はじめに
前回の記事
では、OptimumライブラリのBetter Transformerの機能を利用してHugging Face形式のモデルでFlash Attentionを使う方法を紹介しました。
日本語LLM (ELYZA-japanese-Llama-2-7b) の推論をFlash Attentionで高速・軽量化できるかを実験したのですが、LLMの推論を高速・軽量化する別の手法のkey-value cacheの方が効果的であり、一緒に使うとFlash Attentionの効果は見えなくなるという少し残念な結果でした。
その後、X(旧Twitter)で、Hugging Face Transformersから直接、公式実装のFlash Attention2を簡単に使えるようなったという情報を見かけたので早速試してみました。
https://twitter.com/younesbelkada/status/1705258148045750343?t=656ikfDpFWkZArTGlpjUHQ&s=19
環境
実験はGoogle Colab上で行いました。
公式のFlash Attention実装では(記事執筆時点では)Ampereかそれより新しいアーキテクチャのGPUしかサポートせず、T4 GPUでは動作しないので、Proに課金してA100 GPU (VRAM 40,960MiB)を使用しました。
ライブラリのインストール
最新版のHugging Face Transformersを使う必要がありますので、GitHubからインストールします。
!pip install git+https://github.com/huggingface/transformers.git
さらに、Flash Attention公式実装のflash-attnライブラリもインストールする必要があります。
!pip install flash-attn --no-build-isolation
load_in_8bit=True引数などを指定して量子化モデルを読み込む場合には以下のライブラリも必要です。
!pip install accelerate bitsandbytes
今回の実験では、optimumライブラリは必要ありません。
Pythonおよびライブラリのバージョン
Python 3.10.12
accelerate 0.23.0
bitsandbytes 0.41.1
flash-attn 2.2.4.post1
torch 2.0.1+cu118
transformers 4.34.0.dev0
実験
前回と同じく、LLMとしてELYZA-japanese-Llama-2-7bを使用し、Flash Attentionおよびkey-value cacheの有無によって推論時間およびVRAM使用量がどれだけ変化するかを調べます。
前回は日本語LLMの1例としてELYZAのモデルを選んだだけで他の日本語LLMを使用しても良かったのですが、今回使用するTransformersのFlash Attentionサポート機能は現在開発中のものであり、こちらのissueのページによると記事執筆時点(2023/9/23)ではLlamaとFalconアーキテクチャしかサポートしていません。従って、LlamaをベースとしているELYZAモデルなら今回の方法でFlash Attentionを使用できますが、他のGPT-NeoXをベースとした日本語LLMでは今回の方法は使えません。実際、LINEのjapanese-large-lm-3.6bでも試してみましたが、サポート外だというエラーが出ました。しかし、活発に開発が進んでいるようですので近いうちにGPT-NeoXもサポートされると期待しています。
さて、Flash Attentionを有効化するためには、AutoModelForCausalLM.from_pretrained()の引数にuse_flash_attention_2=Trueを与えるだけです。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "elyza/ELYZA-japanese-Llama-2-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
use_cache=True,
use_flash_attention_2=True,
)
model.cuda()
非常に簡単ですが、サポート対象モデルであればこれでFlash Attentionを使用することができます。しかも、最初のバージョンよりも高速なFlash Attention 2.0が使われます。
モデル読み込み時に以下のメッセージが出ますので、実際にFlash Attention 2.0が使われていることがわかります。メッセージの通り、Flash Attentionは当然GPU上でしか使えません。また、入力データはfloat16かbfloat16である必要があります。
You are attempting to use Flash Attention 2.0 with a model initialized on CPU. Make sure to move the model to GPU after initializing it on CPU with `model.to('cuda')`.
結果
Flash Attentionの使用有無(use_flash_attention_2引数で制御)とkey-value cacheの使用有無(use_cache引数で制御)を切り替えた4パターンのモデルに対して、系列長を変えながらテキストを生成させて、推論実行時間とGPUメモリ(VRAM)使用量を計測しました。
詳しい実験方法は前回の記事を参照ください。
以下の表とグラフで、系列長(sequence length)は、入力と出力の系列長の和を意味します。
また、推論によるVRAM使用量とは、推論実行中のピーク使用量から実行前の使用量(モデルが占有しているメモリ量)を引いたもののことです。
float16
まず、モデルの重みをtorch.float16で読み込んだ場合の結果を示します。
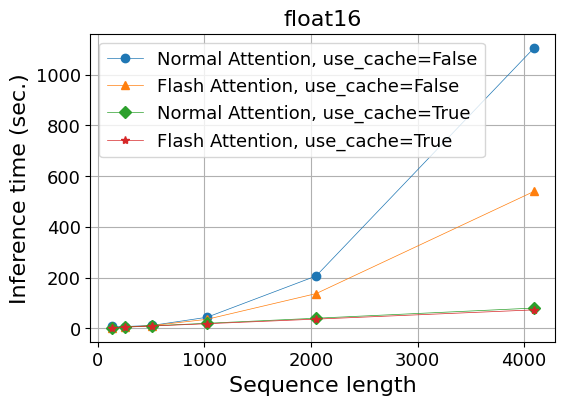
- 計算時間(秒)
| 系列長 | 128 | 256 | 512 | 1024 | 2,048 | 4,096 |
|---|---|---|---|---|---|---|
| Normal Attention, use_cache=False | 7.2 | 7.0 | 11.6 | 43.5 | 206.1 | 1,105.6 |
| Flash Attention, use_cache=False | 2.4 | 4.8 | 10.8 | 35.5 | 136.7 | 539.9 |
| Normal Attention, use_cache=True | 2.6 | 5.0 | 9.9 | 19.7 | 39.7 | 79.9 |
| Flash Attention, use_cache=True | 2.3 | 4.5 | 9.0 | 18.1 | 36.2 | 72.6 |
- 推論によるVRAM使用量 (GB)
| 系列長 | 128 | 256 | 512 | 1024 | 2,048 | 4,096 |
|---|---|---|---|---|---|---|
| Normal Attention, use_cache=False | 0.05 | 0.08 | 0.16 | 0.42 | 1.35 | 4.71 |
| Flash Attention, use_cache=False | 0.04 | 0.08 | 0.16 | 0.31 | 0.63 | 1.25 |
| Normal Attention, use_cache=True | 0.12 | 0.25 | 0.50 | 1.00 | 2.00 | 4.00 |
| Flash Attention, use_cache=True | 0.12 | 0.25 | 0.50 | 1.00 | 2.00 | 4.00 |
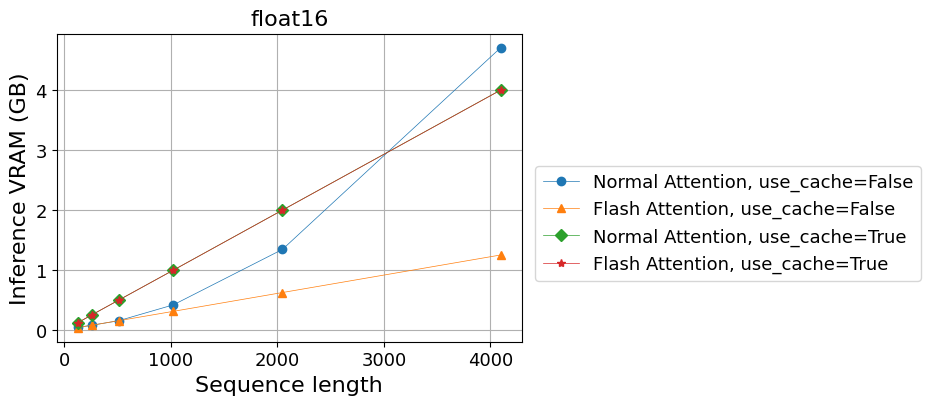
以下の傾向が見て取れます:
- Key-value cacheを使わない場合、
- 通常のAttentionではメモリ使用量は系列長に対してほぼ2乗で増えるのに対し、Flash Attentionを使うと線形の増加に抑えられる。
- 計算時間もFlash Attentionによって短縮される。
- Key-value cacheを使う場合、
- 通常のAttentionではメモリ使用量の増加は系列長に対して線形であり、Flash Attentionを使っても変わらない。
- 線形増加の傾きは、key-value cacheを使わない場合に比べるとcacheの分だけ大きい。
- 計算時間はFlash Attentionを使うとわずかに短くなる。
前回のBetter TransformerのFlash Attentionを使った時とほぼ同じ傾向ですが、key-value cacheを使った場合でも計算時間はFlash Attentionによりわずかながら短縮されており、Flash Attentionを併用しても意味がないというわけではないという結論になります。
int8
次に、load_in_8bit=True引数を与えてモデルの重みをtorch.int8で読み込んだ場合の結果です。
ちなみに、この場合はモデルの重みは自動でGPUメモリ上にのせられ、model.cuda()を実行するとエラーが起きるので注意です。
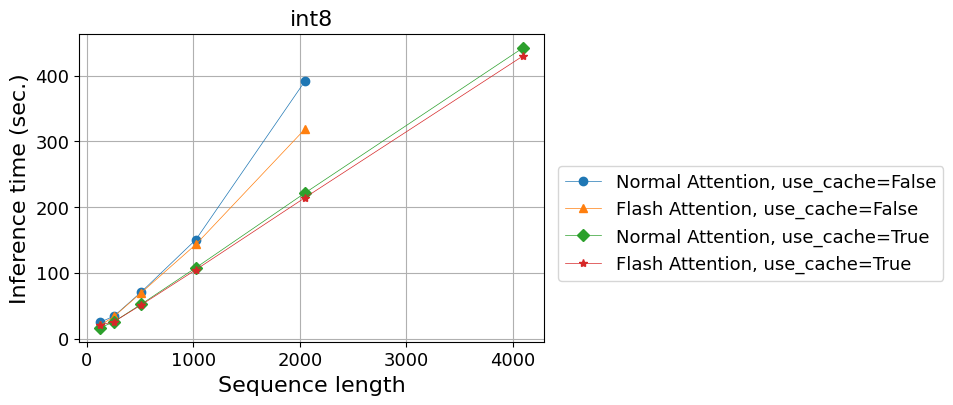
- 計算時間(秒)
| 系列長 | 128 | 256 | 512 | 1024 | 2,048 | 4,096 |
|---|---|---|---|---|---|---|
| Normal Attention, use_cache=False | 25.1 | 34.2 | 71.0 | 150.5 | 391.5 | - |
| Flash Attention, use_cache=False | 20.3 | 33.7 | 69.9 | 143.2 | 318.7 | - |
| Normal Attention, use_cache=True | 16.5 | 25.7 | 52.5 | 107.8 | 221.4 | 442.2 |
| Flash Attention, use_cache=True | 20.7 | 25.8 | 51.4 | 104.7 | 214.3 | 430.0 |
use_cache=Falseの時の系列長4,096は時間がかかりすぎるので実行していません。
- 推論によるVRAM使用量 (GB)
| 系列長 | 128 | 256 | 512 | 1024 | 2,048 | 4,096 |
|---|---|---|---|---|---|---|
| Normal Attention, use_cache=False | 0.07 | 0.08 | 0.16 | 0.44 | 1.35 | - |
| Flash Attention, use_cache=False | 0.07 | 0.08 | 0.16 | 0.31 | 0.70 | - |
| Normal Attention, use_cache=True | 0.13 | 0.25 | 0.50 | 1.00 | 2.00 | 4.00 |
| Flash Attention, use_cache=True | 0.13 | 0.25 | 0.50 | 1.00 | 2.00 | 4.00 |
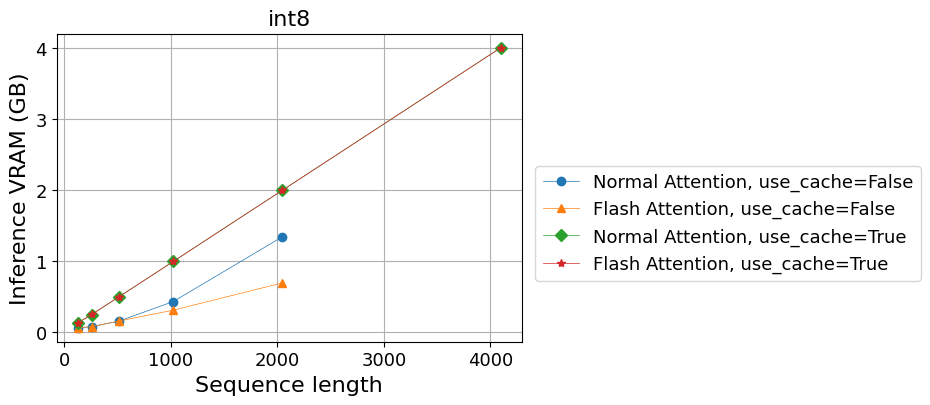
この場合も、float16の場合と同じ傾向となりました。
今回使用したFlash Attentionの方法も重みの量子化と一緒に使って問題ないということが確かめられました。
まとめ
Hugging Face Transformersで、非常に簡単にFlash Attentionを使うことができる新しい機能を試してみました。
推論においては、やはりkey-value cacheによる効率化の効果が高いため、Flash Attentionのメリットは少ないという結論は前回記事と同じですが、わずかでも高速化の効果が見られたのは収穫です。
対応しているモデルであればfrom_pretrained()の引数一つでFlash Attentionを有効化できますので、ファインチューニングの際に威力を発揮する機能だと思います。