はじめに
huggingfaceのTrainerクラスはhuggingfaceで提供されるモデルの事前学習のときに使うものだと思ってて、下流タスクを学習させるとき(Fine Tuning)は普通に学習のコードを実装してたんですが、下流タスクを学習させるときもTrainerクラスは使えて、めちゃくちゃ便利でした。
ただTrainerクラスのinitやTrainingArgumentsの引数はたくさんあるしよくわからん、という人のために、TrainerクラスのFine Tuning時の使い方を実装を通してまとめてみようと思います。
今回は自然言語処理のタスクとしてlivedoorニュースコーパスのタイトル文のカテゴリー分類問題をFine Tuningの例題として扱おうと思いますが、ViTのFine Tuningとかでも同様かと思います。
基本的にはhuggingfaceのTrainerクラスのリファレンスをひたすら見ながら勉強したので、詳しくはリファレンスをご参照ください。
Trainerクラスを使ったFineTuningの実装例
データ準備
livedoorニュースコーパスをbody, title, categoryに分けたデータフレームを事前に用意しておきます。
import pandas as pd
import os
df = pd.read_pickle('./input/livedoor_data.pickle')
# カテゴリーのID列を付与しておく
categories = df['category'].unique().tolist()
category2id = {cat: categories.index(cat) for cat in categories}
df['category_id'] = df['category'].map(lambda x: category2id[x])
df.sample(3)

データを学習、検証、テストで分けます。
from sklearn.model_selection import train_test_split
train_df, eval_df = train_test_split(df, train_size=0.7)
eval_df, test_df = train_test_split(eval_df, train_size=0.5)
print('train size', train_df.shape)
print('eval size', eval_df.shape)
print('test size', test_df.shape)
# train size (5163, 4)
# eval size (1106, 4)
# test size (1107, 4)
Datasetクラスを用意
Datasetからデータを取り出すと辞書形式でタイトル文とカテゴリーのIDが紐付いたデータを取れるような形式にしました。
from torch.utils.data import Dataset
from tqdm import tqdm
class LivedoorDataset(Dataset):
def __init__(self, df):
self.features = [
{
'title': row.title,
'category_id': row.category_id
} for row in tqdm(df.itertuples(), total=df.shape[0])
]
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx]
train_dataset = LivedoorDataset(train_df)
eval_dataset = LivedoorDataset(eval_df)
test_dataset = LivedoorDataset(test_df)
train_datsetからデータを1件取り出して中身を確認してみるとこんな感じです。
train_dataset[0]
# {'title': '肉体派イケメン総出演で、チャニング・テイタムの″ストリップ経験″を映画化!', 'category_id': 0}
DataCollatorの定義
-
TrainerクラスがDataLoaderじゃなくてDataCollatorを引数として受け取るので、DataCollatorクラスを自作します。 - huggingfaceも
DataCollatorクラスをいくつか提供してますが、今回は単純な処理しかしないので、自作で済ませてます。
import torch
from transformers import AutoTokenizer
class LivedoorCollator():
def __init__(self, tokenizer, max_length=512):
self.tokenizer = tokenizer
self.max_length = max_length
def __call__(self, examples):
examples = {
'title': list(map(lambda x: x['title'], examples)),
'category_id': list(map(lambda x: x['category_id'], examples))
}
encodings = self.tokenizer(examples['title'],
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors='pt')
encodings['category_id'] = torch.tensor(examples['category_id'])
return encodings
tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
livedoor_collator = LivedoorCollator(tokenizer)
後の処理では使いませんが、DataCollatorの動きを確認するために、DataLoaderを作成して、1件バッチデータを取り出してみます。
from torch.utils.data import DataLoader
loader = DataLoader(train_dataset, collate_fn=livedoor_collator, batch_size=8, shuffle=True)
batch = next(iter(loader))
for k,v in batch.items():
print(k, v.shape)
# input_ids torch.Size([8, 41])
# token_type_ids torch.Size([8, 41])
# attention_mask torch.Size([8, 41])
# category_id torch.Size([8])
print(batch)
# {'input_ids': tensor([[ 2, 9680, 10520, 28770, 28865, 450, 52, 53, 512, 9594,
# 5359, 126, 243, 28673, 12, 6, 5359, 40, 16329, 28476,
# 2935, 63, 7388, 104, 6, 331, 28483, 4658, 35, 15288,・・・
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,・・・
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ・・・
# 'category_id': tensor([0, 8, 8, 2, 1, 7, 0, 2])}
モデルの定義
テキストの特徴量変換は学習済BERTにまかせて、カテゴリー分類用のヘッド(nn.Linear)を1層追加したシンプルなモデルを実装しますが、モデル定義が少しTrainerクラス用に書く必要があります。
Trainerクラスのリファレンスにも書いてあるように、TrainerクラスはhuggingfaceのPreTrainedModelで動作が最適化されているようなので、PreTrainedModelと同じようなルールで動作するモデルを実装する必要があります。
普段FineTuningとかするときのモデルはnn.Moduleを継承したクラスで実装するかと思いますが、以下のルールを満たしていればTrainerクラスは動いてくれます。
- モデルの戻り値はhuggingfaceの
ModelOutputの形式で返す(もしくはtupleでもいいようですが、ModelOutputのほうが便利だと思うので、ModelOutputのケースで説明します。) - モデルの
forwardが正解ラベルを受け取れるようにしておく - モデルが損失の値を返す
1. モデルの戻り値をModelOutputにする
ModelOutputはtransformers.modeling_outputs.ModelOutputを使えばいいだけです。キーに[]じゃなくて.でもアクセスできる便利な辞書のイメージです。BERTの戻り値の型BaseModelOutputWithPoolingAndCrossAttentionsもModelOutputを継承したクラスでした。
ModelOutputを使うときは、ModelOutputのリファレンスでそうしてるように、損失の値をloss、モデルの予測結果をlogitsという名前に格納します。
2. forwardで正解ラベルを受け取れるようにする
今回自作したDataCollatorが正解ラベルcateogory_idを返すようにしているので、forwardの引数にもcateogory_idを含めておけば良いです。(Trainerクラスのデフォルトでは正解ラベルをlabelsという名前で想定していますが、後に解説するTrainingArgumentsで正解ラベルの名前を指定できます。マルチタスク学習のような正解ラベルが複数あるケースにも対応できます。)
3. モデルが損失を返すようにする
つまりはモデル内で損失を計算する必要があるので、モデルのinitで損失関数を指定するようにしています。モデルのforward内で引数で受け取った正解ラベルcategory_id(やlabels)とモデルの予測結果を受け取って損失関数でlossを計算し、ModelOutputのlossに損失を格納して返してやればOKです。以下の実装ではFineTuning後に推論で使うことも想定して、損失関数をinitで指定しなかった場合、lossは計算されずNoneを返すようにしています。
import torch.nn as nn
from transformers import AutoModel
from transformers.modeling_outputs import ModelOutput
class LivedoorNet(nn.Module):
def __init__(self, pretrained_model, num_categories, loss_function=None):
super().__init__()
self.bert = pretrained_model
self.hidden_size = self.bert.config.hidden_size
self.linear = nn.Linear(self.hidden_size, num_categories)
self.loss_function = loss_function
def forward(self,
input_ids,
attention_mask=None,
position_ids=None,
token_type_ids=None,
output_attentions=False,
output_hidden_states=False,
category_id=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
token_type_ids=token_type_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states)
state = outputs.last_hidden_state[:, 0, :]
state = self.linear(state)
loss=None
if category_id is not None and self.loss_function is not None:
loss = self.loss_function(state, category_id)
attentions=None
if output_attentions:
attentions=outputs.attentions
hidden_states=None
if output_hidden_states:
hidden_states=outputs.hidden_states
return ModelOutput(
logits=state,
loss=loss,
last_hidden_state=outputs.last_hidden_state,
attentions=attentions,
hidden_states=hidden_states
)
loss_fct = nn.CrossEntropyLoss()
pretrained_model = AutoModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
net = LivedoorNet(pretrained_model, len(categories), loss_fct)
compute_metricsを自作する
ここまでの実装の準備でTrainerクラスは動かせるのですが、このままだと、学習中の検証データに対するメトリクスの計算が行われません。メトリクスは自作で関数を用意する必要があります。今回はニュース記事のカテゴリーの分類問題なので、評価指標にF1スコアを使うことにします。合わせてPrecisionやRecallも計算できるようにしました。
Trainerクラスに渡すcompute_metricsの引数はEvalPredictionを想定しています。EvalPredictionについてはこちらを参照していただきたいのですが、要はEvalPrediction.predictionsにモデルの予測結果が、EvalPrediction.label_idsに正解ラベルが格納されています。
戻り値は辞書形式で返してやれば良いです。この辞書で定義したキー名(precision, recall, f1は後にeval_の接頭辞が付与されてログ情報に使われます。)
from transformers import EvalPrediction
from typing import Dict
from sklearn.metrics import precision_score, recall_score, f1_score
def custom_compute_metrics(res: EvalPrediction) -> Dict:
# res.predictions, res.label_idsはnumpyのarray
pred = res.predictions.argmax(axis=1)
target = res.label_ids
precision = precision_score(target, pred, average='macro')
recall = recall_score(target, pred, average='macro')
f1 = f1_score(target, pred, average='macro')
return {
'precision': precision,
'recall': recall,
'f1': f1
}
TrainingArgumentsを設定する
TrainingArgumentsの引数は大量にあって、全部紹介するのは難しので詳しくはリファレンスを参照していただきたいですが、いくつかよく使いそうなものを紹介します。
-
output_dir: モデルのチェックポイントや学習後のパラメータファイルとかの保存先 -
evaluation_strategy: デフォルトはstepsが指定されてます。評価データをどのタイミングで評価するかを指定します。stepsを指定すると、eval_stepsで指定したステップ毎にcompute_metricsで指定したメトリクスが計算されます。今回はepochを指定するので、1エポック終わるたびに評価されます。 -
logging_strategy: 学習のロギング(損失の値とか学習率の状況とか)をどのタイミングで実施するかを指定します。デフォルトはstepsが指定されており、logging_stepsで指定したステップ毎にロギングされます。今回はepochを指定するので、1エポック終わるたびにロギングされます。 -
save_strategy: チェックポイント(学習の中間の状況)をどのタイミングで保存するかを指定します。デフォルトはやはりstepsが指定されており、save_stepsで指定したステップ毎にチェックポイントが保存されます。今回はepochを指定するので、1エポック終わるたびにチェックポイントが保存されます。 -
save_total_limit: チェックポイントを何件残すか。 -
label_names: 正解ラベルのラベル名を配列で指定します。指定しなければTrainerクラスは正解ラベルをlabelsという名前で参照しに行きます。マルチタスク学習のような正解ラベルが複数あるケースでも対応可能のようです。 -
lr_scheduler_type: 学習率のスケジュールのテンプレートを指定します。どんなテンプレートがあるかはこちらをご参照ください。SchedulerTypeのソースコードを見るとテンプレートと名前の対応関係がわかります。デフォルトはlinearが指定されており、最終エポックに向かって線形に学習率が減少していくようなスケジュールになっています。以下のようにconstantを指定すれば学習率が減少するようなスケジュールは設定されません。 -
learning_rate: 学習率です。デフォルトは5e-5が指定されています。この値をこのまま使いたいので、今回は指定していません。 -
warmup_ratio/warmup_steps: (今回は指定していません。)デフォルトではともに0が指定されているのでフォームアップは行われませんが、これらのどちらかを指定すると、指定したステップまで線形に学習率が増加してしくフォームアップの学習を行うことができます。 -
metric_for_best_model: early stoppingをする際には必要です。異なるモデルを比較するときに比較する指標をします。compute_metricsで定義したメトリクスの名前を指定します。今回はF1スコアが一番良いモデルを保存したいので、f1を指定しました。 -
load_best_model_at_end: early stoppingを行うときはTrueを指定する必要があります。学習中に得られたベストモデルを学習終了後にロードするかどうか。 -
per_device_train_batch_size: 学習中に1GPUに割り振るバッチサイズ。例えば2枚のGPUが使える環境では1枚毎に指定したバッチサイズが乗ります。 -
per_device_eval_batch_size: 評価データを計算するときに1GPUに割り振るバッチサイズ -
num_train_epochs: 学習のエポック数 -
remove_unused_columns: デフォルトがTrue。これがTrueだと、Trainerにわたすデータセットのカラム(今回でいえば、titleとcategory_id)のうちモデルのforward関数の引数に存在しないものは自動で削除されます。今回の実装方法はcollatorクラスでtokenizerに通してinput_idsとかを取得したいのでこのパラメータがTrueだとcollatorの__call__関数内で空の辞書が渡されてしまいます。datasetの時点でtokenizerに通してtensorを保持しているようなケースであればTrueで良いかもしれませんが、今回はFalseにします。
2023/4/10 追記
transformersのバージョンを4.27.1を使っていたところ、学習を開始したら wandb に関する以下のメッセージが表示されました。
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice:
別に wandb とか使ってませんよー、って人は毎回これが表示されるのうっとおしいと思いますが、これは以下の引数で "none" を指定すれば回避できます。
- 'report_to': 結果やログ情報をなんのプラットフォームを使ってまとめるかを指定します。デフォルトで
"all"になってるんですが、いらない場合は"none"を指定すれば良いです。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir='./output/model',
evaluation_strategy='epoch',
logging_strategy='epoch',
save_strategy='epoch',
save_total_limit=1,
label_names=['category_id'],
lr_scheduler_type='constant',
metric_for_best_model='f1',
load_best_model_at_end=True,
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
num_train_epochs=3,
remove_unused_columns=False,
report_to='none'
)
Trainerクラスの定義と実行
これまで定義してきたものを全部Trainerクラスのinitに渡してやればOKです。
今回はearly stoppingも行っていますが、その際はcallbacksに以下のようにEarlyStoppingCallbackを指定してやります。
Trainerクラスで使えるcallbacksの詳しい情報はリファレンスをご参照ください。
Trainerクラスを定義すれば、後は.trainで学習を開始できますが、そのときにignore_keys_for_evalで評価に必要ないモデルの戻り値の変数名を指定するようにしましょう。
from transformers import Trainer
from transformers import EarlyStoppingCallback
trainer = Trainer(
model=net,
tokenizer=tokenizer,
data_collator=livedoor_collator,
compute_metrics=custom_compute_metrics,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
trainer.train(ignore_keys_for_eval=['last_hidden_state', 'hidden_states', 'attentions'])
notebookで実行すればこんな感じのprogress barが表示されますね。
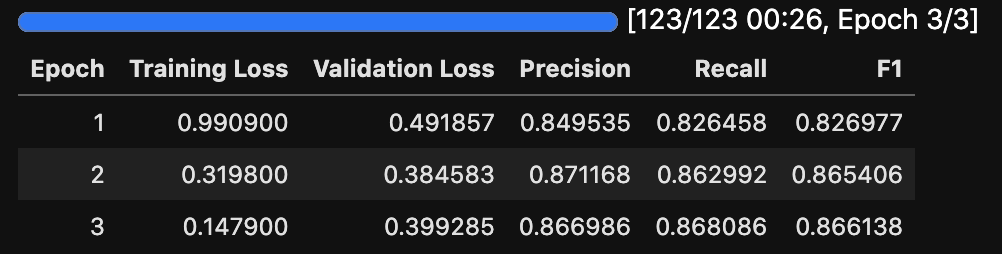
チェックポイントから学習を再開する
TrainingArgumentsの引数にチェックポイントから学習を再開するときに指定するresume_from_checkpointがありますが、TrainingArgumentsでこれを指定してもチェックポイントから学習が再開されません。
詳しくはリファレンスを参照いただきたいですが、チェックポイントから学習を再開したいときは、Trainerクラスの.trainメソッドに対して、resume_from_checkpointを指定する必要があります。Trueを指定すればTrainingArgumentsのoutput_dirで指定したディレクトリの中にある最後のチェックポイントから学習が再開されます。チェックポイントのディレクトリのパスを指定してじっこうすることもできます。
# チェックポイントから学習を再開したいときと
trainer.train(ignore_keys_for_eval=['last_hidden_state', 'hidden_states', 'attentions'],
resume_from_checkpoint=True)
モデルの保存
学習後のモデルの保存は.save_modelで保存できますが、上のプログレスバーのような各エポックの損失の推移であったり、評価データのメトリクスの情報は.save_stateで保存できます。.save_stateを実行すると、TrainingArgumentsのoutput_dirで指定したフォルダにtrainer_state.jsonというファイルが保存されます。
trainer.save_state()
trainer.save_model()
テストデータの予測
テストデータに対する予測は.predictで行えます。最初に避けといたtest_datasetを指定し、テストに必要ないモデルの戻り値の変数名をignore_keysに指定します。
.predictの戻り値の.predictionsにモデルの推論結果が格納されています。
最後に予測結果をsklearnのclassification_reportで表示してみました。たった3エポックですがいい感じに学習できてる感じですね。
pred_result = trainer.predict(test_dataset, ignore_keys=['loss', 'last_hidden_state', 'hidden_states', 'attentions'])
test_df['predict'] = pred_result.predictions.argmax(axis=1).tolist()
from sklearn.metrics import classification_report
print(classification_report(test_df['category_id'], test_df['predict'], target_names=categories))
# precision recall f1-score support
#
# movie-enter 0.85 0.90 0.87 136
# it-life-hack 0.87 0.86 0.87 103
# kaden-channel 0.96 0.93 0.94 136
# topic-news 0.87 0.88 0.88 112
#livedoor-homme 0.73 0.80 0.76 82
# peachy 0.81 0.72 0.76 127
# sports-watch 0.96 0.87 0.91 130
#dokujo-tsushin 0.83 0.90 0.86 145
# smax 0.96 0.97 0.96 136
#
# accuracy 0.87 1107
# macro avg 0.87 0.87 0.87 1107
# weighted avg 0.88 0.87 0.87 1107
おわりに
上で見たようにFine Tuning時の学習に関する実装はTrainingArgumentsを指定してTrainerクラスのインスタンスに対して.trainで終わりです。これだけで、学習や評価データのロギング、学習率のスケジューラー、Early Stoppingなどの、自分で実装するとなったらそこそこ大変は実装をすっ飛ばすことができます。もちろんTrainerクラスの仕組みや内部でどのような計算が行われているかはリファレンスを熟読して理解しておく必要はありますが、今回紹介した内容で少しはTrainerクラスでどんなことができるのかの雰囲気はつかめるのではないかと思います。
Trainerクラスの便利さを知ってしまったので、もう自分であれこれ学習コードの実装なんてしたくない...
おわり