概要
こちらのHugging Faceのブログ記事では大規模言語モデル(LLM)に関する色々な技術が紹介されているのですが、その中でHugging Face形式のモデルのattentionをFlash Attentionに置き換える簡単な方法も紹介されていたので、日本語LLMで試してみました。推論速度およびGPUメモリ消費量が改善するかを検証しています。
Flash Attention
近年の深層学習モデルでは、LLMはもちろん画像・音声などの他の分野でもTransformerアーキテクチャがデファクトスタンダードとなっています。
Transformerアーキテクチャの中でコアとなるのが、Scaled Dot-Product Attention (SDPA)です。SDPAの解説は世にあふれているので詳細は他に譲りますが、SDPAは計算量が系列長に対して2乗で増加するので、長い系列を扱うときに計算量(特にGPUメモリ使用量)が膨大になってしまうという問題があります。
それに対して、アテンションに制限を加えて疎にしたり、ソフトマックス部分を置き換えることなどにより、計算量を下げる様々な方法が提案されています(サーベイ論文)。
それらの方法は元のSDPAとは計算内容が異なる"近似"手法なのですが、Flash Attention(論文1, 論文2, GitHub)は計算内容が元のSDPAと同じ厳密手法でありながら、計算アルゴリズムとGPUメモリへのアクセス方法を工夫することにより、GPUメモリ(VRAM)使用量を系列長に対して線形に抑え、計算速度も速くなるという手法です。
GPUアーキテクチャや入力データの形式によって使えない場合もあるのですが、Hugging Faceブログに
In practice, there is currently absolutely no reason to not use Flash Attention if available. The algorithm gives mathematically the same outputs, and is both faster and more memory-efficient.
とあるように、使える状況であれば使って損はない手法だと思います。
Flash AttentionはPytorch 2.0以降で公式にサポートされており、torch.nn.functional.scaled_dot_product_attentionを呼び出せば、使える時には自動的にFlash Attentionを使ってくれるようです。
ただし、様々な制限があり、特にcausal以外のattention_maskを与えた場合にはFlash Attentionは適用されません。こちらの日本語記事が参考になります。
ミニバッチ内で系列長が揃っておらずパディングを行う必要がある場合は、現時点では公式のFlash Attention実装やそれをラップしたxformersライブラリを使う必要がありますが、autoregressiveモデルの推論ではパディングは行われないので、Pytorch 2のFlash Attentionであっても問題なく使用できます。
今回は、Hugging Faceブログに従って、OptimumライブラリのBetter Transformerの機能を使うことで、Hugging Face形式のモデルでPytorch 2のFlash Attentionを使用可能にする方法を試します。
環境
実験はGoogle Colab上で行いました。使用したGPUはT4 (VRAM 15,360MiB)です。
公式のFlash Attention実装では(記事執筆時点では)TuringアーキテクチャのT4はサポートされていませんが、Pytorch 2のFlash Attentionであれば、(今回の実験結果を見る限り)T4でも使用できるようです。
ライブラリのインストール
!pip install transformers accelerate bitsandbytes optimum
Pythonおよびライブラリのバージョン
Python 3.10.12
accelerate 0.23.0
bitsandbytes 0.41.1
optimum 1.13.1
torch 2.0.1+cu118
transformers 4.33.2
実験
LLMとして、ELYZA-japanese-Llama-2-7bを使用します。
Instruction tuningされたモデルでもモデルアーキテクチャは同じですので、同様にFlash Attentionを使用することができます。
今回の方法は、OptimumライブラリのBetter Transformerがサポートしている形式のモデルにしか適用できず、ドキュメントを見るとLlamaが含まれていないのですが、ソースコードを見るとLlamaもサポートしているようです。(Hugging Face上ではLlamaとLlama-2は同じコードで実装されているので、Llama-2をもとにしたELYZA-japanese-Llama-2-7bもサポートされると思います。)
他の日本語LLMはたいていGPT-NeoXをもとにしているので、Better Transformerのサポート対象のはずです。
ライブラリインポート
import gc
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
GPUメモリ(VRAM)計測用関数
Hugging Faceブログに従って、ピークGPUメモリ使用量を計測する関数と、メモリ上のキャッシュを削除して計測をリセットする関数を準備します。
def measure_gpu_memory_allocation():
bytes = torch.cuda.max_memory_allocated()
return bytes / 1024**3 # GB
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
トークナイザーおよびモデルの立ち上げ
model_name = "elyza/ELYZA-japanese-Llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
use_cache=False,
)
model.cuda()
Flash Attentionを使うためには、テンソルの型がfloat16あるいはbfloat16であることが必須なので、モデルもtorch.float16で読み込んでいます。
Hugging Faceブログに書いてあるように、たいていのLLMは学習時点でfloat16を使用していますし、計算量の観点からも推論時にfloat32を使用するメリットはないので、この制約は問題にはならないでしょう。
また、今回はuse_cache=Falseという引数を与えています。これは、key-value cacheと呼ばれる、autoregressiveモデルの推論を効率よく行うための機能で、デフォルトではTrue(key-value cacheを利用する)となっています。
このkey-value cacheもLLMにおける重要技術の一つでHugging Faceブログでも解説されています。
Key-value cacheを使うと、Flash Attentionを使わない場合でもGPUメモリ使用量が系列長に対して線形になるため、Flash Attentionの効果が見えなくなるので、まずはuse_cache=Falseとして実験します。
use_cache=Trueの場合も含めた詳細な比較は最後に示します。
ダミーデータ準備
長い系列長に対するモデルのふるまいを調べたいので、ダミーの長い文章を準備します。文章の中身はなんでもいいです。
適当な文章を繰り返すことで長い文章を作りました。
sample_text = "大規模言語モデル(だいきぼげんごモデル、英: large language model、LLM)は、多数のパラメータ(数千万から数十億)を持つ人工ニューラルネットワークで構成されるコンピュータ言語モデルで、膨大なラベルなしテキストを使用して自己教師あり学習または半教師あり学習(英語版)によって訓練が行われる[1]。"
long_text = sample_text * 600
print(len(long_text)) # 文字数
# -> 94800
次にトークナイザーでトークン化します。
token_ids_long_text = tokenizer.encode(long_text, add_special_tokens=False, return_tensors="pt")
token_ids_long_text.shape
# -> torch.Size([1, 96601])
非常に長いトークン列が得られたので、これを適当な長さで切ってモデルの入力とします。
元モデルでの推論
まずは立ち上げたモデルそのままでFlash Attentionは使わずに推論にかけて、所要時間とGPUメモリ使用量を計測します。
長さnum_input_tokensの入力を与え、その続きを最大max_num_new_tokensまで生成させます。
今回の実験では、モデルは常に最大値のmax_num_new_tokensまで生成したので、モデルが扱う系列長はnum_input_tokens + max_num_new_tokensということになります。
初めに推論実行前のGPUメモリ使用量(主にモデルが占有するメモリ量)を計測し、推論実行後にピークメモリ使用量を計測することで、推論でどれだけのGPUメモリを使用したのかを測定します。
num_input_tokens = 512
max_num_new_tokens = 512
flush()
vram0 = measure_gpu_memory_allocation()
print(f"VRAM at start: {vram0:.2f} GB")
token_ids = token_ids_long_text[:, :num_input_tokens]
torch.cuda.synchronize() # GPU上の計算時間測定では必要
time0 = time.time()
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=max_num_new_tokens,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
do_sample =False,
)
torch.cuda.synchronize()
time1 = time.time()
vram1 = measure_gpu_memory_allocation()
output_text = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(f"Sequence length: {output_ids.size(1)}")
print(f"Output text length: {len(output_text)}")
print(f"Computation time: {time1 - time0:.1f} sec.")
print(f"VRAM at end: {vram1:.2f} GB")
print(f"VRAM difference: {vram1 - vram0:.2f} GB")
実行結果は以下のようになりました。
VRAM at start: 12.62 GB
Sequence length: 1024
Output text length: 506
Computation time: 400.2 sec.
VRAM at end: 13.06 GB
VRAM difference: 0.44 GB
Flash Attentionを使用した推論
Flash Attentionを使用する方法は非常に簡単です。
まず、BetterTransformer形式にモデルを変換します。
model.to_bettertransformer()
このとき、以下のメッセージが出力されますので、BetterTransformerではattention maskをサポートしておらず、パディングを使う場合には適用できないことがわかります。
The BetterTransformer implementation does not support padding during training, as the fused kernels do not support attention masks. Beware that passing padded batched data during training may result in unexpected outputs. Please refer to https://huggingface.co/docs/optimum/bettertransformer/overview for more details.
モデルの変換は一瞬で終わりますので、あとはモデルを呼び出す部分を以下のwith句で囲ってコンテキストを指定してやるだけです。
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
実験用コードの全体は以下のようになります。
num_input_tokens = 512
max_num_new_tokens = 512
flush()
vram0 = measure_gpu_memory_allocation()
print(f"VRAM at start: {vram0:.2f} GB")
token_ids = token_ids_long_text[:, :num_input_tokens]
torch.cuda.synchronize() # GPU上の計算時間測定では必要
time0 = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=max_num_new_tokens,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
do_sample =False,
)
torch.cuda.synchronize()
time1 = time.time()
vram1 = measure_gpu_memory_allocation()
output_text = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True)
print(f"Sequence length: {output_ids.size(1)}")
print(f"Output text length: {len(output_text)}")
print(f"Computation time: {time1 - time0:.1f} sec.")
print(f"VRAM at end: {vram1:.2f} GB")
print(f"VRAM difference: {vram1 - vram0:.2f} GB")
実行結果は以下の通りです。
VRAM at start: 12.62 GB
Sequence length: 1024
Output text length: 506
Computation time: 333.5 sec.
VRAM at end: 12.93 GB
VRAM difference: 0.31 GB
Flash Attentionを使わない場合と比較して、
- 計算時間: 400秒 → 333秒
- 推論VRAM使用量: 0.42 GB → 0.31 GB
とそれぞれ減少していることがわかります。
モデルに入力する系列長を変えて、系統的に行った比較の結果は以下で示します。
結果①
モデルに入力する系列長を変えながら、上記の計算を繰り返しました。
Key-value cacheを使わない場合と使う場合それぞれで比較を行っています。
以下の表とグラフで、系列長(sequence length)は、num_input_tokens + max_num_new_tokens(入力と出力の系列長の和)を意味します。
また、推論によるVRAM使用量とは、推論実行中のピーク使用量から実行前の使用量(モデルが占有しているメモリ量)を引いたもののことです。
Key-Value cacheを使わない場合 (use_cache=False)
- 計算時間(秒)
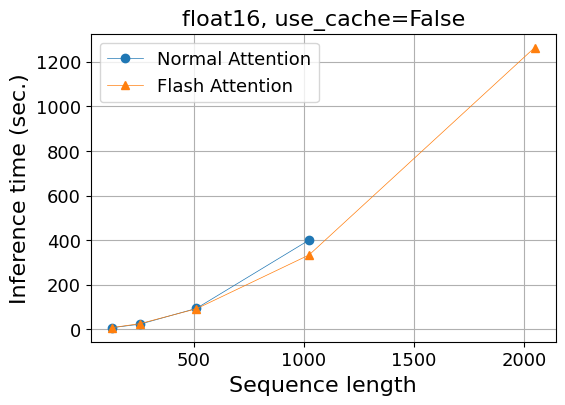
| 系列長 | 128 | 256 | 512 | 1,024 | 2,048 |
|---|---|---|---|---|---|
| Normal Attention | 7.0 | 22.9 | 93.6 | 400.2 | OOM |
| Flash Attention | 7.3 | 25.3 | 91.9 | 333.5 | 1,263.3 |
OOMはOut Of Memoryで計算が実行できなかったことを意味します。
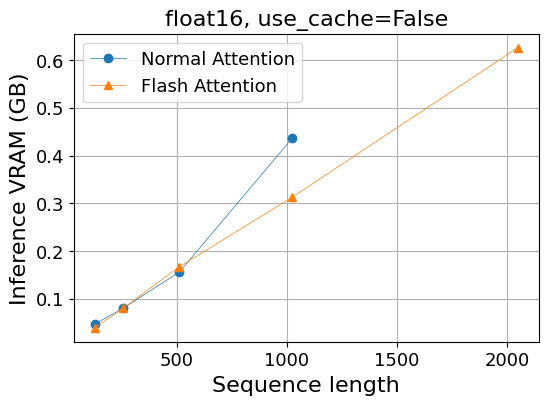
- 推論によるVRAM使用量 (GB)
| 系列長 | 128 | 256 | 512 | 1,024 | 2,048 |
|---|---|---|---|---|---|
| Normal Attention | 0.05 | 0.08 | 0.16 | 0.44 | OOM |
| Flash Attention | 0.04 | 0.08 | 0.17 | 0.31 | 0.63 |
それぞれグラフにしたものが下図です。
 |
 |
計算時間に関しては大きな差はありませんが、系列長が長くなるにつれFlash Attentionが優勢になる傾向は見えます。
メモリ使用量に関しては明らかな差が見えています。通常のAttentionでは系列長に対して線形よりも早く増加しており、系列長2,048ではout of memoryとなってしまいました。一方、Flash Attentionではメモリ使用量は系列長に対して線形で増加していることが見て取れます。
Key-Value cacheを使う場合 (use_cache=True)
次にモデルインスタンスを立ち上げる時に、use_cache=True引数を与えてkey-value cacheを有効化した時の結果を見てみましょう。
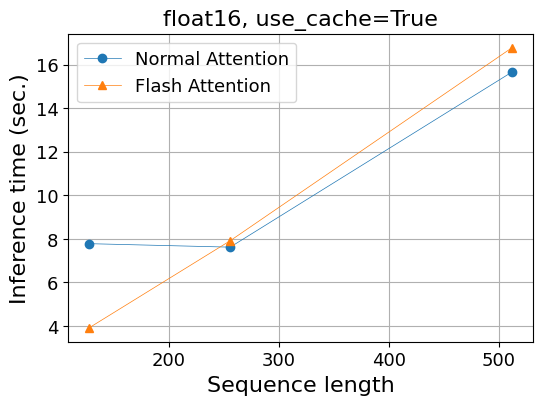
- 計算時間(秒)
| 系列長 | 128 | 256 | 512 | 1,024 |
|---|---|---|---|---|
| Normal Attention | 7.8 | 7.6 | 15.7 | OOM |
| Flash Attention | 3.9 | 7.9 | 16.8 | OOM |
- 推論によるVRAM使用量 (GB)
| 系列長 | 128 | 256 | 512 | 1,024 |
|---|---|---|---|---|
| Normal Attention | 0.13 | 0.25 | 0.50 | OOM |
| Flash Attention | 0.12 | 0.25 | 0.50 | OOM |
 |
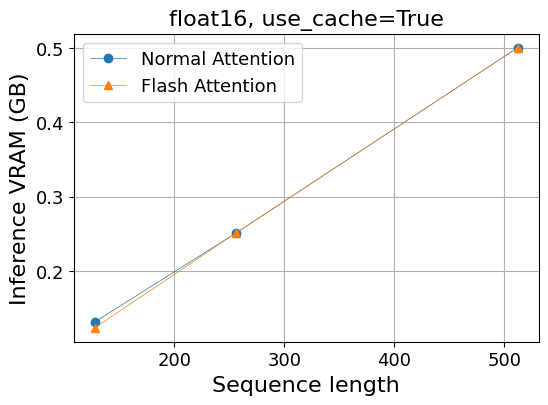 |
この場合、通常のAttentionを使っていても、メモリ使用量は系列長に対して線形で増えています。
Hugging Faceブログで解説されている通りです。
計算時間に関しても、key-value cacheを使うことによって、使わない場合に比べて特に系列長が長い時に高速化されています。
通常のAttentionとFlash Attentionとの比較では、key-value cacheを使うことによって計算時間でもメモリ使用量でも差がなくなってしまいました。(系列長128の時の計算時間には差がありますが、なんらかの誤差である可能性が高いと思います。)
これは、key-value cacheによる最適化の恩恵が大きいためにFlash Attentionの効果が見えなくなったとも考えられますが、key-value cacheを有効化した時にはFlash Attentionは実装上無効になるという可能性もあり、理由は調査できていません。
結果② int8の場合
上記の実験では、VRAMの容量が15GBしかないT4 GPUに70Bモデルをfloat16で読み込んだため、VRAMの残り容量が少なく、系列長をそれほど長くすることが出来ませんでした。
Flash Attentionやkey-value cacheを使ったときの効果をよりはっきりと確認するために、モデルをint8で読み込んで同様の実験をすることとします。
hugging Faceでは、下記のようにload_in_8bit=True引数を与えるだけで、8bit量子化した重みを読み込むことができます。
model = AutoModelForCausalLM.from_pretrained(model_name, load_in_8bit=True, use_cache=False)
Flash Attentionは入力データがfloat16かbfloat16の時にしか使えないので、重みを量子化した時にも使えるのかという疑問が生じますが、Hugging Faceブログによると、重みと入力データをかける前に重みをbfloat16に変換するそうなので、Flash Attentionの使用には問題ないはずです。
今回は、use_cache=False/Trueの場合をまとめて示します。
- 計算時間(秒)
| 系列長 | 128 | 256 | 512 | 1024 | 2,048 | 4,096 |
|---|---|---|---|---|---|---|
| Normal Attention, use_cache=False | 16.8 | 33.8 | 92.5 | 353.4 | 1745.3 | OOM |
| Flash Attention, use_cache=False | 16.4 | 33.9 | 82.5 | 267.1 | 1,039.1 | 4,529.2 |
| Normal Attention, use_cache=True | 18.8 | 27.8 | 54.8 | 112.6 | 228.4 | 481.3 |
| Flash Attention, use_cache=True | 13.1 | 27.0 | 54.5 | 109.3 | 225.4 | 474.8 |
- 推論によるVRAM使用量 (GB)
| 系列長 | 128 | 256 | 512 | 1024 | 2,048 | 4,096 |
|---|---|---|---|---|---|---|
| Normal Attention, use_cache=False | 0.07 | 0.08 | 0.16 | 0.42 | 1.36 | OOM |
| Flash Attention, use_cache=False | 0.03 | 0.08 | 0.16 | 0.33 | 0.71 | 1.45 |
| Normal Attention, use_cache=True | 0.14 | 0.25 | 0.50 | 1.00 | 2.00 | 4.00 |
| Flash Attention, use_cache=True | 0.11 | 0.25 | 0.50 | 1.00 | 2.00 | 4.00 |
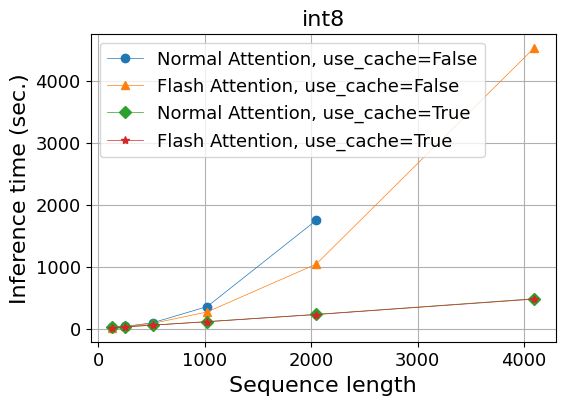

実験①で見られたものと同様の傾向が、よりはっきりと見て取れます:
- Key-value cacheを使わない場合、Flash Attentionによりメモリ使用量が系列長に対して線形に軽減され、計算速度も上がっている。
- Key-value cacheを使うと、Flash Attentionを使わなくてもメモリ増加は線形になり、Flash Attentionの効果は見えなくなる。
- メモリ使用量はkey-value cacheを使うと大きくなる(線形の傾きが大きくなる)。
- 計算時間はkey-value cacheを使った方が圧倒的に速い。
メモリ使用量だけを見るとkey-value cacheを使わずにFlash Attentionだけを使った方が有利な状況もありますが、key-value cacheを使わないと長い系列に対する計算時間が非常に長くなるので、key-value cacheを使わないという選択肢はないと思います。実際、use_cache引数はデフォルトでTrueとなっています。
モデルの重みがfloat16の時との比較では、推論に必要なメモリ使用量は変わりませんが、推論時間は全体に長くなっています。これは、上述したように内部で重みをint8からbfloat16に変換する処理があり計算量が増えるためだと思われます。
まとめ
Hugging Faceで利用できるLLMではFlash Attentionを簡単に適用でき、実際にFlash Attentionにより系列長に対するGPUメモリ使用量の増加が線形に軽減されることを確かめました。
一方で、LLMの推論を効率化する別の技術であるkey-value cacheによっても、GPUメモリ使用量は線形に軽減され、推論速度向上の効果はkey-value cacheの方が圧倒的に高いため、key-value cacheを使うとFlash Attentionの効果が見えなくなるということも確認しました。
したがって、実用上は推論時にはFlash Attentionを使う利点はないという結論に至りました。(ただし、key-value cacheを使うとFlash Attentionが実装上無効化されるという可能性を排除できていません。)
今回は推論のみを調べましたが、Flash Attentionの原論文で示されているように、学習時であればFlash Attentionは速度向上・使用メモリ軽減の大きな効果を持つことが期待されます。学習時も今回紹介した方法でFlash Attentionを使えるはずなので今後試してみたいです。