画像水増しの意義
ディープラーニングのCNN等のクラス分類の精度を向上させるためには、優れた学習データセットが必要です。精度を担保するためには、以下のような工夫をする必要があります。
- 十分な画像枚数を用意する。
- 各タグの画像枚数を揃える
- タグ付けをより正確に行う
- 同じ分類のものでも、見た目が異なる場合は細かくタグを分ける
これらを行うためには、とにかく枚数が必要です。種類によって枚数に偏りがある場合もあり、すべて手作業で抽出・タグ付けしていると大変です。
そこで、ある程度タグ付けされた画像たちを加工することで、画像の枚数を増やすことを考えます。その手法を幾つか紹介します。なお説明には、高城れにさんを画像処理のサンプルに使うべきとの意見に基づき、高城れにさんを利用します。
水増し手法
OpenCV 3.0 Pythonで実装します。
実際に水増しに使えるソースをこちらに用意しておきます。
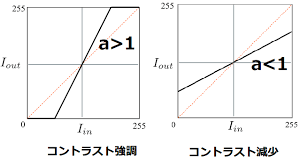
コントラスト調整
コントラストを強調、低減させた画像を作ります。
強調するには、一定以下の低輝度の画素を0, 一定以上の高輝度の画素を255にし、中間の輝度のものを調整します。
逆に低減するには、輝度の幅を小さくするように調整します。こちらの図がわかりやすいです。
# ルックアップテーブルの生成
min_table = 50
max_table = 205
diff_table = max_table - min_table
LUT_HC = np.arange(256, dtype = 'uint8' )
LUT_LC = np.arange(256, dtype = 'uint8' )
# ハイコントラストLUT作成
for i in range(0, min_table):
LUT_HC[i] = 0
for i in range(min_table, max_table):
LUT_HC[i] = 255 * (i - min_table) / diff_table
for i in range(max_table, 255):
LUT_HC[i] = 255
# ローコントラストLUT作成
for i in range(256):
LUT_LC[i] = min_table + i * (diff_table) / 255
# 変換
src = cv2.imread("reni.jpg", 1)
high_cont_img = cv2.LUT(src, LUT_HC)
low_cont_img = cv2.LUT(src, LUT_LC)
コントラストを強調したもの

コントラストを低減したもの

ガンマ変換
ディスプレイの表示などの際に使われる変換で、輝度値をγの値によって変化させます。
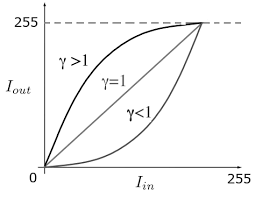
コントラスト調整のソースのルックアップテーブルを、こちらに置き換えてください。
# ガンマ変換ルックアップテーブル
gamma1 = 0.75
gamma2 = 1.5
for i in range(256):
LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1)
LUT_G2[i] = 255 * pow(float(i) / 255, 1.0 / gamma2)
γ=1.5のとき

γ=0.75のとき

参考
[ルックアップテーブル(ガンマ補正の例)] (http://imagingsolution.blog107.fc2.com/blog-entry-67.html)
平滑化
画像を滑らかにします。ここでは平均化フィルタをかけています。
average_square = (10,10)
src = cv2.imread("reni.jpg", 1)
blur_img = cv2.blur(src, average_square)
10×10平均化フィルタ

ガウス分布に基づくノイズ
各画素にガウス分布に基づく生成値を足して、ノイズを付加します。
σ=15のガウシアンノイズ

src = cv2.imread("reni.jpg", 1)
row,col,ch= src.shape
mean = 0
sigma = 15
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
gauss_img = src + gauss
Salt&Pepperノイズ
塩と胡椒をかけたようなノイズなので、こう呼ばれます。インパルスノイズとも言うそうです。
src = cv2.imread("reni.jpg", 1)
row,col,ch = src.shape
s_vs_p = 0.5
amount = 0.004
sp_img = src.copy()
# 塩モード
num_salt = np.ceil(amount * src.size * s_vs_p)
coords = [np.random.randint(0, i-1 , int(num_salt)) for i in src.shape]
sp_img[coords[:-1]] = (255,255,255)
# 胡椒モード
num_pepper = np.ceil(amount* src.size * (1. - s_vs_p))
coords = [np.random.randint(0, i-1 , int(num_pepper)) for i in src.shape]
sp_img[coords[:-1]] = (0,0,0)
0.4%の画素にノイズ

反転
左右の反転、上下の反転を行います。
src = cv2.imread("reni.jpg", 1)
hflip_img = cv2.flip(src, 1)
vflip_img = cv2.flip(src, 0)
拡大縮小
画像の一部を拡大、縮小します。
src = cv2.imread("reni.jpg", 1)
hight = src.shape[0]
width = src.shape[1]
half_img = cv2.resize(src,(hight/2,width/2))