目次
0.機械学習とディープラーニング
1.アルゴリズムの違い
2.用途の違い
3.学習の違い
─3.1.バッチ学習とミニバッチ学習
─3.2.誤差逆伝播法
─3.3.隠れ層の存在─ハイパーパラメータ
─3.4.特徴量抽出の有無
0.機械学習とディープラーニング
この記事では機械学習とディープラーニングの違いに焦点を当てて説明していきます。
これらとAIには以下のような包含関係があります。
AI > 機械学習 > ディープラーニング
ここからは**「機械学習」と「ディープラーニング」を明確に区別して扱っていきます。
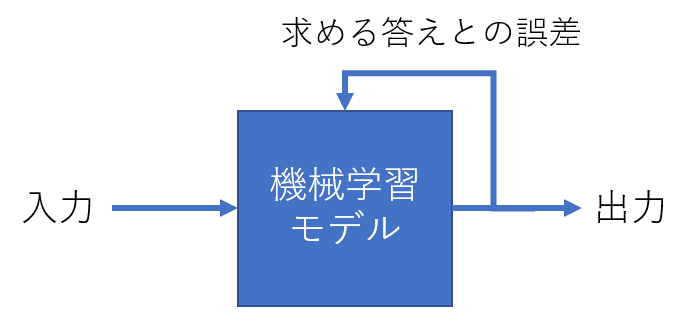
そもそも機械学習というのは、アルゴリズムで構築したモデルに対し、求める出力が出るようにパラメータを調整することです。パラメータを調整する部分を指して学習や訓練**といいます。
対して、よくディープラーニングは「機械学習の規模を大きくしたもの」として紹介されます。これは巨大なモデルを構築し、それを学習するために膨大なデータを入力するということです。
では、一体中身はどのように違うのか、3つの観点から見ていきましょう。
1.アルゴリズムの違い
「機械学習」のフレームワークの一つにscikit-learnがあります。フレームワークというのはプログラムのツールをまとめたようなものです。機械学習用フレームワークにはモデルを構築するためにいくつかのアルゴリズムが準備されています。例えば以下のようなものです。
線形回帰/SVM/決定木/ランダムフォレスト/k近傍法/ロジスティック回帰/ニューラルネットワーク.....
たくさんありますね笑。
機械学習を道具として利用するエンジニアはこれらのアルゴリズムの中から、問題に対して最も効果的なものを選びます。
そこで、エンジニアという何かと楽をしたがる生き物はこう考えます─「すべての問題に対して効果的な最強アルゴリズムはないの?」
ないんだそうです。残念ですね。
「ノーフリーランチ定理」という外国人特有のおしゃれな定理がそう言っています。語源は「ただより高い物はない」から来ているそうです。
話を戻しますと、機械学習が多彩なアルゴリズムを使い分けるのに対し、「ディープラーニング」には一つしかありません。ニューラルネットワークです。ニューラルネットワークは脳の神経細胞を模したモデル...とよく説明されますが、ろ過装置のように入り口からデータを流して、何層もの層を通って、答えに変換された値が出てくる、というようなイメージです。
tensorflowのようなディープラーニングフレームワークには、ニューラルネットワーク以外のアルゴリズムはありません。なぜでしょうか?
それはニューラルネットワークが他のアルゴリズムより遥かに拡張性に優れているからです。これは利点でもあり、欠点でもあります。工夫次第で色々なことができる反面、ネットワークは巨大になり、人間の手に負えなくなっていく...そんな感じです。
ディープラーニングフレームワークには、こういった人間の手に負えない規模の計算を行うための様々な工夫が実装されています。scikit-learnにもニューラルネットワークはありますが、それを巨大にし、学習させるとなると不可能になってくるわけです。
2.用途の違い
2021年時点でAIを活用する職業は大きく分けて二つあります。データサイエンティストと機械学習エンジニアです。データサイエンティストは、AI技術を使って統計学の観点からビジネス的な助言を行うコンサル業務が主な仕事です。マーケティングに関係ありそうな過去のデータから機械学習モデルを作って予測を行い、先々の戦略を立案するといったところでしょうか。
対して、機械学習エンジニアはAIに特化したソフトウェアエンジニアです。実際の製品にAIを組み込み、画像認識や音声認識のような様々な機能を実現させます。
なぜこんな話をしたのかというと、それぞれのタスクが違うからです。「調査・分析」に対する「開発」です。
いずれも例外はありますので、大まかな傾向という話ですが、調査や分析には機械学習が向いています。理由を簡潔に言えば、すぐ作れるからです。スピード感を要求されるビジネスの現場では、学習や調整に時間のかかるディープラーニングを選択する場合は少ないのではないでしょうか。聞くところによると、データ分析を行う会社では、データ分析・考察・計画立案を一週間のサイクルで行うそうです。
対して開発はどうでしょうか?
常に最新が求められる世界です。例えば画像認識なら、機械学習での認識精度は目に見えています。ディープラーニングを使えば、数千~数万枚の画像から認識対象を学習できます。開発においてディープラーニングが避けて通れない道というのは、おわかりかと思います。
3.学習の違い
さて、ここまで読んでいただいて恐縮ですが、今回書きたかった内容はここからです。機械学習とディープラーニングの具体的な中身の違いです。
機械学習でもニューラルネットワークモデルは作れますが、ディープラーニングは何が違うのか。一言でいえばネットワークの層の数 (規模) が違うのですが、規模が違うと何が違うのか、どんな問題が起きるのかを書いていきます。
3.1 バッチ学習とミニバッチ学習
ここでは層が一つしかない単純なニューラルネットワークモデル、「ADALINE」を例にとって説明していきます。ADALINEの構造は以下のようになっています。
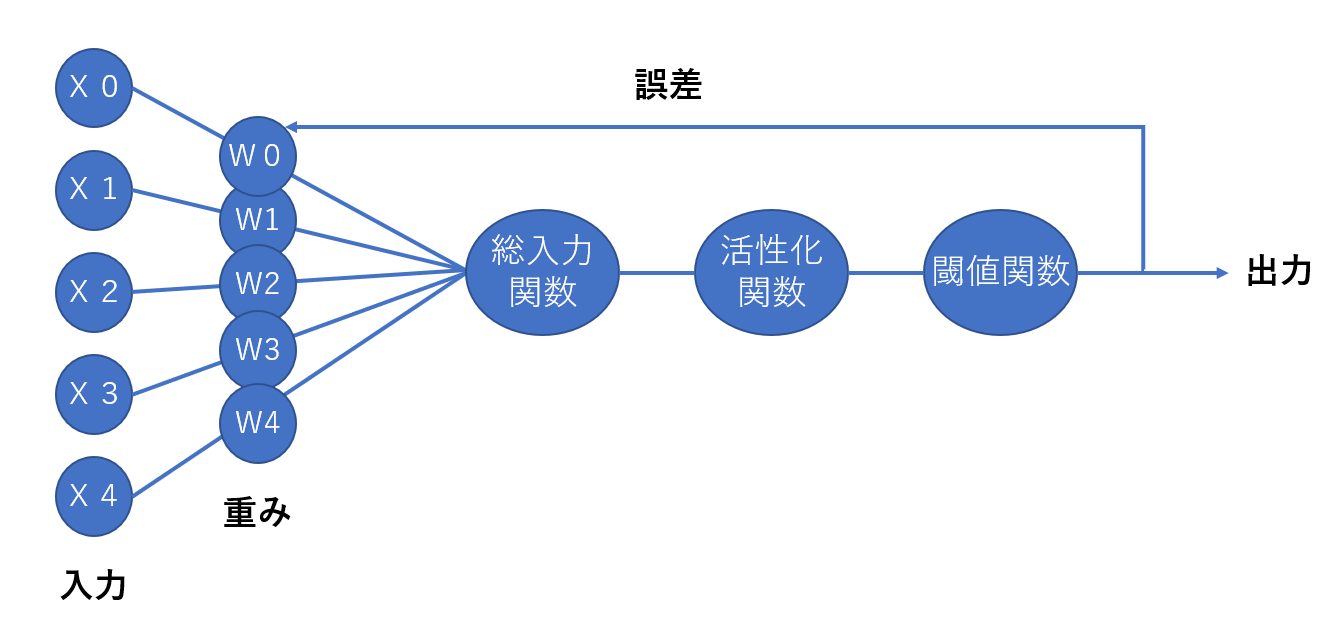
いきなり関数がたくさん並んでいますが、ここでは重みと誤差だけ見ていただければ大丈夫です。左から5つの入力が入ってきて→重みをかけ合わされ→関数を通って→出力が1つ出てくる、という感じです。
ここでの「重み」というのが、ニューラルネットワークが学習するパラメータそのものになります。
「誤差」はどの程度学習できているかの指標です。大きければ学習できておらず、小さいほど学習できています。誤差はコスト関数や損失関数と呼ばれますが、これは重みの値によって変化します。
つまり、重みの関数です。
数学に慣れた方はここでピンとくるかもしれませんが、学習の目的はコスト関数を小さくすることです。
関数の最小値(極小値)...高校数学で夢中になって取り組んだ(散々やらされた)、微分です。
コスト関数は重みの関数です。そのため、コスト関数を各重みで偏微分することで、重みを変化させたときにコスト関数がどう変化するかがわかります。あとはコスト関数が小さくなるように重みを変化させる、というのが学習の流れです。
ちなみに、偏微分した値を並べたものをベクトル微分 (勾配) と呼びます。そのため、以上の重み更新の手法を勾配降下法といいます。図で示すと以下のようになります。
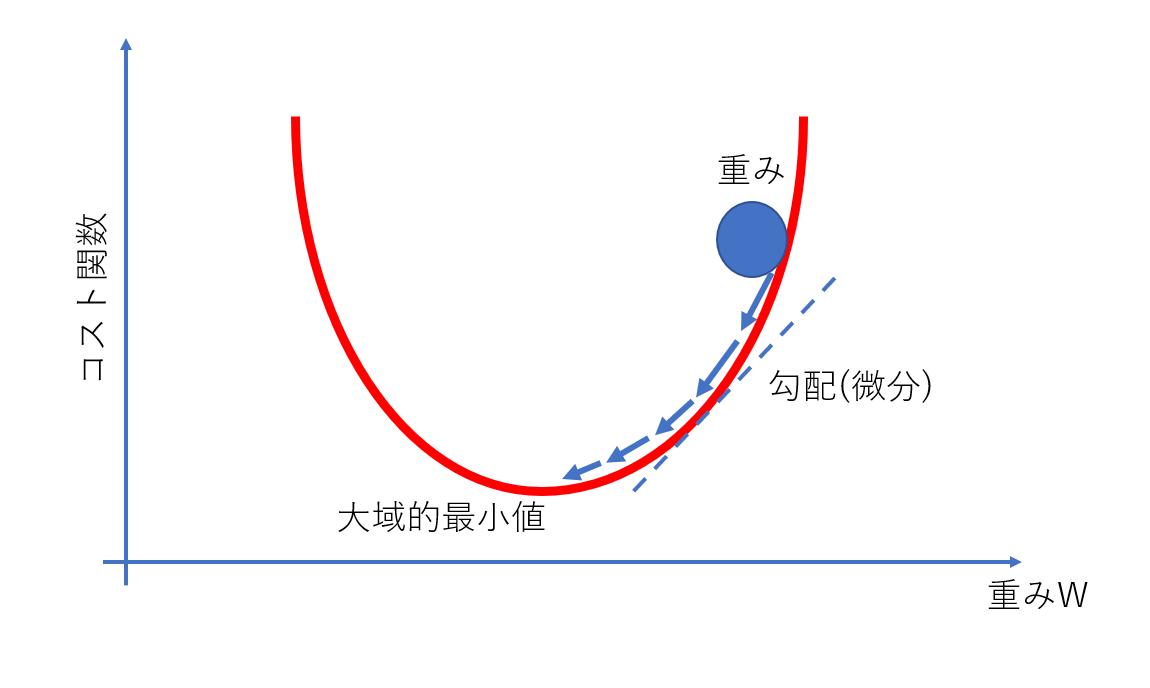
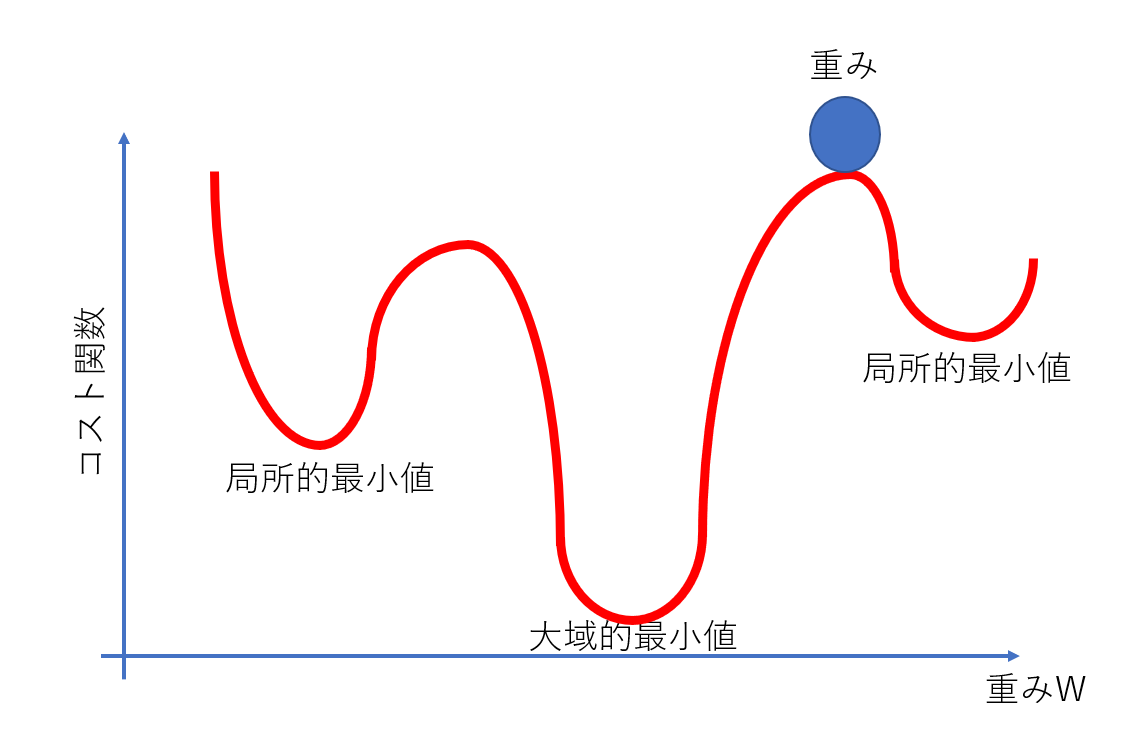
重みの更新は大域的最小値や局所的最小値に達するまで行われますが、一回の更新で達するわけではありません。
学習データを何度も流し、あっちでもない、こっちでもないという感じで徐々に近づいていきます。
学習データを一巡する単位をエポックといいます。一巡で1エポックです。
一度に全ての学習データを流す方法をバッチ学習と呼びます。例えば100個のデータを、100個流し更新→100個流し更新→......といった具合です。これは機械学習でよく行われる方法です。データの数がそれほど多くないからこそ、一度に全て流せるというわけです。
では、1万個のデータの場合はどうでしょう?
計算量が大きすぎて手に負えないことが想像できるかと思います。そこで行われるのが確率的勾配降下法(Stochastic Gradient Descent, SGD)です。
SGDは二つに分けられます。
まず、一度に1個ずつ学習データを流し更新するオンライン学習です。これは主に、新しいデータに対してその場で適応するような場面で使われます。
そしてもう一つが、一度にある程度の塊(ミニバッチ)ごとにデータを流すミニバッチ学習です。こちらは例えば1万個のデータのうち、32個流し更新→別の32個流し更新→......という感じです。10,000 / 32 = 312.5、つまり313回データを流して1エポック学習させるというものです。
ミニバッチ学習はデータの多いディープラーニングにおいて重要な役割を果たします。これはバッチ学習とオンライン学習のいいとこどりです。バッチ学習はデータ数が多い分、ノイズに強い利点があります。オンライン学習には学習が素早く進む利点があります。ミニバッチ学習はこの二つを併せ持ちますが、それに加えてもう一つうれしいことがあります。
計算効率の改善です。
ディープラーニングはGPUを使って計算することが現在の主流ですが、その理由はミニバッチ学習です。GPUは行列演算が得意で、ミニバッチ学習では入力データを以下のように何個かの塊にし、行列として入力することができます。(ちなみに1次元配列をベクトル、2次元配列を行列、3次元以上をテンソルといいます)
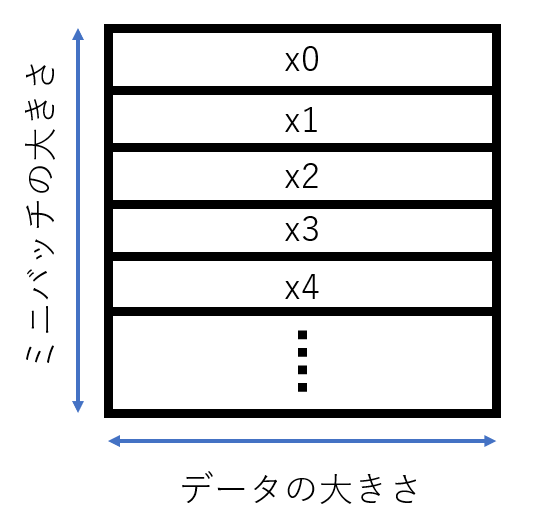
ミニバッチの大きさは16,32,64... のように2のn乗個にすることが多いです。
付け加えておきますと、バッチ学習ができることに越したことはありません。実際のところは、使っているコンピュータのスペックに応じてミニバッチの大きさはできるだけ大きくする、というのがセオリーになっています。
3.2 誤差逆伝播法
ディープラーニングの特徴というと誤差逆伝播法(バックプロパゲーション)が欠かせません。ここでは簡単な紹介にとどめます。
よく誤差逆伝播法を、出力を入力方向へフィードバックして学習させること、と認識している方がいますが、これは半分誤った認識です(言葉だけ見ればそう思いますが)。
半分というのは、出力をフィードバックさせることに違いはないですが、学習させること自体を指しているのではありません。誤差逆伝播法はニューラルネットワークを効率的に訓練するアルゴリズムです。
具体的には、コスト関数の偏微分の計算を効率化します。この効率化なしではディープラーニングは不可能といえるほど、誤差逆伝播法は必需品です。なぜなら、ニューラルネットワークの層が増えるほど重みの数も増えるからです。
どのくらい増えるかは、2層のネットワークを見ればすぐわかります。
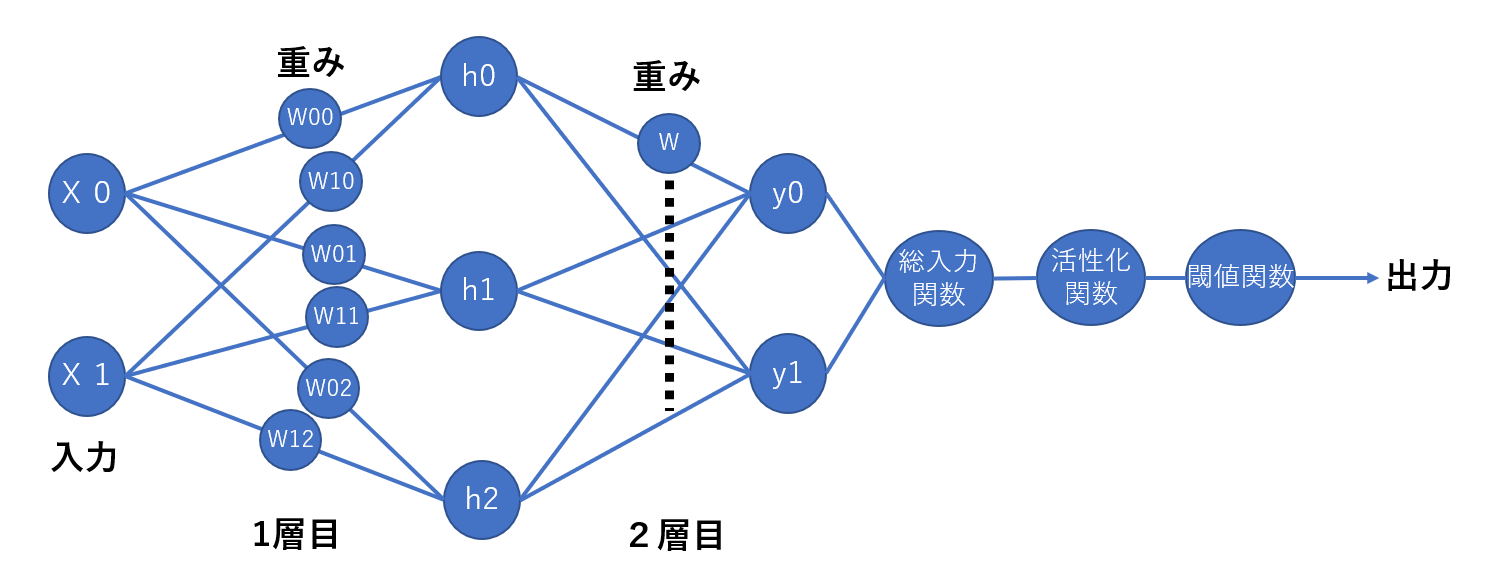
1層増えただけでこんなに増えるのですから、数百の層を持つようなディープラーニングでは、重みは数十億個にもなります。それらの偏微分は膨大な計算量です。
ちなみに、そういった巨大なニューラルネットワークのコスト関数は、先に見たADALINEのような単なる凸関数ではありません。一例を下に示します。
誤差逆伝播法の中心にあるのは連鎖律という考え方です。微積分で当時勉強した時には「こんなもの何の役に立つのか」と思ったものですが、とんでもなく役立っていたみたいです。
連鎖律は合成関数の微分を簡単に求めるための方法です。イメージは以下のようになります。
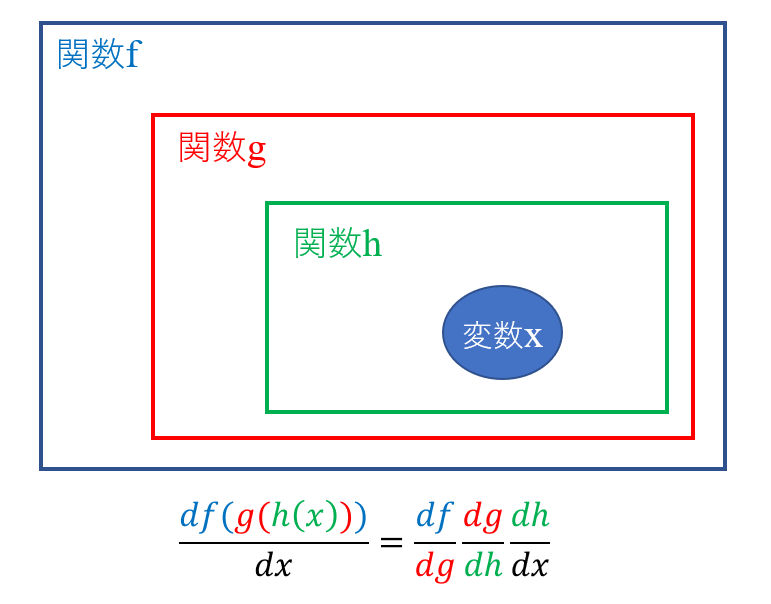
合成関数は関数の中に別の関数が入っているものです。
この連鎖律をニューラルネットワークでは以下のように使います。
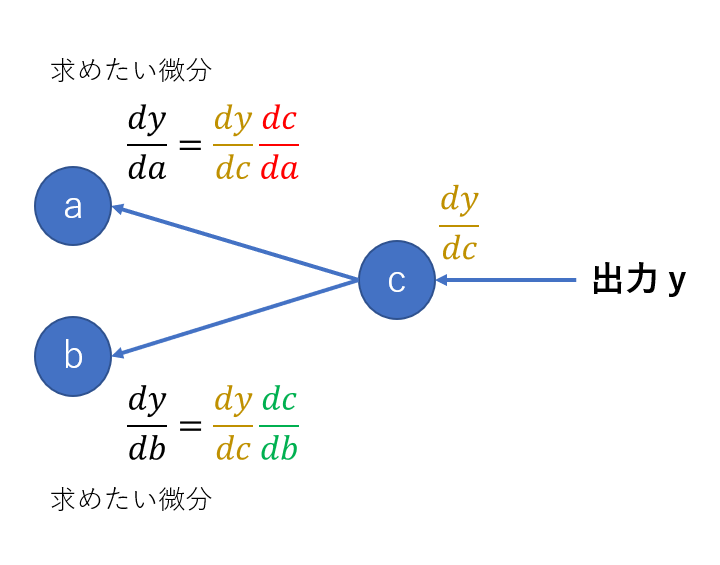
ざっくりした説明で恐縮ですが、出力側から流れてくる微分を使って求めたい微分を得る、という感じです。イメージくらいは伝わっていると嬉しいです。
興味を持たれたら、詳しく勉強してみてください。
3.3 隠れ層の存在─ハイパーパラメータ
先ほど、2層のニューラルネットワークを示しました。ここで、しれっと増えていたのが「h」と書かれた中間の層です。これは隠れ層(hidden layer)と呼ばれます。定義では、隠れ層が一つ以上存在するネットワークがディープニューラルネットワーク(DNN)とされています。
DNNの学習が複雑になるのは、この隠れ層の存在によるところが大きいです。なぜなら、隠れ層を何層にするのか、ニューロンの数(図中の青丸の数)を何個にするのかは、作り手である人間が決めなければならないからです。
こういった、人の手で調整・決定する必要のある数値をハイパーパラメータといいます。ハイパーパラメータは実験を繰り返すなどして調整していきます。
機械学習アルゴリズムの中でも、調整があまり要らず、かつ良い性能を持つランダムフォレストとニューラルネットワークをパラメータの面で比較してみましょう。
scikit-learnに実装されているランダムフォレストを定義するとき、pythonでは以下のように書きます。

これは少し極端な例ですが、これで動くものが作れます。
これに対し、scikit-learnでニューラルネットワークを定義するときは以下のようになります。

実際にはもっと細かく見ると思いますが、ざっとこんなに違います。
さらに、tensorflowを使ってニューラルネットワークを定義すると以下のようになります。

この例ではネットワークの層をConv2D→MaxPooling2D→Flatten→Dense→Dense という風に重ねています。tensorflowの方が視覚的にわかりやすい感じがしませんか?
アルゴリズムの項でも書きましたが、ニューラルネットワークは自分の手でいくらでもカスタマイズができます。何層重ねるのか、どういう順番にするのか、パラメータはどうするか...考えなければいけないことは山積みなので、きちんと定石を理解し、方針を立てておくことが必要です。
3.4 特徴量抽出の有無
特徴量抽出というのは、学習データとして集めたデータ(特徴量)の中で何が大事なのかを選別する作業のことです。
よく用いられる例えが、リンゴです。リンゴの特徴量としては、その「色」「味」「大きさ」などがあります。ここで、美味しいリンゴを選別したいとき、最も大事な特徴量は「味」になります。そのため、「味」を学習データに選別するわけです。
しかし、こういった作業は機械学習特有のもので、ディープラーニングでは行われません。
リンゴでいえば、 ディープラーニングは膨大な数のリンゴを調べて、美味しいリンゴの共通点を自分で導きます。ここでディープラーニングが考慮するのは「味」だけではありません。美味しいリンゴはより鮮やかな色をしているとか、より大きいとか、「色」「大きさ」も加味することで、より高い精度で美味しいリンゴを見極めます。
このとき、ネットワークは人間に認識できないようなパターンや経験則を学習しており、これを表現学習といいます。
これには問題があります。それは、ディープラーニングモデルが「このリンゴは美味しいよ」と出した答えに対し、「なんで美味しいの?」と聞いても答えを返してくれないことです。
なぜそのリンゴが美味しいのかは、ディープラーニングモデルが学習した膨大な数字の羅列の中に、人間にはわからない形で埋もれています。そして、ディープラーニングが結論にたどり着くまでの過程は、考慮している要素が多すぎて人間には把握しきれません。
もう一つ問題があります。それは過学習です。ディープラーニングモデルは特に過学習しやすい傾向がありますが、こちらは様々な手法によって回避することが可能です。
過学習とは、ディープラーニングモデルが問題に過度に適応することを言います。リンゴでいえば、モデルが「赤くて大きくて甘いリンゴは美味しい」ということに過度に適応したとします。そこに「この青リンゴは美味しいの?」と尋ねれば、モデルは必ずこう答えます。「青いんだから不味いに決まってるよ」と。
これには全国の青リンゴ農家さんも真っ赤っか。
人間と違ってモデルはコンピュータの計算でできていますから、融通が利かず、学習もとどまるところを知りません。
そのため、相応の対策として、「青いリンゴというのも世の中にはあるんだよ」と人間が教えておくこと(実際にはもっと色々な工夫)が必要です。
おわりに
いかがだったでしょうか?今回は機械学習とディープラーニングの違いに焦点を当て、AI技術の基本的な仕組みについて書きました。AIのことを「なんだか難しそう」と思っておられた方も、実態を知ってしまえば、これはコンピュータの計算の塊だということがおわかりかと思います。
それはつまり、AIは万能ではないことも意味します。ファンタジーではAIは自分で考えて行動して勝手にいろんなことを覚えて人類に敵意を覚えて滅ぼしに来ますが、現在のAIはそんなものとはまるで別物です。
長くなりましたが、ここまでお読みいただきありがとうございました。
わかりづらいところもあったかとは思いますが、そこはお互い精進しましょうということで。