はじめに
huggingfaceにはTRL(Transformer Reinforcement Learning)というライブラリがあります。これは、LLMをチューニングする際の、Instruction Tuning、報酬モデルの学習、PPOによるLLMのチューニング、をフルスタックで提供してくれるライブラリです。

今回はその中でもSFTTrainerに焦点を当てて使い方を詳しめに解説していきます。
SFTTrainerでできること
以前、huggingfaceのtransformersに紐づくTrainerクラスの紹介をしました。
SFTTrainerはこのTrainerクラスを継承したクラスになっており、TrainerクラスをよりLLMのチューニングに特化させたもの、みたいな位置づけかと思います。
SFTTraienrではLLMをチューニングしていく上で以下のことを簡単に行うことができます。
CausalLMによる学習(次単語を予測するタスク)
これはSFTTrainerに限った話ではなく、Trainerクラスでももちろんサクッと行うことができるのですが、SFTTrainerではdata_collatorを何も指定しないと、裏で DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)が設定されます。
Instruction Tuningの際に応答部分のみを損失計算する
trlにDataCollatorForCompletionOnlyLMというcollatorクラスがあります。このcollatorはInstruction Tuningする際のプロンプトの応答フォーマット(###応答、[ASSISTANT]: みたいなやつ)を指定することで、それ以降に続くtokenのみをCrossEntropyLossの計算対象としてくれます。(応答フォーマットを含むそれ以前のtokenに対してはCrossEntropyLossのignore_index -100を設定してくれる)
複数ターンの会話を学習させたいときも応答フォーマットに併せて、指示フォーマット(###指示、[USER]: など)の指定もすることで、各ターンの応答部分のみを損失計算できるようにignore_indexを良しなに設定してくれます。
LoRAによるチューニング
以前LoRAを使ったLLMのチューニング記事を投稿しましたが、SFTTrainerを使えば、同様のことがよりスッキリしたコードで実現できるかと思います。
packingによる学習
packingはデータセットを指定した固定長に(無理やり)詰め込んでpaddingをなくし効率的にLLMなどを学習させる方法で、LLMのチューニングの際はよく行われる方法です。
SFTTrainerでは、packingという引数があり、これをTrueに指定すると、内部でtrlのConstantLengthDatasetというクラスが使用されます。名前の通り、packing専用のDatasetクラスです。
NEFTuneによる学習
NEFTune(Noisy Embedding Fine Tuning)はLLMのEmbedding層にランダムなノイズを加えながら学習することでInstruction Tuningの性能を劇的に向上させることができる画期的な手法です。
これはそもそもTrainerクラスにも実装されてますが、SFTTrainerからも指定できます。Trainerと同様にSFTTrainerにもneftune_noise_alphaという引数があり、これでノイズのスケール調整を行うことができます。
本記事手は、上記の学習方法を実装例とともに解説していきます。
とくにpacking=Trueとしたときの内部の挙動が個人的には複雑に感じており理解に時間がかかったため、厚めに解説します。
※SFTTrainerのドキュメントにはFlash Attentionへの言及もありますが、SFTTrainer自体はあまり関係無い気がするので、本記事では割愛します。ただ、packingを行うときは系列長が長くなることが想定されるので、Flash Attentionを併せて使うことでより効率的に学習が行なえます。
Flash Attentionの使い方は以下の方の記事がめちゃくちゃわかりやすいのでこちらをご覧ください。
- Flash Attentionを使ってLLMの推論を高速・軽量化できるか?
- 【続】Flash Attentionを使ってLLMの推論を高速・軽量化できるか?
- Flash AttentionとDeep Speedを使ってLLMをGPU1枚でフルファインチューニングする
本記事を記述するに当たって、参考にさせていただいた記事やコードは以下のとおりです。
- SFTTrainerの公式ドキュメント
- Google Colab で SFTTrainer によるLLMのフルパラメータのファインチューニングを試す
- Google Colab で SFTTrainer によるLLMのフルパラメータの指示チューニングを試す
- SFTTrainerのコード
- ConstantLengthDatasetのコード
- DataCollatorForCompletionOnlyLMのコード
実装準備
本記事を投稿するに当たって使用した主要ライブラリのバージョンは以下のとおりです。huggingfaceは変化が激しいので、バージョンが変わると、本記事の内容が動かない可能性はありえますので、その点はご容赦ください。
accelerate 0.23.0
datasets 2.14.5
peft 0.5.0
torch 2.1.0+cu118
transformers 4.34.1
trl 0.7.4
今回実装紹介をする上で扱うLLMやデータセットは以下の通りとします。
- LLM: cyberagent/open-calm-large
- dataset: kunishou/databricks-dolly-15k-ja
open-calm-largeモデルをdolly-jaデータセットを使ってInstruction Tuningする、ということを題材にします。
まずはdolly-jaデータセットを用意します。
from datasets import load_dataset
dolly_dataset = load_dataset("kunishou/databricks-dolly-15k-ja")
# 簡易化のためinputの値が空のデータに絞る
# npakaさんの記事(https://note.com/npaka/n/nc7a4c20f98f8)を参考
dolly_train_dataset = dolly_dataset['train'].filter(lambda example: example['input'] == '')
print(dolly_train_dataset)
# データ件数は全部で10,417件
#Dataset({
# features: ['output', 'index', 'category', 'instruction', 'input'],
# num_rows: 10417
#})
print(dolly_train_dataset[0])
#{'output': 'イコクエイラクブカ',
# 'index': '1',
# 'category': 'classification',
# 'instruction': '魚の種類はどっち?イコクエイラクブカとロープ',
# 'input': ''}
モデルも読み込んでおきます。
from transformers import AutoModelForCausalLM, AutoTokenizer
# open-calm-largeは約7億パラメータの小さめのLLMです。
# とはいえ、本記事で紹介するコードをそのまま使うとcolab pro+で使えるA100ギリギリかもしれません。(試してません)
# お手元のGPUのリソースが限られている場合、動作確認が目的であれば、open-calm-smallに切り替えるなどしていただくと良いかもしれません。
model_name = "cyberagent/open-calm-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
# torch_dtype=torch.float16, # この時点でtorch.float16を指定すると、train時のlossが0.0になって学習がうまくいかない。原因がよくわかっていません。
)
2024年11月25日 追記
モデルを from_pretrained でロードする際、torch_dtype=torch.float16を指定するとloss=0になる現象について、@seanayuuto0826さんより有益なコメントをいただいているので、同様の事象に遭遇された場合はコメント欄の内容をご確認ください。
Instruction Tuningの際に応答部分のみを損失計算する
まず、SFTTrainerのformatting_func引数に渡すプロンプトフォーマット変換用の関数を定義します。SFTTrainerのドキュメントに記載されている通り実装しています。また、npakaさんの記事でも行っているように末尾にeos_token文字列を追加しています。
※前回記事と同様のプロンプトフォーマットを採用しています。
print(tokenizer.eos_token)
#'<|endoftext|>'
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n{example['instruction'][i]}\n\n### 応答:\n{example['output'][i]}<|endoftext|>"
output_texts.append(text)
return output_texts
Intruction Tuningを行う際、指示文も含めてすべてのトークンをCausalLMの損失計算の対象にしても学習はされるかと思いますが、応答部分のみを損失計算の対象とする方法のほうが効果的そうな気がします。(実際にそれを示す先行研究とかあれば知りたい。)
これを実現するには、data_collatorとしてDataCollatorForCompletionOnlyLMを使用する必要があります。
DataCollatorForCompletionOnlyLMを使用するにはSFTTrainerの引数としてpacking=Falseを設定する必要があります。つまり応答部分のみを損失計算しながら固定長にpackingする学習はSFTTrainerだけでは難しい、ということになるかと思います。
packing=Falseを指定するとConstantLengthDatasetも使われません。SFTTrainerに渡したデータセットをこちらのチュートリアルで行ってる方法と同様にtokenizeしてinput_idsやattention_maskを返すようになっています。(該当コードはこちら)
(packing=Trueのときの挙動については後半で詳しめに解説します。)
DataCollatorForCompletionOnlyLMはresponse_templateが必須指定になっています。
今回のプロンプトで言えばresponse_templateは### 応答:\nになるので、この文字列を指定します。
また、以下では指定していませんが、instruction_templateという引数もあります。
これは複数回の対話形式をする際に、ASSISTANTの応答部分のみを特定し、それ以外のtokenを-100に設定するためのものです。今回は1問1答形式の学習を想定しているため、特にinstruction_templateは指定していません。
instruction_templateが設定されていない場合、最後のASSISTANTの応答部分のみを特定し、それ以外のtokenを正解ラベルとして-100が設定されます。
from trl import DataCollatorForCompletionOnlyLM
# response_templateは必須指定
response_template = "### 応答:\n"
collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
実際にSFTTrainerインスタンスを作成するコードが以下になります。SFTTrainerはTrainerクラスで使うTrainingArgumentsを使って、学習時の様々な設定をTrainerクラスと同様に行うことができます。
from transformers import TrainingArguments
from trl import SFTTrainer
# SFTTrainerはTrainingArgumentsを使用することができる。
# 指定しない場合、TrainingArgumentsのデフォルトが指定される。
args = TrainingArguments(
output_dir='./output',
num_train_epochs=2,
gradient_accumulation_steps=8,
per_device_train_batch_size=8,
save_strategy="no",
logging_steps=20,
lr_scheduler_type="constant",
save_total_limit=1,
fp16=True,
)
# data_collatorが指定されていない場合、以下のようにDataCollatorForLanguageModelingがmlm=Falseで使われる。
# つまり通常のCausal LMを学習することになる。
# if data_collator is None:
# data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# packing=False(default)ではdataset_text_fieldかformatting_funcを指定する必要あり
trainer = SFTTrainer(
model,
args=args,
train_dataset=dolly_train_dataset,
formatting_func=formatting_prompts_func,
max_seq_length=1024,
data_collator=collator,
)
上記で定義したtrainerから指定したデータセットがちゃんとプロンプトフォーマットに変換されていることが確認できます。
print(trainer.train_dataset)
#Dataset({
# features: ['input_ids', 'attention_mask'],
# num_rows: 10417
#})
print(tokenizer.decode(trainer.train_dataset[0]['input_ids']))
#以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
#
#### 指示:
#魚の種類はどっち?イコクエイラクブカとロープ
#
#### 応答:
#イコクエイラクブカ<|endoftext|>
trainer.train_datsetがSFTTrainerの内部で使われるDatasetになるわけですが、これを先程定義したcollatorを使ってDataLoaderを動かしてみると、ちゃんと応答部分以外がignore_index -100で埋められていることも確認できます。(応答部分の前すべてとpaddingトークンに対して-100が設定されている。)
from torch.utils.data import DataLoader
loader = DataLoader(trainer.train_dataset, collate_fn=collator, batch_size=8)
batch = next(iter(loader))
print(batch['labels'][0])
#tensor([ -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, 275, 19052, 4044, 2048, 431, 367,
# 0, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
# -100, -100, -100, -100, -100])
あとはTrainerクラスと同様に.train()で学習、.save_model()でモデルの保存が簡単にできます。
trainer.train()
trainer.save_model()
このようにLLMをInstruction Tuningする際応答部分だけを損失計算対象として訓練する方法がこんなに簡単に少ないコードで実現できます。
LoRAによるチューニング
SFTTrainerを使えば、LoRAによるチューニングも少ないコードで簡単に記述できます。公式ドキュメント通り、peftでLoraConfigを定義して、SFTTrainerのpeft_config引数に指定してやれば終わりです。(data_collator引数やformatting_func引数などは前述と同様のものを指定しています。)
from peft import LoraConfig
peft_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
args = TrainingArguments(
output_dir='./output_lora',
num_train_epochs=2,
gradient_accumulation_steps=8,
per_device_train_batch_size=8,
save_strategy="no",
logging_steps=20,
lr_scheduler_type="constant",
save_total_limit=1,
fp16=True,
)
trainer = SFTTrainer(
model,
args=args,
train_dataset=dolly_train_dataset,
formatting_func=formatting_prompts_func,
max_seq_length=1024,
data_collator=collator,
peft_config=peft_config,
)
trainer.train()
trainer.save_model()
SFTTrainerではLoRAのAdapter部分だけを保存するためにcallback関数を定義しましょう、的なことが書かれています。この辺よくわかってないのですが、上記のコードのようにtrainer.save_model()とするだけで、output_dirに指定したディレクトリにはパラメータファイルとしてadatper_model.bin(LoRA Adapterのみのパラメータ)だけが保存されてました。ライブラリがドキュメントが書かれたときよりアップデートしてるんですかね。
また、SFTTrainerからLoRA学習を行うと、思った以上にGPUメモリ喰いました。同じ条件下でSFTTrainer使わずにLoRAチューニングを試してないので、気のせいかもしれませんが。
上記の点からもSFTTrainerによるLoRA学習が意図した挙動担っているかを念のため確認します。具体的には、SFTTrainerでLoRA学習する前後でモデルのベースのパラメータに変化がない(学習が行われていない)ことを確認します。
まず、今回使用するモデル(open-calm-large)の構造を見ておきます。これはSFTTrainerにモデルを渡す前の段階です。
print(model)の出力
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(52096, 1536)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-23): 24 x GPTNeoXLayer(
(input_layernorm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(in_features=1536, out_features=4608, bias=True)
(dense): Linear(in_features=1536, out_features=1536, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=1536, out_features=6144, bias=True)
(dense_4h_to_h): Linear(in_features=6144, out_features=1536, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=1536, out_features=52096, bias=False)
)
また、SFTTrainerに渡す前段階のLoRA Adapterが挿入されない層のパラメータも見ておきます。
# 最初の層のFFNの一部を確認する
# この時点ではrequires_grad=Trueになっている
first_ffn_param = model.gpt_neox.layers[0].mlp.dense_h_to_4h.weight
print(first_ffn_param)
#Parameter containing:
#tensor([[-0.1072, 0.0417, -0.0432, ..., -0.0873, -0.1708, -0.1608],
# [-0.0934, 0.0773, 0.0074, ..., -0.2107, 0.0881, -0.0803],
# [-0.0506, -0.1282, -0.1511, ..., 0.1120, -0.0126, -0.1172],
# ...,
# [ 0.1274, -0.0688, 0.1787, ..., 0.1432, 0.0266, -0.1370],
# [-0.1108, -0.0758, 0.0035, ..., -0.0404, -0.1801, 0.0338],
# [ 0.0669, 0.0399, -0.0443, ..., -0.2275, -0.1323, 0.0034]],
# device='cuda:0', requires_grad=True)
次にSFTTrainerにmodelを渡した後でSFTTrainerからmodelにアクセスしてみます。
print(trainer.model)
PeftModelForCausalLM(
(base_model): LoraModel(
(model): GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(52096, 1536)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-23): 24 x GPTNeoXLayer(
(input_layernorm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(
in_features=1536, out_features=4608, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.05, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=1536, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4608, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(dense): Linear(in_features=1536, out_features=1536, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=1536, out_features=6144, bias=True)
(dense_4h_to_h): Linear(in_features=6144, out_features=1536, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=1536, out_features=52096, bias=False)
)
)
)
今回特にLoraConfigを設定する際、target_modulesを指定していませんでしたが、いい感じにself-attentionの計算部分のLinear層にだけAdapterが挿入されていることがわかります。
学習されるパラメータ数を確認します。
trainer.model.print_trainable_parameters()
#trainable params: 1,179,648 || all params: 841,178,112 || trainable%: 0.14023760047622352
trainableなパラメータがかなり少なく、LoRAによる設定がちゃんとされてそうです。
SFTTrainerを使って学習されたAdapterを読み込むときはoutput_dirに指定したディレクトリを.from_pretrainedで読み込むだけでAdapterが挿入された状態でLLMをロードすることができます。ベースのパラメータはどこから持ってきてるんだ?って話ですが、output_dirのディレクトリ配下にadapter_config.jsonというものが出力されており、base_model_name_or_pathという項目にベースのモデルの参照先が格納されているので、ベースのパラメータをそこから持ってくることができているようです。
# adapterだけが保存されているディレクトリを指定するだけでちゃんとモデルをロードできている
lora_model = AutoModelForCausalLM.from_pretrained('./output_lora', device_map="auto")
念のため、ロードしたモデルと学習前のLLMにおいて、ベースモデルのパラメータに変化がないことも確認できます。
# adapterが挿入されていない層はパラメータはbaseモデルのときとまったく同じ
(lora_model.gpt_neox.layers[0].mlp.dense_h_to_4h.weight == first_ffn_param).all()
#tensor(True, device='cuda:0')
念のためいろいろ確認しましたが、SFTTrainerを使ったLoRAによるチューニングが簡単に記述できることを確認できました。
NEFTuneによる学習
NEFTuneは冒頭でも触れたようにLLMのEmbedding層にランダムなノイズを加えて学習することでInstruction Tuning
することで性能を向上させられる手法です。
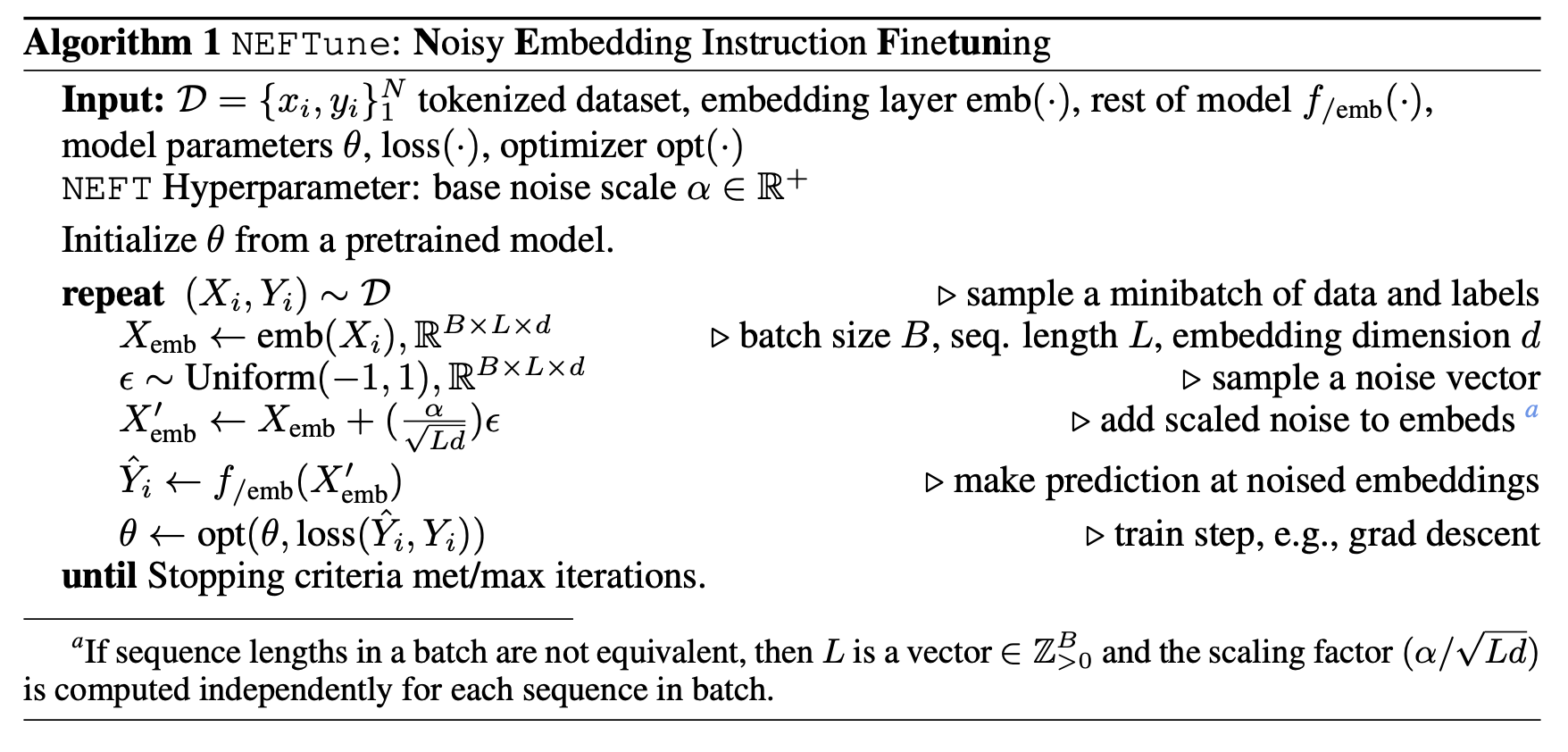
原論文のAlgorithm1から引用
neftune_noise_alphaは$\frac{\alpha}{\sqrt{Ld}}$ ($L$:系列長、$d$: embeddingの次元数)の計算式でノイズのスケーリングの機能を果たすようです。
NEFTuneを用いた学習を有効にするのは非常に簡単で、以下のようにSFTTrainerでneftune_noise_alphaを指定するだけでOKです。これだけでNEFTuneに学習が有効になります。
args = TrainingArguments(
output_dir='./output_neftune',
num_train_epochs=2,
gradient_accumulation_steps=8,
per_device_train_batch_size=8,
save_strategy="no",
logging_steps=20,
lr_scheduler_type="constant",
save_total_limit=1,
fp16=True,
)
# neftune_nosise_alphaはデフォルトでNone
# Noneでないfloat値が設定されるとNEFTuneの機能が有効になる。
# neftune_noise_alphaは埋め込み層に加算されるノイズベクトルのスケール調整に使われる。
trainer = SFTTrainer(
model,
args=args,
train_dataset=dolly_train_dataset,
formatting_func=formatting_prompts_func,
max_seq_length=1024,
data_collator=collator,
neftune_noise_alpha=5,
)
trainer.train()
trainer.save_model()
上記ではneftune_noise_alpha=5と、SFTTrainerのドキュメントで紹介されている値をそのまま使っています。本記事の条件下でこれが最適な値かどうかまでは調べていません。原論文では、Apppendix A.1にて、70BのLLamaモデルの実験では$\alpha=15$を使用したが、十分な検証はできていない、という記述があります。実際にNEFTuneを使用する際は、neftune_noise_alphaを何パターンか検証したほうがよいでしょう。
When using NEFTune on the 70B parameter model, we use α = 15 and did not explore other (potentially better) settings due to computational constraints.
packingを用いた学習
LLMの学習を行う際、データセットを固定の系列長に詰め込んで学習させる手法が主流のようで、SFTTrainerでもその学習方法をサポートしています。
SFTTrainerの引数としてpacking=Trueを指定することで、ConstantLengthDatasetが内部で使用されます。
注意点としてpacking=Trueを指定しつつ、data_collatorとしてDataCollatorForCompletionOnlyLMを使うことはできません。つまり、packingを行いながら、応答部分だけの損失を計算するような挙動はSFTTrainerに閉じる形では実現が現状は難しそうです。そういう学習を行いたい場合は自作でcollatorクラスを作るなりする必要があるかと思います。
packing=Trueのときの挙動を理解するにはConstantLengthDatasetの挙動を理解することが重要です。SFTTrainerのドキュメントにもpacking=Trueの説明で、以下のような記述があります。
Note that if you use a packed dataset and if you pass max_steps in the training arguments you will probably train your models for more than few epochs, depending on the way you have configured the packed dataset and the training protocol. Double check that you know and understand what you are doing.
まずはContantLengthDatasetを実際に使ってみましょう。
ConstantLengthDataset
ConstantLengthDatasetはIterableDatasetを継承したクラスです。なので、__getitem__メソッドを持っていません。
ConstantLengthDatasetの主な引数は以下です。
-
formatting_func- 各データをプロンプトのフォーマットに変換する関数を指定します。ちょっと注意なのが、上記でみてきた
formatting_funcとは違って、こちらでは各レコード1件に対しての変換処理を記述する必要があります。SFTTrainerのformatting_funcから指定することになります。
- 各データをプロンプトのフォーマットに変換する関数を指定します。ちょっと注意なのが、上記でみてきた
-
seq_length- packingする際の固定の系列長を指定します。指定された系列長になるまでデータが詰め込まれることを意味します。SFTTrainerからは
max_seq_lengthで指定します。
- packingする際の固定の系列長を指定します。指定された系列長になるまでデータが詰め込まれることを意味します。SFTTrainerからは
-
chars_per_token- 1トークンが占める文字数の推定値を指定します。これは
ConstantLengthDatasetの内部でデータをpackingする際にpacking対象として一時的にバッファー領域にデータを格納するのですが、そのバッファーの容量を決めるために使われます。SFTTrainerからはchars_per_tokenで指定します。
- 1トークンが占める文字数の推定値を指定します。これは
-
num_of_sequences- 内部で計算するバッファー容量として何センテンスまでを格納したいかを指定します。SFTTrainerからは
num_of_sequencesで指定します。
- 内部で計算するバッファー容量として何センテンスまでを格納したいかを指定します。SFTTrainerからは
-
infinite-
ConstantLengthDatasetの内部のイテレーターの処理において、データセットの終端に到達したときにイテレーターを終了させる代わりにデータセットの開始地点にイテレーターを戻す役割を果たします。実質無限ループのような振る舞いをします。デフォルトではFalseですが、infinite=Trueを指定したときは別の制御軸(エポック数やmaxステップ数)などで学習ループを制御する必要があります。SFTTrainerからはinfiniteで指定します。
-
packingとは?
そもそもpackingってどんな処理って感じの方に簡単に一般的なpackingの挙動の説明をします。
例えば以下のようなデータセットがあったとします。(1文字で1トークンだと思ってください。)
aaaaa
bbb
cccccc
dddd
...
このデータセットに対し、バッチサイズ2でそのまま上から順番にバッチ化すると、
1batch目: [aaaaa, bbb<pad><pad>]
2batch目: [cccccc, dddd<pad><pad>]
...
こんな感じでバッチ内の最大系列長に併せて短いデータはpaddingトークンで埋められてバッチ内で系列長を揃えます。ただこのpaddingは学習に使われない(attention maskが張られる)ので、paddingがたくさん発生すると計算効率が悪いです。(paddingも各networkを通るわけで。)
そこで以下のように無理やりデータを固定長に詰め込んでpaddingをなくすことを考えます。今回のケースでは固定長を5とすると、
1batch目: [aaaaa, bbbcc]
2batch目: [cccdd, ddeee]
...
こんな感じの詰め込み方になり、ccccccのデータが途中でtruncationされてます。文が途中で切れてよくないんじゃないか、とか、通常であれば計算されないattention(bbbとccの部分)も計算されちゃうのはどうなんだ?とかの懸念点はあるかと思いますが、その懸念以上にこのようにすることの計算効率向上のほうが、より大量のデータを早く学習できて恩恵が大きい、ということなんだと理解しています。
ConstantLengthDatasetの内部で行われるpackingの処理の流れ
実際のコードも適宜参照してもらいつつ、言葉でこの処理の説明をします。
実際の該当コード
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.max_buffer_size:
break
try:
buffer.append(self.formatting_func(next(iterator)))
buffer_len += len(buffer[-1])
except StopIteration:
if self.infinite:
iterator = iter(self.dataset)
warnings.warn("The dataset reached end and the iterator is reset to the start.")
else:
more_examples = False
break
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
examples = []
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length]
if len(input_ids) == self.seq_length:
examples.append(input_ids)
if self.shuffle:
random.shuffle(examples)
for example in examples:
self.current_size += 1
yield {
"input_ids": torch.LongTensor(example),
"labels": torch.LongTensor(example),
}
Step1
まず、バッファーという考えがあります。これはデータをpackingする際に、事前にpacking対象のデータを取り分けて一時的に格納しておく領域を果たします。バッファーのサイズは3つの引数を使って以下のように計算されます。
self.max_buffer_size = seq_length * chars_per_token * num_of_sequences
このバッファーに入り切るだけデータセットから順番にテキストを詰め込んでいきます。
Step2
バッファーの容量がいっぱいになったら、次にpackingの処理に入ります。packingはこのバッファーに格納されているテキストを全部tokenizerでtoken化します。このとき、各データ(文章)の末尾にEOSトークンを追加します。
そしてseq_length分のトークンをスライスして取り出し、バッチ内に含む1レコード分のデータを作成していきます。
seq_lengthで割り切れない端数分のデータは切り捨てられることに注意が必要です。
Step3
バッファー分のデータをpackingしてseq_length分のデータを順番にyieldで返却していきます。すべてのデータを返却し終えたら、バッファーの容量を空にして、データセットのイテレーターの続きからまたバッファーに格納する作業を再開します。
これをデータセットの終端まで繰り返します。データセットの終端までたどり着いたら、infinite=Falseを指定している場合、1epoch分が完了したことになりますが、infinite=Trueが指定されている場合はデータセットのイテレーターが初期化され、データセットの最初からバッファーに詰め込む作業が再開されます。
バッファーのサイズが小さすぎると、Step2で切り捨てられるデータが多くなってしまうかもしれません。逆にバッファーサイズが大きすぎると、一時的に大量のデータを確保しtokenizeする必要があり、効率が悪くなるかもしれません。この辺はトレードオフの関係があると思います。
なんでこんなバッファー領域が必要なのかというと、seq_lengthとして指定する固定長は実際はtokenizerでtoken化された後で計算する必要がありますが、最初からDatasetの段階ですべてのデータをtokenizeしてtoken化した上でデータをseq_lengthに詰め込む作業をしちゃうと、毎epoch同じpacking方法のデータで学習することになり、学習にへんな偏りとかが生じちゃうのを防ぐ目的もあるのかなーと考察してます。
ConstantLengthDatasetを実際に触ってみる
挙動の理解を確かめるために、おおよそすべてのデータをできるだけもれなくseq_length=1024でpackingできるバッファーサイズを計算してみます。そのためにchars_per_tokensとnum_of_sequencesを推定する必要があります。
まず今回の条件下(dolly-jaデータセットをopen-calm-largeモデルのTokenizerで扱う)に置いて、chars_per_tokensがどれくらいの値なのかを推定します。
# chars_per_tokensはデフォルトが3.6という値が設定されている。
# 推定方法のコードはstack-llamaqを参照している。
# 英語前提で計算してそうなので、日本語データで推定するとどれくらいの値になるのか、今回のdollyデータセットで確認
# 結果的に約2.12になった。これは扱うtokenizerが日本語のものなのか、多言語のものなのか、とかでも変わりそう。
from tqdm import tqdm
def prepare_sample_text(example):
"""Prepare the text from a sample of the dataset."""
# text = f"Question: {example['question']}\n\nAnswer: {example['response_j']}"
text = f"以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n{example['instruction']}\n\n### 応答:\n{example['output']}"
return text
def chars_token_ratio(dataset, tokenizer, nb_examples=400):
"""
Estimate the average number of characters per token in the dataset.
"""
total_characters, total_tokens = 0, 0
for _, example in tqdm(zip(range(nb_examples), iter(dataset)), total=nb_examples):
text = prepare_sample_text(example)
total_characters += len(text)
if tokenizer.is_fast:
total_tokens += len(tokenizer(text).tokens())
else:
total_tokens += len(tokenizer.tokenize(text))
return total_characters / total_tokens
chars_per_tokens = chars_token_ratio(dolly_train_dataset, tokenizer, nb_examples=dolly_train_dataset.num_rows)
chars_per_tokens
# 2.123043180452291
さらに今回使用するデータセットの合計文字数を計算します。
# 今回使用する合計文字数を計算
all_char_len = 0
for example in dolly_train_dataset:
text = formatting_func(example)
all_char_len += len(text)
all_char_len
# 2730673
これらの値からnum_of_sequencesは
num_of_sequences = (all_char_len / seq_len) / chars_per_tokens
# (2730673 / 1024) / 2.123043180452291
num_of_sequences
# 1257.8645526238206
だいたいnum_of_sequences=1258くらいに設定しておけばちょうどよいサイズのバッファーになりそうです。これを元にConstantLengthDatasetを使ってみます。
from trl.trainer import ConstantLengthDataset
# packing=Falseのときに見てきたformatting_funcと作り方が違う点に注意
# ConsantLengthDatset内部で末尾にeos_tokenを挿入するので、ここではeos_tokenの挿入は行わない。
def formatting_func(example):
text = f"以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n{example['instruction']}\n\n### 応答:\n{example['output']}"
return text
cl_dataset = ConstantLengthDataset(
tokenizer=tokenizer,
dataset=dolly_train_dataset,
formatting_func=formatting_func,
num_of_sequences=1258,
seq_length=1024,
chars_per_token=2.12,
shuffle=False,
)
実際にデータを取り出してみます。
# ConstantLengthDatasetはIterableDatsetを継承しているので、__getitem__を持っていない。
# i.e. cl_dataset[0]という呼び出しはエラーになる
d = next(iter(cl_dataset))
tokenizer.decode(d['input_ids'])
取り出した結果は以下のとおりです。長いので閉じておきます。
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n魚の種類はどっち?イコクエイラクブカとロープ\n\n### 応答:\nイコクエイラクブカ<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nラクダはなぜ水なしで長く生きられるのか?\n\n### 応答:\nラクダは、長時間にわたってエネルギーと水分で満たされた状態を保つために、腰の脂肪を利用しています。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nアリスの両親には3人の娘がいる:エイミー、ジェシー、そして三女の名前は?\n\n### 応答:\n三女の名前はアリス<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n国連に本部を建てるためにニューヨークの土地を寄付したのは誰?\n\n### 応答:\nジョン・デイヴィソン・ロックフェラー<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nスマホが人間に悪い理由\n\n### 応答:\n常にスマホを操作しているのが良くないため。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n多角形とは何ですか?\n\n### 応答:\n多角形は、幾何学における形の一つです。多角形は閉折れ線あるいは閉曲線を成す、線分の閉じた有限鎖で囲まれた平面図形である。多角形の頂点は、2つの辺が交わるところに形成されます。多角形の例としては、六角形、五角形、八角形があります。辺や頂点を含まない平面は、多角形ではありません。多角形でないものの例として、円があります。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nランニングを始めるにはどうしたらいいのでしょうか?\n\n### 応答:\nランニングシューズや服装は、使い慣れたものを用意し、5kmの走行のような達成可能な目標から始めましょう。走ったことがない人は、最初は15~30分を目標に、ウォーキング、早歩き、軽いジョギングから徐々に始めてください。体力がついてきましたら、少しずつ走る時間や距離を延ばしていきましょう。最も重要なことは、クールダウンとストレッチです。自分の体の声に耳を傾け、必要な時には休養をとり、怪我をしないようにしましょう。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nミシェル・マクラーレンが監督した『ゲーム・オブ・スローンズ』シーズン4のエピソードは?\n\n### 応答:\nシーズン4の第4話「誓約を果たすもの」、第5話「新王誕生」をそれぞれ監督した。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n自分で作れるユニークなカーテンのタイバックは?\n\n### 応答:\nカーテンのタイバックを作るために使用できるアイテムはたくさんあります。チェーン、サークル、ピン、ジュートロープ、木製ビーズロープ、ネックラック、ブレスレット、ドアノブ、革ベルト、マクラメロープ、造花などがそのアイデアです。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n楽器が弦楽器なのか、打楽器なのかを分類する:カンタロー、グドーク\n\n### 応答:\nグドークは弦楽器、カンタローは打楽器です。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nゴルフ用品の会社名トップ5をあげてください。\n\n### 応答:\nTitleist、Taylormade、Callaway、Ping、Cobra<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nオリンピック史上、最も多くの金メダルを獲得した個人は?\n\n### 応答:\nマイケル・フェルプス選手は歴代最多の23個の金メダルを獲得しています。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n「真珠の耳飾りの少女」を描いたオランダの画家は?\n\n### 応答:\nフェルメール<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n太陽が沈むとどうなるのか?\n\n### 応答:\n太陽が沈むと、夜が始まる。<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n動詞とは何ですか?\n\n### 応答:\n動詞とは、主に動作や状態を表し、項として主語や目的語などの名詞句をとる語である。動詞の例として泳ぐ、歩く、この結果を見てわかるように、各データの末尾<|endoftext|>の後に次のデータの指示文がくっついています。packingはこれをそのままCausalLMで学習します。
cl_datasetから全てのデータを取り出し、合計の文字数をカウントしてみます。
num_of_all_chars = 0
for chunked_text in cl_dataset:
decoded_text = tokenizer.decode(chunked_text['input_ids'])
decoded_text = decoded_text.replace(tokenizer.eos_token, '')
num_of_all_chars += len(decoded_text)
num_of_all_chars
# 2730086
全データの文字数が2,730,673だったの対し、packingされたデータの文字数は2,730,086になっており、ほぼほぼ全部のデータをpackingできていた、ということが確認できました。
SFTTrainerでpacking=Trueを指定して学習させる
ConstantLengthDatasetの使い方がなんとなくわかったところで、実際にSFTTrainerでpacking=Trueを指定して学習を行いますが、注意点がいくつかあります。
- 本セクションの冒頭でも述べたように
packing=TrueとDataCollatorForCompletionOnlyLMは併用できない。packing=Trueを指定する場合は通常のCausalLMで学習される。 -
formatting_func引数に渡す関数がpacking=Falseのときと仕様が違う -
infinite=Trueを指定してもTrainingArgumentsの段階でmax_stepsを指定していないとSFTTrainerの内部でinfinite=Falseが設定される。
とくにinfinite=Trueの挙動が個人的にはすごくわかりにくいと思いました。SFTTrainerではinfinite引数は指定できるのですが、それをちゃんと有効にするにはTrainingArgumentsで指定するmax_stepsを明示的に指定しないといけないからです。
つまりinfinite=Trueで学習させたいときは明確に何ステップ学習させたい、という計画があるとき以外は使う必要がない、ということでしょうか。そのようなケースがどういうときにありえるのか、私はちゃんと理解できていません。
def formatting_func(example):
text = f"以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n{example['instruction']}\n\n### 応答:\n{example['output']}"
return text
args = TrainingArguments(
output_dir='./output_packing',
num_train_epochs=2,
gradient_accumulation_steps=8,
per_device_train_batch_size=8,
save_strategy="no",
logging_steps=20,
lr_scheduler_type="constant",
save_total_limit=1,
fp16=True,
)
trainer = SFTTrainer(
model,
args=args,
train_dataset=dolly_train_dataset,
packing=True,
formatting_func=formatting_func,
# infinite=True, # Trueを指定してもargsでmax_stepsを指定しない限り内部でFalseになる
chars_per_token=2.12,
max_seq_length=1024,
num_of_sequences=1258,
)
trainer.train()
trainer.save_model()
packing=Falseのときと比べて、他の条件下が同じのとき、学習の時間が半分くらいになりました。
こんなに効率化されて逆に不安ですが、この後、紹介した全パターンの学習方法に対する推論結果を紹介します。
学習結果の比較
今回SFTTrainerで以下の4パターンのInstruction Tuningを試しました。
- 応答部分のみ損失計算する学習
- packingを用いた学習
- LoRAによる学習
- NEFTuneを用いた学習
(2.だけ応答部分のみの損失計算ができていません。)
今回はあくまでSFTTrainerの使い方にフォーカスしていたので、良いモデルを作ることは想定していません。本セクションではあくまで、各学習方法で、全然学習できてない、という状態ではなく、まぁちゃんとInstruction Tuningはされてそうだね、くらいの確認ができれば良いかなと思います。
そのために、Instruction TuningしていないベースのLLMの状態の推論結果も併せて確認していきます。
テキストを生成するコートは以下のようにしました。同じ条件下で生成させるため、ベースのLLMであっても今回の学習に使ったプロンプトフォーマットで入力します。
def generate(model, tokenizer, input_text):
input_text = f"以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n{input_text}\n\n### 応答:"
inputs = tokenizer(input_text, return_tensors='pt').to(model.device)
with torch.no_grad():
generated_tokens = model.generate(
**inputs,
max_length = 512,
do_sample = True,
temperature = 0.8,
top_p = 0.9,
top_k = 0,
repetition_penalty = 1.1,
num_beams = 1
)
generated_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
return generated_text
各モデルを辞書でまとめます。
model_name = "cyberagent/open-calm-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_dict = {
'base_model': AutoModelForCausalLM.from_pretrained(model_name, device_map="auto"),
'sft_model': AutoModelForCausalLM.from_pretrained('./output', device_map="auto"),
'packing_model': AutoModelForCausalLM.from_pretrained('./output_packing', device_map="auto"),
'lora_model': AutoModelForCausalLM.from_pretrained('./output_lora', device_map="auto"),
'nef_model': AutoModelForCausalLM.from_pretrained('./output_neftune', device_map="auto")
}
実際にいくつか推論させてみます。
(warningとかは適宜削除して記載しています。)
データサイエンティストに求められるスキルを5つ挙げてください。
input_text = "データサイエンティストに求められるスキルを5つ挙げてください。"
for model_type, model in model_dict.items():
generated_text = generate(model, tokenizer, input_text)
print('@'*3, model_type, '@'*3)
print(generated_text)
print('='*30)
@@@ base_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
データサイエンティストに求められるスキルを5つ挙げてください。
### 応答:
あるシナリオに関する詳細を回答し、適切なデータモデルを含めるようにします。
### データ分析:
発生したイベントと応答のデータ構造を比較し、各イベントの原因を理解します。
### PHPアプリケーション:
ウェブサービス開発者がクライアントのフォームに入力した値を表示するPHPコードを書きます。
==============================
@@@ sft_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
データサイエンティストに求められるスキルを5つ挙げてください。
### 応答: データサイエンスには、以下を含む多くの役割があります:統計解析、機械学習(ML)、パターン認識と予測、モデル評価、最適化された意思決定支援アルゴリズム(AOAC)。
==============================
@@@ packing_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
データサイエンティストに求められるスキルを5つ挙げてください。
### 応答:
1.データ分析の基礎を学ぶ2.データの可視化3.統計的アプローチ4.モデル駆動型分析5.予測と意思決定のためのツールの使用
==============================
@@@ lora_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
データサイエンティストに求められるスキルを5つ挙げてください。
### 応答: データ分析スキル
==============================
@@@ nef_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
データサイエンティストに求められるスキルを5つ挙げてください。
### 応答: データサイエンスのスキルには、コンピュータサイエンスの知識と、数学的な推論や探索に関するスキルが含まれます。これらの知識は、目的変数と述語変数を含む一般的な概念を理解するのに役立ちます。
==============================
日本の観光名所を3つ教えて下さい。
input_text = "日本の観光名所を3つ教えて下さい。"
for model_type, model in model_dict.items():
generated_text = generate(model, tokenizer, input_text)
print('@'*3, model_type, '@'*3)
print(generated_text)
print('='*30)
@@@ base_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
日本の観光名所を3つ教えて下さい。
### 応答:
どこに行きたいか説明しなさい。(その国の)地図を提供してください。
## # ###
(n-1) Haskellで2進数の数値を表す言語です。コンピュータのプログラムで使われることが多いですが、文字列処理でも使われます。コード例とアルゴリズムの例は以下に示されています。
### 指示:
$ k = $ (N + 1) / 2 を返します。ただし N + 1 は整数です。
### 応答:
$ x = $ (N + 1) / 4 を返します。ただし N + 1 は整数です。
## # ###
(n-1) K の素因数分解の実装を説明しなさい。
### 応答:
(n-1) K の素因数分解の実装を説明しなさい。
### 指示:
# \[ -\variable \] から答えよ。
### 回答:
a, b, c, dを 3 つ定めると、$a=b+c$ と書けることがわかります。
### 応答:
各文字について、その最初の文字がアルファベット以外の文字の場合に成立する、次の4つの規則のうち、条件に合うものを選びなさい。
1. 文字Aが '' で始まる文字は、'' を含むことを示す。
2. 文字A が '' で終わる文字は、'' を含まないことを示す。
3. 文字Aは '' で終わるが、'' に続く文字がないときは、'' を含むことを示す。
4. 文字B が '' で終わる文字は、'' を含まないことを示す。
### 指示:
オブジェクトをグループ化する関数makedocument_groupの作り方とその機能を説明しなさい。
### 応答:
makedocument_groupという新しい関数を作ってください。
makefuncsやmakemakeinstanceを使って作れます。
### 解説:
以下のような関数を定義します。
引数がそれぞれ、以下の通りです。
group()
echo func0;
makefileには以下のオプションがあります。
make install
引数argsに追加された内容を元に実行ファイルを生成してくれます。
###
==============================
@@@ sft_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
日本の観光名所を3つ教えて下さい。
### 応答:
- 日本は旅行先として素晴らしい国ですが、実は日本はとても魅力的な観光地でもあります。日本はアニメやゲームなどの影響もあり、世界的に有名で人気のある文化圏であることも知られています。その伝統や文化から、より多くの日本人に訪れてもらいたいと願っています。
==============================
@@@ packing_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
日本の観光名所を3つ教えて下さい。
### 応答:
富士山、京都、大阪
==============================
@@@ lora_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
日本の観光名所を3つ教えて下さい。
### 応答:
京都、日光東照宮、長崎など
==============================
@@@ nef_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
日本の観光名所を3つ教えて下さい。
### 応答:富士山、京都、そして日本の美しい景色を見るために多くの人が訪れる場所を紹介します:
- 京都 - 宇治市
- 日本海 - 北前船の港で有名である。
==============================
次の英文を日本語に翻訳してください。\nThis is a pen.
input_text = "次の英文を日本語に翻訳してください。\nThis is a pen."
for model_type, model in model_dict.items():
generated_text = generate(model, tokenizer, input_text)
print('@'*3, model_type, '@'*3)
print(generated_text)
print('='*30)
@@@ base_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
次の英文を日本語に翻訳してください。
This is a pen.
### 応答:
このペンを見て下さい。
### これは、文の意味です。
### 文は、動詞と名詞・代名詞の語幹を抽出したものでできています。また、文末のs(s)とcause(causal(s))も名詞と形容詞の語幹を抽出しています。
### 文章は短文で書きました。また、句読点なしで書く必要があります。
### 文中に句読点を使ってはいけません。つまり、空欄は空白でかまいません。
### 特定の単語やフレーズを書く必要はありません。単語リストに示されているように、どんな単語も3語以上であってもかまいません。また、語尾が「-ers」になっていてもかまいません。
### この文には、前置詞を入れても入れなくてもかまいません。しかし、その場合でも、すべての前置詞が動詞の語幹になっていることを確認してかまいません。そうでない場合は、「?p.」という語幹を使います。これは動詞「~するまで待つ」という意味です。
### 「there」に名詞または動詞が入る場合を除いて、次のように書きましょう。
1. (1) 「This is not the official soccer team.」
2. (2) 「This is a playoff league team.」
## #1. 「This is the official soccer team.」
## #2. 「This is a playoff league team.」
## # 3. 「That’s all for Tanzania and Oreo international cup.」
## #4. 「Oreo takes reaching university's rich debate.」
## #5. 「The leaders of your country are Hamilton, which are the best wrestler from Matchmaking, South Africa.」
## #6. 「They work hard and they don't miss Theater Openings at the basis.」
## #7. 「A few months ago the Oregon will open another ball roll.」
## #8. 「Friends about their family as a n
==============================
@@@ sft_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
次の英文を日本語に翻訳してください。
This is a pen.
### 応答:このペンはペンです
==============================
@@@ packing_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
次の英文を日本語に翻訳してください。
This is a pen.
### 応答:
ペンです!
==============================
@@@ lora_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
次の英文を日本語に翻訳してください。
This is a pen.
### 応答:
==============================
@@@ nef_model @@@
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい
### 指示:
次の英文を日本語に翻訳してください。
This is a pen.
### 応答:このペンはペンです
==============================
結果はさておき、SFTTrainerでチューニングされた各モデルは一応指示に従うような挙動はしてそうです。
なんどか推論させてみた感覚値ですが、
- LoRAは出力がされないときが結構ある
-
packing=Trueで学習したモデルが一番いい感じな挙動してそう - NEFTuneの効果が今回の検証の範囲ではよくわからん
おまけ(packing=Trueのときのattention可視化)
packing=Trueの学習は、複数のデータをEOSで繋げているので、本来計算されるべきでないattentionも計算されてしまいます。そんな学習の仕方なのになんでうまくいくのか不思議だったので、実際にpacking=Trueで学習されたモデルに対し、複数のデータをEOSで繋げた状態で推論したとき、各トークンが次単語を予測する際に、どのトークンにattentionしているかを可視化してみました。
まず上記で紹介した方法でpacking=Trueで学習されたモデルを読み込みます。
model_name = "/media/sj-archimedes/data/03_pretrained_model/llm/open-calm-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained('./output_packing')
model.cuda()
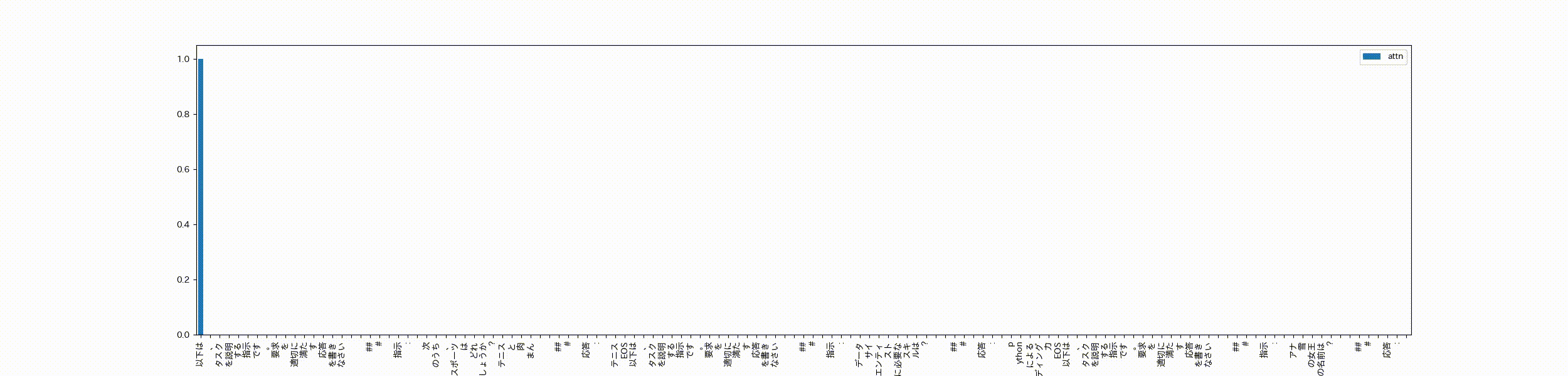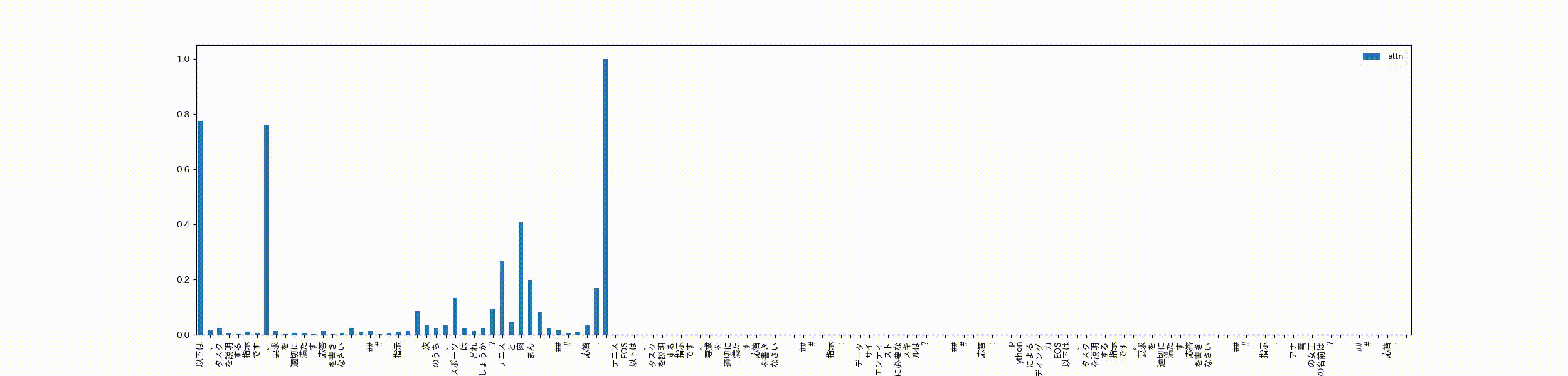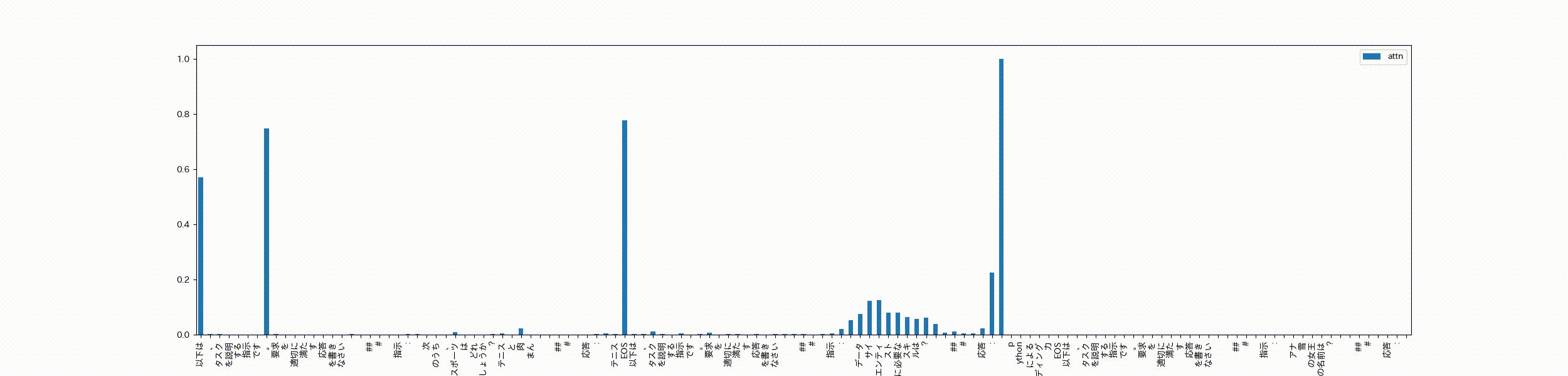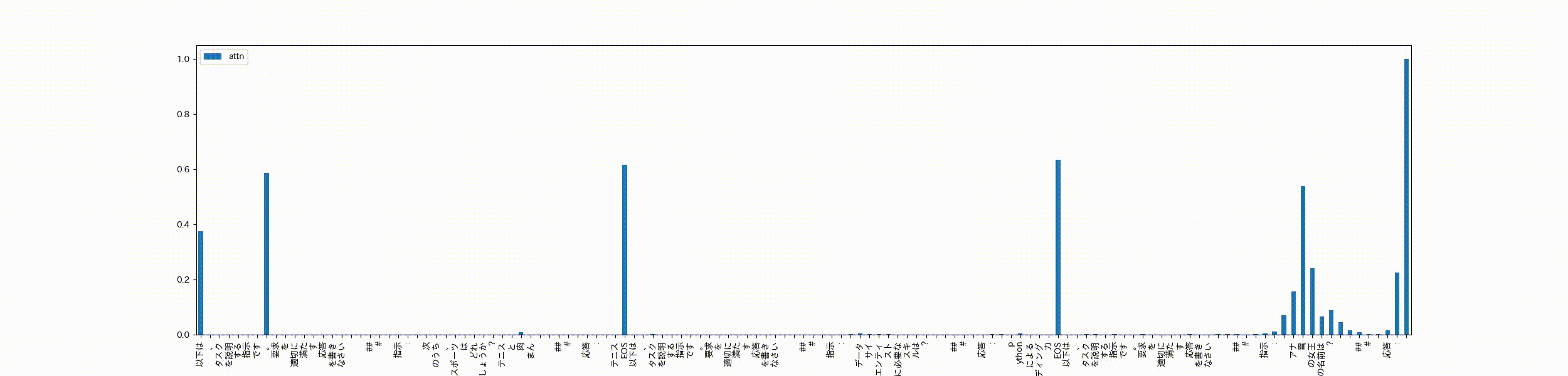
次にテキトーなサンプル文を用意します。これは私が作ったデータなので、多分学習データにはないかな?EOSトークンを使って3つのデータをpackingしています。最後のデータは回答がまだない状態です。
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\n次のうち、スポーツはどれでしょうか?テニスと肉まん\n\n### 応答:\nテニス<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nデータサイエンティストに必要なスキルは?\n\n### 応答:\npythonによるコーディング力<|endoftext|>以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい\n\n### 指示:\nアナ雪の女王の名前は?\n\n### 応答:\n"
このサンプル文章を学習済のモデルに入力したときの最終層のSelf-Attentionに対し、各headのattentionの合計をmaxで割って正規化したattentionを可視化します。
可視化するときは先頭のtokenから順番にどのtokenたちにattentionしてるかを計算し、アニメーションで表示させてみます。
可視化に使ったコードはちょっと雑なので、伏せておきます。
import pandas as pd
import matplotlib.ticker as ticker
from matplotlib.animation import FuncAnimation
import japanize_matplotlib
# サンプル文をforwardする
# input_textは上で紹介したサンプルのテキストを格納した変数
inputs = tokenizer(input_text, return_tensors='pt')['input_ids'].cuda()
outputs = model(inputs, output_attentions=True)
# 最終層のattention weightを取得
last_attn = outputs.attentions[-1][0].cpu().detach()
# 各tokenに対し、全てのheadに関するattentionを合算
all_attn = last_attn[0]*0
for head_idx in range(last_attn.shape[0]):
all_attn += last_attn[head_idx]
# サンプル文をtokenizerで分割した状態を作っておく(グラフのx軸のラベルに使う)
decoded_token = []
for token in inputs[0].cpu().detach():
t = tokenizer.decode(token)
if t == tokenizer.eos_token:
# <|endoftext|>だと文字が長いので短い表現に変える
t = 'EOS'
decoded_token.append(t)
df = pd.DataFrame({'token': decoded_token, 'attn': all_attn[0]})
df = df.set_index('token')
# フィギュアと軸の作成
fig, ax = plt.subplots(figsize=(25, 6))
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
# アニメーションを更新する関数
def update(i):
ax.clear()
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
last_token_attn = all_attn[i]
# 正規化
last_token_attn /= last_token_attn.max()
df['attn'] = last_token_attn
df.plot.bar(rot=90, ax=ax)
# アニメーションの作成
ani = FuncAnimation(fig, update, frames=range(all_attn.shape[1]), repeat=False)
# アニメーションの表示
plt.show()
※Decoder onlyなモデルなので、当然自身より後のtokenにはattentionされません。
先頭の文章の「以下は」と最初の句点にattentionが寄っちゃってますが、packingの処理でくっついただけの無関係なデータ同士はほとんどattentionせずEOSトークンがattentionをブロックする役割?を担ってる感じがします。最後のデータに対する応答もそのデータの指示文をattentionし、前にくっついている無関係なデータにはほとんどattentionしてません。
packing=Trueで学習してもEOSトークンで繋げておけば問題なさそう、ということがよくわかりました。
おわりに
huggingfaceのTRLライブラリにあるSFTTrainerの使い方について紹介しました。
TRLには他にもLLMをチューニングする上で便利な機能がたくさんあります。次はPPOTrainerとかその辺を紹介したい。
おわり