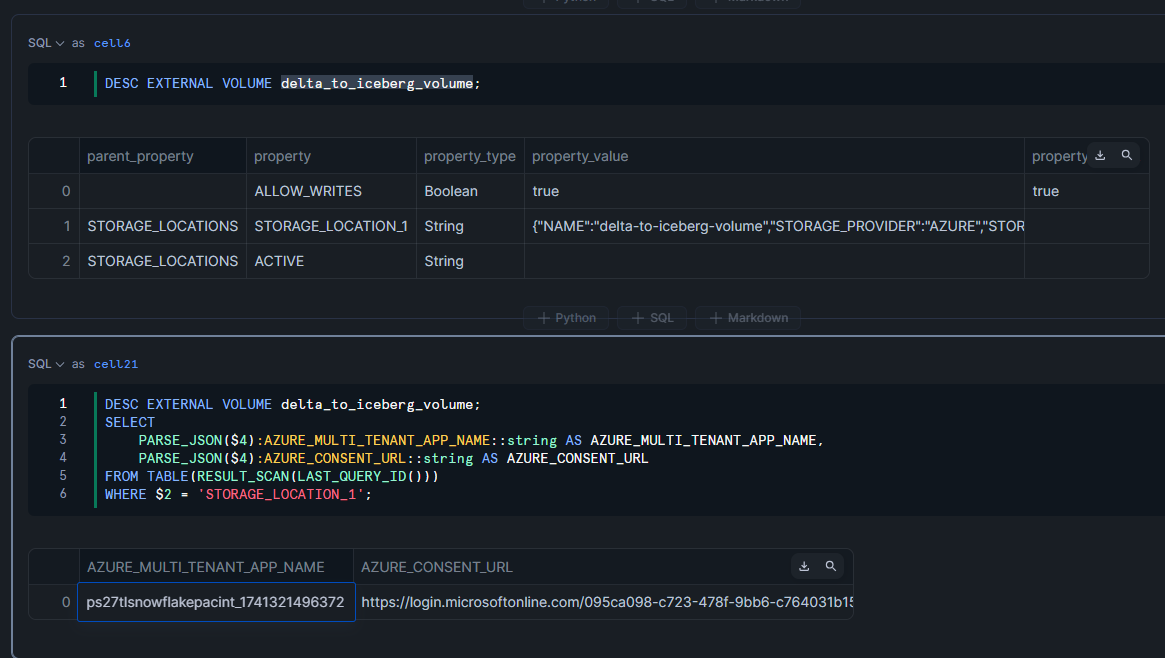
外部Volumeへのアクセス権付与
AZURE_CONSENT_URLのURLをAzureにログイン中のブラウザで開き、Snowflakeからのアクセス許可を与えます。
DESC EXTERNAL VOLUME my_azure_sf_volume;
SELECT
PARSE_JSON($4):AZURE_MULTI_TENANT_APP_NAME::string AS AZURE_MULTI_TENANT_APP_NAME,
PARSE_JSON($4):AZURE_CONSENT_URL::string AS AZURE_CONSENT_URL
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE $2 = 'STORAGE_LOCATION_1';
承諾を選択します。
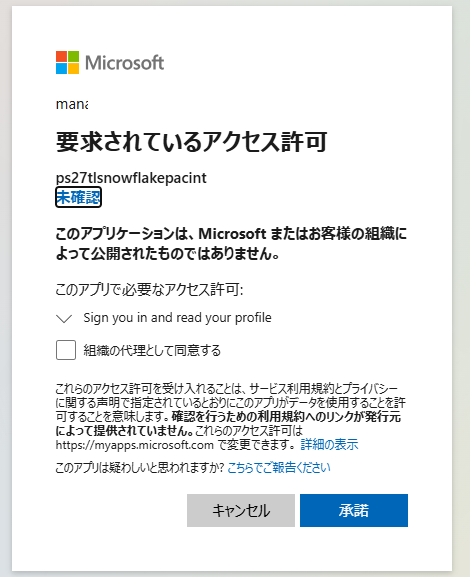
Azure Storage上でAZURE_MULTI_TENANT_APP_NAMEのアンダーバーより前の文字列(例:ps27tlsnowflakepacint)を検索し、適切なロールを付与します。
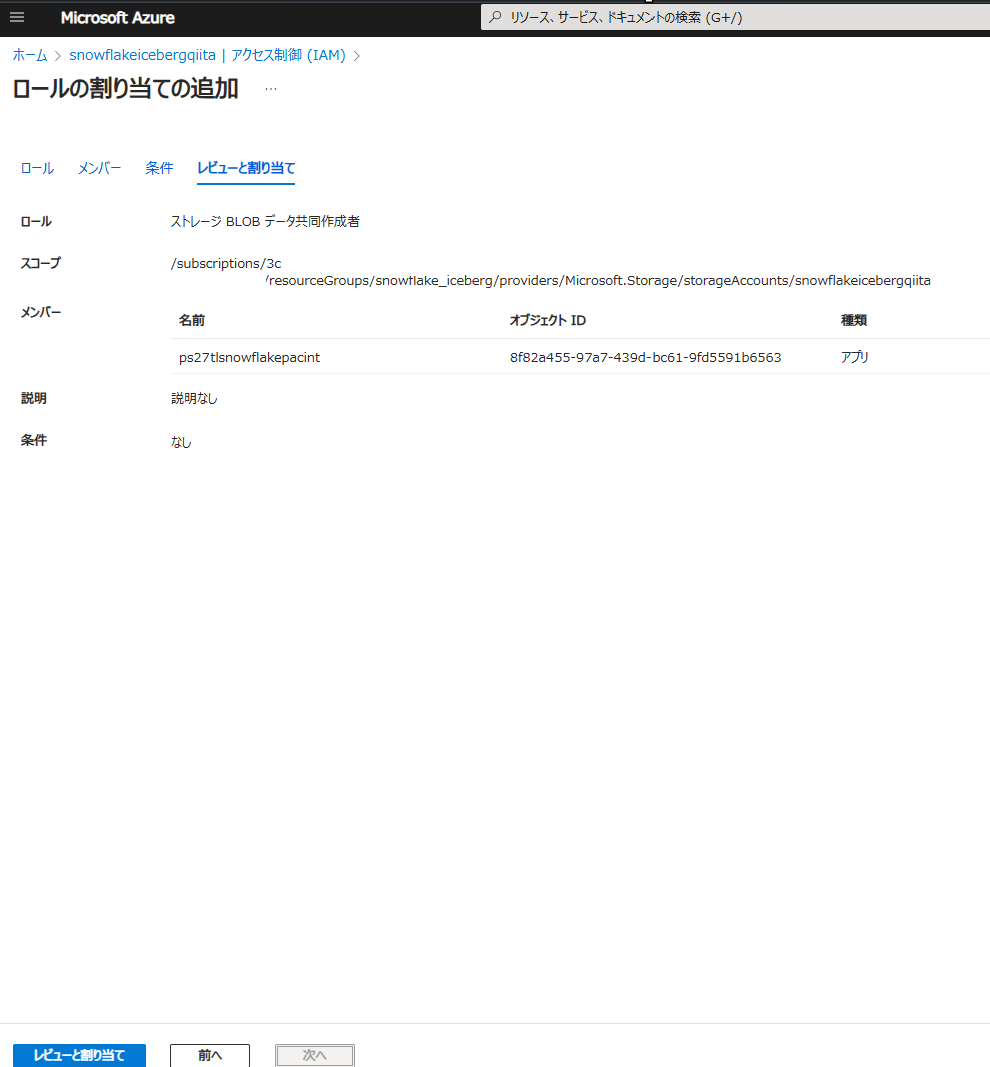
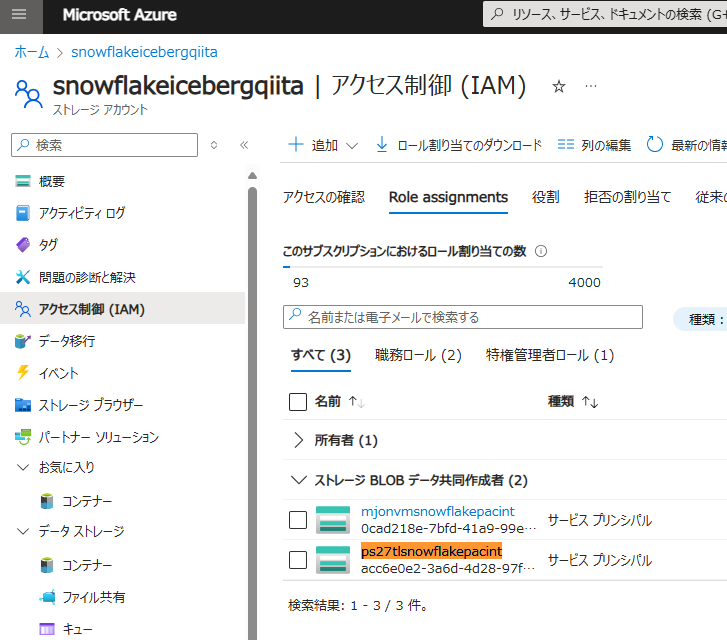
なお、本記事ではAzure向けの手順を示していますが、Snowflakeのドキュメントにはクラウドベンダーごとに手順が用意されています。
- Amazon S3用の外部ボリュームを構成する | Snowflake Documentation
- Google Cloud Storageの外部ボリュームを構成する | Snowflake Documentation
- Azureの外部ボリュームを構成する | Snowflake Documentation
テーブルの作成
Delta Lake形式のオブジェクトストレージからIcebergテーブルを作成します。
CREATE OR REPLACE ICEBERG TABLE first_table
CATALOG = delta_catalog_integration
EXTERNAL_VOLUME = delta_to_iceberg_volume
BASE_LOCATION = 'first_table/'
AUTO_REFRESH = FALSE;
SHOW TABLES;
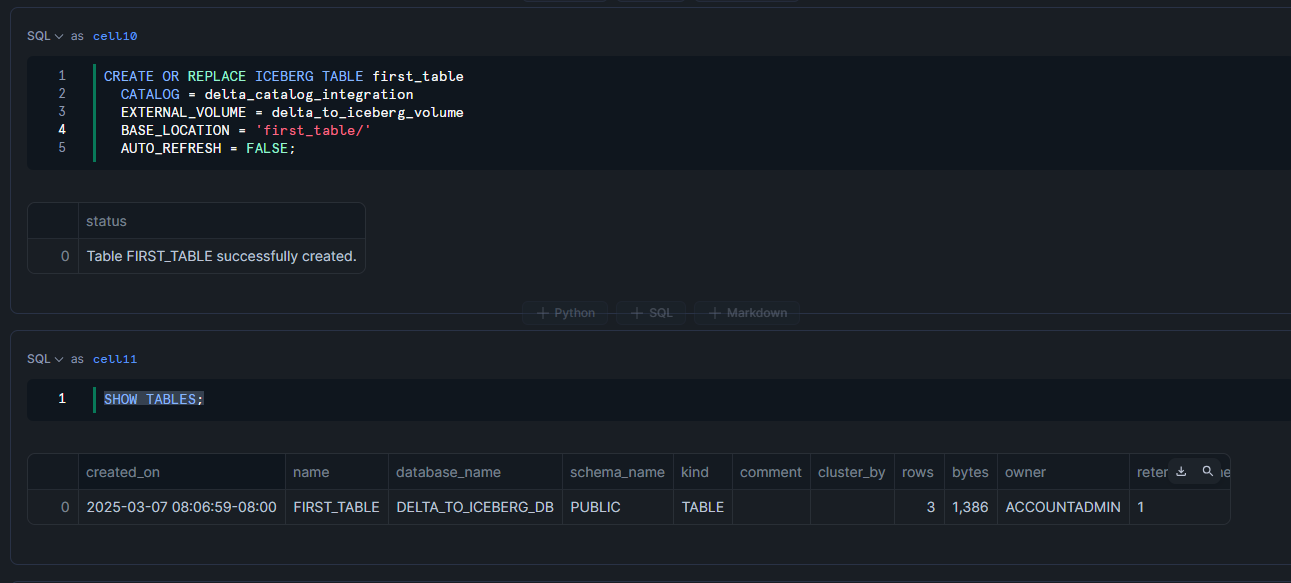
クエリを発行してみます。
SELECT
*
FROM
first_table
ORDER BY
ID;
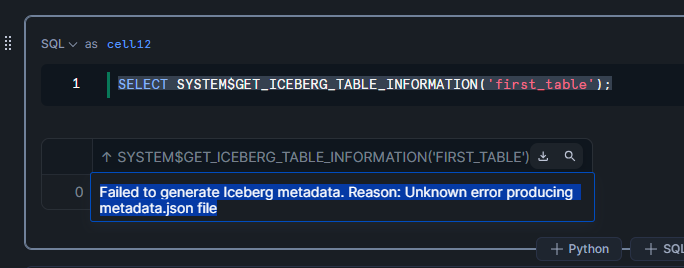
一方、Icebergテーブルの最新metadata fileを参照するシステム関数を呼び出すとエラーが発生します。
SELECT SYSTEM$GET_ICEBERG_TABLE_INFORMATION('first_table');
Failed to generate Iceberg metadata. Reason: Unknown error producing metadata.json file
手動リフレッシュの実施
Google Colab(Spark)でデータを追加
Google Colab(Spark)を使い、id列が4のデータをDelta Lakeテーブルに追加します。
schema = """
id INT,
name STRING
"""
data = [(4, "David")]
df = spark.createDataFrame(data, schema)
display(df.toPandas())
df.write.mode("append").format("delta").saveAsTable("first_table")
display(spark.table("first_table").orderBy("id").toPandas())
display(spark.sql("DESC HISTORY first_table").toPandas())
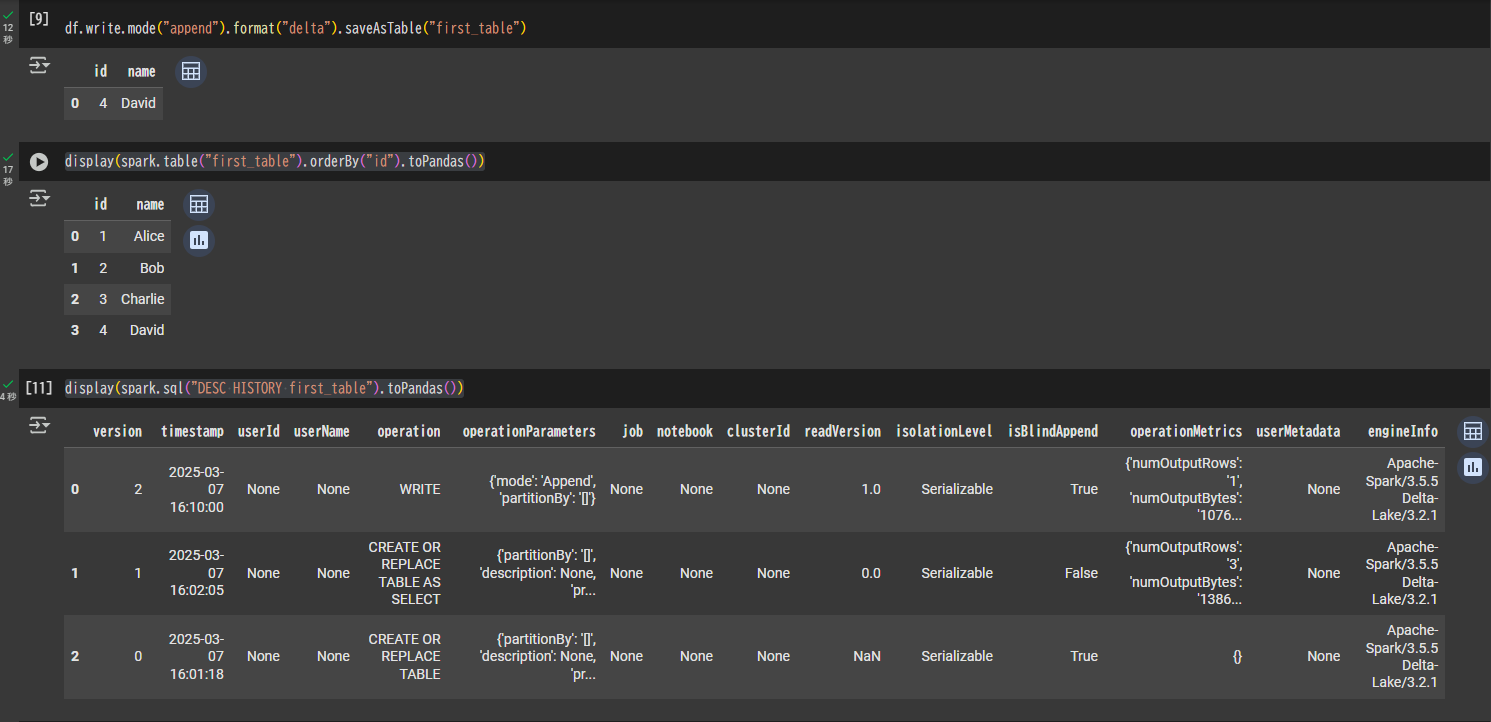
Snowflakeで手動リフレッシュの実施
Snowflakeでクエリを実行すると、まだid列が4のデータは取得できません。
SELECT
*
FROM
first_table
ORDER BY
ID;
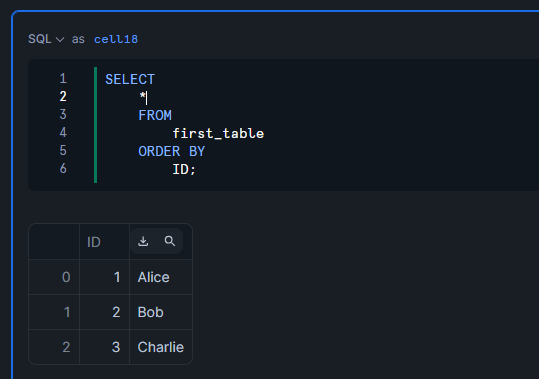
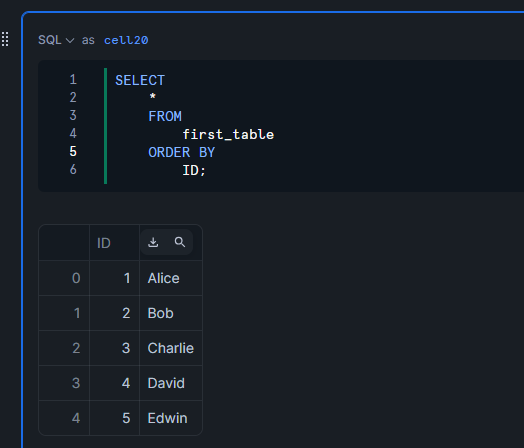
手動リフレッシュを実行すると、テーブルが最新化され、id列が4のデータも取得できます。
ALTER ICEBERG TABLE first_table REFRESH;
SELECT
*
FROM
first_table
ORDER BY
ID;
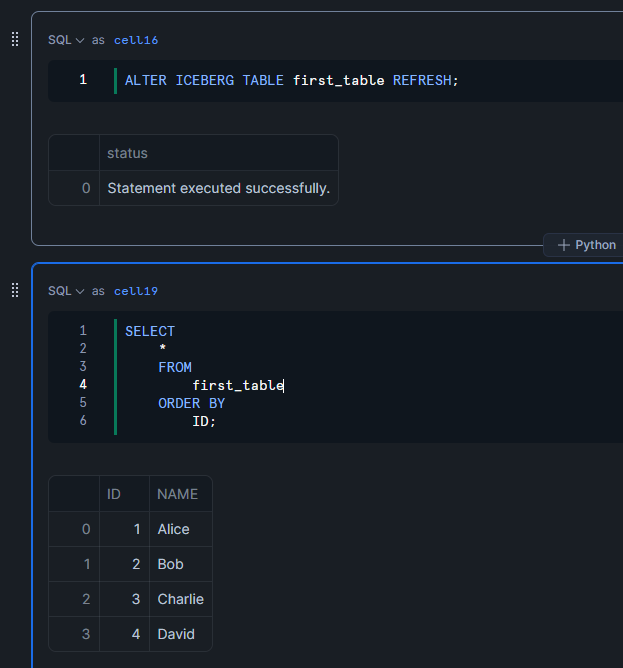
自動リフレッシュの設定
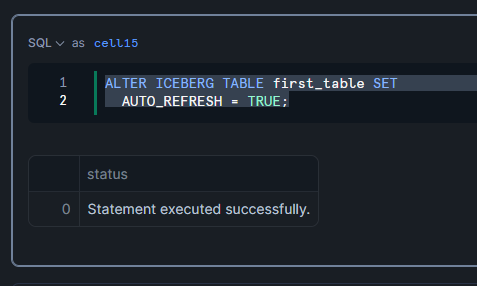
SnowflakeでテーブルのAUTO_REFRESHをTRUEに設定
ALTER ICEBERG TABLE first_table SET
AUTO_REFRESH = TRUE;
Google Colab(Spark)でデータを追加
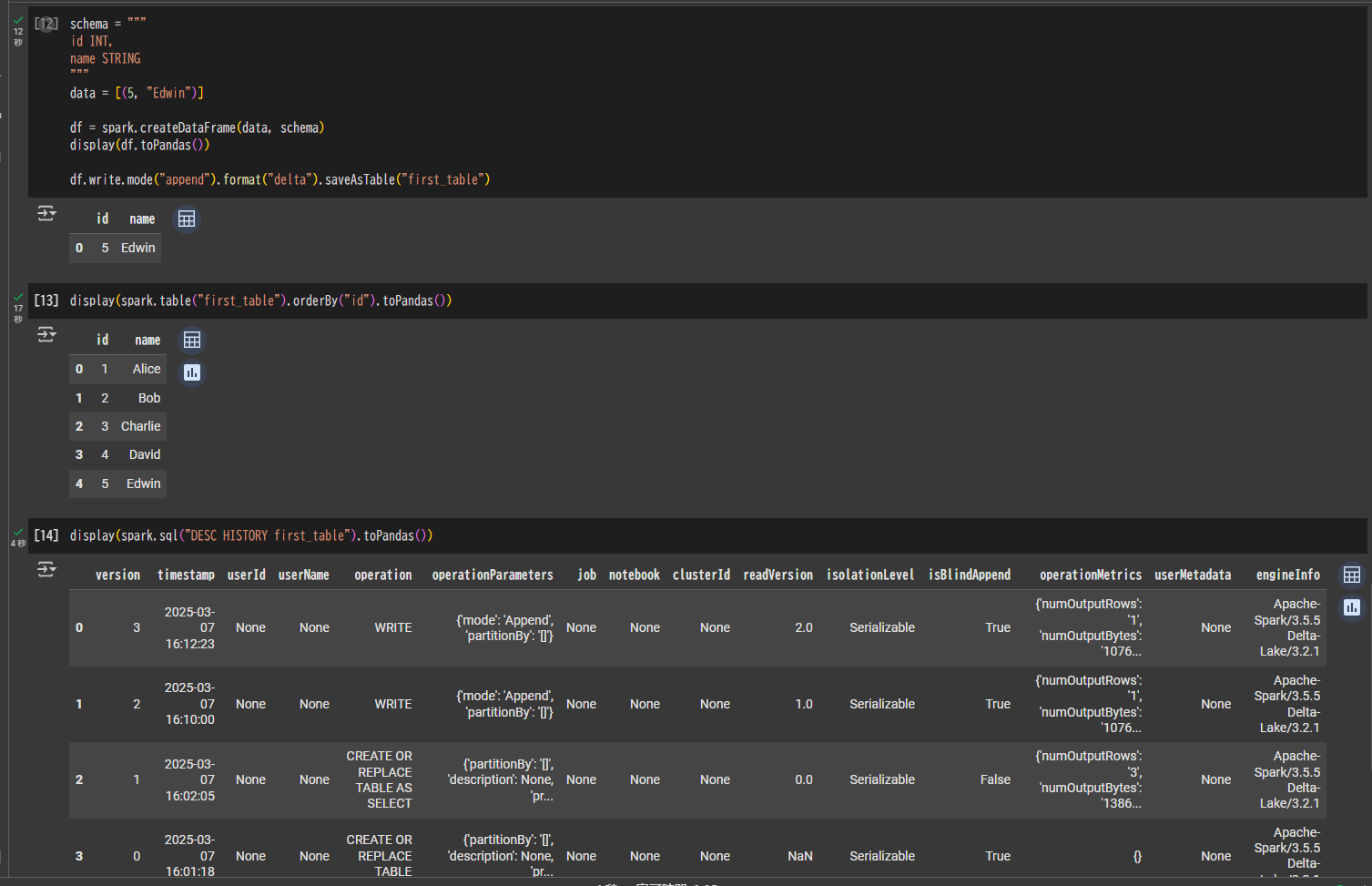
Google Colab(Spark)にて、id列が5のデータをDelta Lakeテーブルに追加します。
schema = """
id INT,
name STRING
"""
data = [(5, "Edwin")]
df = spark.createDataFrame(data, schema)
display(df.toPandas())
df.write.mode("append").format("delta").saveAsTable("first_table")
display(spark.table("first_table").orderBy("id").toPandas())
display(spark.sql("DESC HISTORY first_table").toPandas())
テーブルが自動で最新化されることを確認
手動リフレッシュをしなくてもid列が5のデータを取得でき、テーブルが自動で最新化されていることが確認できます。
SELECT
*
FROM
first_table
ORDER BY
ID;