仕事で Cloud Dataflow を使って便利さに驚いたので共有します。
この記事を読めば、 Cloud Dataflow がいかに便利か、ざっとどんな感じで動くかがわかるはずです。
Cloud Dataflow とは
簡単に言えば、フルマネージドなデータを変換してくれる君です。
例えば「Cloud Pub/Subからデータを受け取って、必要な変換を施した上で、1分ごとのデータをgzipでまとめてAWSに上げる」ということが少ないコード量でフルマネージドに出来ちゃうよ!ということです。
入力は、ファイルのように終わりのあるデータでも、Cloud Pub/Subのような終わりの無いデータでもほぼ同じように扱えます。
詳しいことは https://qiita.com/tutuming/items/948ddfadf7202a45b72c の記事が参考になります。
サンプルコード
何はともあれコードを見てみます。
「Cloud Pub/Subからデータを受け取って、1分ごとのデータをgzipでまとめてAWSに上げる」を実現するコードです。
package com.malt03;
import org.apache.beam.sdk.io.Compression;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import java.io.IOException;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.transforms.windowing.FixedWindows;
import org.apache.beam.sdk.transforms.windowing.Window;
import org.joda.time.Duration;
public class SamplePipeline {
public static void main(String[] args) throws IOException {
PubsubIO.Read<String> read = PubsubIO.readStrings().fromSubscription("projects/project-name/subscriptions/subscription-name"); // ①
Window<String> window = Window.<String>into(FixedWindows.of(Duration.standardMinutes(1))); // ②
TextIO.Write write = TextIO.write().withWindowedWrites().to("s3://bucket-name/").withCompression(Compression.GZIP).withNumShards(1); // ③
// ④
Pipeline pipeline = Pipeline.create(PipelineOptionsFactory.fromArgs(args).withValidation().create());
pipeline.apply(read).apply(window).apply(write);
pipeline.run();
}
}
素晴らしくないですか。このコード量。
どうやって実現するか、というのは全く書いておらず、何をやって欲しいかだけを記述しているのが分かります。
少し解説
何を書いているか一応説明します。
- ① こういう名前のsubscriptionから読みますよ。
- ② 1分毎に切りますよ。
- ③ ここに書き込みますよ。gzipで圧縮してね。
- withWindowedWritesは、終わりの無いデータを書き込むという宣言です。
- withNumShards(1)は、1区切りにつき1ファイルで書いてね、という宣言です。
- dataflowは内部的に並列で動いているので、ここの数字が大きいほうがパフォーマンス的には良いです。
- ④ 実行
リザルト
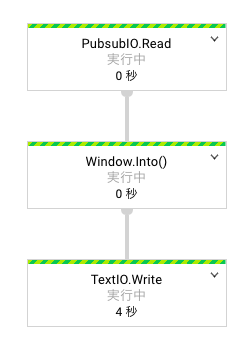
Dataflowにデプロイしてコンソールを見ると、以下のような画面が出ます。
コードに書いたとおりに実行されていることが分かります。
実際にアップロードされたファイルは以下のとおりです。
きちんと一分ごとにファイルがアップロードされており、ファイル名も良さげです。

まとめ
流れてくるデータをファイルにまとめてアップロードする、というのは普通にやるととても骨の折れる作業です。
それがこんなに簡単に出来てしまうなんて…!
結構色々出来るので、みなさんも是非触ってみることをおすすめします。
補足
補足がやたら長くなってしまった。
デプロイ方法
gradleを作ってコマンドを叩きます。
apply plugin: 'application'
repositories {
jcenter()
}
dependencies {
compile group: 'org.apache.beam', name: 'beam-sdks-java-core', version:'2.9.0'
compile group: 'org.apache.beam', name: 'beam-sdks-java-io-google-cloud-platform', version:'2.9.0'
compile group: 'org.apache.beam', name: 'beam-sdks-java-io-amazon-web-services', version:'2.9.0'
runtime group: 'org.apache.beam', name: 'beam-runners-google-cloud-dataflow-java', version:'2.9.0'
compile group: 'org.slf4j', name: 'slf4j-api', version:'1.7.25'
compile group: 'org.slf4j', name: 'slf4j-jdk14', version:'1.7.25'
}
mainClassName = "com.malt03.SamplePipeline"
./gradlew run --args=" \
--awsRegion=us-east-1 \
--project=project-name \
--runner=DataflowRunner \
--jobName=sample \
--awsCredentialsProvider='{ \
\"@type\": \"AWSStaticCredentialsProvider\", \
\"awsAccessKeyId\":\"access-key\", \
\"awsSecretKey\": \"secret-key\" \
}' \
"
AWSのcredentialの指定方法クソでは
はい、クソです。
僕は以下のようなコードを書いてしのいでいました。何れにせよクソ。
private static String[] createArgsWithAwsCredentials(String[] args, String awsAccessKey, String awsSecretKey) {
String[] newArgs = new String[args.length + 1];
System.arraycopy(args, 0, newArgs, 1, args.length);
String jsonFormat = "--awsCredentialsProvider={" +
" \"@type\": \"AWSStaticCredentialsProvider\"," +
" \"awsAccessKeyId\":\"%s\","+
" \"awsSecretKey\": \"%s\"" +
"}";
newArgs[0] = String.format(jsonFormat, awsAccessKey, awsSecretKey);
return newArgs;
}
ローカルで動かないんだけど
動きません。デバッグもデプロイしないと出来ないのは辛い…。
なんか、window処理は direct runner では対応していないようです。頑張れ direct runner。
ログ吐く場合
final class Logging extends DoFn<String, String> {
static final long serialVersionUID = 1;
private final Logger logger = LoggerFactory.getLogger(Logging.class);
@ProcessElement
public void processElement(ProcessContext c) {
logger.info(c.element());
c.output(c.element());
}
}
多分こんな感じの挟めば吐かれるはず。
stackdriver logging から確認できます。
実装の更新のやり方
--update をつければ、同名のjobNameからgracefulにやってくれます。素晴らしい。
ただ、一つ一つのtransformごとにデータを引き継ぐため、内部のデータ処理を変えていたりするとややこしいことになります。
また、当然transformが増えていたり減っていたりするとupdate出来ません。
そういうときは、ジョブをいったん停止してデプロイしなおしましょう。
停止するときは「ドレイン」を選択すれば、現在保持しているデータは片付けてから停止してくれます。
./gradlew run --args=" \
--update \
--awsRegion=us-east-1 \
--project=project-name \
--runner=DataflowRunner \
--jobName=sample \
--awsCredentialsProvider='{ \
\"@type\": \"AWSStaticCredentialsProvider\", \
\"awsAccessKeyId\":\"access-key\", \
\"awsSecretKey\": \"secret-key\" \
}' \
"
GCSにもあげられるのか?
どちらかというと「s3にも上げられる」だけで、特殊な事情がない限りGCSを使うほうが素直です。
普通に gcs://bucket-name/ とか書けば、認証とかは同プロジェクト内だったらサービスアカウント作るだけなので余裕です。
順序は保証されるか
されません。
無理にやろうとすれば出来ないことは無いか…?
まぁ、やめたほうが良いと思います。
もし保証したい場合は別を当たりましょう。
ファイル名もっとよさげにしたい場合
これはじつは結構大変です。
単に分割したパイプラインに対して出力先を変えたいのであれば、 FilenamePolicy を継承したクラスを作ってあげるだけです。
class MyFilenamePolicy extends FilenamePolicy {
private static final long serialVersionUID = 1;
private ResourceId prefix;
private DateTimeFormatter dateTimeFormatter = DateTimeFormat.forPattern("yyyy-MM-dd-HH-mm");
MyFilenamePolicy(String bucket) {
this.prefix = FileSystems.matchNewResource(bucket, true);
}
@Override
public ResourceId windowedFilename(int shardNumber, int numShards, BoundedWindow window, PaneInfo paneInfo,
OutputFileHints outputFileHints) {
IntervalWindow intervalWindow = (IntervalWindow) window;
String timeText = dateTimeFormatter.print(intervalWindow.start());
String filename = String.format("%s-%d%s", timeText, shardNumber, outputFileHints.getSuggestedFilenameSuffix());
return prefix.resolve(filename, StandardResolveOptions.RESOLVE_FILE);
}
@Override
public ResourceId unwindowedFilename(int shardNumber, int numShards, OutputFileHints outputFileHints) {
return null;
}
}
ただ、来たデータに応じてよしなにファイル名を変更したいのであれば、 TextIO の代わりに FileIO というのを使う必要があります。
ドキュメントがあまりなく、辛いです。
参考までに、僕が書いたコードを張っておきます。ちょっと改変して動作確認していないので動かなかったらすみません。
FileIO
.<String, PubsubMessage>writeDynamic()
.by(message -> message.getAttribute("bucket"))
.withDestinationCoder(StringUtf8Coder.of())
.withNaming(bucket -> new MyFileNaming(bucket))
.via(Contextful.<PubsubMessage, String>fn(message -> (new String(message.getPayload())).trim()), TextIO.sink())
.withTempDirectory(tempDirectory)
.withNumShards(1)
.withCompression(Compression.GZIP);
class MyFileNaming implements FileNaming {
private static final long serialVersionUID = 1L;
private static final DateTimeFormatter dateTimeFormatter = DateTimeFormat.forPattern("yyyy-MM-dd-HH-mm");
private final String bucket;
MyFileNaming(String bucket) {
this.bucket = bucket;
}
@Override
public String getFilename(BoundedWindow window, PaneInfo pane, int numShards, int shardIndex, Compression compression) {
IntervalWindow intervalWindow = (IntervalWindow) window;
String timeText = dateTimeFormatter.print(intervalWindow.start());
return String.format(
"%s/%s-%d%s",
bucket,
timeText,
shardIndex,
compression.getSuggestedSuffix()
);
}
}
複数のファイルに同じデータをあげたい場合
パイプラインは分岐できます。
以下のようにすると同じ内容の2つのファイルが作られます。
Pipeline pipeline = Pipeline.create(PipelineOptionsFactory.fromArgs(args).withValidation().create());
PubsubIO.Read<String> read = PubsubIO.readStrings().fromSubscription("projects/project-name/subscriptions/subscription-name");
Window<String> window = Window.<String>into(FixedWindows.of(Duration.standardMinutes(1)));
TextIO.Write write0 = TextIO.write().withWindowedWrites().to("s3://bucket-name-0/").withCompression(Compression.GZIP).withNumShards(1);
TextIO.Write write1 = TextIO.write().withWindowedWrites().to("s3://bucket-name-1/").withCompression(Compression.GZIP).withNumShards(1);
PCollection<String> windowed = pipeline.apply(read).apply(window);
windowed.apply(write0);
windowed.apply(write1);
pipeline.run();
障害がおきたらどうなるのか
例えば、s3までのルートが断絶した場合は、延々リトライし続けてくれます。
ただ、dataflowの母艦になっているGCEが死んだ場合どうなるのか、正直内部がブラックボックス過ぎてはっきり分かっていません。
ドキュメントを読む限り、復旧可能な形になっているようではあるのですが…。
pub/subとの関係性
ackのタイミングについて
pub/subに対していつackが送られるのかを調査したのですが、どうやら受け取り次第すぐackしているようです。
個人的にはファイルのアップロードが完了してからackしてくれる方が安心感があるのですが、そうはなっていません。
おそらく、データを受け取って内部的にデータを永続化したタイミングでackしているのだとは思いますが、想像でしかありません。
pub/subって複数回同じデータ送ってくることあるよね?
古いバージョンのドキュメントには、pub/subのmessageIdを見てよしなに弾いてくれる的なことが書いてありますが、最新のドキュメントには見当たりません。
また、独自のAttributeを利用してユニーク性を担保する withIdAttribute というメソッドがあるのですが、そこのドキュメントには
When reading from Cloud Pub/Sub where unique record identifiers are provided as Pub/Sub message attributes, specifies the name of the attribute containing the unique identifier. The value of the attribute can be any string that uniquely identifies this record.
Pub/Sub cannot guarantee that no duplicate data will be delivered on the Pub/Sub stream. If idAttribute is not provided, Beam cannot guarantee that no duplicate data will be delivered, and deduplication of the stream will be strictly best effort.
と、恐ろしいことが書いてあります。なので、publishする側で独自AttributeにUUIDでも付与したうえでこのメソッドを利用することをおすすめします。
このidは10分間保持され、それ以降に同じidが来ても通過するようです。10分以内に同じidが来た場合は更新され、更にその10分後に破棄されます。
これも古いドキュメントには書いてあるのですが、新しいドキュメントには書いていないので、あくまで調査した結果です。
どのタイミングのタイムスタンプでwindowingされるのか
pub/subがpublishを受け取ったタイミングのタイムスタンプが利用されるようです。
実装して変更することも可能です。ただし、受け取ったタイムスタンプよりも過去のタイムスタンプに変更しようとするとエラーになりますので注意してください。
final class CurrentTimestampTransformer extends DoFn<PubsubMessage, PubsubMessage> {
static final long serialVersionUID = 1;
@ProcessElement
public void processElement(ProcessContext c) {
Instant now = Instant.now();
if (now.isAfter(c.timestamp())) {
c.outputWithTimestamp(c.element(), now);
} else {
// 未来のtimestampが来ることがママある
c.output(c.element());
}
}
}
pub/subが遅延した場合
windowがどの程度の遅延を許容するかは .withAllowedLateness(Duration.standardDays(1)) のように定義できます。
それ以降に来たデータは破棄されます。
また、遅延した場合に、再度window内のすべてのデータを流すのか、新しく来たデータのみを流すのかは discardingFiredPanes もしくは accumulatingFiredPanes を呼び出すことで指定できます。
処理の冪等性が担保されているのであれば accumulatingFiredPanes を利用するのが良いでしょう。
僕が実装したケースではファイル名とデータの時間が一致している必要性がなかったので、上記の実装でタイムスタンプを更新し、遅延を考慮しなくて良いようにしてしまいました。
変換処理を挟む場合、windowの前にするのとあとにするのどっちが良いか
実験してみましたが、端的に言ってあまり気にしなくて良さそうです。
windowのあとに変換処理を入れても、1分毎に変換処理が走るわけではなく、データが来るたびに変換処理が走っていました。
内部処理がどうなっているかはわかりませんが、順番を入れ替えてもあまり処理としては変わらなそうです。
オートスケール
一応実装はされているものの、Betaです。負荷をかけてみましたが、オートスケールすることはありませんでした。
逆に勝手にスケールしまくっちゃうのも怖いですし、僕は --autoscalingAlgorithm=NONE としています。
スケーラビリティ
スケールアウトが簡単にできるので、かなりスケーラブルです。
--numWorkers=4 とかにしてあげればスケールアウトします。
パフォーマンスを更に良くしたいなら、 .withNumShards(4) とかすればファイルをまとめるコストもなくなります。