1ヵ月ほど機械学習について学んだので
復習とメモを兼ねて書きます。
はじめに
ペンギンは現在、全18種確認されているようです。
今回は画像認識によりペンギン全18種を判断することができるモデルの作成を目指します。
なお、ペンギンの画像は成体のみを対象としました。
訓練データ・テストデータ準備
機械学習用のデータを準備します。
ペンギンの画像をWebスクレイピングで収集し、ラベルを紐づけます。
ペンギンの画像は1種100枚とし、18種全1800枚を訓練データとテストデータに分けます。
なお、ルートフォルダ配下に種類ごとのフォルダ名が存在し、種類ごとのフォルダ名配下に画像ファイルを配置しています。
画像準備
初めに、スクレイピングで集めたペンギンの画像を水増しします。
1種あたり100枚を超えるまで水増しを行います。
from PIL import Image
import os.path
import glob
import numpy as np
import cv2
# インプットのルートフォルダ配下に種別のフォルダが存在し、種別のフォルダ配下に画像ファイルが存在している前提
class DataAugmentation:
def __init__(self, input_dir, output_dir, types):
self.input_dir = input_dir
self.output_dir = output_dir
self.types = types
self.name_idx = 0
# 出力先フォルダが存在しない場合は作成
if not(os.path.isdir(self.output_dir)):
os.makedirs(self.output_dir)
# 出力先フォルダに種別のフォルダが存在しない場合は作成
for img_type in self.types:
type_dir = self.output_dir + "\\" + img_type
if not(os.path.isdir(type_dir)):
os.makedirs(type_dir)
# 左右と上下に反転した画像を作成
def image_flip(self, image_file):
img = Image.open(image_file)
type_file = self.output_dir + "\\" + image_file.split("\\")[-2]
# 左右反転
tmp = img.transpose(Image.FLIP_LEFT_RIGHT)
tmp = tmp.convert('RGB') # RGBモードに変換する
tmp.save(type_file + "\\" + str(self.name_idx) + ".jpg")
self.name_idx += 1
# 上下反転
tmp = img.transpose(Image.FLIP_TOP_BOTTOM)
tmp = tmp.convert('RGB') # RGBモードに変換する
tmp.save(type_file + "\\" + str(self.name_idx) + ".jpg")
self.name_idx += 1
# 15度から345度まで15度ずつ回転した画像を作成
def image_rotate(self, image_file):
tmp = Image.open(image_file)
type_file = self.output_dir + "\\" + image_file.split("\\")[-2]
angle = 15
while angle <= 345:
rotate_img = tmp.rotate(angle)
rotate_img = rotate_img.convert('RGB') # RGBモードに変換する
rotate_img.save(type_file + "\\" + str(self.name_idx) + ".jpg")
self.name_idx += 1
angle += 15
# ノイズを付加した画像を作成
def image_noise(self, image_file):
try: # cv2.imread ファイルパスに日本語を含む場合の対応
n = np.fromfile(image_file, np.uint8)
tmp = cv2.imdecode(n, cv2.IMREAD_COLOR)
except Exception as e:
print(e)
return None
# 画像にノイズを付加
row, col, ch = tmp.shape
mean = 0
sigma = 15
gause = np.random.normal(mean, sigma, (row, col, ch))
gause = gause.reshape(row, col, ch)
gauss_img = tmp + gause
try: # cv2.imwrite ファイルパスに日本語を含む場合の対応
type_file = self.output_dir + "\\" + image_file.split("\\")[-2] + "\\" + str(self.name_idx) + ".jpg"
ext = os.path.splitext(type_file)[1]
self.name_idx += 1
result, n = cv2.imencode(ext, gauss_img, None)
if result:
with open(type_file, mode='w+b') as f:
n.tofile(f)
return True
else:
return False
except Exception as e:
print(e)
return False
# フォルダパス
input_root = "画像のルートフォルダ"
output_root = "画像の出力先フォルダ"
# ペンギンの種類
penguin_types = ["アデリーペンギン", "イワトビペンギン", "ガラパゴスペンギン",
"キングペンギン", "キンメペンギン", "ケープペンギン",
"コウテイペンギン", "コガタペンギン", "ジェンツーペンギン",
"シュレーターペンギン", "スネアーズペンギン", "ハネジロペンギン",
"ヒゲペンギン", "フィヨルドランドペンギン", "フンボルトペンギン",
"マカロニペンギン", "マゼランペンギン", "ロイヤルペンギン"]
# データ水増し
data_augmentation = DataAugmentation(input_root, output_root, penguin_types)
for type_name in penguin_types:
# 種別に画像を読み込み
penguin_type_dir = input_root + "\\" + type_name
files = glob.glob(penguin_type_dir + "/*.jpg")
# 画像の水増し処理を実行
for file in files:
data_augmentation.image_flip(file)
data_augmentation.image_rotate(file)
data_augmentation.image_noise(file)
訓練データ・テストデータ準備
画像ファイルを正規化し、one-hotラベルを作成する処理を作ります。
(to_categorical()を使用すればone-hotラベルを作成する必要はありませんでした。)
import glob
import random
import math
from PIL import Image
import numpy as np
# 全データ格納用配列
allfiles = []
# 種類の合計
type_total = None
# 画像の正規化とone-hotラベル作成
def make_image(files):
# 画像データ用配列
X = []
# ラベルデータ用配列
Y = []
cnt = 0
T = np.zeros((len(files), type_total))
for label, fdata in files:
# 画像ファイル正規化
img = Image.open(fdata).convert('RGB')
img = img.resize((300, 300))
data = np.asarray(img)
data = data.astype(np.float32) / 255.0 # 画像のピクセル値を0.0~1.0に正規化する
X.append(data)
# one-hotラベル作成
T[cnt][label] = 1
Y.append(T[cnt])
cnt += 1
return np.array(X), np.array(Y , dtype = 'uint8')
# 訓練用データとテストデータを作成
def load_data(root_dir, types):
global allfiles, type_total
type_total = len(types)
for idx, cat in enumerate(types):
image_dir = root_dir + "\\" + cat
files = glob.glob(image_dir + "/*.jpg")
for file in files:
allfiles.append((idx, file))
# 訓練データとテストデータに分ける
random.shuffle(allfiles)
th = math.floor(len(allfiles) * 0.8)
learning_data = allfiles[0:th]
test_data = allfiles[th:]
# 画像の正規化,one-hotラベルの作成
x_train, t_train = make_image(learning_data)
x_test, t_test = make_image(test_data)
# 訓練画像, 訓練ラベル, テスト画像, テストラベル
return (x_train, t_train), (x_test, t_test)
学習モデル
学習率は0.0001、活性化関数にRelu、最適化にAdamを使用したモデルを構築します。
from keras import layers, models
from keras.optimizers import Adam
# 学習モデル
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation="relu"))
model.add(layers.Dense(18,activation="softmax"))
adam = Adam(lr=1e-4)
model.summary()
model.compile(optimizer=adam, loss="binary_crossentropy", metrics=["accuracy"])
学習を行う
構築したモデルにペンギンを覚えてもらいます。
# 画像ファイルのルートフォルダ
root_dir = "ルートフォルダ"
# ペンギンの種類
penguin_types = ["アデリーペンギン", "イワトビペンギン", "ガラパゴスペンギン",
"キングペンギン", "キンメペンギン", "ケープペンギン",
"コウテイペンギン", "コガタペンギン", "ジェンツーペンギン",
"シュレーターペンギン", "スネアーズペンギン", "ハネジロペンギン",
"ヒゲペンギン", "フィヨルドランドペンギン", "フンボルトペンギン",
"マカロニペンギン", "マゼランペンギン", "ロイヤルペンギン"]
# データの読み込み
# 訓練画像, 訓練ラベル, テスト画像, テストラベル
(x_train, t_train), (x_test, t_test) = load_data(root_dir, penguin_types)
model = model.fit(x_train, t_train, epochs=10, batch_size=32, validation_data=(x_test,t_test))
# 学習結果を表示
acc = model.history['acc']
val_acc = model.history['val_acc']
loss = model.history['loss']
val_loss = model.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='training acc')
plt.plot(epochs, val_acc, 'b', label='validation acc')
plt.title('accuracy')
plt.legend()
plt.savefig('penguin_acc')
plt.figure()
plt.plot(epochs, loss, 'bo', label='training loss')
plt.plot(epochs, val_loss, 'b', label='validation loss')
plt.title('loss')
plt.legend()
plt.savefig('penguin_loss')
# モデルの保存
json_string = model.model.to_json()
open('PenguinsProblemProject.json', 'w').write(json_string)
# 重みの保存
hdf5_file = "PenguinsProblemProject.hdf5"
model.model.save_weights(hdf5_file)
学習結果-①
| 精度 | 損失率 |
|---|---|
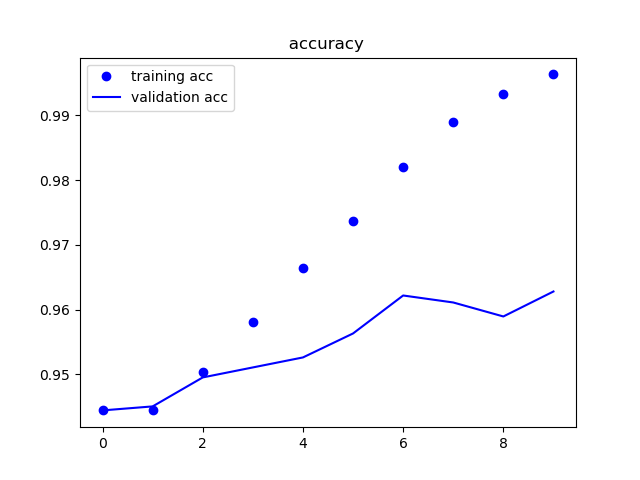 |
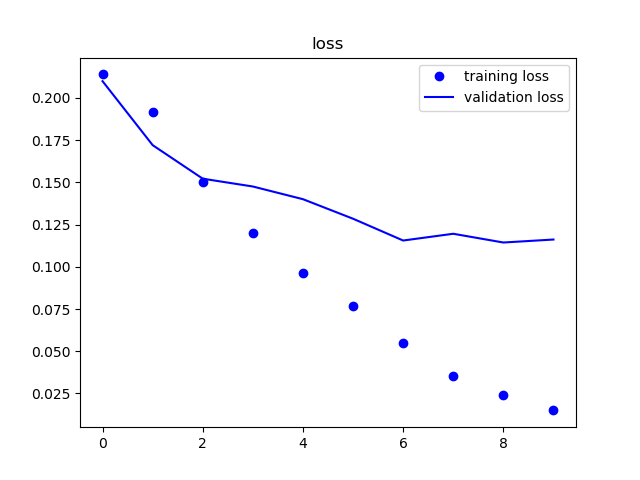 |
6epoch以降からまったく学習が進んでいないように見えます。
データの少なさから過学習が起きていると思われるので、データを増やし再度学習を行います。
また、同時にデータの質についても考えてみます。
データの拡張
1度目の学習では学習用のデータとして、ペンギンの画像を1種100枚(計1800枚)用意しました。
しかし、学習結果からデータ数が不足していると考えられるので、KerasのImageDataGeneratorを使用して学習用のデータを増やします。
# KerasのImageDataGeneratorを使用して画像を水増しする
# paramsに変換方法のパラメーターを指定
def keras_generator(self, image_file, params, save_image_num=10):
type_file = self.output_dir + "\\" + image_file.split("\\")[-2]
datagen = image.ImageDataGenerator(**params)
img = image.load_img(image_file)
img = np.array(img)
x = img[np.newaxis]
gen = datagen.flow(x, batch_size=1, save_to_dir=type_file, save_format='jpeg')
for i in range(save_image_num):
next(gen)
params = {
'rotation_range': 90, # 回転
'height_shift_range': 0.3, # 上下移動
'width_shift_range': 0.3, # 左右移動
'shear_range': 10, # せん断
'zoom_range': 0.3, # 拡大縮小
'channel_shift_range': 5.0, # 画素値
'fill_mode': 'nearest' # 外挿は最も近い値で埋める
}
とりあえず、何も考えずに画像を量産します。
その後、学習に適している(と思われる)画像を選定します。
データの選定
"ペンギン素人の私が直感的にペンギンの種類を判別できる=ペンギンの特徴がよく表れている"と考え、
水増しを行った画像のサムネイルからペンギンの種類が直感的に判断できるものを学習用のデータとして使用します。
- 水増ししたデータ

- 直感的に判断できるデータ

全身は写っていないですが、黒い顔と目の周りが白いというアデリーペンギンの特徴がサムネイルから見て取れます。
そのため、直感的にアデリーペンギンであると判断できる画像のため学習用のデータとして使用します。
- 直感的に判断できないデータ

全身が写っているためペンギンであることは判断可能です。
しかし、アデリーペンギンの特徴である顔が写っていないため、すぐに判断することができません。
そのため、学習には不適切であると考えられるため使用しません。
上記のような選定を行い、1種500枚の画像を用意しました。
学習結果-②
1種500枚(計9000枚)のデータを使用して再度学習を行います。
モデルは"学習モデル"と同様のモデルを使用します。
| 精度 | 損失率 |
|---|---|
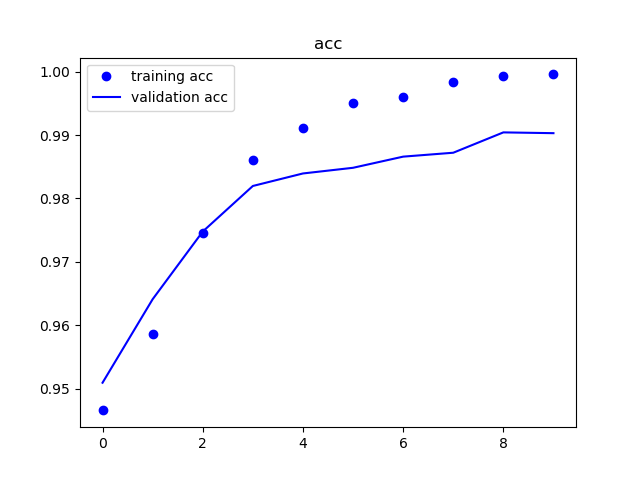 |
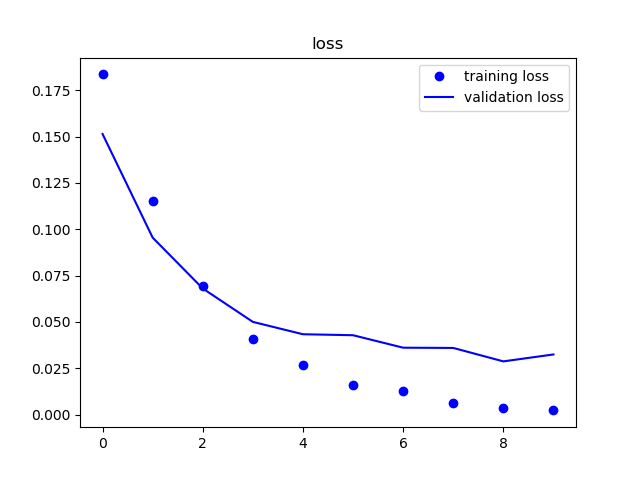 |
精度は改善されていますが、8epochから過学習しているように見えます。
次はドロップアウトを実装し、同様のデータを再度学習します。
学習結果-③
1種500枚(計9000枚)のデータを使用して、ドロップアウトを実装したモデルで学習を行います。
from keras import layers, models
from keras.optimizers import Adam
# 学習モデル
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation="relu",input_shape=(300, 300, 3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(Dropout(0.2)) # ドロップアウト率0.2を追加
model.add(layers.Conv2D(64,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(Dropout(0.2)) # ドロップアウト率0.2を追加
model.add(layers.Conv2D(64,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(Dropout(0.2)) # ドロップアウト率0.2を追加
model.add(layers.Conv2D(128,(3,3),activation="relu"))
model.add(layers.MaxPooling2D((2,2)))
model.add(Dropout(0.2)) # ドロップアウト率0.2を追加
model.add(layers.Flatten())
model.add(layers.Dense(512,activation="relu"))
model.add(Dropout(0.5)) # ドロップアウト率0.5を追加
model.add(layers.Dense(18,activation="softmax"))
adam = Adam(lr=1e-4)
| 精度 | 損失率 |
|---|---|
 |
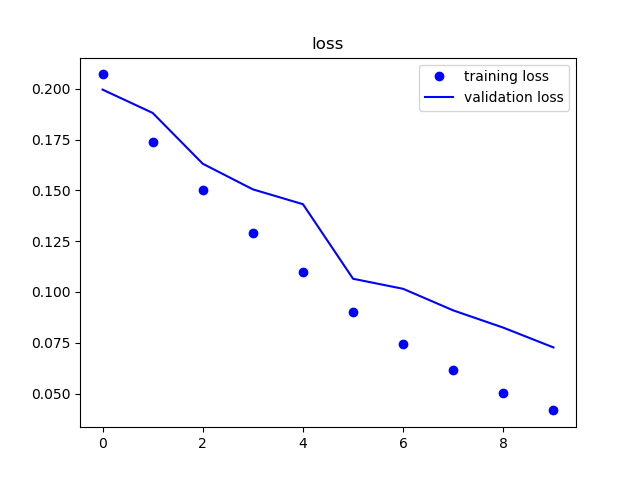 |
精度は順調に上がり続けているようです。
しかし、ドロップアウトを実装したため、収束に時間がかかっているように見えます。
ドロップアウトを実装した場合、10epochでは足りてないようです。
epoch数を増やすことでさらに良い結果が得られそうです。
(学習用のデータを増やしたことで学習時間が伸びたため、epoch数を増やした学習は行いませんでした。。)
学習結果を使用してペンギンの種類を判断する
最後に、学習した結果を使用してペンギンの種類を判断します。
なお、ここで使用した学習結果は"学習結果-②"を使用しています。
from keras.models import model_from_json
from PIL import Image
import numpy as np
# params
model_file = 'PenguinsProblemProject.json'
weight_file = 'PenguinsProblemProject.hdf5'
image_file = '画像のファイルパス'
penguin_types = ["アデリーペンギン", "イワトビペンギン", "ガラパゴスペンギン",
"キングペンギン", "キンメペンギン", "ケープペンギン",
"コウテイペンギン", "コガタペンギン", "ジェンツーペンギン",
"シュレーターペンギン", "スネアーズペンギン", "ハネジロペンギン",
"ヒゲペンギン", "フィヨルドランドペンギン", "フンボルトペンギン",
"マカロニペンギン", "マゼランペンギン", "ロイヤルペンギン"]
# 画像ファイル読み込み
img = Image.open(image_file).convert('RGB')
img = img.resize((300, 300))
img_arr = np.asarray(img)
img_arr = img_arr.reshape(300, 300, 3)
img_arr = img_arr.astype(np.float32) / 255.0 # 正規化
img_arr = np.expand_dims(img_arr, axis=0)
# 予測
model = model_from_json(open(model_file).read())
model.load_weights(weight_file)
ret = model.predict(img_arr)
# 結果を出力
print(penguin_types[np.argmax(ret)])
実行結果

種類:ロイヤルペンギン
出力結果:ロイヤルペンギン
→正解

種類:マゼランペンギン
出力結果:マゼランペンギン
→正解

種類:アデリーペンギン
出力結果:ケープペンギン
→不正解
おわりに
わかってはいましたが、データが非常に重要ですね。量もそうですが、特徴が掴めるデータを用意することが大切であると再確認しました。今回はペンギンを題材にしましたが、データ作成が非常に大変で後悔しました。個人で学習を行う分にはMNISTなどの公開されているデータセットを使用すべきですね。
参考にさせていただきました
- 書籍
- ゼロから作るDeep Learning
- 人工知能は人間を超えるか
- Data Augmentation
- Keras
- その他 google先生